









TiDB 简介 *
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
五大核心特性
- 一键水平扩容或缩容
- 金融级高可用
- 多副本存储、通过Multi-Raft协议同步事务日志,确保强一致性且少数副本故障不影响数据可用性
- 可按需配置副本位置和数量等策略,满足容灾要求。
- 实时 HTAP
- 提供 行存储引擎 TiKV和 列存储引擎 TiFlash, (TiFlash 从 TiKV 实时复制数据)
- 云原生的分布式数据库
- 兼容 MySQL 5.7 协议和 MySQL 生态
四大核心应用场景:
- 对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高的金融行业属性的场景
- 对存储容量、可扩展性、并发要求较高的海量数据及高并发的 OLTP 场景
- Real-time HTAP 场景
- 数据汇聚、二次加工处理的场景
TiDB 架构
整体架构 *
TiDB 整体架构如下:
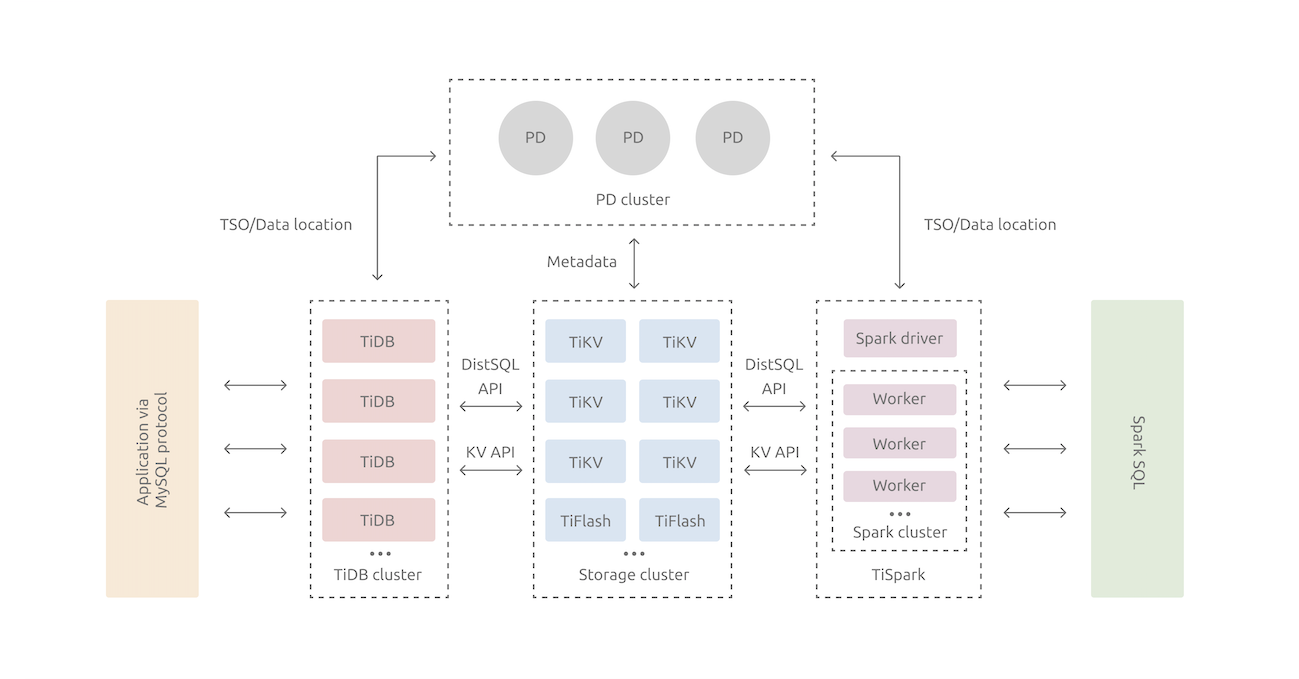
- TiDB Server:SQL 层,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。
- 存储节点
- TiKV Server:一个 Key-Value 的数据 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
TiKV
概述
TiKV 使用 kev-value 的数据格式存储数据,并且按照 key 的二进制顺序排列。
而 key-value 数据则是存储在 RocksDB 中(Meta开源的一个单机KV存储引擎:详见RocksDB 概览),通过RocksDB将数据存储在磁盘上。
另外,TiKV 通过实现 Raft 协议将数据复制到多台机器上,保证分布式下的数据一致性。即每个数据变更都会称为一条 raft日志,通过raft的日志复制功能将数据同步到复制组的每个节点中。
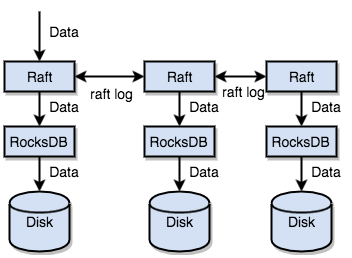
通过单机的 RocksDB,TiKV 可以将数据快速地存储在磁盘上;通过 Raft,将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,TiKV 变成了一个分布式的 Key-Value 存储,少数几台机器宕机也能通过原生的 Raft 协议自动把副本补全,可以做到对业务无感知。
数据分布方案 region
为了实现存储的水平扩展,数据将被分散在多台机器上。
