






1、找到价值
对于任何平台,一个问题是,其核心价值是什么?
应用的高可用、灵活、高性能。
K8s在谷歌的前身,是一套集群管理的系统叫Borg。容器是一个个的独立个体,要跑一个容器应用,一定要有一个东西来做housekeeper,来管控它。如果应用出现故障,应该有一种方法来做资源管控,做整个应用的生命周期管理,如果失败了,要重启等等这些机能,这就是Borg需要去解决的问题。
Borg本身是一个集群管理加一个作业调度的平台,它要支持很多灵活调度的策略。有了Borg系统,能实现应用的高可用和高可靠。它把很多基础架构层面的东西隐藏起来了,这也是云的价值。
云的理解,把它简单理解为把计算资源抽象出来,对应用开发人员或者应用这个云平台的使用者,只要去描述要跑哪个作业即可。
云上运行业务,可以通过Docker把业务build成一个个容器镜像,容器镜像里面,第一,可以定义运行时要跑哪些应用,第二,定义资源需求。然后把这个请求发给某一个云平台,剩下的事情交给云平台,云平台帮你去做调度。
云的优势,就是它把所有硬件的底层相关的资源都抽象出来了,对用户来讲,只需要告诉它你要跑什么作业,需要多少资源,它帮你去处理所有的东西。这也是Borg追求的目标和它的优势。
2、理解原理和机能
Borg 管理谷歌的整个数据中心。
谷歌有两类大的应用,一类叫做Product workload; 一类叫做non product workload。
Product workload就是我们日常所熟知的在线的服务,比如web search。它的特性是这些应用永远在线。提供任何在线业务所追求的终极目标就是它的可用性,即任何用户来访问,它都在提供服务。这是一个最基本的需求。
Non- Product workload是批处理应用。比如电信银行要做对账,账单的处理是批处理行为,比如要对一些用户的日志做行为分析等等,都是批处理业务。它的特性是实时性要求不高,但是很耗资源,所以这种作业就是有资源就跑一跑。如果Product workload需要资源了,就可以把我的资源先临时让给你,等你空闲了以后我再继续跑。
i、资源利用率
通过在线应用和离线应用混布的手段,保证整个集群资源利用率很高。
在Borg里面有一个Cell的概念, Cell就是一个集群,一个数据中心可能有10万台机器,需要把这些机器化成一个个的逻辑单元,可能是5000台或者1万台。
为什么这么划分?
第一,因为集群规模支撑的上限是有限的,集群规模越大,越意味着集群控制面所做的计算越大。要提升性能,要做一定的切分
第二,因为故障率的控制。要把集群分成一个小的逻辑单元,带来的好处就是控制面Down的话,只有一部分机器死了。
ii、自动化运维
K8s和Borg被应用的原因一样,相对于虚拟机的一些问题,而启用的云机能,比如虚拟机缺少全自动化,如果一个instance虚机坏了,需要把这个虚拟机下架,要起一个新的虚拟机,要把应用部署到这台虚机上,让应用起好,然后一点点去测新应用没有问题,再把它跟之前的那台整个替换才完成。这样就会涉及到大量人工操作,使得整个应用的维护成本非常高。
自己维护平台,所有这些维护工作加业务逻辑都得写,成本是很大的。
Borg这样的系统,它跟OpenStack的区别是什么?
最核心就是调度的不是虚机,是目标实体,就是你的作业,是某一个应用。
通过模型抽象,就使得从开发到基础架构能知道这台机器上跑了哪些应用,就可以做很多自动化的功能。
自动化运维就是云的最大特征。
iii、应用高可用
怎么确保应用高可用?最常见的手段就是冗余部署。
这时要考虑故障率。无论在Borg,在K8s里面都有多种范围,比如主机、机架、可用区、数据中心等等。
要控制故障率,就要考虑清楚哪一个是控制面,哪一个是数据面。
控制面要控制的是什么?要保证平台上面跑的应用的高可用。比如跑了一个web server,Borg是可以死的,但是 web server不能死,所以是确保应用的高可用,就是数据面所运行的应用是非常非常重要。作为一个平台,平台出现故障,平台可以维护,但是上面跑的应用不能维护,所以第一目标是保证这些应用的高可用。作为一个云平台,永远要追求自己应用平台的高可用。
当然,万一Borg死了,所有请求、所有的变更都不能做了,很可能同时引发数据面的问题,所以同时要追求自身的高可用。
iv、资源调整
Borg还会做对于每个应用的资源调整。
它允许定资源,比如要了10个CPU,但是应用是单线程的,Borg会做监控,在这个应用启动后,它监控发现实际的资源没有用到你设定的那么多资源,就会给你压缩,这样就提升整个资源利用率。压缩以后,会一直扫描计算,确保把剩下的资源空出去,再给别的应用使用。
K8s也遵循了以上这些机能。
K8s在解决哪些问题?
