







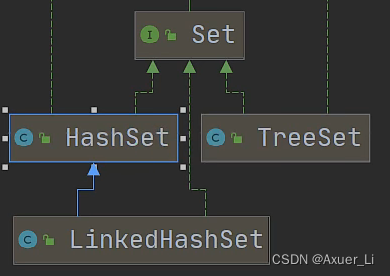
一、Set
1、Set 接口基本介绍
① 无序(添加和去除的顺序不一致),没有索引;
② 不允许重复元素,所以最多包含一个null ==》 数据不可以重复;
③ JDK API中Set接口的实现类

④ 注意:取出的顺序的顺序虽然不是添加的顺序,但它是固定的.
public static void main(String[] args) {
Set set = new HashSet();
set.add("john");
set.add("lucy");
set.add("john");//重复
set.add("jack");
set.add("hsp");
set.add("mary");
set.add(null);//
set.add(null);//再次添加null
for(int i = 0; i <10;i ++) {
System.out.println("set=" + set);
}
}
输出结果:

2、Set 接口的常用方法
和 List 接口一样, Set 接口也是 Collection 的子接口,因此,常用方法和 Collection 接口一样。
3、Set 接口的两种遍历方式
同Collection的遍历方式一样,因为Set接口是Collection接口的子接口。
① 可以使用迭代器;
② 增强for;
③ 不能使用索引的方式来获取(没有get方法)==》不能用普通for循环遍历。
//遍历
//方式1: 使用迭代器
System.out.println("=====使用迭代器====");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
set.remove(null);
//方式2: 增强for
System.out.println("=====增强for====");
for (Object o : set) {
System.out.println("o=" + o);
}
//set 接口对象,不能通过索引来获取
//set没有get方法
二、HashSet
1、HashSet的全面说明
① HashSet实现了Set接口;
② HashSet实际上是HashMap,HashMap底层是(数组+链表+红黑树);
③ 可以存放null值,但是只能有一个null;
④ HashSet不保证元素是有序的,取决于hash后,再确定索引的结果;(即,不保证存放元素的顺序和取出顺序一致)
⑤ 不能有重复元素/对象。
HashSet set = new HashSet();
//说明
//1. 在执行add方法后,会返回一个boolean值
//2. 如果添加成功,返回 true, 否则返回false
System.out.println(set.add("john"));//T
System.out.println(set.add("lucy"));//T
System.out.println(set.add("john"));//F
System.out.println(set.add("jack"));//T
System.out.println(set.add("Rose"));//T
//3. 可以通过 remove 指定删除哪个对象
set.remove("john");
System.out.println("set=" + set);//set=[Rose, lucy, jack]
set = new HashSet();
System.out.println("set=" + set);//set=[]
//4. Hashset 不能添加相同的元素/数据?
set.add("lucy");//添加成功
set.add("lucy");//加入不了
set.add(new Dog("tom"));//OK
set.add(new Dog("tom"));//Ok,和上面行是两个不同的对象(元素是对象)
System.out.println("set=" + set); //set=[Dog{name='tom'}, Dog{name='tom'}, lucy]
//再加深一下. 非常经典的面试题.
//看源码,做分析,先留一个坑,后面讲源码就懂了
//去看他的源码,即 add 到底发生了什么?=> 底层机制.
set.add(new String("hsp"));//ok
set.add(new String("hsp"));//加入不了.
System.out.println("set=" + set); //set=[hsp, Dog{name='tom'}, Dog{name='tom'}, lucy]
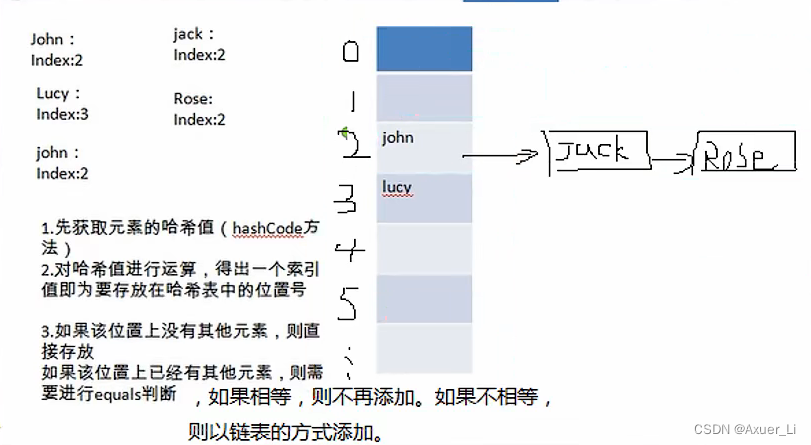
2、模拟简单的数组+链表结构
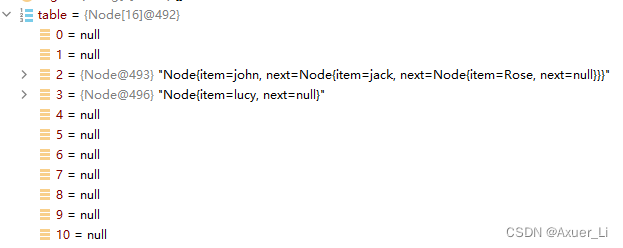
public class Test {
@SuppressWarnings({"all"})
public static void main(String[] args) {
//模拟一个HashSet的底层 (HashMap 的底层结构)
//1. 创建一个数组,数组的类型是 Node[]
//2. 有些人,直接把 Node[] 数组称为 表
Node[] table = new Node[16];
//3. 创建结点
Node john = new Node("john", null);
table[2] = john;
Node jack = new Node("jack", null);
john.next = jack;// 将jack 结点挂载到john
Node rose = new Node("Rose", null);
jack.next = rose;// 将rose 结点挂载到jack
Node lucy = new Node("lucy", null);
table[3] = lucy; // 把lucy 放到 table表的索引为3的位置.