将数据分散在多台机器上有两种比较典型的方案:
- Hash:按照 Key 做 Hash,根据 Hash 值选择对应的存储节点。
- Range:按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上。
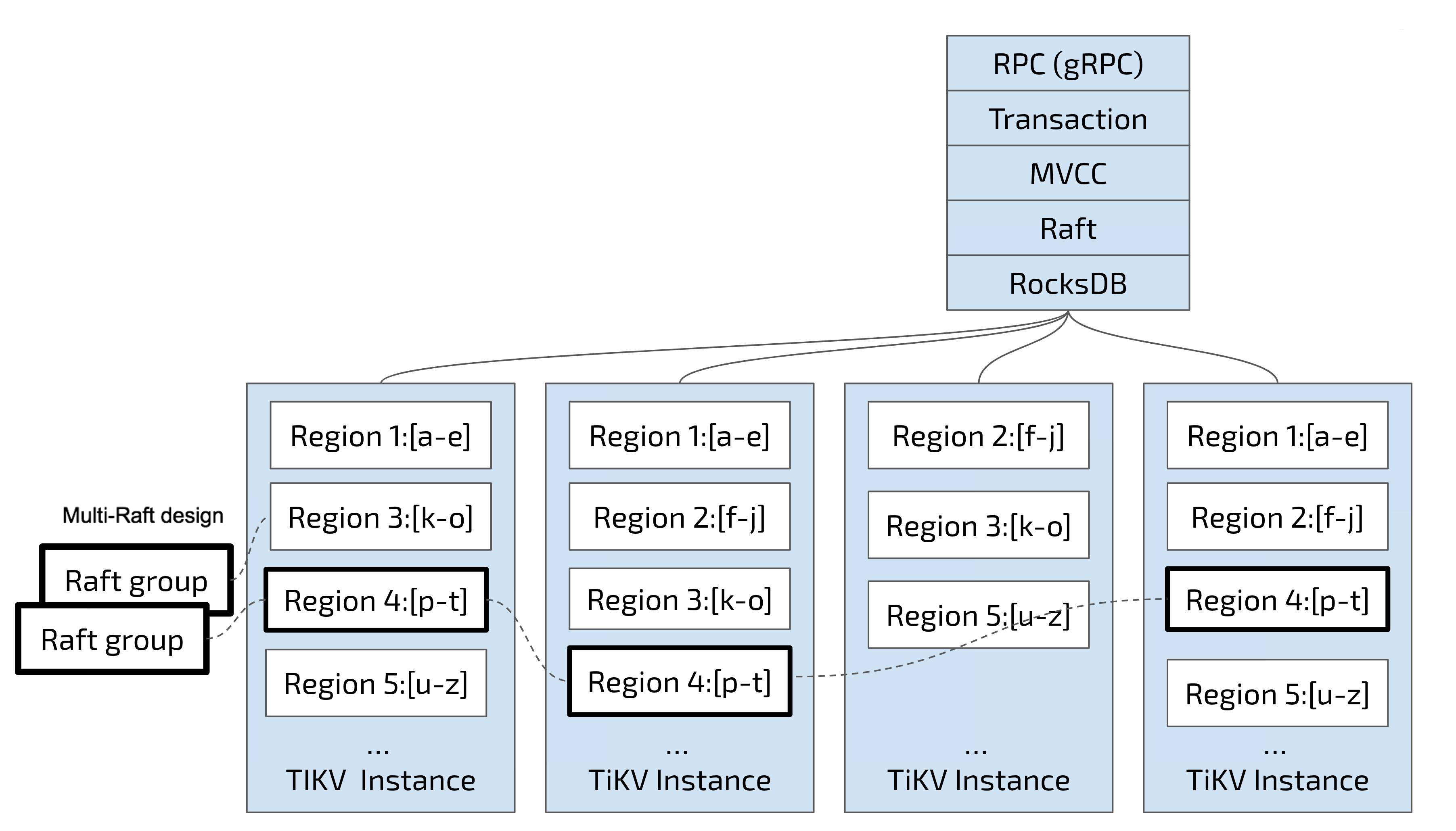
TiKV 使用 Range 的方式,将一个 key-value 分成多段,每段称为一个 region,每个region为一个左闭右开的区间,且不超过一定大小。
然后 tikv 数据分布和复制都是以 regin 为单位:
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多。
- 以 Region 为单位做 Raft 的复制和成员管理。
如图,TiKV 以 region 为单位做数据的分散和复制,从而实现一个分布式的具备一定容灾能力的keyValue系统。
表数据与 key-value 的映射关系
看完前面的内容后,我们对 TiKV 整个节点的存储有了大概的了解。但仍然不知道一张表在 tikv 中的实际存储情况。然后就从 key-value 结构来看看是怎么和表数据关联的。
表数据的key-values
TiDB 中 表数据和key-values的映射关系如下:
- 一行数据对应一个 key-value 键值对
- key 由 tableId 和 rowId 组成
- tableId 为 TiDB 为每个表分配的一个id
- rowId 为 TiDB 为每行分配的一个id,如果表存在整型主键,则取主键值作为rowid
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
// 其中 tablePrefix 和 recordPrefixSep 都是特定的字符串常量,用于在 Key 空间内区分其他数据。
索引数据 的 key-value
TiDB 同时支持主键和二级索引(包括唯一索引和非唯一索引)。与表数据映射方案类似,TiDB 为表中每个索引分配了一个索引 ID,用 IndexID 表示。
对于主键和唯一索引,需要根据键值快速定位到对应的 RowID,因此,按照如下规则编码成 (Key, Value) 键值对:
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: RowID
而对于不需要满足唯一性约束的普通二级索引,一个键值可能对应多行,为保证key的唯一性,所以key中添加了 rowid 信息:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID}
