









Spark是一种强烈依赖内存的计算框架,结合其运行流程,可以有很多可以调优的地方
用reduceByKey 替代groupByKey
这两个转换都有shuffle过程发生,且都类似map reduce,但是reduceByKey会在map阶段会对相同的key进行聚合,极大的减少了map产生的数据量,进而减少了shuffle的数据量,提高了程序的执行效率
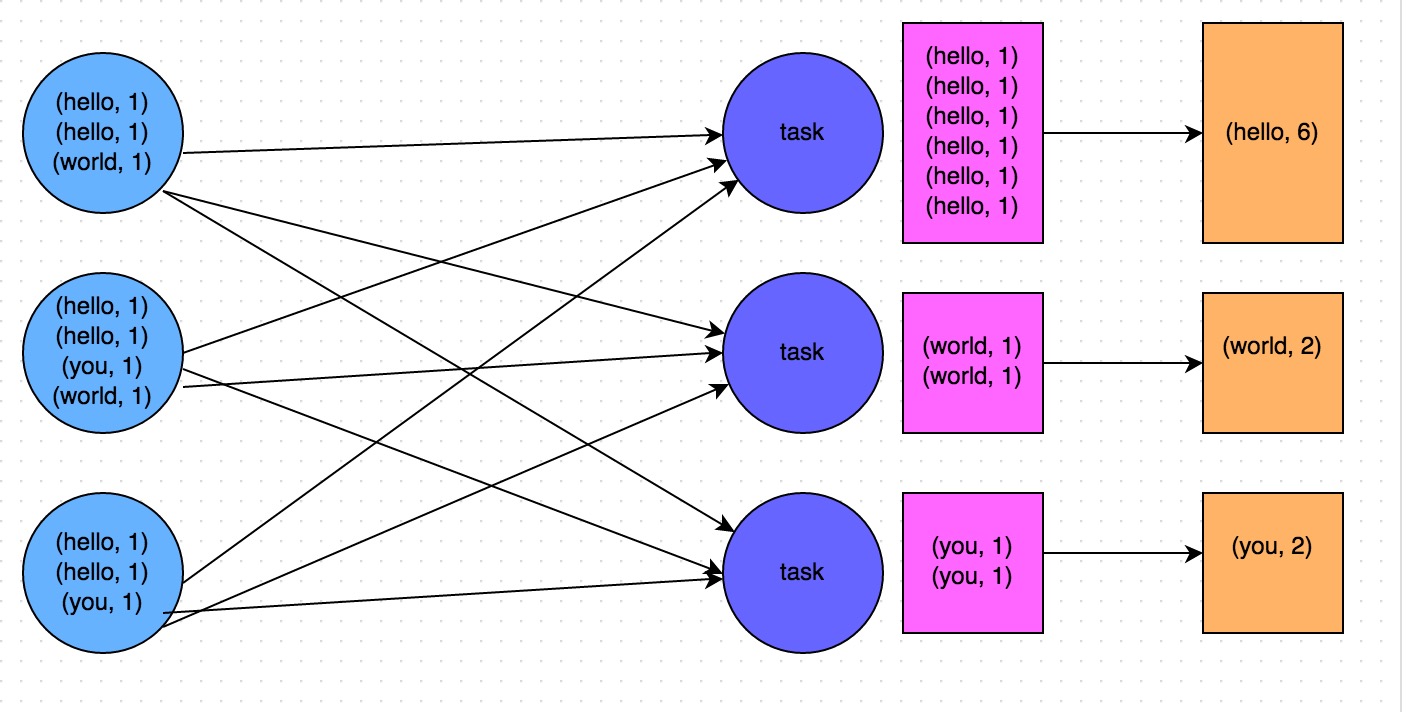
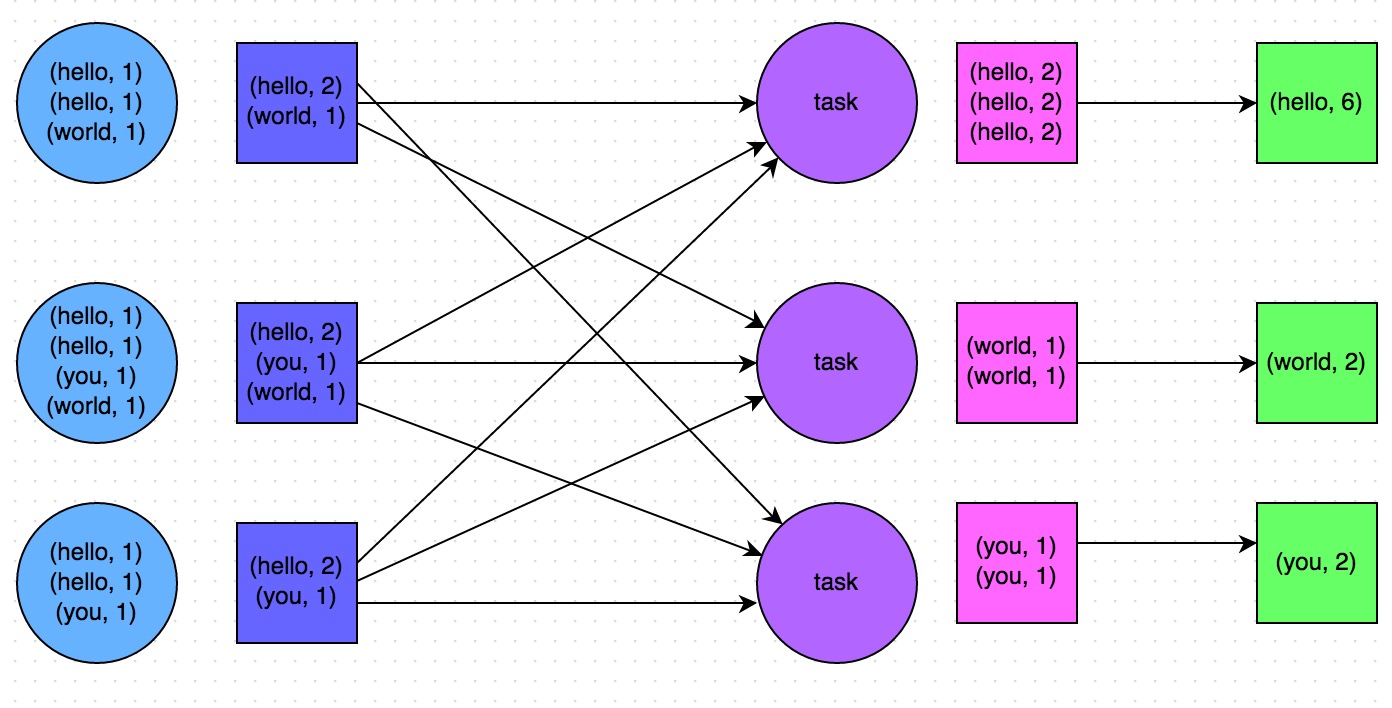
避免shuffle
shuffle类算子会将多个节点的key,拉取到一个节点上,进行join或者聚合操作,代价很大。
关于缓存
如果一个rdd被多个rdd依赖,就要持久化该rdd,避免被生成多次,而持久化时又有一些小技巧,如下
用persist(MEMORY_ONLY_SER) 代替persist和cache
persist的默认持久化类型是MEMORY_ONLY,该类型在内存中会缓存原始的对象,而MEMORY_ONLY_SER将对象序列化后再缓存,这样会节省大量的内存。因为Spark模型的各个阶段都会耗内存,而且现在计算的瓶颈一般不在CPU而在IO上,节省了内存。会让Spark其他阶段拥有更多的内存,从而减少了和磁盘的交互,进而加快作业的执行速度
内存不够时
内存不够时,使用 MEMORY_AND_DISK_SER
避免使用DISK_ONLY和后缀为_2的持久化方式
DISK_ONLY将rdd缓存在磁盘上,基于磁盘的读写会严重影响性能
后缀为_2的持久化方式,会将rdd复制一份副本,发送到其他节点上,数据复制和网络传输的性能开销较大
使用Kryo序列化
该种序列化方式会比默认的java序列化方式节省2到5倍的空间
分解一个job之中的transformation
尽量避免在一个transformation中处理所有的逻辑, 尽量分解成map, filter等之类的操作,这样程序会更容易理解
调低spark.memory.fraction
如果因为GC导致outofmemory,很可能是老年代的内存较小,可以调低该参数
包冲突
- 将spark自带的包设置成provided,这样就可以使用spark内核自带的相应类
- spark自带了很多包,比如org.json4s, guava等,因为这些包升级时没做向前兼容性,如果用户自己引入了这些包,很可能产生运行时异常。这个时候,有两种方式处理:不使用这些包,这样就将雷跳过去了;使用shade打包,改变包的名字,也可以将雷跳过去
yarn-client
选择了yarn-client模式, 因此是默认没有开启本地Driver的gc log的, 为了更好应对出错时debug, 建议在本地export 因此是默认没有开启本地 Driver 的 gc log 的, 为了更好应对出错时 debug, 建议在本地 export
SPARK_SUBMIT_OPTS=" -Xloggc:tmp/gc_log -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCDetails -XX:+PrintGCDateStamps -verbose:gc -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10M " - 查看调试信息
spark-submit --verbose 














 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