第一个,应用的部署维护和滚动升级
随时随地都可以做升级,怎么做升级?发布滚动升级,相当于一个应用先跑三个版本,三个实例。在做升级的时候,一个个滚动着升级,这样对用户来说是无感知的,悄悄地就把版本换掉了,用户是不知道的。
第二个,负载均衡、服务发现、自动伸缩等自动化能力
在任何一个云平台发布服务,别人要访问你,你要访问别人。为高可用用了冗余部署以后要去做负载均衡。当一个请求过来,把请求丢给一个真实的后端,跨故障域的集群调度,跨机器、跨地区,两地三中心完成生产应用的部署,自动伸缩等。以前都是手工操作,在K8s,很简单一条命令就行了。会去监控应用的CPU、 memory、 qps等等metrics,如果超过你设置的阈值,会自动做个伸缩,可以做横向扩展,可以做纵向扩展。
把从前非常多花费运维成本的工作,现在都通过K8s自动化了。
K8s和OpenStack的最大区别
最重要的一点差异就是:K8s是一个声明式系统。
怎么理解声明式?它可以基于设定的要求和上一次的实施反应来决定下一步应该怎么操作。是一个互动式的interactive方式。
所谓申明式系统,是把你的请求提交给平台,平台记录下来,在后台慢慢的调整这个系统的真实状态到跟你的请求期望状态一致。
对于平台来说,与命令式系统相比,声明式系统有什么样的好处?
第一,命令式系统是有顺序的。
第二,命令式系统前后是有依赖的。
很少人会把所有参数每一步骤都记下来,所以命令式系统比较大的困难是到后期,想追溯历史状态是很难的。
比如数据中心,我们知道一个机器变成这个样,或者一个应用现在长得这样,但是他怎么变成这样,没人能说得清楚。然后能不能动不知道,因为也不知道它为什么变成今天这样了,到最后是这个东西放在那跑着,ok的,谁敢动吗?没人敢动。这就是以前系统的弊端。
对于K8s声明式系统的解决之道:
第一点,提供API方式接受和存储声明,
这些API接受的是你的声明,可以把你的期望状态告诉它,它把期望状态存到它的数据库里面,相当于做了持久化,就可以追溯历史。任何时候看最终的系统,能知道它是怎么来的,能知道在任何时间点系统是长什么样的,可以追溯的。
第二点,声明交由系统自动异步执行,应用无需等待,
告诉系统期望值,系统会一直去尝试,直到满足用户的需求。同时系统只要告诉用户,接收到这个请求就好了。对于客户端,是一个非阻塞的运行过程,应用就可以做别的事情了。
这样方式有助于提高整个平台或者整个生态系统的效率。
K8s除了有一个声明式系统,同时它跟业界的各个公司一起定规范,形成了一个统一的API,这套API就是云原生的统一API。