System.out.println("table=" + table);
}
}
class Node { //结点, 存储数据, 可以指向下一个结点,从而形成链表
Object item; //存放数据
Node next; // 指向下一个结点
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}
3、HashSet底层机制说明
① HashSet 底层是 HashMap;
② 添加一个元素时,会得到hash值,会转成->索引值
③ 找到存储数据表table,看这个索引位置是否已经存放了元素;
④ 如果没有,直接加入;
⑤ 如果有,调用equals方法比较,如果相同,就放弃添加;如果不相同,则看链表的元素是否相同,如果相同,则放弃添加,否则添加到最后;
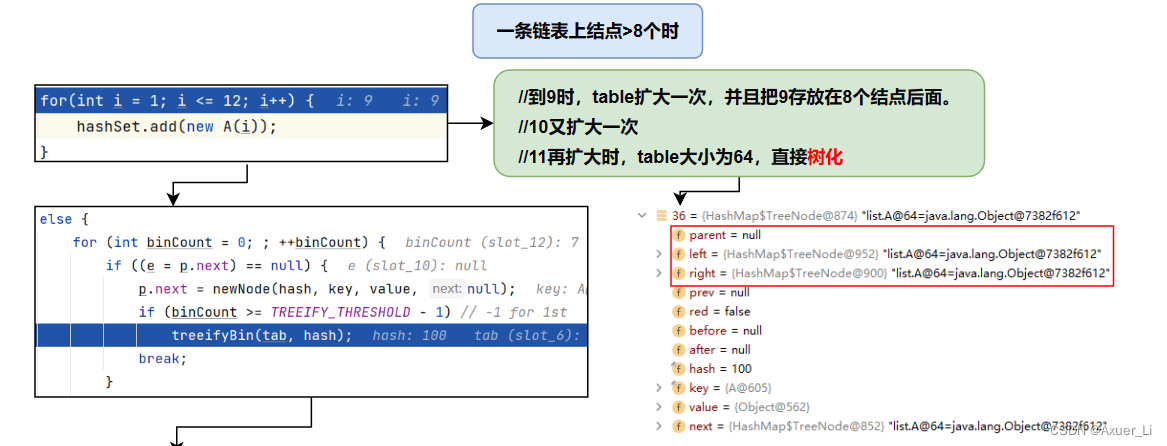
⑥ 在Java8中,如果一条链表的元素个数 >= TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。
- 如果一条链表到了8个,但table没到64,则会先对table进行扩容
4、HashSet源码图解
HashSet hashSet = new HashSet();
hashSet.add("java");//到此位置,第1次add分析完毕.
hashSet.add("php");//到此位置,第2次add分析完毕
hashSet.add("java");
System.out.println("set=" + hashSet);
1)构造器
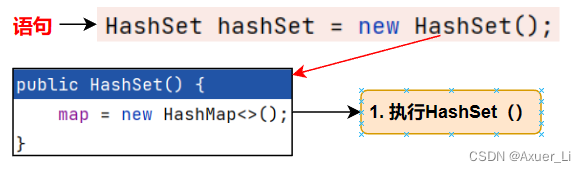
2)第一次add:扩容+存放
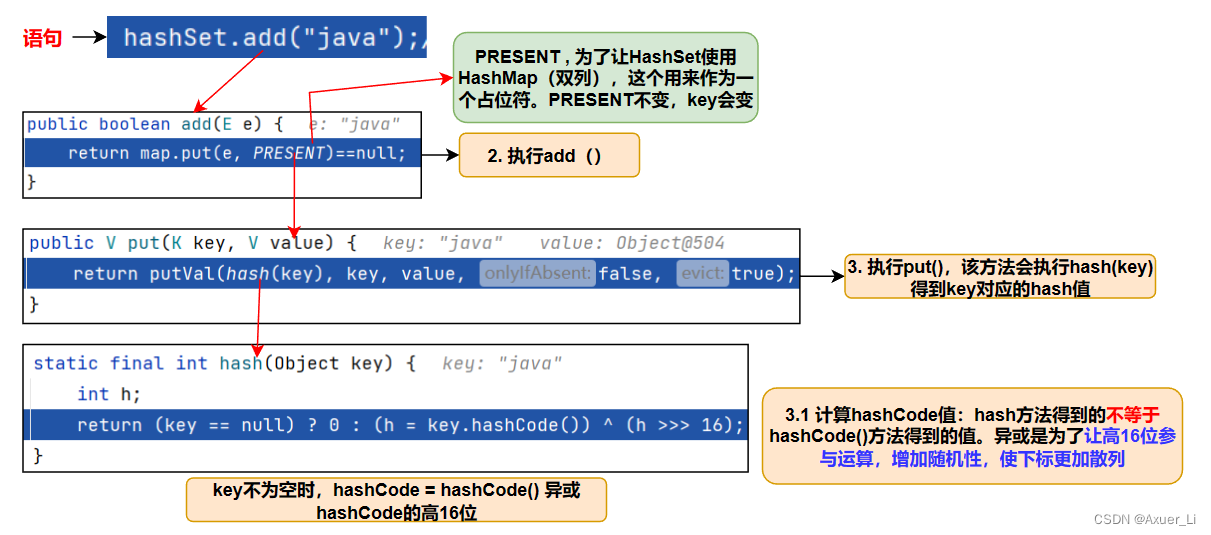
点击:为什么hash方法要右移16位,和直接求得的hashCode值异或
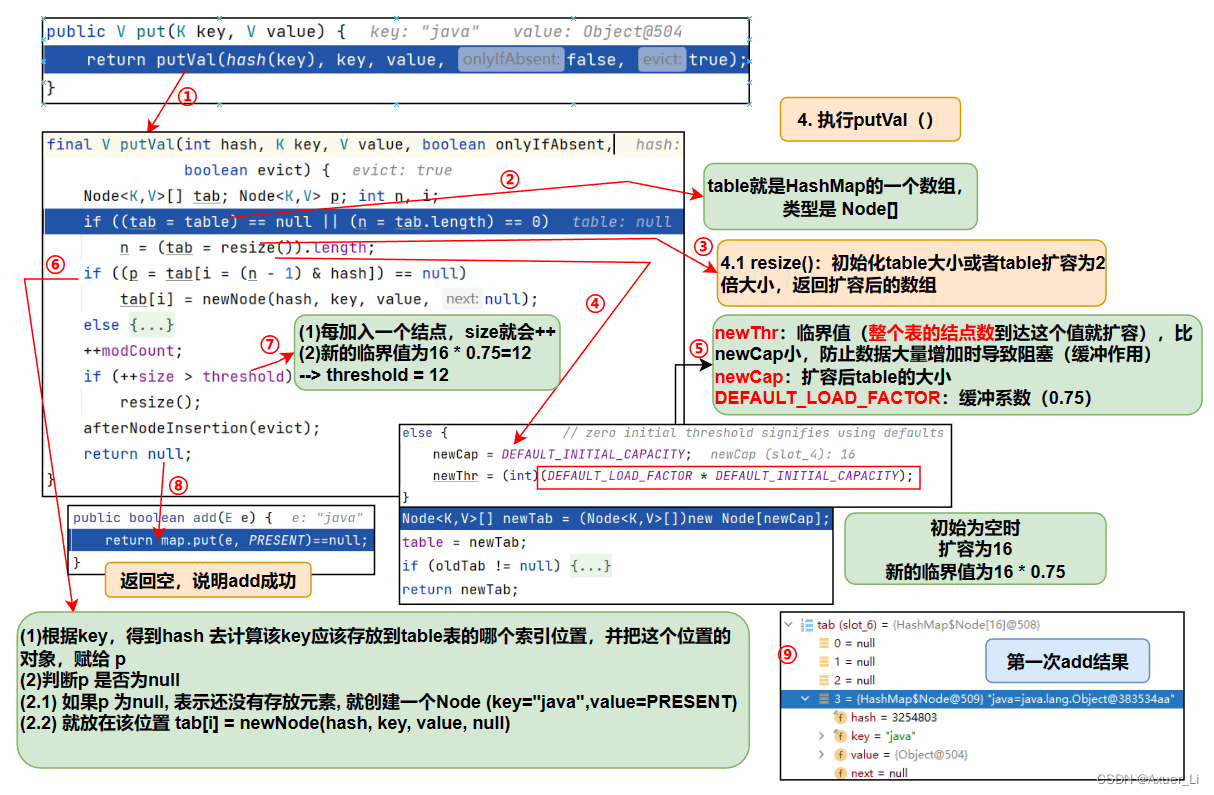
3)第二次add:直接存放
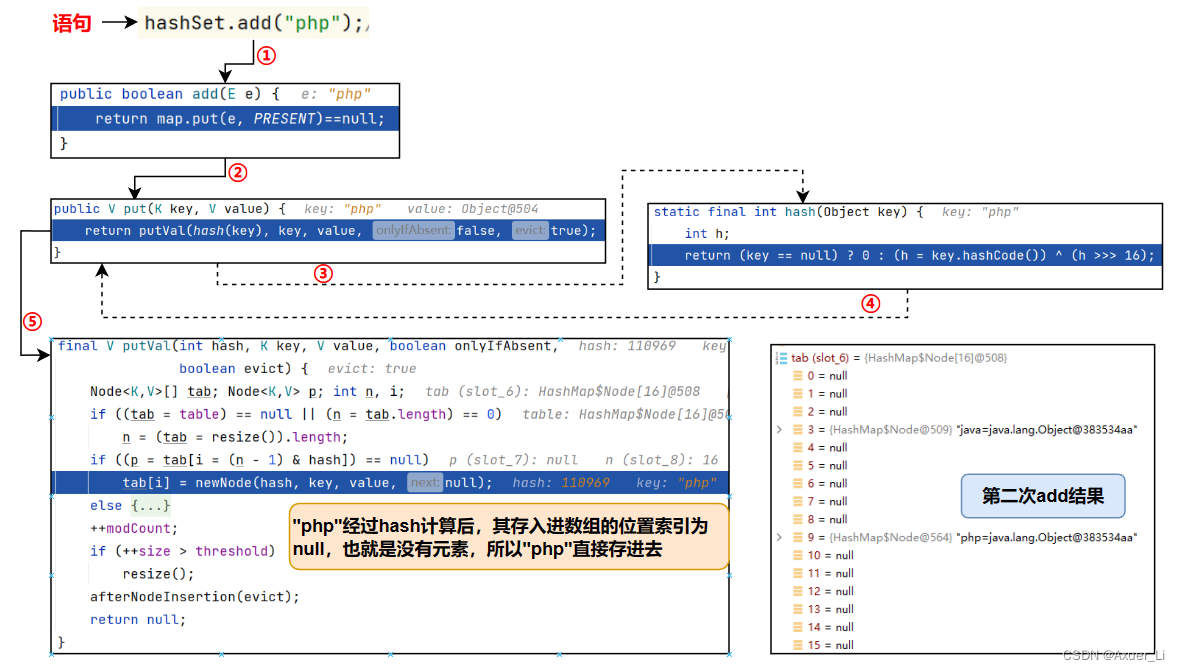
4)第三次add:重复元素存放

5)HashSet扩容机制
【a) 原table不为空时扩容】
- 第一次添加时,table容量扩容到16,临界值 = 16 * 0.75
- 后续添加,table容量为原容量的2倍,临界值 = 原临界值两倍
【b) HashSet扩容成红黑树机制】
在Java8中,如果一条链表的元素个数 >= TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),否则仍然采用数组扩容机制。
public class Test {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
/*
在Java8中, 如果一条链表的元素个数到达 TREEIFY_THRESHOLD(默认是 8 ),
并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树),
否则仍然采用数组扩容机制
*/
for(int i = 1; i <= 12; i++) {
hashSet.add(new A(i)); //到9时,table扩大一次,并且存放在8个结点后面。10又扩大一次,11再扩大时,table大小为64,直接树化
}
}
}
class B {
private int n;
public B(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 200;
}
}
class A {
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode() {
return 100;
}
}
5、HashSet课堂练习

@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
System.out.println(hashSet.add(new Employee("jack",20))); //T
System.out.println(hashSet.add(new Employee("tom",22))); //T
System.out.println(hashSet.add(new Employee("tom",22))); //F
System.out.println(hashSet.add(new Employee("mike",24))); //T
}
}
class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Employee employee = (Employee) o;
return age == employee.age && Objects.equals(name, employee.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
//底层源码:
//public static int hash(Object... values)↓
//public static int hashCode(Object a[])↓