Value: null
通过将同一张表的数据和索引的key前缀都设计为一致,保证所有数据都排列在一起。
TiDB server *
TiDB 的 SQL 层,即 TiDB Server,负责将 SQL 翻译成 Key-Value 操作,将其转发给共用的分布式 Key-Value 存储层 TiKV,然后组装 TiKV 返回的结果,最终将查询结果返回给客户端。这一层的节点都是无状态的,节点本身并不存储数据,节点之间完全对等。
一个sql请求的流程如下:

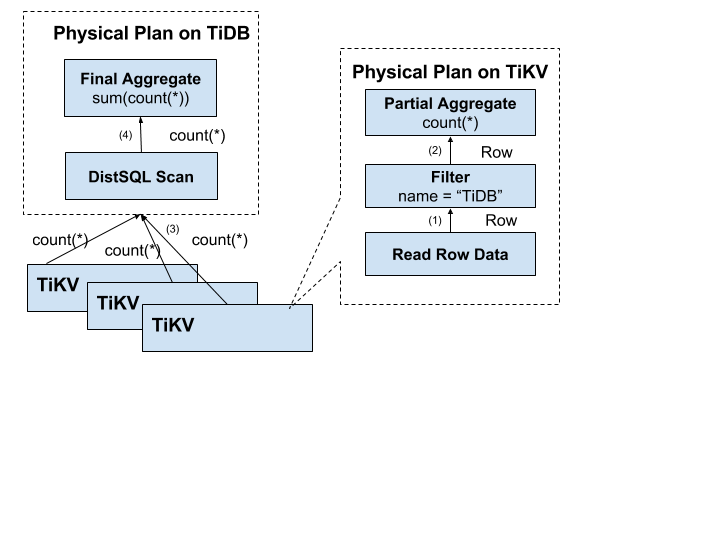
用户的 SQL 请求会直接或者通过 Load Balancer 发送到 TiDB Server,TiDB Server 会解析 MySQL Protocol Packet,获取请求内容,对 SQL 进行语法解析和语义分析,制定和优化查询计划,执行查询计划并获取和处理数据。
另外 TiDB 会将可以由存储层分担的计算下推给 TiKV 的协处理器(Coprocessor),计算单元仍然是以 Region 为单位。
一次查询中 TiDB 和 TiKV 的交互示例如下:
TiPD *
详细内容查看官方文档:TiDB 数据库的调度
PD (Placement Driver) 是 TiDB 集群的管理模块,同时也负责集群数据的实时调度。
TiPD 主要负责对集群的管理和数据分区的调度功能。
为了保证系统具备容灾、系统整体的资源利用率更高且合理、良好的扩展性,tipd 实现的功能有:控制副本的数量和分布、自动容灾、管理节点状态等。
tipd 会不断地收集tikv的信息,如每个TiKv节点的状态、Raft group信息、业务访问操作的统计等;然后根据调度策略,制定对应的调度计划,如增加、删除、迁移leader副本;将调度计划返回,region leader 再根据自身状态决定如何执行。
这里简单列举一些信息收集和调度策略的内容:
信息收集
- 每个 TiKV 节点会定期向 PD 汇报节点的状态信息
- TiKV 信息:总磁盘容量、可用磁盘容量、承载的 Region 数量、数据写入/读取速度、发送/接受的 Snapshot 数量(副本之间可能会通过Snapshot 同步数据)、是否过载、labels 标签信息
- 每个 Raft Group 的 Leader 会定期向 PD 汇报 Region 的状态信息
- Region信息:Leader 的位置、Followers 的位置、掉线副本的个数、数据写入/读取的速度
调度策略
- 一个 Region 的副本数量正确