K8s通过声明式API把云计算的整个领域所有对象都定义好了,要管控的资源都定义好了。相当于定义好了一些约定,这些约定意味着大家都适配,那么将来要改造,成本巨大,不会有人有驱动力再去把它推掉重建的,一定是在这个基础之上不断的去更新。
K8s标准对象
第一个,Node,计算节点,
它是资源抽象,描述资源的capacity是多少,有多少计算能力,比如最多有多少CPU,多少memory,有多少可以再分配的资源,健康状况是ready还是military等等健康状况。用来代表计算节点的实体。
第二个,Namespace,其实是个文件目录,
把它理解为文件系统中的目录结构。对于不同的用户,可以通过权限控制来决定a用户只能访问namespace A,b用户只能访问namespace B。相当于做资源隔离,通过权限控制,可以把namespace分离,不同的用户可以在自己的namespace里操作有权限一些资源。
第三个,Pod,作业的基本调度单位
理解K8s可以从几个层面去理解,第一个是集群管理,就是它对计算节点的管理,所以通过node把这些节点都抽象出来,相当于把这些node变成一个集群。第二个是功能层面的作业调度,就是要跑一个应用,这个应用要跑什么进容器镜像,需要多少资源,这种实力用Pod来描述。
Pod是一个调度的基本单位。用来满足云平台的作业调度。
pod还有丰富的状态控制。可以控制pod的状态,能不能take traffic,能不能提供服务,通过Pod这种对象的应用,就可以把应用和基础架构两个层面的角色打通了。
K8s最厉害的地方是什么?基础架构和应用是互相能够感知的。
通过什么资源或者API去感知?就是通过Pod。
第四个,Service,服务发现
通过service对象来定义跑一个应用。定义了一堆Pod跑应用,别人应该怎么来访问,就是通过service方式去访问。
service本质上是去配负载均衡和提供域名服务。
K8s架构
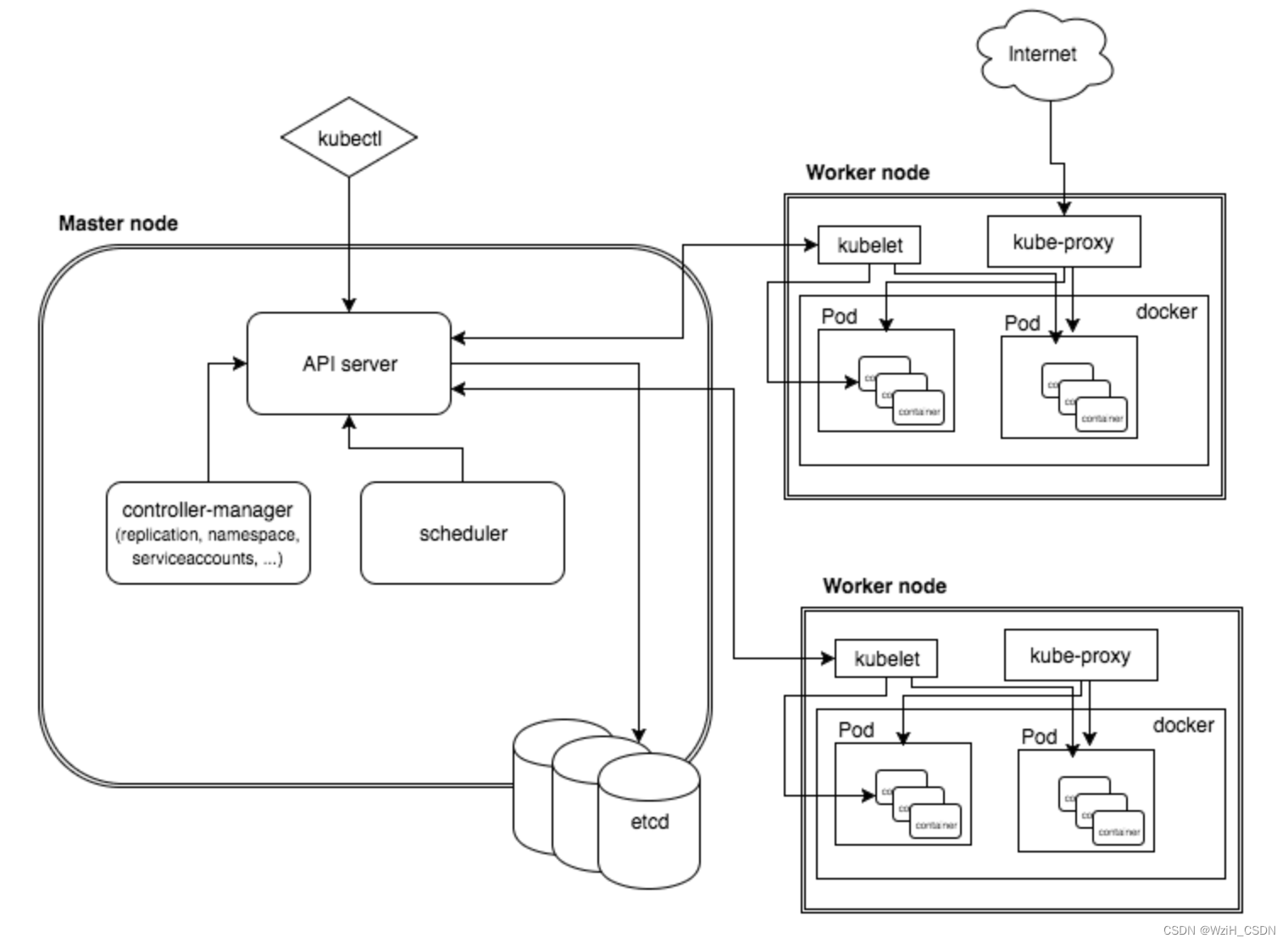
对于集群,会把一部分节点作为master节点,作为管理界面,剩下的所有节点作为workload。
在master节点上面有几个重要的组件:
第一个,API server。
API server是什么?
它是整个云平台的API网关,API server就是集群的入口。
它做什么呢?
用来接受用户的请求,并且支持所有控制做交互。是整个集群的核心组件,大家都跟他通信。
在API server后端接收到请求以后做什么呢?