//for (Object element : a) { result = 31 * result + (element == null ? 0 : element.hashCode()); }
//假如hash传入n个参数
//计算方式:31^n + a[0].hashCode() * 31^(n-1) + a[1].hashCode() * 31^(n-2) + ... + a[n-1].hashCode();
}
}

@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
System.out.println(hashSet.add(new Employee("jack",20000,new MyDate(1998, 5, 2)))); //true
System.out.println(hashSet.add(new Employee("tom",25000,new MyDate(1999, 3, 23)))); //true
System.out.println(hashSet.add(new Employee("tom",22000,new MyDate(1999, 3, 23)))); //false
System.out.println(hashSet.add(new Employee("mike",13000,new MyDate(1997, 1, 19)))); //true
}
}
class Employee {
private String name;
private double sal;
private MyDate birthday;
public Employee(String name, double sal, MyDate birthday) {
this.name = name;
this.sal = sal;
this.birthday = birthday;
}
public String getName() {
return name;
}
public MyDate getBirthday() {
return birthday;
}
@Override
public boolean equals(Object o) {
if(this == o) return true;
if(o == null || o.getClass() != getClass()) return false;
Employee e = (Employee) o;
return e.getName().equals(name) && e.getBirthday().equals(birthday);
}
@Override
public int hashCode() {
return Objects.hash(name, birthday);
}
}
class MyDate {
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
this.year = year;
this.month = month;
this.day = day;
}
@Override
public boolean equals(Object o) {
if(this == o) return true;
if(o == null || o.getClass() != getClass()) return false;
MyDate md = (MyDate)o;
return md.year == year && md.month == month && md.day == day;
}
//必须重写hashCode(),不然在调用Objects.hash(name, birthday)时,birthday.hashCode()会因为不同对象而有不同hash值
@Override
public int hashCode() {
return Objects.hash(year,month,day);
}
}
三、LinkedHashSet
1、LinkedHashSet 的全面说明
① LinkedHashSet 是 HashSet 的子类;
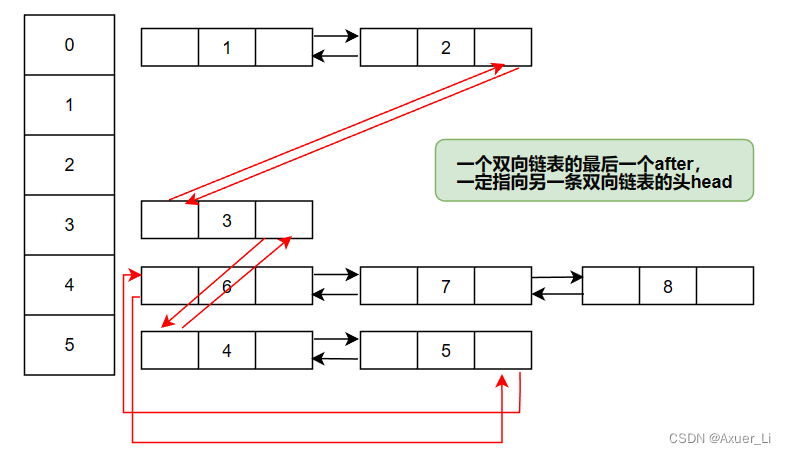
② LinkedHashSet 底层是一个 LinkedHashMap,底层维护了一个数组+双向链表;
- LinkedHashSet 有
head和tail - 每一个结点有
before和after属性,这样可以形成双向链表
③ LinkedHashSet 根据元素 hashCode来决定元素的存储位置,同时使用链表维护元素的次序(图),这使得元素看起来是以插入顺序保存的;
④ LinkedHashSet 不允许添加重复元素
2、LinkedHashSet底层机制图

3、源码分析
public class Test {
public static void main(String[] args) {
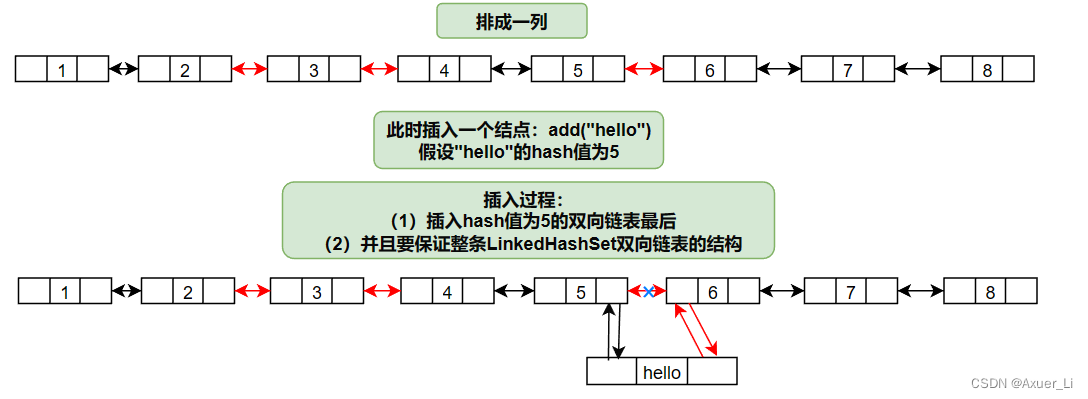
//分析一下LinkedHashSet的底层机制
//在添加一个元素时,先求hash值,再求索引。
//确定该元素在table的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加)
//[原则和hashSet一样])
Set set = new LinkedHashSet();
