一些说明:
- 使用urllib或requests包来爬取页面。
- 使用正则表达式分析一级页面,使用Xpath来分析二级页面。
- 将得到的标题和链接,保存为本地文件。
NewsSpider.py代码:
import os
import sys
import urllib
import requests
import re
from lxml import etree
def StringListSave(save_path, filename, slist):
if not os.path.exists(save_path):
os.makedirs(save_path)
path = save_path+"/"+filename+".txt"
with open(path, "w+") as fp:
for s in slist:
fp.write("%s\t\t%s\n" % (s[0].encode("utf8").decode('utf-8'), s[1].encode("utf8").decode('utf-8')))
def Page_Info(myPage):
'''Regex'''
mypage_Info = re.findall(r'<div class="titleBar" id=".*?"><h2>(.*?)</h2><div class="more"><a href="(.*?)">.*?</a></div></div>', myPage, re.S)
return mypage_Info
def New_Page_Info(new_page):
'''Regex(slowly) or Xpath(fast)'''
dom = etree.HTML(new_page)
new_items = dom.xpath('//tr/td/a/text()')
new_urls = dom.xpath('//tr/td/a/@href')
assert(len(new_items) == len(new_urls))
return zip(new_items, new_urls)
def Spider(url):
i = 0
print("下载中 ", url)
myPage = requests.get(url).content.decode("gbk")
myPageResults = Page_Info(myPage)
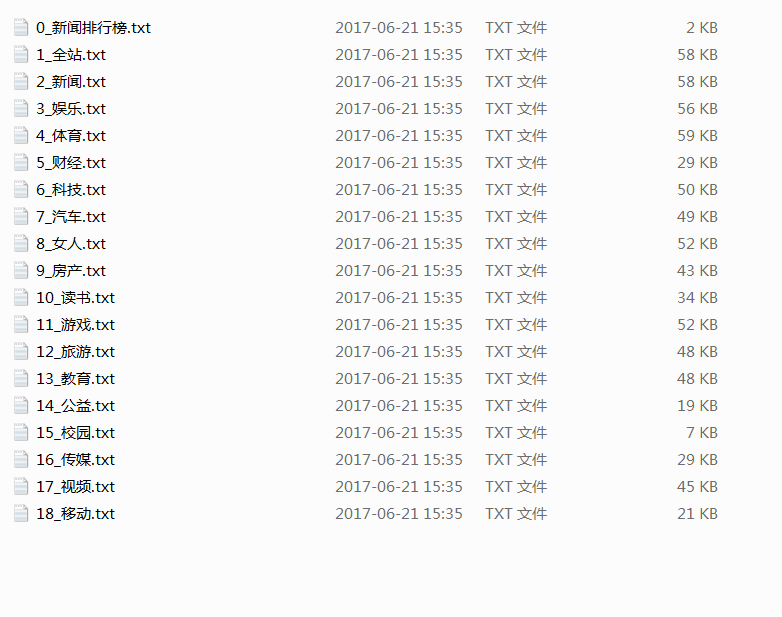
save_path = u"网易新闻抓取"
filename = str(i)+"_"+u"新闻排行榜"
StringListSave(save_path, filename, myPageResults)
i += 1
for item, url in myPageResults:
print("下载中 ", url)
new_page = requests.get(url).content.decode("gbk")
newPageResults = New_Page_Info(new_page)
filename = str(i)+"_"+item
StringListSave(save_path, filename, newPageResults)
i += 1
if __name__ == '__main__':
print("开始")
start_url = "http://news.163.com/rank/"
Spider(start_url)
print("结束")
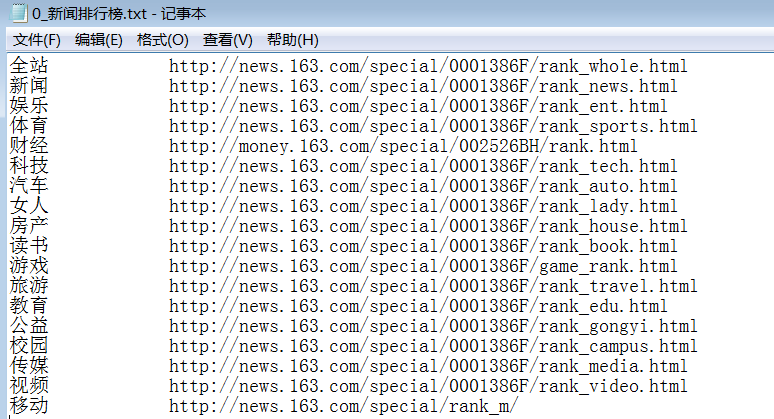
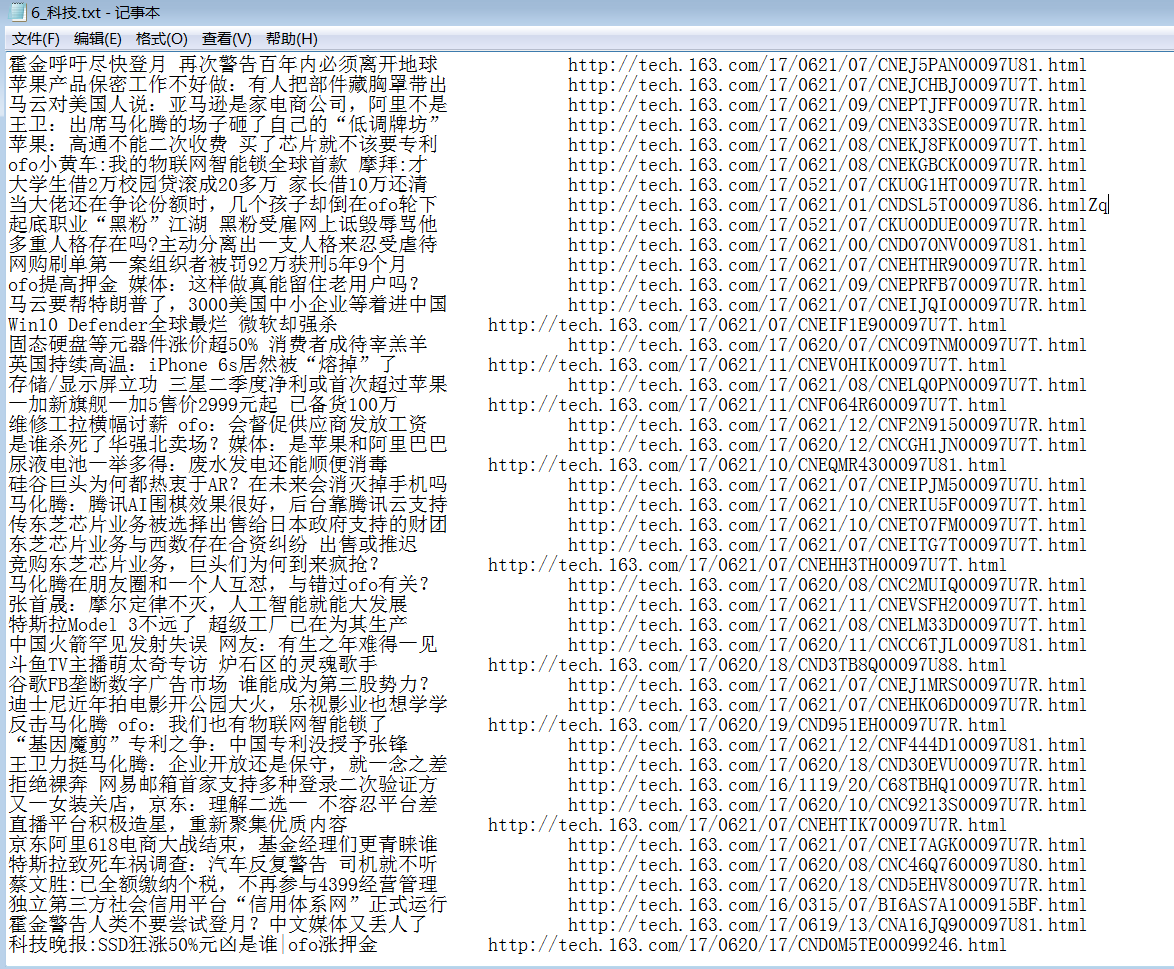
运行结果如图:


























 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