它把用户请求保存下来,存在分布式数据库ETCD。
这两个组件是静态的,没有任何行为触发。
第二个,Scheduler,调度器。
有任何用户建了Pod发到API server里边, Scheduler会看到有一个新的Pod创新了,会去看这个Pod有没有做过调度,如果没有,就要去帮它调度;调度完后,数据也存到etcd里面。
第三个,Controller,控制器。
每一个控制器都会去做一些特定的动作,比如node controller会监控node的健康状况来决定是不是要做一些动作。比如service controller,建好了一个service后,是不是要分配负载均衡。比如namespace controller,当你删namespace的时候,会看你的namespace里面还有没有数据,如果有数据的话,应该先把内容清掉,再去清目录。
控制器里面是一堆控制器整合在一起,每一个控制器监控不同的对象,使得整个集群动起来。
第四个,Kubelet。
把Node上面的资源信息和健康状况上报到API server,
调度器完成调度以后,用户的Pod跟某个节点绑定好了,Pod里的容器应用要在机器上起,看本地是不是起了。
调度器,控制器,Kubelet,都是控制器的模式,来监控API server里面对象的变更,并完成相应的配置。
第五个,ETCD。
分布式存储,是一个分布式的配置管理,是key-value pair的存储,基于RAFT协议实现。
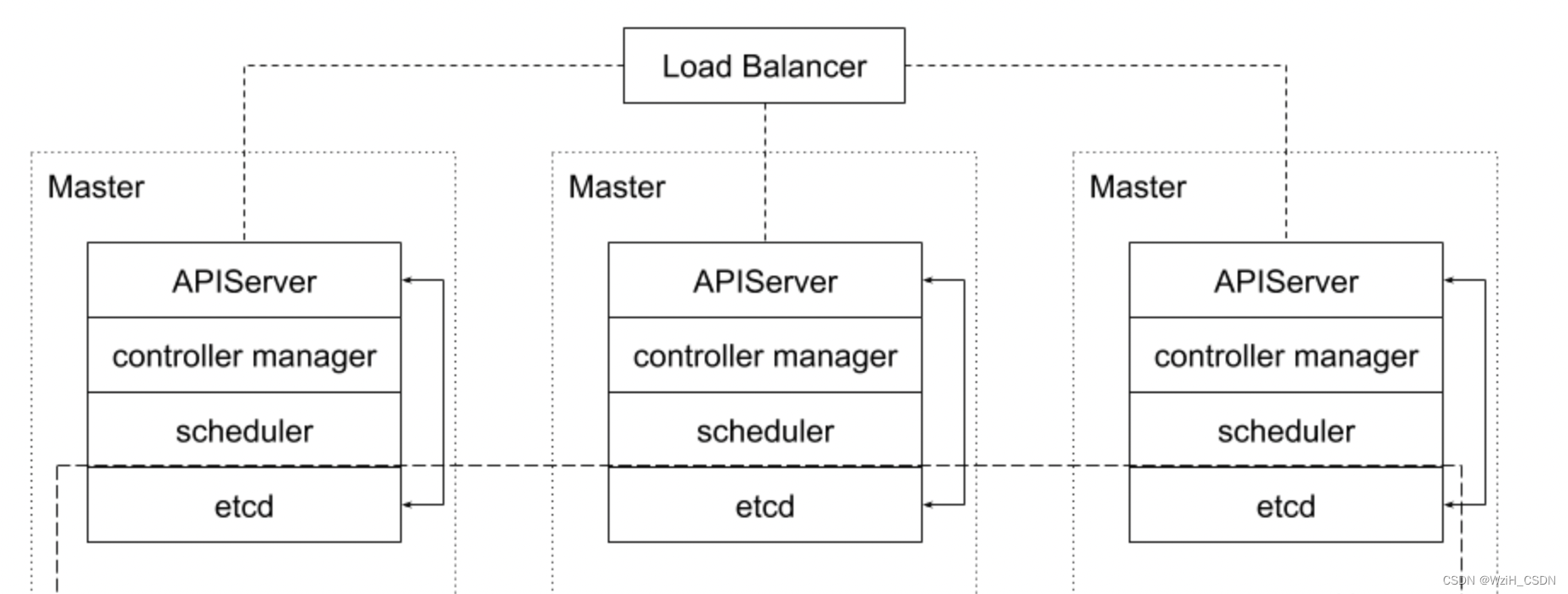
1,分布式的存储,怎么理解呢?
如:选三台机器冗余部署,这三台机器都是 master,在上面都去布etcd的instance,这三个instance组成一个etcd的集群。
有了这个集群要解决就是分布式的存储,要解决什么样的问题呢?
数据一致性的问题。
ETCD工作机制
etcd启动的时候,每一个member会有三种身份,第一种身份叫做follower,跟随者,就是我要听别人的话;第二种角色叫做leader我是发指令的那个;第三种角色叫做candidate,就是我这个时候又不是leader,又不是follower,作为candidate是要去投票,去拉票。为了通过这种协议,从里面选出一个主来,之后所有的写操作从主去写,其他要变成follower的角色听从主的吩咐。这就是etcd的工作机制。
确定了一个leader,数据就可以写入了。如果从接受了一个请求,它会把这个请求转到主,有任何写请求,到了主以后,主会把请求跟下次心跳一起发给从,然后从这边接收到请求以后,要存下这个 log,并且回给主,得到多数确认以后,多数人都已经确认了,主认为好了,这个数据写入完成,它再告诉client这次数据写入完成。
2,ETCD支持watch机制,怎么理解呢?
比如有一个watch操作,发给etcd的时候它会有两个行为,第一个行为是根据你的请求条件,返回当前的结果,并且不会断开client请求,保持长连接。接下来你的查询条件里面有任何数据变更,它会用event的方式推送给你,这个是etcp消息机制的一个非常非常重要的,用来确保整个集群的机制,确保集群大规模访问情况下,DB不垮,应用不垮。要查任何东西,查任何对象的状态变更,不需要一直轮循,只需要注册一下watch,然后它返回给你就好了。
3.K8s核心组件
API server
是整个集群的核心,这个核心就接收了所有的请求,并且所有的数据库读写都是从API server经过的。
Api网关除了提供基本的服务,还要做自我保护。
第一个认证,得知道这个请求从哪来,请求用户是谁。
第二个授权,得知道他有没有某个操作权限。
第三个准入,准入分为两个行为,一个叫做变形,一个叫做校验。
怎么理解变形和校验呢?
用户发了一个请求过来,作为集群的运营方,或者作为一个自动化平台,需要在原来的请求上加一些东西,这个时候希望在原始请求被被存到etcd之前,要在原始的请求上面更改一些属性或者添加一些属性,这个就是变形。在存之前我要知道这个新的请求生成的请求是不是有效,要做校验。
怎么理解准入呢?