- 一个 Raft Group 中的多个副本不在同一个位置
- 副本在 Store(TiKV) 之间的分布均匀分配
- Leader 数量在 Store 之间均匀分配
- 访问热点数量在 Store 之间均匀分配
- 各个 Store 的存储空间占用大致相等
- 控制调度速度,避免影响在线服务
事务
TiDB 支持分布式事务,提供乐观事务与悲观事务两种事务模式。TiDB 3.0.8 及以后版本,TiDB 默认采用悲观事务模式。
tidb 事务概览:https://docs.pingcap.com/zh/tidb/stable/transaction-overview
整体使用上和mysql查不多,有一些和mysql不同的是:
- 当tidb显示开启事务时,会立即获取当前数据库快照
- 执行 DML 语句时,乐观事务默认不会检查主键约束或唯一约束,而是在 COMMIT 事务时进行这些检查。
mvcc 多版本并发控制
TiKV 通过在 Key 后面添加版本号实现了 MVCC。
即一行数据实际上为
key_version2: value2
key_version1: value1
Key=tablePrefix{TableID}_recordPrefixSep{RowID}
Value=[col1, col2, col3, col4]
对于同一个 Key 的多个版本,版本号较大的会被放在前面,版本号小的会被放在后面。再通过 RocksDB 的 SeekPrefix(Key_Version) API,定位到第一个大于等于这个 Key_Version 的位置。
当开启事务后,tidb 从 pd 获取 一个全局唯一递增的时间戳 start_ts 作为当前事务的数据库快照版本,所以此时用户只能查到当前事务以前的数据。提交的时候,又重新获取一个 commit_ts 作为提交的 version。
备注:TiDB 同时提供了 GC 机制用于清理不需要的旧版本数据。具体可以查看官方文档: GC 机制简介
事务隔离级别
官方文档:TiDB 事务隔离级别
tidb 当前提供两种事务隔离级别:
可重复读
tidb 实现了快照隔离级别的一致性,又称为“可重复读”。
当事务隔离级别为可重复读时,只能读到该事务启动时已经提交的其他事务修改的数据,未提交的数据或在事务启动后其他事务提交的数据是不可见的。对于本事务而言,事务语句可以看到之前的语句做出的修改。
tidb在乐观模式下可重复读级别中的事务,不能并发的更新同一行,否则会在提交的时候报错回滚。
与 mysql 的区别:
- tidb乐观模式下,提交事务时发现数据已更新就会报错回滚;悲观模式下和mysql行为一致,更新时不检查数据版本(使用当前读).
