







原文:Chapter 5
5.1 下载一个月的天气数据
在处理自行车数据时,我需要温度和降水数据,来弄清楚人们下雨时是否喜欢骑自行车。 所以我访问了加拿大历史天气数据的网站,并想出如何自动获得它们。
这里我们将获取 201 年 3 月的数据,并清理它们。
以下是可用于在蒙特利尔获取数据的网址模板。
url_template = "http://climate.weather.gc.ca/climateData/bulkdata_e.html?format=csv&stationID=5415&Year={year}&Month={month}&timeframe=1&submit=Download+Data"我们获取 2013 年三月的数据,我们需要以month=3, year=2012对它格式化:
url = url_template.format(month=3, year=2012)
weather_mar2012 = pd.read_csv(url, skiprows=16, index_col='Date/Time', parse_dates=True, encoding='latin1')这非常不错! 我们可以使用和以前一样的read_csv函数,并且只是给它一个 URL 作为文件名。 真棒。
在这个 CSV 的顶部有 16 行元数据,但是 Pandas 知道 CSV 很奇怪,所以有一个skiprows选项。 我们再次解析日期,并将Date/Time设置为索引列。 这是产生的DataFrame。
weather_mar2012<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 744 entries, 2012-03-01 00:00:00 to 2012-03-31 23:00:00
Data columns (total 24 columns):
Year 744 non-null values
Month 744 non-null values
Day 744 non-null values
Time 744 non-null values
Data Quality 744 non-null values
Temp (°C) 744 non-null values
Temp Flag 0 non-null values
Dew Point Temp (°C) 744 non-null values
Dew Point Temp Flag 0 non-null values
Rel Hum (%) 744 non-null values
Rel Hum Flag 0 non-null values
Wind Dir (10s deg) 715 non-null values
Wind Dir Flag 0 non-null values
Wind Spd (km/h) 744 non-null values
Wind Spd Flag 3 non-null values
Visibility (km) 744 non-null values
Visibility Flag 0 non-null values
Stn Press (kPa) 744 non-null values
Stn Press Flag 0 non-null values
Hmdx 12 non-null values
Hmdx Flag 0 non-null values
Wind Chill 242 non-null values
Wind Chill Flag 1 non-null values
Weather 744 non-null values
dtypes: float64(14), int64(5), object(5)让我们绘制它吧!
weather_mar2012[u"Temp (\xb0C)"].plot(figsize=(15, 5))<matplotlib.axes.AxesSubplot at 0x34e8990>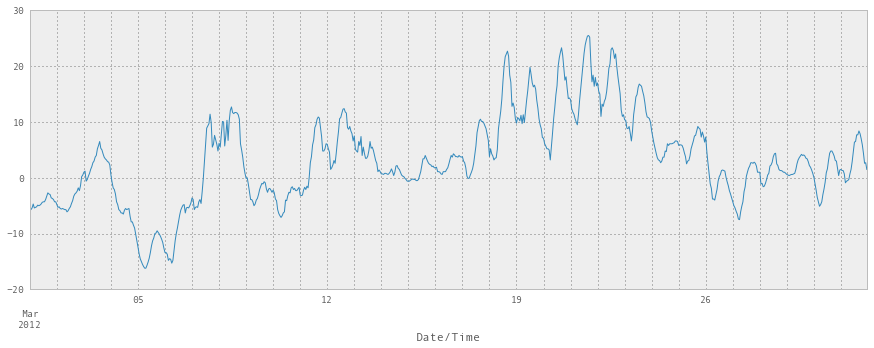
注意它在中间升高到25°C。这是一个大问题。 这是三月,人们在外面穿着短裤。
我出城了,而且错过了。真是伤心啊。
我需要将度数字符°写为'\xb0'。 让我们去掉它,让它更容易键入。
weather_mar2012.columns = [s.replace(u'\xb0', '') for s in weather_mar2012.columns]你会注意到在上面的摘要中,有几个列完全是空的,或其中只有几个值。 让我们使用dropna去掉它们。