准入必须放在API server,因为只有API server能访问etcd。API server在访问etce的时候,构建了一个在API server这边的缓存,对于客户端,访问API server的时候,默认行为数据是不穿透API server的, API server会把它这边数据的缓存直接返回给你,这个请求不会到etcd。
然后etcd这边有什么变化?
会以通知的形式告诉API server,理论上API server里面的所有数据都应该是最新的,作为客户端访问API server,基本上能拿到最新的数据。
Controller manager,是这个整个集群的大脑,是让集群动起来的关键。为什么呢?
前面提到,etcd就是个数据库,你发给发它什么它存什么。API server里面是没有逻辑的,其实就做完了一些检查以后,只要检查结束了,它就把数据存到etcd里面,这些都是静态的。
K8s作为声明式系统,意味着你告诉这个系统要建一个对象,一个期望的状态,desire state。这个系统一定要持续一直不停的工作,使得它的真实状态和期望状态一致。如何保持一致就是后面的Controller在干活。
Controller manager就是一堆控制器的集合。它会去监控API server,监控kubelet里面组件所创建的对象的变更,如果一个对象发生了变更,这个控制器就会去做相应的配置。
Scheduler,调度器
比如你建了一个Pod,调度器要去看你的Pod有没有做过调度,没有,就会去选择一个适合的节点,并且把你Pod里面的noble name的属性填上,这个就是调度器所完成的一个职责;Controller是类似的,比如你建一个service,service controller,发现你的service是用来描述负载均衡配置的,它就会去配负载均衡,这样你的服务就可以被访问了。
Kubelet,节点代理
用来管理节点上Pod的整个生命周。调度器把建好的Pod调到某个Node节点上,这个时候Kubelet就要去工作了,起这个Pod,去看当前的节点,这个容器起来了没有,如果没起,它就会起起来。