读已提交
从 TiDB v4.0.0-beta 版本开始,TiDB 支持使用 Read Committed 隔离级别。
但 Read Committed 隔离级别仅在悲观事务模式下生效。
由于历史原因,当前主流数据库的 Read Committed 隔离级别本质上都是 Oracle 定义的 一致性读隔离级别。
与 mysql 的区别:
- MySQL 的 Read Committed 隔离级别大部分符合一致性读特性,但其中存在某些特例,如半一致性读 (semi-consistent read),TiDB 没有兼容这个特殊行为。 (innodb事务隔离级别)
乐观事务和悲观事务
tidb 提供了乐观事务和悲观事务两种事务模式,不过自 v3.0.8 开始,新创建的 TiDB 集群默认使用悲观事务模式。
手动修改事务模式的方法:
# 设置整个集群的新创建的显示事务为悲观事务
SET GLOBAL tidb_txn_mode = 'pessimistic';
# 显示开始悲观事务
BEGIN PESSIMISTIC;
BEGIN OPTIMISTIC;
BEGIN /*T! PESSIMISTIC */;
乐观事务
乐观事务模型下,将修改冲突视为事务提交的一部分。因此并发事务不常修改同一行时,可以跳过获取行锁的过程进而提升性能。但是并发事务频繁修改同一行(冲突)时,乐观事务的性能可能低于悲观事务。
官方文档:TiDB 乐观事务模型
TiDB 中乐观事务使用两阶段提交协议,流程如下:
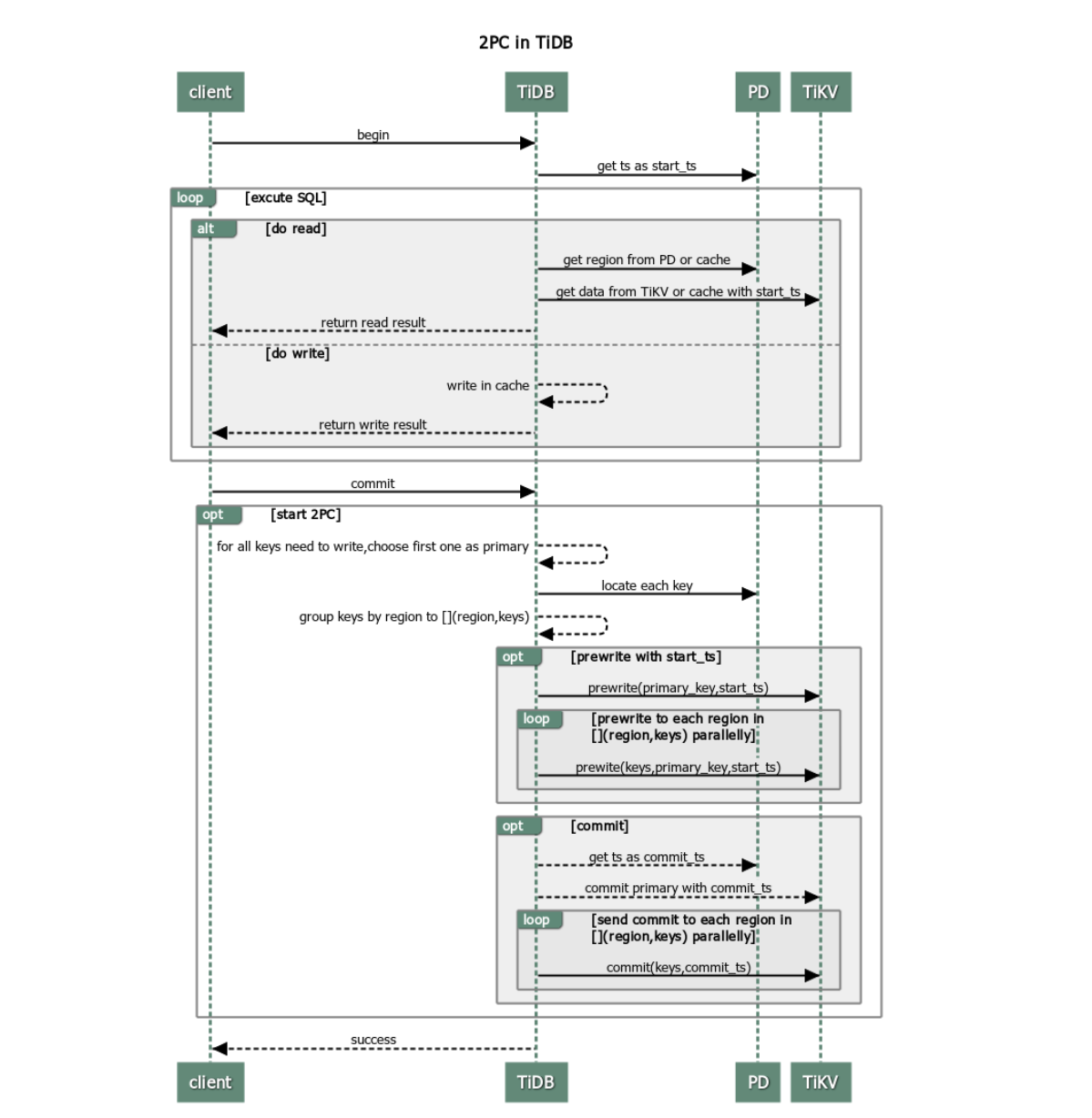
图中大概流程如下:
- 客户端开启事务:
- 从 PD 获取当前事务id 作为 start_ts
- 客户端发起读请求:
- TiDB 从 PD 获取 region 位置,
- 并使用 start_ts 从对应 TiKV 读取数据
- 客户端发起写请求
- TiDB 校验数据,通过的写入TiDB改事务的私有内存中。
- 客户端发起 commit
- TiDB 开始两阶段提交,保证事务的原子性前提下,进行持久化
- TiDB 从当前事务要写的 Key 任选一个作为 primary key
- TiDB 从 PD 获取所有数据的路由信息(region所在位置),并按照路由进行分类。
- TiDB 向对应 TiKV 发起 prewrite 请求, TiKV 收到后, 检查数据版本信息,符合条件的加锁
- TiKV 收到所有 TiKV 所有 prewrite 响应且成功
- TiDB 从 PD 获取第二个版本号 作为 commit_ts