dropna中的axis=1意味着“删除列,而不是行”,以及how ='any'意味着“如果任何值为空,则删除列”。
现在更好了 - 我们只有带有真实数据的列。
| Year | Month | Day | Time | Data Quality | Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Date/Time | |||||||||||
| 2012-03-01 00:00:00 | 2012 | 3 | 1 | 00:00 | -5.5 | -9.7 | 72 | 24 | 4.0 | 100.97 | |
| 2012-03-01 01:00:00 | 2012 | 3 | 1 | 01:00 | -5.7 | -8.7 | 79 | 26 | 2.4 | 100.87 | |
| 2012-03-01 02:00:00 | 2012 | 3 | 1 | 02:00 | -5.4 | -8.3 | 80 | 28 | 4.8 | 100.80 | |
| 2012-03-01 03:00:00 | 2012 | 3 | 1 | 03:00 | -4.7 | -7.7 | 79 | 28 | 4.0 | 100.69 | |
| 2012-03-01 04:00:00 | 2012 | 3 | 1 | 04:00 | -5.4 | -7.8 | 83 | 35 | 1.6 | 100.62 |
Year/Month/Day/Time列是冗余的,但Data Quality列看起来不太有用。 让我们去掉他们。
axis = 1参数意味着“删除列”,像以前一样。 dropna和drop等操作的默认值总是对行进行操作。
weather_mar2012 = weather_mar2012.drop(['Year', 'Month', 'Day', 'Time', 'Data Quality'], axis=1)
weather_mar2012[:5]| Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
|---|---|---|---|---|---|---|
| Date/Time | ||||||
| 2012-03-01 00:00:00 | -5.5 | -9.7 | 72 | 24 | 4.0 | 100.97 |
| 2012-03-01 01:00:00 | -5.7 | -8.7 | 79 | 26 | 2.4 | 100.87 |
| 2012-03-01 02:00:00 | -5.4 | -8.3 | 80 | 28 | 4.8 | 100.80 |
| 2012-03-01 03:00:00 | -4.7 | -7.7 | 79 | 28 | 4.0 | 100.69 |
| 2012-03-01 04:00:00 | -5.4 | -7.8 | 83 | 35 | 1.6 | 100.62 |
5.2 按一天中的小时绘制温度
这只是为了好玩 - 我们以前已经做过,使用groupby和aggregate! 我们将了解它是否在夜间变冷。 好吧,这是显然的。 但是让我们这样做。
temperatures = weather_mar2012[[u'Temp (C)']]
temperatures['Hour'] = weather_mar2012.index.hour
temperatures.groupby('Hour').aggregate(np.median).plot()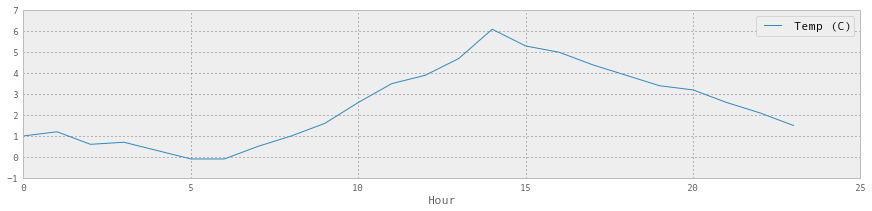
所以温度中位数在 2pm 时达到峰值。
5.3 获取整年的数据
好吧,那么如果我们想要全年的数据呢? 理想情况下 API 会让我们下载,但我不能找出一种方法来实现它。
首先,让我们将上面的成果放到一个函数中,函数按照给定月份获取天气。
我注意到有一个烦人的 bug,当我请求一月时,它给我上一年的数据,所以我们要解决这个问题。 【真的是这样。你可以检查一下 =)】
def download_weather_month(year, month):
if month == 1:
year += 1
url = url_template.format(year=year, month=month)