Kubelet用Docker运行时去起:
理论上就是把用户进程拉起来,放到某个Namespace,通过Cgroup把资源控制起来,通过reply,这个docker image把OverlayFS拉起来,通过网络的插件把网络配起来。
Kubelet为了实现标准化,把这些配置都抽象成了一个个的接口,CRI,CNI,CSI,(container runtime interface,container network interface,container storage interface)
任何一个系统都有一个初始化进程,Linux的初始进程是systemD,kubelet是systemD的一个service,systemD起来,Kubelet就先起来了。同时Kubelet作为K8s系统的初始进程,它启动后,一种拉起集群的方式是它去扫描本地目录来加载Pod等。通过这种方式,就把架构中以上这些控制器,调度器,API server,ETCD都拉起来了。这些组件无需再去systemD里面配置启动,用kubelet拉起来就OK了。
所以通过这种方式我们就简化了集群的部署,并且依赖于kubelet本身或者K8s本身的特性,来保证K8s控制面的高可用。
Kubeproxy
建好的服务要发布出去,Kubeproxy去监控这个 service对象完成负载均衡的配置
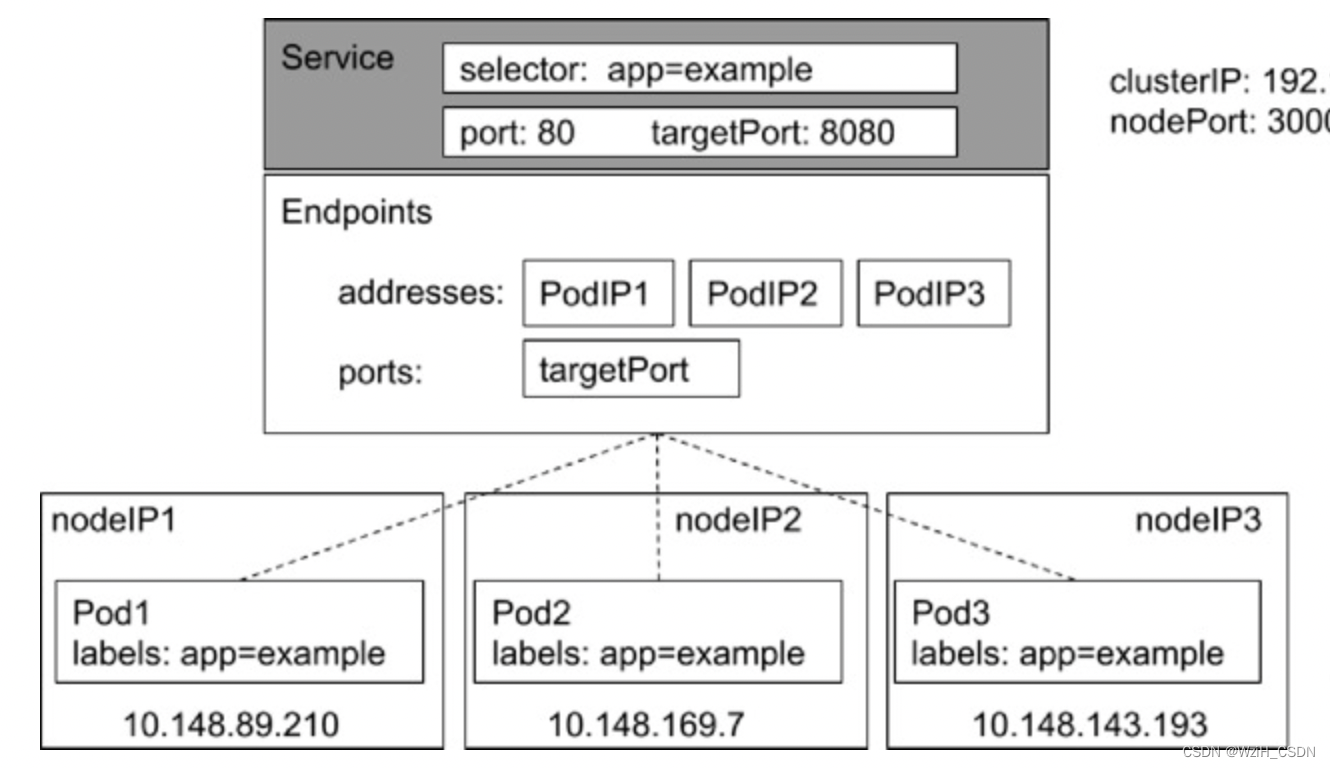
插件KubeDNS(必须)
是集群里面的域名服务,发布一个服务要提供域名的,这个域名是通过KubeDNS来提供的。
集群自带域名服务,建的service,其他的程序就可以通过服务名来查找了。
除了KubeDNS这个插件,其他插件依据业务需要可选。
K8s工作模式
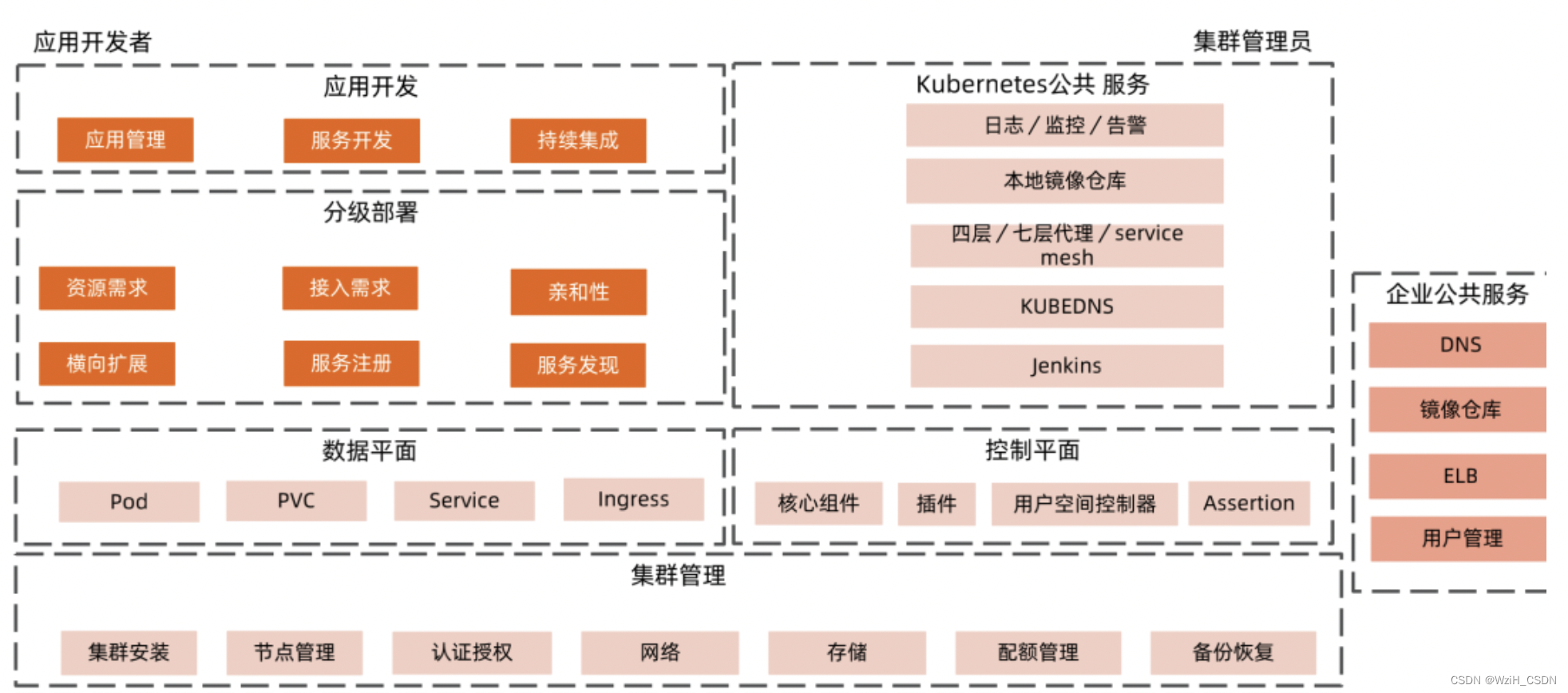
作为应用开发人员,应用开发、分级部署以及数据平面对象,都跟应用开发人员有关系。容器技术其实也有一定的关系,要对你的应用的资源消耗负责,怎么去做监控,这些都跟容器技术相关。