set.add(new String("AA"));
set.add(456);
set.add(456);
set.add(new Customer("刘", 1001));
set.add(123);
set.add("HSP");
System.out.println("set=" + set);
//解读
//1. LinkedHashSet 加入顺序和取出元素/数据的顺序一致
//2. LinkedHashSet 底层维护的是一个LinkedHashMap(是HashMap的子类)
//3. LinkedHashSet 底层结构 (数组table+双向链表)
//4. 添加第一次时,直接将 数组table 扩容到 16 ,存放的结点类型是 LinkedHashMap$Entry
//5. 数组是 HashMap$Node[] 存放的元素/数据是 LinkedHashMap$Entry类型
/*
//继承关系是在内部类完成.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
*/
}
}
class Customer {
private String name;
private int no;
public Customer(String name, int no) {
this.name = name;
this.no = no;
}
}
4、课后练习
public class Test {
public static void main(String[] args) {
LinkedHashSet linkedHashSet = new LinkedHashSet();
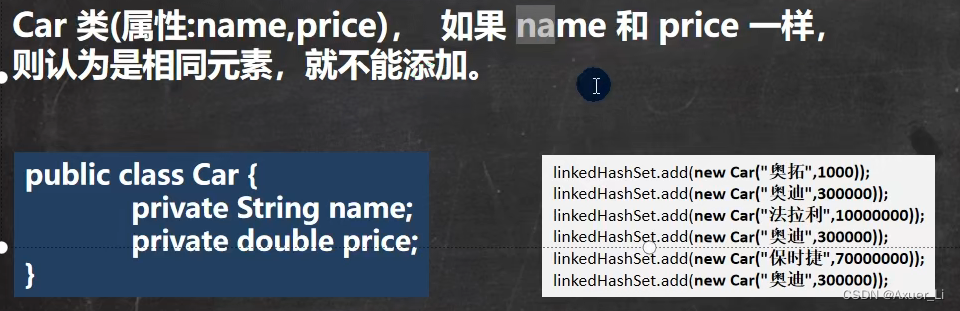
linkedHashSet.add(new Car("奥拓", 1000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//OK
linkedHashSet.add(new Car("法拉利", 10000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
linkedHashSet.add(new Car("保时捷", 70000000));//OK
linkedHashSet.add(new Car("奥迪", 300000));//加入不了
System.out.println("linkedHashSet=" + linkedHashSet);
}
}
class Car {
private String name;
private double price;
public Car(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public double getPrice() {
return price;
}
// @Override
// public boolean equals(Object o) {
// if(this == o) return true;
// if(o == null || o.getClass() != getClass()) return false;
// Car car = (Car) o;
// return car.getName().equals(name) && car.getPrice() == price;
// }
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Car car = (Car) o;
return Double.compare(car.price, price) == 0 && Objects.equals(name, car.name);
//Objects.equals(a:name, b:car.name); => 会调用a.equals(b),这里name为String类型,所以会调用String的equals
}
@Override
public int hashCode() {
return Objects.hash(name,price);
}
@Override
public String toString() {
return "Car{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
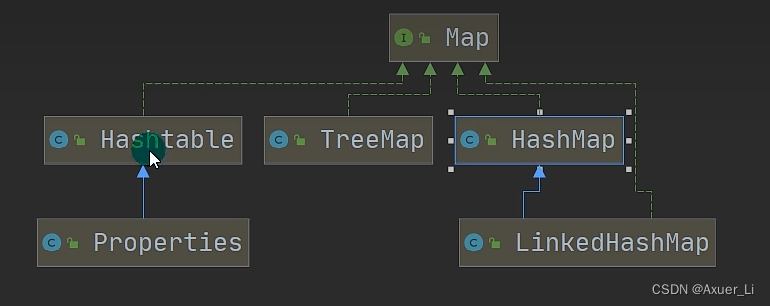
四、Map
1、Map接口继承实现关系图
2、Map 接口实现类的特点
这里讲的是JDK8的Map接口特点:
① Map与Collection并列存在(即平行关系);
- Map用于保存具有映射关系的数据:Key-Value
② Map 中的 key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node对象中;
③ Map 中的 key 不允许重复;
- 原因和HashSet 一样;因为hash值是由key的hashCode()计算得到,equals比较的也是key值
④ Map 中的 value 可以重复;
- 当有相同的key时 , 就等价于替换.
map.put("no1", "孙悟空");
map.put("no1", "张三丰");//当有相同的k , 就等价于替换.
