




 本文介绍了如何安装libsvm,并通过实例展示了libsvm在简单分类问题中的使用。首先,从libsvm官网下载并解压,将libsvm.dll放入系统目录,将python模块放入python安装路径。然后,通过svm-toy.exe演示分类过程。接着,讲解了libsvm数据格式,并提供了将数据转换为libsvm格式的方法。最后,展示了使用python接口训练模型和进行预测的步骤,以及使用svm-train和svm-predict命令行工具生成模型和进行预测的过程。
本文介绍了如何安装libsvm,并通过实例展示了libsvm在简单分类问题中的使用。首先,从libsvm官网下载并解压,将libsvm.dll放入系统目录,将python模块放入python安装路径。然后,通过svm-toy.exe演示分类过程。接着,讲解了libsvm数据格式,并提供了将数据转换为libsvm格式的方法。最后,展示了使用python接口训练模型和进行预测的步骤,以及使用svm-train和svm-predict命令行工具生成模型和进行预测的过程。
使用libsvm进行简单分类
参考:http://blog.csdn.net/xuxiatian/article/details/53736549
https://www.cnblogs.com/codingmengmeng/p/6256382.html
http://blog.csdn.net/u013634684/article/details/49646311
http://blog.csdn.net/longxinchen_ml/article/details/50521933
1.安装:
先从libsvm官网下载并解压,得到这个。
本来想在vs2015上编译运行libsvm,结果不行,所以最后就以python和exe的方式来使用libsvm。
我忘记了在那里看到的一篇文章说要用vs的命令行工具将libsvm.dll重新编译成64位系统可使用的动态链接库,我之前编译完了,所以我把64位系统可用的libsvm.dll上传到百度云上,需要的同学可以下载一下。
链接: https://pan.baidu.com/s/1c3Ok6wo 密码: uk4m
下载完之后要把这个libsvm.dll拷贝到 C:\Windows\System32 目录下。
另外,以python的方式使用libsvm非常方便,所以我将 libsvm-3.22\python 目录下的 svmutil.py 和 svm.py 拷贝到我python安装目录下的 Lib\site-packages 里面,然后尝试导入svm,成功即可调用它的功能了。
from svmutil import *
from svm import *作为新手的我对libsvm的基本配置就到这里了,接下来是学习如何使用它。
2.使用:
进入 libsvm-3.22\windows 文件夹下有一个 svm-toy.exe 的演示,你可以变换颜色地在背景上添加点,最终svm会将你不同的颜色的点划分出一个分类边界出来。

这个是基本演示,但是作为学习,我们应当学会如何使用libsvm这个工具来对我们自己的数据进行分类,生成模型然后来使用。
那接下来看看,如何简单使用libsvm,我觉得数据格式很重要,所以先看看libsvm处理的数据的格式:
(这个是主目录下的样例heart_scale的片段)
+1 1:0.708333 2:1 3:1 4:-0.320755 5:-0.105023 6:-1 7:1 8:-0.419847 9:-1 10:-0.225806 12:1 13:-1
-1 1:0.583333 2:-1 3:0.333333 4:-0.603774 5:1 6:-1 7:1 8:0.358779 9:-1 10:-0.483871 12:-1 13:1
+1 1:0.166667 2:1 3:-0.333333 4:-0.433962 5:-0.383562 6:-1 7:-1 8:0.0687023 9:-1 10:-0.903226 11:-1 12:-1 13:1
-1 1:0.458333 2:1 3:1 4:-0.358491 5:-0.374429 6:-1 7:-1 8:-0.480916 9:1 10:-0.935484 12:-0.333333 13:1
