




 文章详细介绍了归并排序的算法思想,包括递归和非递归两种版本的代码实现,强调了空间复杂度以及算法的稳定性。归并排序的时间复杂度为O(N*log(2)N),在处理大数据排序时,如外排序,具有重要作用。
文章详细介绍了归并排序的算法思想,包括递归和非递归两种版本的代码实现,强调了空间复杂度以及算法的稳定性。归并排序的时间复杂度为O(N*log(2)N),在处理大数据排序时,如外排序,具有重要作用。
一.归并排序
1.算法思想
归并排序是一个不太好理解的排序算法,
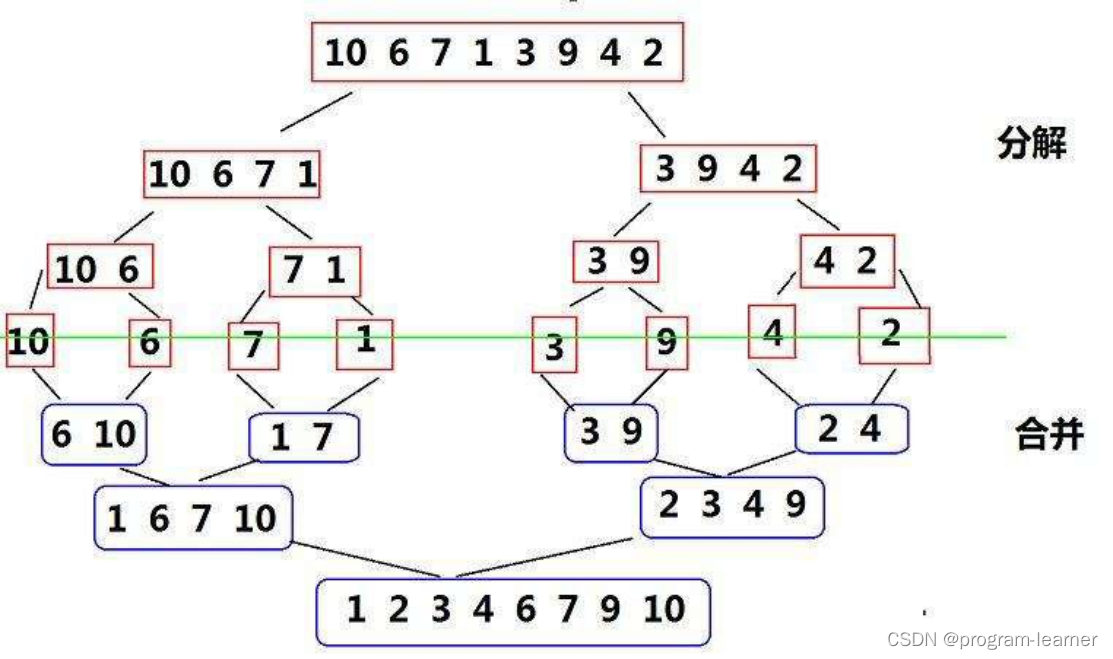
我们先看一下一张图片,了解一下归并排序的整体思想
不过归并的假设前提是:左区间有序,右区间有序
而给定一个数组,该怎么才能让它左半区间有序,右半区间也有序呢?

> 我们可以类比一下快排的递归版本的思想
> 在那里,我们成功使得key前面的数字都小于key,key后面的数字都大于key
> 那么我们当时在想:怎么才能让整个数组都有序呢?
> 只要让它的左半区间有序,右半区间有序,那么整体不久有序了吗?
> 所以我们进行递归调用,不断缩小区间长度
> 最坏的情况下,当某个对应区间的长度等于1时,该区间必定有序
所以我们类比得出,我们可以采用递归调用的方式,来不断缩小区间长度,最后进行多次归并得到有序序列
下面我们看一下归并排序整体的实现逻辑
但是我们注意到当我们进行多次的归并时,如果我们每个数组都去动态开辟出来(malloc),那开辟的是不是太多了呢?
所以我们这里只开辟了一个临时数组,那么怎么做到的呢?我们接下来来看一下