- TiDB 向 Primary Key 所在 TiKV 发起第二阶段提交。TiKV 收到 commit 操作后,检查数据合法性,清理 prewrite 阶段留下的锁。
- TiDB 收到两阶段提交成功的信息。
- TiDB 向客户端返回事务提交成功的信息。
- TiDB 异步清理本次事务遗留的锁信息。
为什么这里有两个版本号(start_ts 和 commit_ts):
- 个人理解:为了支持可重复读。如果只用一个start_ts 的话,在commit 前新开启的事务可能会读取到不同版本的数据(事务1开启-> 事务2开启 & 读数据 -> 事务1提交 -> 事务2又读数据, 前后不一致,不可重复读。),事务隔离级别变成了读已提交。
悲观事务
TiDB 悲观锁复用了乐观锁的两阶段提交逻辑,重点在 DML 执行时做了改造。在两阶段提交之前增加了 Acquire Pessimistic Lock 阶段。 (下图红框部分)
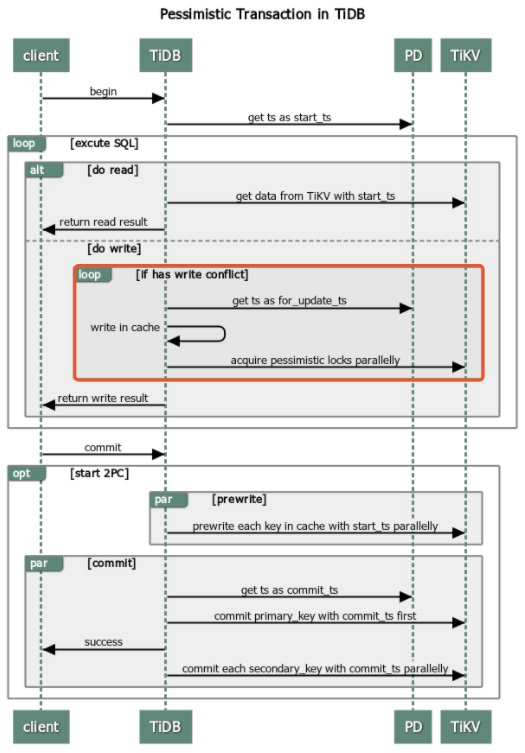
具体流程就不再赘述了,感兴趣可以参考文档:TiDB 悲观锁实现原理
悲观事务模式的行为
tidb事务悲观锁行为和mysql基本一致,也存在一些差异。
详见文档:TiDB 悲观事务模式
例如悲观事务行为有(仅举例,不全):
- DML 语句读取已提交的最新行来执行,并加悲观锁
- select for update 对已提交的最新数据加锁
- 如果多个事务尝试获取各自的锁,会出现死锁,并被检测器自动检测到 (文档:TiDB 锁冲突问题处理 )
- 等等等
差异:
- tidb 不支持 gap lock 间隙锁。 对于where子句中使用了range的语句,不会阻塞range内并发的dml语句执行。
- TiDB 不支持 SELECT LOCK IN SHARE MODE。 使用无效。
- autocommit 事务优先采用乐观事务提交。
- 等等等
pipelined 加锁流程
pipelined 加锁流程:当数据满足加锁要求时,TiKV 立刻通知 TiDB 执行后面的请求,并异步写入悲观锁,从而降低大部分延迟,显著提升悲观事务的性能。

当 TiKV 出现网络隔离或者节点宕机时,悲观锁异步写入有可能失败,从而产生以下影响:
- 无法阻塞修改相同数据的其他事务。如果业务逻辑依赖加锁或等锁机制,业务逻辑的正确性将受到影响。
- 有较低概率导致事务提交失败,但不会影响事务正确性。
如果业务逻辑依赖加锁或等锁机制,或者即使在集群异常情况下也要尽可能保证事务提交的成功率,应关闭 pipelined 加锁功能。
推荐文章:TiDB 新特性漫谈-悲观事务
其他
explain 执行计划