System.out.println(map.get("no1"));//张三丰
⑤ Map 的key 可以为 null, value 也可以为null
- 注意 key 为null, 只能有一个,value 为null ,可以多个;
⑥ 通过get 方法,传入 key ,会返回对应的value
map.put("no2", "张无忌");
System.out.println(map.get("no2"));//张无忌
⑦ 常用String类作为Map的 key;
- 当然,其他类也可以(只要是Object子类都可以)
⑧ key 和 value 之间存在单向一对一关系;
- 即通过指定的 key 总能找到对应的 value。
@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put("no1", "张三丰");//当有相同的k , 就等价于替换.
map.put("no3", "张三丰");//k-v
map.put(null, null); //k-v
map.put(null, "abc"); //等价替换
map.put("no4", null); //k-v
map.put("no5", null); //k-v
map.put(1, "赵敏");//k-v
map.put(new Object(), "金毛狮王");//k-v
//
System.out.println(map.get("no2"));//张无忌
System.out.println("map=" + map);
//map={no2=张无忌, null=abc, no1=张三丰, 1=赵敏, no4=null, no3=张三丰, no5=null, java.lang.Object@1b6d3586=金毛狮王}
}
}
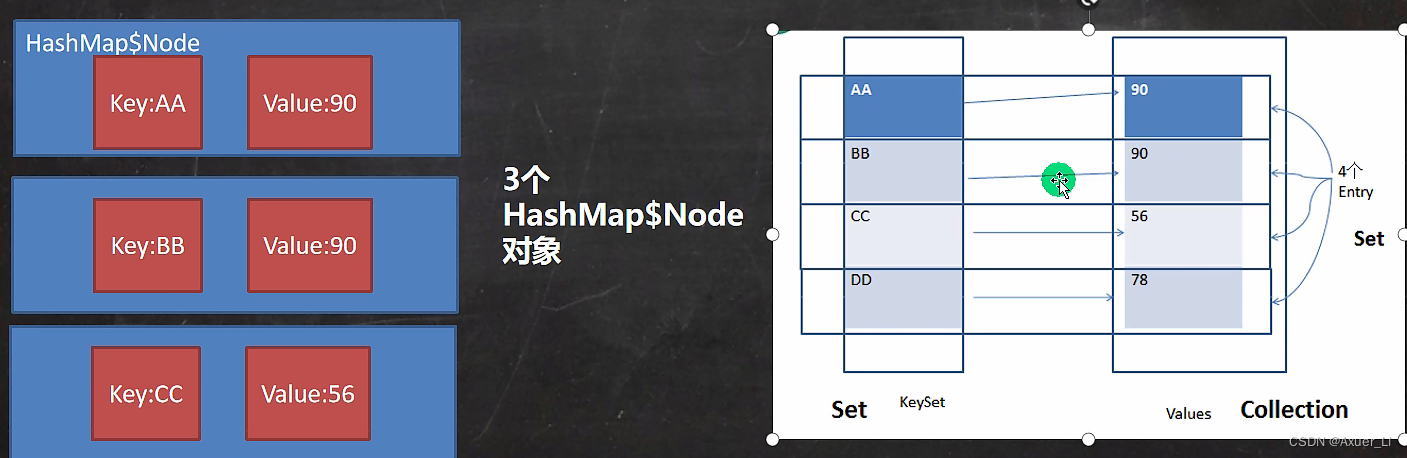
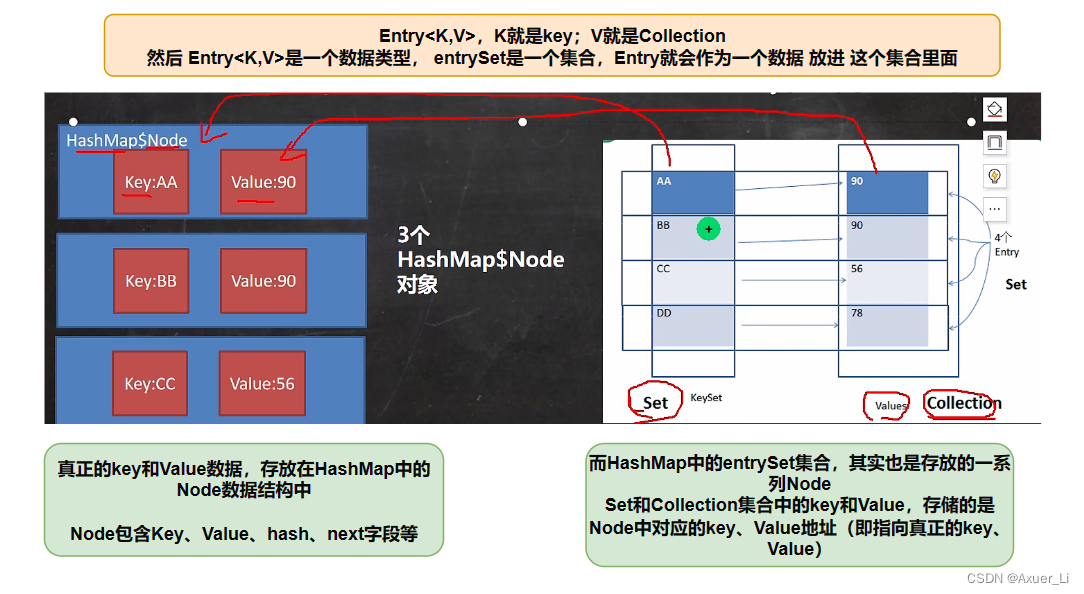
⑧ Map存放数据的key-value示意图,一对 k-v 是放在一个Node中的,又因为Node 实现了 Entry 接口,有些书上也说一对k-v就是一个Entry
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1", "韩顺平");//k-v
map.put("no2", "张无忌");//k-v
map.put(new Car(), new Person());//证明entrySet不是存放数据,而是指向
//解读
//1. k-v 最后是 HashMap$Node node = newNode(hash, key, value, null)
//2. k-v 为了方便程序员的遍历,还会 创建 entrySet 集合 ,该集合存放的元素的类型是 Entry, 而一个Entry
// 对象就有k,v。 即: transient Set<Map.Entry<K,V>> entrySet;
//3. entrySet 中, 定义的类型是 Map.Entry ,但是实际上存放的还是 HashMap$Node
// 这是因为 static class Node<K,V> implements Map.Entry<K,V>,(Node实现了Map.Entry接口)=》接口多态
//4. 当把 HashMap$Node 对象 存放到 entrySet 就方便我们的遍历, 因为 Map.Entry 提供了重要方法
// K getKey(); V getValue();
Set set = map.entrySet();
System.out.println(set.getClass());// HashMap$EntrySet
for (Object obj : set) {
//System.out.println(obj.getClass()); //HashMap$Node
//为了从 HashMap$Node 取出k-v
//1. 先做一个向下转型
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey() + "-" + entry.getValue() );
}
Set set1 = map.keySet();
System.out.println(set1.getClass()); //HashMap$KeySet
Collection values = map.values();
System.out.println(values.getClass()); //HashMap$Values
}
3、Map接口常用方法
put存放键值对remove根据key删除映射关系get根据key获取valuesize获取元素个数(多少对key-value)isEmpty判断个数是否为0clear清空键值对containsKey查找键是否存在
public class Test {
public static void main(String[] args) {
//演示map接口常用方法
Map map = new HashMap();
//1. put: 存放键值对
map.put("邓超", new Book("", 100));//OK
map.put("邓超", "孙俪");//替换-> 一会分析源码
map.put("王宝强", "马蓉");//OK
map.put("宋喆", "马蓉");//OK
map.put("刘令博", null);//OK
map.put(null, "刘亦菲");//OK
map.put("鹿晗", "关晓彤");//OK
map.put("hsp", "hsp的老婆");
System.out.println("map=" + map);
//2. remove: 根据key删除映射关系
map.remove(null);
System.out.println("map=" + map); //null=刘亦菲 被删除
//3. get:根据key获取value
Object val = map.get("鹿晗");
System.out.println("val=" + val); //val=关晓彤
//4. size: 获取元素个数(多少对key-value)
System.out.println("k-v=" + map.size());
//5. isEmpty: 判断个数是否为0
System.out.println(map.isEmpty());//F
//6. clear: 清空键值对
//map.clear();
System.out.println("map=" + map);
//7. containsKey: 查找键是否存在
System.out.println("结果=" + map.containsKey("hsp"));//T
}
}
class Book {
private String name;
private int num;
public Book(String name, int num) {
this.name = name;
this.num = num;
}
}
4、Map接口遍历方法
-
KeySet:获取所有的键; -