weather_data = pd.read_csv(url, skiprows=16, index_col='Date/Time', parse_dates=True)
weather_data = weather_data.dropna(axis=1)
weather_data.columns = [col.replace('\xb0', '') for col in weather_data.columns]
weather_data = weather_data.drop(['Year', 'Day', 'Month', 'Time', 'Data Quality'], axis=1)
return weather_data我们可以测试这个函数是否行为正确:
download_weather_month(2012, 1)[:5]| Temp (C) | Dew Point Temp (C) | Rel Hum (%) | Wind Spd (km/h) | Visibility (km) | Stn Press (kPa) | Weather |
|---|---|---|---|---|---|---|
| Date/Time | ||||||
| 2012-01-01 00:00:00 | -1.8 | -3.9 | 86 | 4 | 8.0 | 101.24 |
| 2012-01-01 01:00:00 | -1.8 | -3.7 | 87 | 4 | 8.0 | 101.24 |
| 2012-01-01 02:00:00 | -1.8 | -3.4 | 89 | 7 | 4.0 | 101.26 |
| 2012-01-01 03:00:00 | -1.5 | -3.2 | 88 | 6 | 4.0 | 101.27 |
| 2012-01-01 04:00:00 | -1.5 | -3.3 | 88 | 7 | 4.8 | 101.23 |
现在我们一次性获取了所有月份,需要一些时间来运行。
data_by_month = [download_weather_month(2012, i) for i in range(1, 13)]一旦我们完成之后,可以轻易使用pd.concat将所有DataFrame连接成一个大DataFrame。 现在我们有整年的数据了!
weather_2012 = pd.concat(data_by_month)
weather_2012<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 8784 entries, 2012-01-01 00:00:00 to 2012-12-31 23:00:00
Data columns (total 7 columns):
Temp (C) 8784 non-null values
Dew Point Temp (C) 8784 non-null values
Rel Hum (%) 8784 non-null values
Wind Spd (km/h) 8784 non-null values
Visibility (km) 8784 non-null values
Stn Press (kPa) 8784 non-null values
Weather 8784 non-null values
dtypes: float64(4), int64(2), object(1)5.4 保存到 CSV
每次下载数据会非常慢,所以让我们保存DataFrame:
weather_2012.to_csv('../data/weather_2012.csv')这就完成了!
5.5 总结
在这一章末尾,我们下载了加拿大 2012 年的所有天气数据,并保存到了 CSV 中。
我们通过一次下载一个月份,之后组合所有月份来实现。
这里是 2012 年每一个小时的天气数据!
weather_2012_final = pd.read_csv('../data/weather_2012.csv', index_col='Date/Time')
weather_2012_final['Temp (C)'].plot(figsize=(15, 6))<matplotlib.axes.AxesSubplot at 0x345b5d0>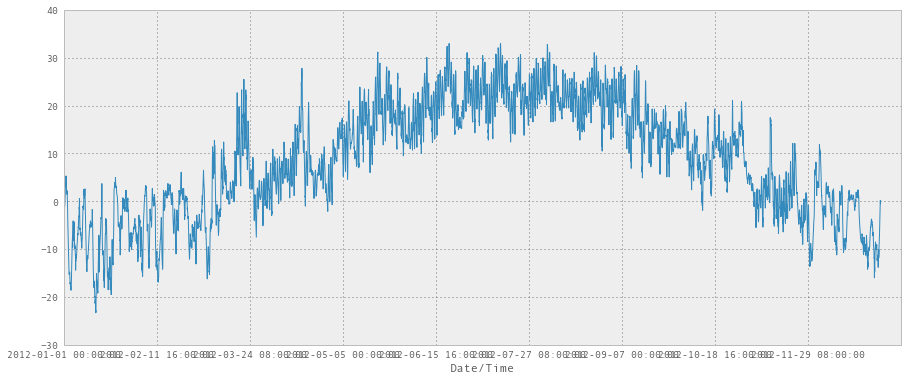















 1237
1237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