和 mysql 一样,tidb 也支持使用 explain 查询执行计划。
EXPLAIN SELECT * FROM t WHERE a = 1;
+-------------------------------+---------+-----------+---------------------+---------------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------------+---------+-----------+---------------------+---------------------------------------------+
| IndexLookUp_10 | 10.00 | root | | |
| ├─IndexRangeScan_8(Build) | 10.00 | cop[tikv] | table:t, index:a(a) | range:[1,1], keep order:false, stats:pseudo |
| └─TableRowIDScan_9(Probe) | 10.00 | cop[tikv] | table:t | keep order:false, stats:pseudo |
+-------------------------------+---------+-----------+---------------------+---------------------------------------------+
3 rows in set (0.00 sec)
EXPLAIN 实际不会执行查询。EXPLAIN ANALYZE 可用于实际执行查询并显示执行计划。如果 TiDB 所选的执行计划非最优,可用 EXPLAIN 或 EXPLAIN ANALYZE 来进行诊断。
explain 解读
EXPLAIN 的返回结果包含以下字段:
- id 为算子名,或执行 SQL 语句需要执行的子任务。
- estRows 为显示 TiDB 预计会处理的行数。该预估数可能基于字典信息(例如访问方法基于主键或唯一键),或基于 CMSketch 或直方图等统计信息估算而来。
- task 显示算子在执行语句时的所在位置。
- access-object 显示被访问的表、分区和索引。显示的索引为部分索引。以上示例中 TiDB 使用了 a 列的索引。尤其是在有组合索引的情况下,该字段显示的信息很有参考意义。
- operator info 显示访问表、分区和索引的其他信息。
tikv 层算子示例
- TableFullScan:全表扫描。