entrySet:获取所有的关系K-V; -
values:获取所有的值
@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
Map map = new HashMap();
map.put("邓超", "孙俪");
map.put("王宝强", "马蓉");
map.put("宋喆", "马蓉");
map.put("刘令博", null);
map.put(null, "刘亦菲");
map.put("鹿晗", "关晓彤");
//=========遍历键值对=========
//1. keySet: 取出所有key 再通过key取出对应的Value
Set keyset = map.keySet();
//1.1 Set遍历方法一:iterator
System.out.println("=========Set_iterator遍历=========");
Iterator iterator = keyset.iterator();
while(iterator.hasNext()){
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//1.2 Set遍历方法二:增强for
System.out.println("=========Set_增强for遍历=========");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//2. values:取出所有value , 但取不出值
Collection values = map.values();
//1.1 Collection遍历方法一:iterator
System.out.println("=========Collection_iterator遍历=========");
Iterator iterator1 = values.iterator();
while(iterator1.hasNext()){
Object value = iterator1.next();
System.out.println(value);
}
//1.2 Collection遍历方法二:增强for
System.out.println("=========Collection_增强for遍历=========");
for (Object value : values) {
System.out.println(value);
}
//1.3 Collection遍历方法三:普通for => 不能用,因为values没有get方法
// System.out.println("=========Collection_普通for遍历=========");
// for (int i = 0 ; i < values.size() ; i++) {
// System.out.println(values.get(i));
// }
//3. 通过EntrySet来获取
Set entryset = map.entrySet();
//3.1 增强for
System.out.println("=========EntrySet_增强for遍历=========");
System.out.println("=====没有格式化的遍历=====");
for (Object entry : entryset) {
System.out.println(entry); //这是没有格式化的遍历
}
System.out.println("=====格式化后的遍历=====");
for (Object entry : entryset) {
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue()); //这是格式化后的遍历
}
//3.2 iterator
System.out.println("=========EntrySet_iterator遍历=========");
Iterator iterator2 = entryset.iterator();
System.out.println("=====没有格式化的遍历=====");
while(iterator2.hasNext()) {
Object entry = iterator2.next();
System.out.println(entry);
}
System.out.println("=====格式化后的遍历=====");
iterator2 = entryset.iterator();
while(iterator2.hasNext()) {
Map.Entry entry = (Map.Entry)(iterator2.next());
System.out.println(entry.getKey() + "-" + entry.getValue());
}
//普通for => 不行,entryset没有get方法
// for (int i = 0; i < entryset.size(); i++) {
// System.out.println(entryset.get(i));
// }
}
}
5、Map接口课堂练习

@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
Employee jack = new Employee("jack", 20000, 1);
Employee tom = new Employee("tom", 30000, 2);
Employee smith = new Employee("smith", 10000, 3);
hashMap.put(jack.getId(),jack);
hashMap.put(tom.getId(),tom);
hashMap.put(smith.getId(), smith);
//keySet
System.out.println("=======keyset=======");
Set keyset = hashMap.keySet();
for (Object key : keyset) {
Employee e = (Employee) hashMap.get(key);
if(e.getSalary() > 18000)
System.out.println(e);
}
System.out.println();
Iterator iterator = keyset.iterator();
while(iterator.hasNext()) {
Object key = iterator.next();
Employee e = (Employee)hashMap.get(key);
if(e.getSalary() > 18000)
System.out.println(e);
}
//entryset
System.out.println("=======entryset=======");
Set entryset = hashMap.entrySet();
for (Object entry : entryset) {