-1 1:0.875 2:-1 3:-0.333333 4:-0.509434 5:-0.347032 6:-1 7:1 8:-0.236641 9:1 10:-0.935484 11:-1 12:-0.333333 13:-1
-1 1:0.5 2:1 3:1 4:-0.509434 5:-0.767123 6:-1 7:-1 8:0.0534351 9:-1 10:-0.870968 11:-1 12:-1 13:1
+1 1:0.125 2:1 3:0.333333 4:-0.320755 5:-0.406393 6:1 7:1 8:0.0839695 9:1 10:-0.806452 12:-0.333333 13:0.5
+1 1:0.25 2:1 3:1 4:-0.698113 5:-0.484018 6:-1 7:1 8:0.0839695 9:1 10:-0.612903 12:-0.333333 13:1
+1 1:0.291667 2:1 3:1 4:-0.132075 5:-0.237443 6:-1 7:1 8:0.51145 9:-1 10:-0.612903 12:0.333333 13:1
以一行为例:
-1 1:0.458333 2:1 3:1 4:-0.358491 5:-0.374429
第一个数字是种类,代表这一行特征是属于哪一个类别的,接下来的1:0.458333 是指第一个特征的数值是0.458333, 依此类推,2:1 代表第二个特征的数值是1。
所以它所有的样本都是以这种形式为数据源,所以不论是训练数据或测试数据都是用这种形式的(修改源代码的方式另当别论),因为刚开始学习,所以我都是用python将自己的数据格式更改成libsvm规定的格式来进行使用。
libsvm的python使用很简单:
from svmutil import *
from svm import *
y, x = svm_read_problem('train.txt')
yt, xt = svm_read_problem('test.txt')
model = svm_train(y, x ) #利用训练数据生产模型
p_label, p_acc, p_val = svm_predict(yt, xt, model) #利用模型预测测试数据optimization finished, #iter = 5289
nu = 0.109058
obj = -6694.758270, rho = 3.652696
nSV = 8729, nBSV = 8719
Total nSV = 8729
Accuracy = 98.565% (19713/20000) (classification)
其中:
iter为迭代次数
nu 与前面的操作参数-n nu 相同,
obj为SVM文件转换为的二次规划求解得到的最小值,
rho 为判决函数的常数项b,
nSV 为支持向量个数,
nBSV为边界上的支持向量个数,
Total nSV为支持向量总个数(对于两类来说,因为只有一个分类模型 Total nSV = nSV ,但是对于多类,这个是各个分类模型的 nSV 之和)。
刚开始我只看得懂Accuracy = 98.565%,这些参数的优化的部分还没掌握,预计快了。
因为以前学习了线性分类器以及简单隐层对数据的分类,对于分类的思想有一定的理解。
以螺旋形的两种分类为例:
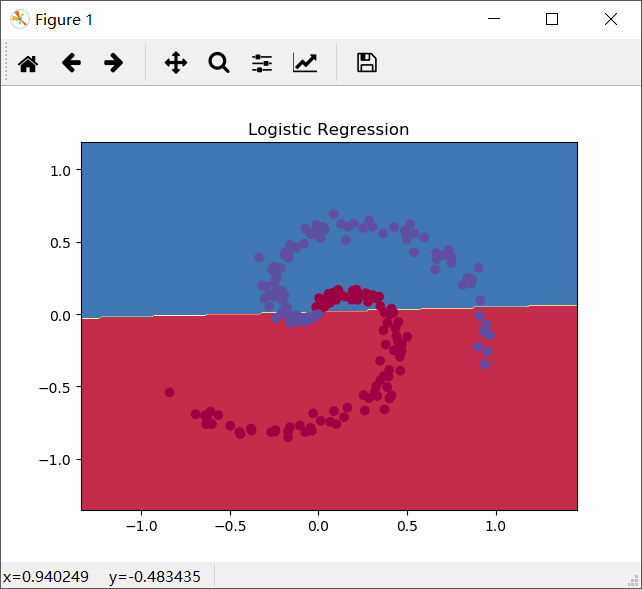
线性分类的相应的python代码如下:
#http://blog.csdn.net/u013634684/article/details/49646311
import numpy as np
from sklearn.linear_model import LogisticRegressionCV
import matplotlib.pyplot as plt
def spiral_line(K,N):
np.random.seed(1)
X = np.zeros((N*K,2))
y = np.zeros(N*K, dtype='uint8')
for j in xrange(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N)
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