- TableRangeScan:带有范围的表数据扫描。
- TableRowIDScan:根据上层传递下来的 RowID 扫描表数据。时常在索引读操作后检索符合条件的行。
- IndexFullScan:另一种“全表扫描”,扫的是索引数据,不是表数据。
- IndexRangeScan:带有范围的索引数据扫描操作。
算子执行顺序
算子的结构是树状的,但在查询执行过程中,并不严格要求子节点任务在父节点之前完成。TiDB 支持同一查询内的并行处理,即子节点“流入”父节点。父节点、子节点和同级节点可能并行执行查询的一部分。
Build 总是先于 Probe 执行,并且 Build 总是出现在 Probe 前面。
关于 tidb 具体的执行计划可以查看官方文档:
tidb 调优:follower read
Follower Read 功能是指在强一致性读的前提下使用 Region 的 follower 副本来承载数据读取的任务,从而提升 TiDB 集群的吞吐能力并降低 leader 负载。Follower Read 包含一系列将 TiKV 读取负载从 Region 的 leader 副本上 offload 到 follower 副本的负载均衡机制。TiKV 的 Follower Read 可以保证数据读取的一致性,可以为用户提供强一致的数据读取能力。
相关文档:Follower Read
关于性能
参考官方性能测试报告: TiDB Sysbench 性能对比测试报告 - v5.0 对比 v4.0
另关于 TiDB 和 MySQL 性能对比:
TiDB 设计的目标就是针对 MySQL 单台容量限制而被迫做的分库分表的场景,或者需要强一致性和完整分布式事务的场景。它的优势是通过尽量下推到存储节点进行并行计算。对于小表(比如千万级以下),不适合 TiDB,因为数据量少,Region 有限,发挥不了并行的优势。其中最极端的例子就是计数器表,几行记录高频更新,这几行在 TiDB 里,会变成存储引擎上的几个 KV,然后只落在一个 Region 里,而这个 Region 只落在一个节点上。加上后台强一致性复制的开销,TiDB 引擎到 TiKV 引擎的开销,最后表现出来的就是没有单个 MySQL 好。
与msyql一些兼容性
TiDB 高度兼容 MySQL 5.7 协议、MySQL 5.7 常用的功能及语法。
TiDB 不支持 MySQL 复制协议,但提供了专用工具用于与 MySQL 复制数据
参考:与MySQL兼容性对比

















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