Map.Entry m = (Map.Entry) entry;
Employee e = (Employee) m.getValue();
if (e.getSalary() > 18000){
System.out.println(e);
}
}
System.out.println();
Iterator iterator1 = entryset.iterator();
while(iterator1.hasNext()) {
Map.Entry entry = (Map.Entry) iterator1.next();
Employee e = (Employee) entry.getValue();
if(e.getSalary() > 18000) {
System.out.println(e);
}
}
}
}
class Employee {
private String name;
private double salary;
private int id;
public Employee(String name, double salary, int id) {
this.name = name;
this.salary = salary;
this.id = id;
}
public String getName() {
return name;
}
public double getSalary() {
return salary;
}
public int getId() {
return id;
}
@Override
public String toString() {
return "姓名:" + getName() + "\t工资:" + getSalary() + "\t员工id:" +getId();
}
}
五、HashMap
1、HashMap介绍

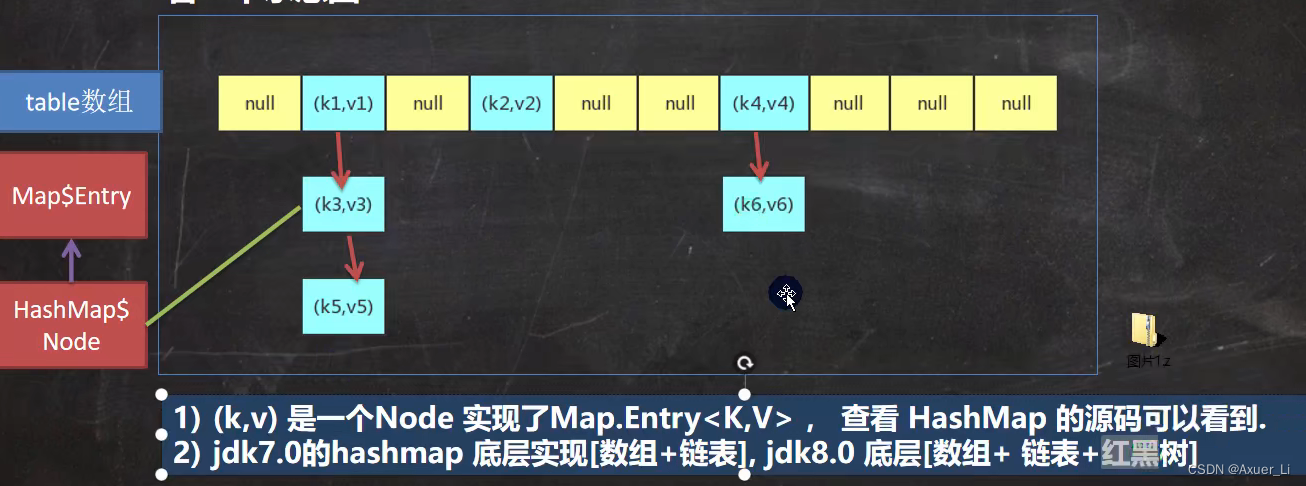
2、HashMap底层机制及源码剖析
3、扩容机制【和HashSet相同】
① HashMap底层维护了Node类型的数组table,默认为null;
② 当创建对象时,将加载因子(loadfactor)初始化为0.75;
③ 当添加key-val时,通过key的哈希值得到在table的索引,然后判断该索引处是否有元素
- 如果没有元素则直接添加。
- 如果该索引处有元素,继续判断该元素的key和准备加入的key是否相等
- 如果相等,则直接替换val
- 如果不相等需要判断是树结构还是链表结构,做出相应处理。
- 如果添加时候发现容量不够,则需要扩容;
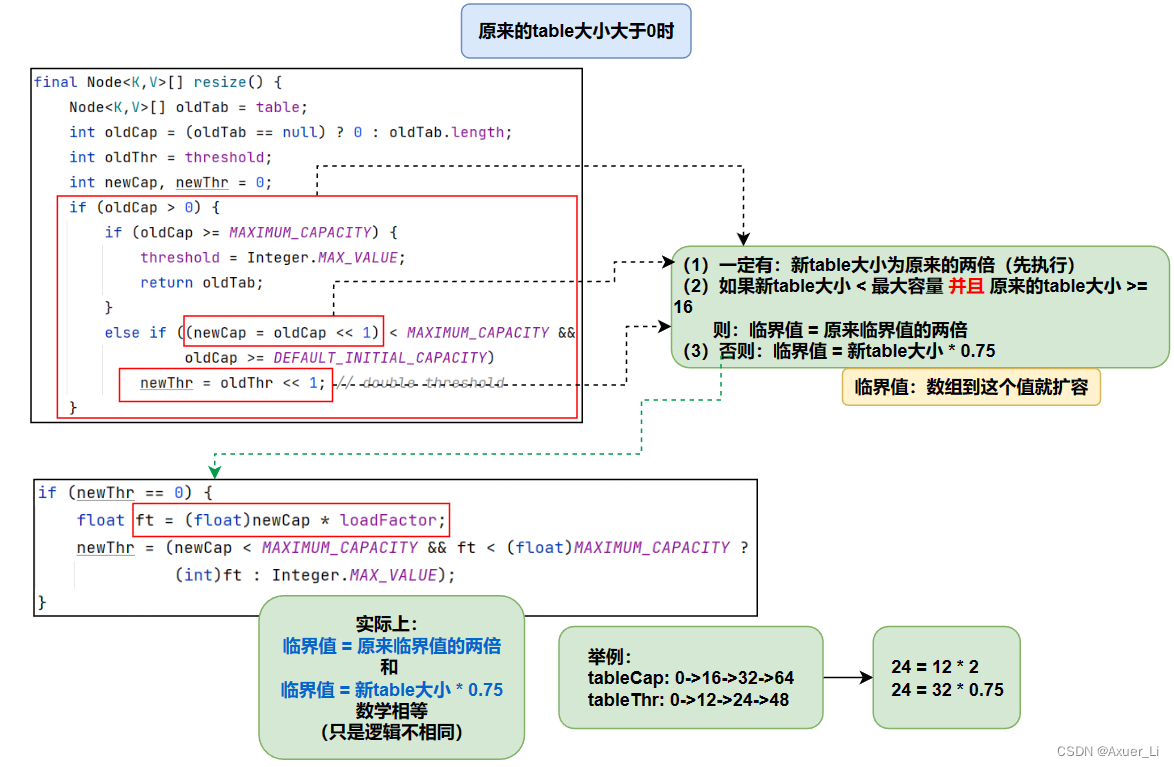
④ 第一次添加,则需要扩容table容量为16,临界值(threshold)为12(16*0.75);
⑤ 以后再扩容,则需要扩容table容量为原来的的2倍(32),临界值为原来的2倍,即24,以此类推;
⑥ 在Java 8中,如果一条链表的元素个数超过TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)。
4、HashMap源码解读
@SuppressWarnings({"all"})
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);//ok
map.put("php", 10);//ok
map.put("java", 20);//替换value
System.out.println("map=" + map);
}
}
/*解读HashMap的源码+图解
1. 执行构造器 new HashMap()
初始化加载因子 loadfactor = 0.75
HashMap$Node[] table = null
2. 执行put 调用 hash方法,计算 key的 hash值 (h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//K = "java" value = 10
return putVal(hash(key), key, value, false, true); */
/*
3. 执行 putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//辅助变量
//如果底层的table 数组为null, 或者 length =0 , 就扩容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取出hash值对应的table的索引位置的Node, 如果为null, 就直接把加入的k-v
//, 创建成一个 Node ,加入该位置即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;//辅助变量
// 如果table的索引位置的key的hash相同和新的key的hash值相同,
// 并 满足(table现有的结点的key和准备添加的key是同一个对象 || equals返回真)
// 就认为不能加入新的k-v
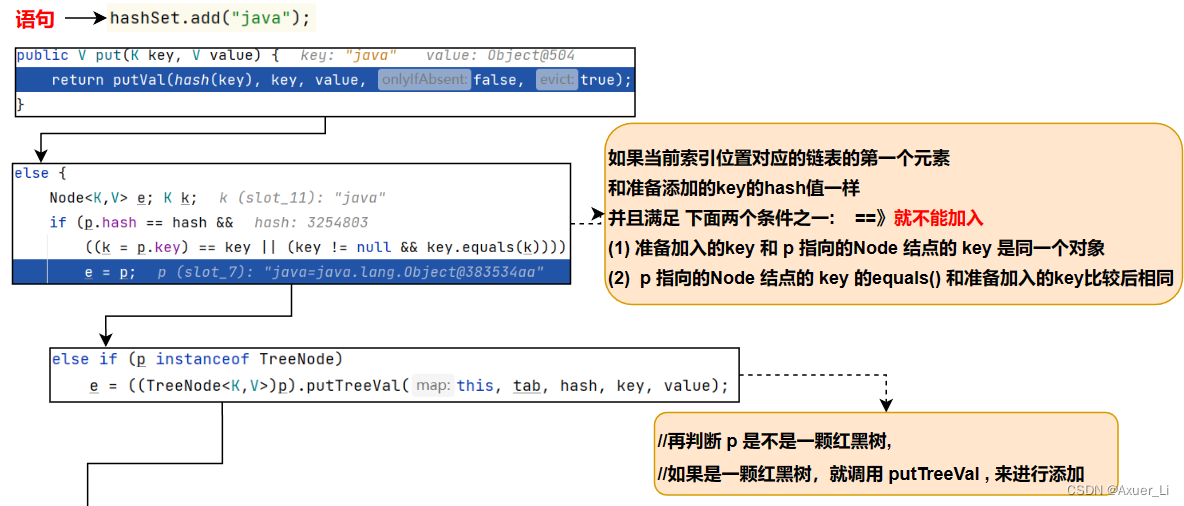
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果当前的table的已有的Node 是红黑树,就按照红黑树的方式处理
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//如果找到的结点,后面是链表,就循环比较
else {
for (int binCount = 0; ; ++binCount) {//死循环
//如果整个链表,没有和他相同,就加到该链表的最后
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//加入后,判断当前链表的个数,是否已经到8个,到8个,后
//就调用 treeifyBin 方法进行红黑树的转换
//(treeifyBin内部还要判断table大小)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果在循环比较过程中,发现有相同,就break,就只是替换value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//由前面的e = p跳转而来,当key相同时,替换value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //替换,key对应value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//每增加一个Node ,就size++
if (++size > threshold[12-24-48])//如size > 临界值,就扩容
resize();
afterNodeInsertion(evict);
return null;
}
*/
/*
5. 关于树化(转成红黑树)
//如果table 为null ,或者大小还没有到 64,暂时不树化,而是进行扩容.
