







从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
- 采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
- 采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
- 对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
- 支持用户词典扩展定义。
- 针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
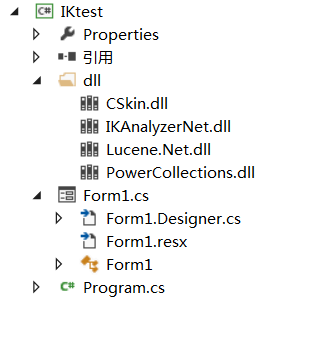
项目结构
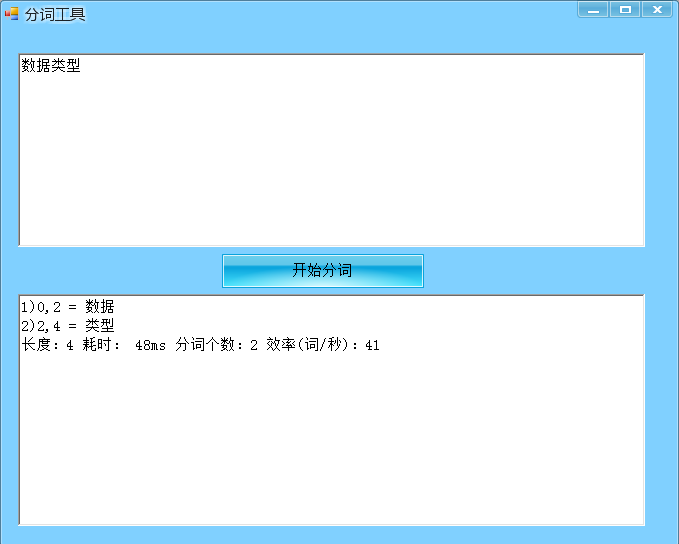
Form1.cs代码:
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using IKAnalyzerNet;
using Lucene.Net.Analysis;
namespace IKtest
{
public partial class Form1 : CCWin.CCSkinMain
{
public Form1()
{
InitializeComponent();
}
private void btnAnalyse_Click(object sender, EventArgs e)
{
String testString = rtfRichtxtInput.Text;
String slen = testString.Length.ToString();
IKAnalyzer ika = new IKAnalyzer();
System.IO.TextReader r = new System.IO.StringReader(testString);
TokenStream ts = ika.TokenStream("TestField", r);
int m = 0;
long begin = System.DateTime.Now.Ticks;
for (Token t = ts.Next(); t != null; t = ts.Next())
{
m++;
rtfRichTxtResult.Text += m + ")" + (t.StartOffset() + "," + t.EndOffset() + " = " + t.TermText()) + "\r\n";
}
int end = (int)((System.DateTime.Now.Ticks - begin) / 10000);
rtfRichTxtResult.Text += ("长度:" + slen + " 耗时: " + (end) + "ms" + " 分词个数:" + m + " 效率(词/秒):" + ((int)(m * 1.0f / (end) * 1000))) + "\r\n";
}
}
}















 4487
4487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