因为我们需要开辟临时数组,所以我们会有空间复杂度的消耗
临时数组需要能够存放下原始数组的所有数据
所以临时数组的长度需要跟原数组相同
所以空间复杂度为O(N)
2.代码实现
void _MergeSort(int* a, int left, int right,int* tmp)//一般某个主函数的子函数在前面加上_
{
if (left >= right)//区间长度为1,则必然有序
{
return;
}
int mid = (left + right) >> 1;
//等价于int mid = (left+right)/2;
//假设[left,mid] [mid+1,right] 有序,那么我们就可以进行归并了
//那么如何让左右区间均有序呢?
//类比递归版本的快排和二叉树的深度优先遍历
//我们可以这样
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//此时该小区间已经有序了,那么下面开始归并,也就是将有序序列存放到临时数组中
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;
while (begin1 <= end1 && begin2 <= end2)//左右区间有一个结束那么就结束循环
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];//a[begin1]和a[begin2]相等的时候,放谁进入临时数组都可以
}
}
//虽然我们在这里写了两个循环,但是只会进入其中一个
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//拷贝回去
int i = 0;
for (i = left; i <= right; i++)
{
a[i] = tmp[i];
}
//则该小区间已经有序了,对该小区间的递归调用结束
//每递归到最后时,区间长度为1,已经有序,无需归并,直接return返回即可
//当递归开始返回时,随着区间长度的增大,该小区间开始进行归并与拷贝,将该小区间变为有序区间
//随着递归调用的返回,有序区间的长度开始逐渐增大,直到整个数组均有序为止
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);//tmp:临时数组
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}
1.每递归到最后时,区间长度为1,已经有序,无需归并,直接return返回即可
2.当递归开始返回时,随着区间长度的增大,该小区间开始进行归并与拷贝,将该小区间变为有序区间
3.随着递归调用的返回,有序区间的长度开始逐渐增大,直到整个数组均有序为止
4.可以类比递归版本的快排和二叉树的深度优先遍历,
思想上类似于二叉树的后序遍历:
左,右,根, 左,右,根, 左,右,根, 左,右,根,左,右,根,…
//这里是:
左,右,归并,左,右,归并,左,右,归并,左,右,归并,左,右,归并…
回来后还要进行排序
而快排类似于:
先序遍历:
根,左,右,根,左,右,根,左,右,根,左,右,根,左,右
回来后就已经有序了
void _MergeSort(int* a, int left, int right, int* tmp)
{
if (left >= right)
{
return;
}
int mid = (left + right) >> 1;
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//开始归并
}
下面是递归调用图,其中当区间长度减为1时,直接返回即可,无需进行归并,其余长度的区间都必须进行归并

3.时间复杂度和稳定性
归并排序(递归跟非递归)的时间复杂度是O(N*log(2)N),
稳定性:稳定
因为它是采取分割为最小区间再重新组合的思想
因为归并的时候
当左区间和右区间的值相等时
我们只要控制让左区间的值复制到临时数组中即可
二.归并排序非递归版本
1.算法剖析
递归改非递归
1.直接改循环(简单)
2.借助数据结构栈模拟递归过程(复杂一点)
这里我们使用循环的方式来做
大家看一下这张图片

2.代码实现
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
int gap = 1;//每组需要归并的数据个数,控制每组有多少个
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
//每一轮for循环都是归并这两组数据
//[i,i+gap-1] [i+gap,i+2*gap-1]
// [begin1,end1] [begin2,end2]
//所以说每次for循环之后i都要从第一组的begin1到第二组的begin1,
//所以要加2*gap
//归并到一起
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//1.归并过程中右半区间可能就不存在
if (begin2 >= n)
{
break;//此时根本就不用进行归并了
}
//2.归并过程中右半区间算多了,修正一下
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//以下两个循环只会进一个
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//拷贝回去
for (int j = i; j <= end2; j++)
{
a[j] = tmp[j];
}
}
gap *= 2;
}
free(tmp);
}
难点剖析:1.
for (int i = 0; i < n; i += 2 * gap)
每一轮for循环都是归并这两组数据
[i,i+gap-1] [i+gap,i+2*gap-1]
[begin1,end1] [begin2,end2]
所以说每次for循环之后i都要从第一组的begin1到第二组的begin1,
所以要加2*gap
归并到一起
2.
for (int j = i; j <= end2; j++)
{
a[j] = tmp[j];
}
必须写j<=end2,不能写j<= i + 2 * gap - 1,因为
//2.归并过程中右半区间算多了,修正一下
if (end2 >= n)
{
end2 = n - 1;
}
出现这种情况时我们将边界修正了一下,到那时如果写为
j<= i + 2 * gap - 1,那就是写死了,导致越界访问了.
3. 拷贝回去
for (int j = i; j <= end2; j++)
{
a[j] = tmp[j];
}
要放在上面那个for循环的内部
否则如果放在上面的那个for循环外面,
像这样的话
for (int j = 0; j <n; j++)
{
a[j] = tmp[j];
}
最外层while循环的里面的话会发生一下这种情况
因为如果放在外面的话,当循环到达4个gap==4且i==0时
| 10 6 7 1 |3 9 4 2|2
我们发现第一轮for循环时左右区间都完整
但是第二轮for循环时不仅右半区间不存在,而且连左半区间都残缺不全
也就是说这个2根本不会拷进tmp临时数组中
tmp临时数组中对应位置存放的是一个随机值
但是我们却在最后进行拷贝,这样就会使得原数组对应位置的这个2被随机值所覆盖,出现错误
4.总之,归并排序的非递归最难的点在于边界的修正和思想
5.因为右半区间的边界需要去时刻准备修正
所以这个归并排序的非递归版本使用栈的话就会很麻烦

3.归并排序的用途
归并排序也叫外排序,还可以对文件中的数据进行排序
只有归并排序才能解决这个问题
假设10G的数据放到硬盘的文件中,要排序,如何排呢?
可能内存不够,假设只有1G的内存可以使用
10G的文件,切分成为10个1G的文件,并且让10个1G的文件有序
依次读文件,每次读1G到内存中形成一个数组,用快排对其进行排序
再写到一个文件中,再继续下一个1G的数据
然后再用归并排序把每个1G的文件逐步归并为一个10G的文件
以上就是归并排序的剖析,希望能对大家有所帮助


















 997
997


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