作为集群管理员,面向的更多的是基础架构、集群管理、控制平面组件,以及维护在K8s上面的一些公共服务。
理论上看不到明显的边界,集群管理员同时也是应用开发者,而且二者之间经常要做一些约定来确保在基础架构上的方案,比如集群做升级的时候不影响业务,所以这条路是打通的。
K8s的设计理念
为了保证应用的高可用,为了保证系统的安全,为了保证和扩展性可一致性,K8s提供了各种各样的对象来描述不同的业务场景,它能够很稳的成为业界的标准,跟它的分层架构很相关。
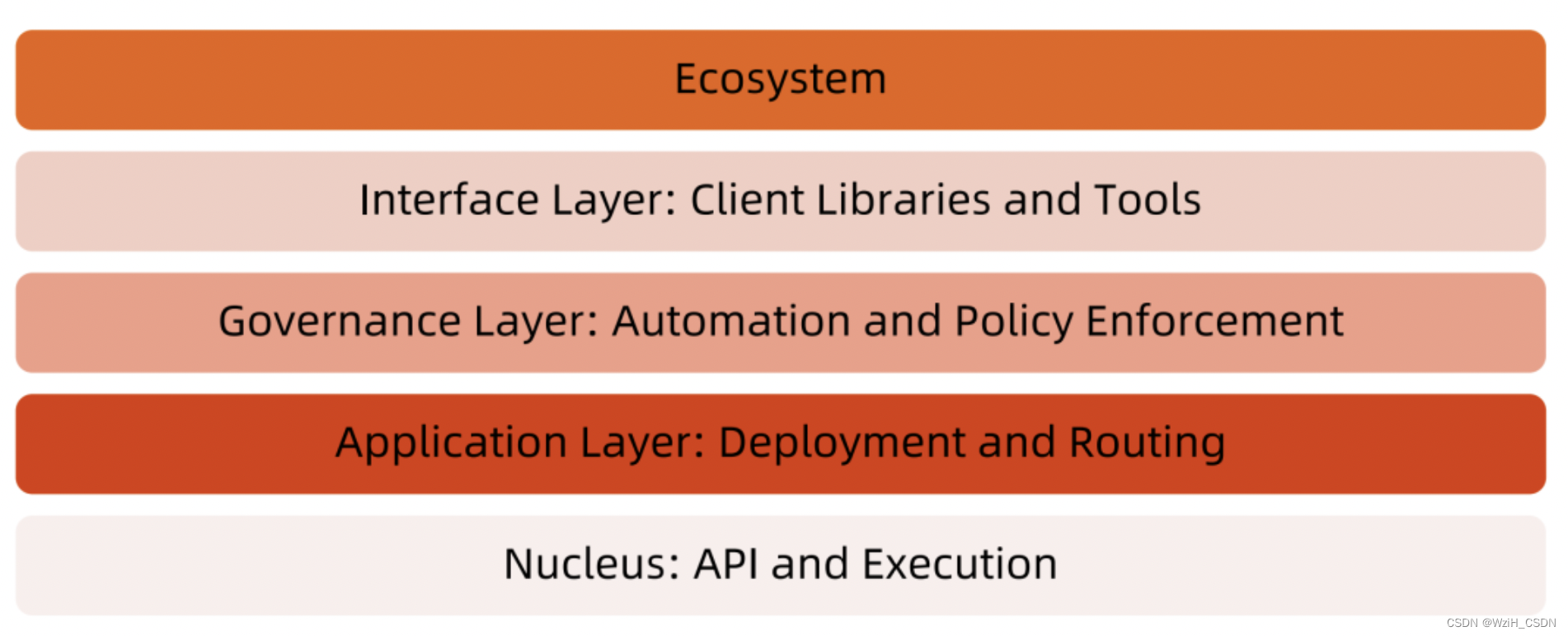
分层架构
它定义好了API,定义好了执行策略。
向下,K8s为了跟不同的云平台供不同的基础架构去做整合,它实现的部分都抽象成了一个个的接口(CRI、CNI、CSI)。这样,作为存储厂商,作为网络提供商,作为运营实体厂商,需要做的事情就是实现一个个的插件plug-in,剩下的事情就是跟K8s framework对接。所以K8s把自己抽象化了,它作为一个framework,这样在业界任何地方都是有一席之地的。
向上,除了基本的API,K8s还提供灵活的扩展,允许定义任何API。比如作为业界的方案提供商,就可以基于K8s构建很多更复杂的方案。这样一个生态系统就能形成了。
其中提到的API的设计原则如下:
-
第一点,所有API都需要是声明式的。
-
第二点,对象和对象之间应该是可互补和可组合的。聚合可能优先于继承,对于K8s来说,这些对象之间没有继承关系,它希望通过对象的组合完成业务的支撑。
-
第三点,控制器的行为必须是可承诺和密等的。怎么理解?就是一个对象如果配到一半,Controller crash了,或者做升级节点坏了,当 Controller重新启动,重新去配对象的时候,它所得到的结果应该是一致而稳定的,这样集群才能有一个稳定态。
进一步看K8s如何通过对象的组合完成业务流:
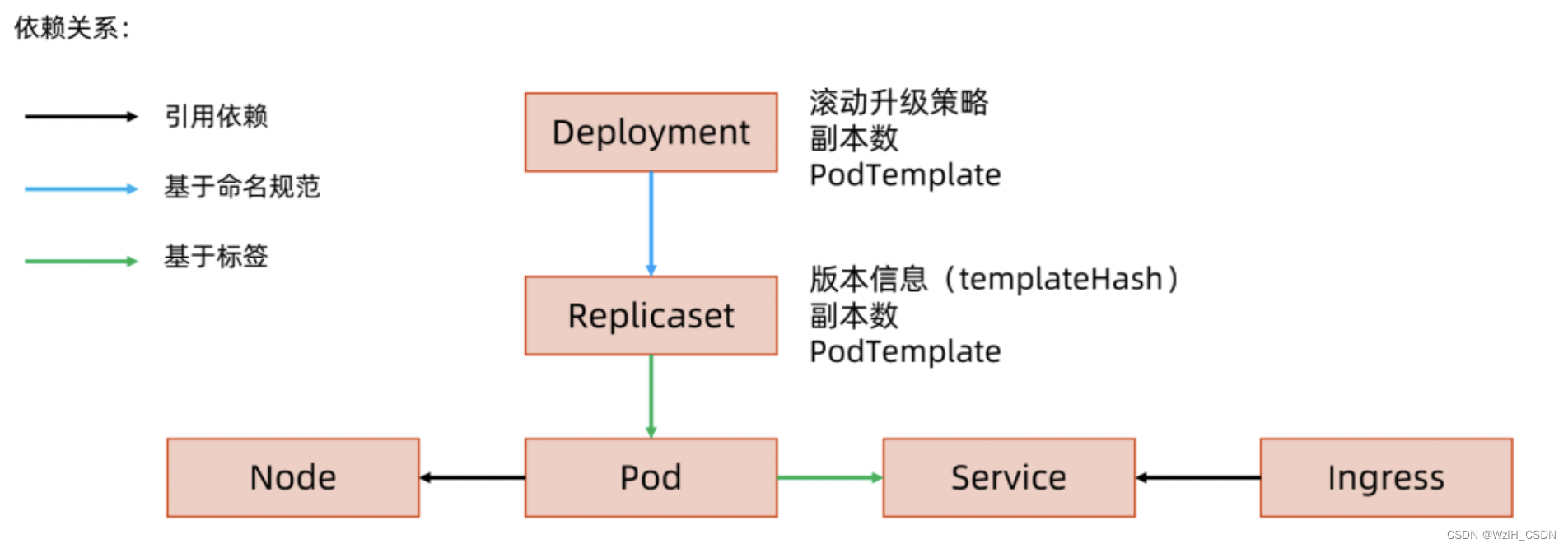
1,确保一个应用的高可用:
要去定义副本级,定义这个应用需要多少个副本,如果一个Pod出现了故障,没了,应用实例就没了。对于申明式系统来说,你的期望值和真实值必须是一致的,你期望一个副本,但是现在一个副本都没有,K8s没有满足你的期望,就会去继续干活,把这个副本建出来,永远都按照期望的值来运行应用的实例。
2,当中间要做版本升级:
原来V1现在V2,应用的升级是通过滚动升级,滚动升级有一定的策略,比如一次做10%,还是一次做一个,什么样的情况下要停下来,这些策略就描述在deployment对象里,通过deployment,raplicaset和Pod的来完成整个业务发布的流程描述。
3,定义和发布一个服务:
应用实例运行了以后,要发布一个服务,希望别人来访问服务。就要定义一个service。包括服务在哪个端口上面,用哪个协议去提供服务。如果要整个网站提供一个入口的网关,那么就要通过Ingress对象去定义。
4.总结
K8s架构原则:
1,只有API server能访问ETCD,其他组件必须跟API server通信,而且其他组件之间不直接通信,其他组件都是要跟API server来交互。
2,密等性的控制器,在处理到一半的情况下,如果出现了故障,比如crash了,那么在恢复的时候要继续去处理上一次没处理完的请求,已处理完的请求,即使再处理也得到同样的结果,就是密等性。
3,要基于监听,而不是轮巡。为什么?因为轮巡会把API server或者etcd OverLoad掉,会给它很大的查询压力,会让它过载掉。要减少主动查询,不要把集群弄死。
4,集群引导原则self hosting,就是kubelet本身是用来起Pod的,它能确保POd里面有一些policy,比如如果应用出现故障,Kubelet会重新把它拉起来。K8s的控制面也是希望达到的一样的目标,希望保证应用的高可用。
所以Kubelet可以把K8s的整个控制面拉起来,因为Kubelet可以从本地的目录去加载Pod清单,通过这种方式Kubelet管控K8s的控制面。














 2495
2495











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