//否则才会真正的树化 -> 剪枝(数据量不大的时候,树重新变回链表的过程)
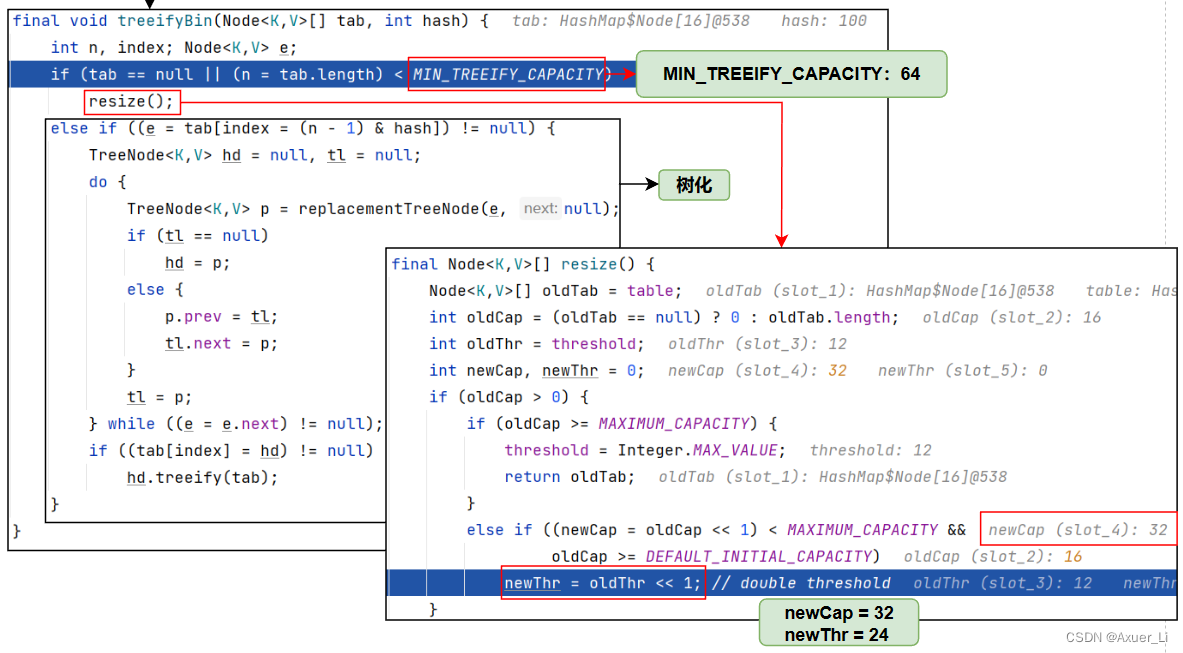
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
}
*/
}
}
5、模拟HashMap触发扩容、树化情况
@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
HashMap hashMap = new HashMap();
for(int i = 1; i <= 12; i++) {
hashMap.put(i, "hello");
}
hashMap.put("aaa", "bbb");
System.out.println("hashMap=" + hashMap);//12个 k-v
}
}
class A {
private int num;
public A(int num) {
this.num = num;
}
//所有的A对象的hashCode都是100
@Override
public int hashCode() {
return 100;
}
@Override
public String toString() {
return "\nA{" +
"num=" + num +
'}';
}
}
六、HashTable
1、HashTable基本介绍
① 存放的元素是键值对:即K-V;
② hashtable的键和值都不能为null,否则会抛出NullPointerException;
③ hashTable使用方法基本上和hashMap一样;
④ hashTable是线程安全的(synnchronized),hashMap是线程不安全的;
⑤ hashTable的应用实例(包括扩容)
@SuppressWarnings({"all"})
public class Test {
public static void main(String[] args) {
Hashtable table = new Hashtable();//ok
table.put("john", 100); //ok
//table.put(null, 100); //异常 NullPointerException
//table.put("john", null);//异常 NullPointerException
table.put("lucy", 100);//ok
table.put("lic", 100);//ok
table.put("lic", 88);//替换
table.put("hello1", 1);
table.put("hello2", 1);
table.put("hello3", 1);
table.put("hello4", 1);
table.put("hello5", 1);
table.put("hello6", 1);
System.out.println(table);
//简单说明一下Hashtable的底层
//1. 底层有数组 Hashtable$Entry[] 初始化大小为 11
//2. 临界值 threshold 8 = 11 * 0.75
//3. 扩容: 按照 int newCapacity = (oldCapacity << 1) + 1; 的大小扩容.(原容量*2 + 1)
//4. 执行 方法 addEntry(hash, key, value, index); 添加K-V 封装到Entry
//5. 当 if (count >= threshold) 满足时,就进行扩容
}
}
2、HashTable底层结构
- 底层有数组 table,类型为
Hashtable$Entry[],初始化大小为11 - 临界值
threshold为 8 => 11 * 0.75 - 扩容: 按照 int newCapacity = (oldCapacity << 1) + 1; 的大小扩容.(原容量*2 + 1)
- 执行 方法 addEntry(hash, key, value, index); 添加K-V 封装到Entry
- 当 if (count >= threshold) 满足时,就进行扩容
七、Properties
1、基本介绍
① Properties类继承自Hashtable类并且实现了Map接口,也是使用一种键值对的形式来保存数据;
② 它的使用特点和Hashtable类似;
③ Properties 还可以用于 从xxx.properties 文件中,加载数据到Properties类对象,并进行读取和修改;
④ 工作中,xxx.properties 文件通常为配置文件,在IO流举例。
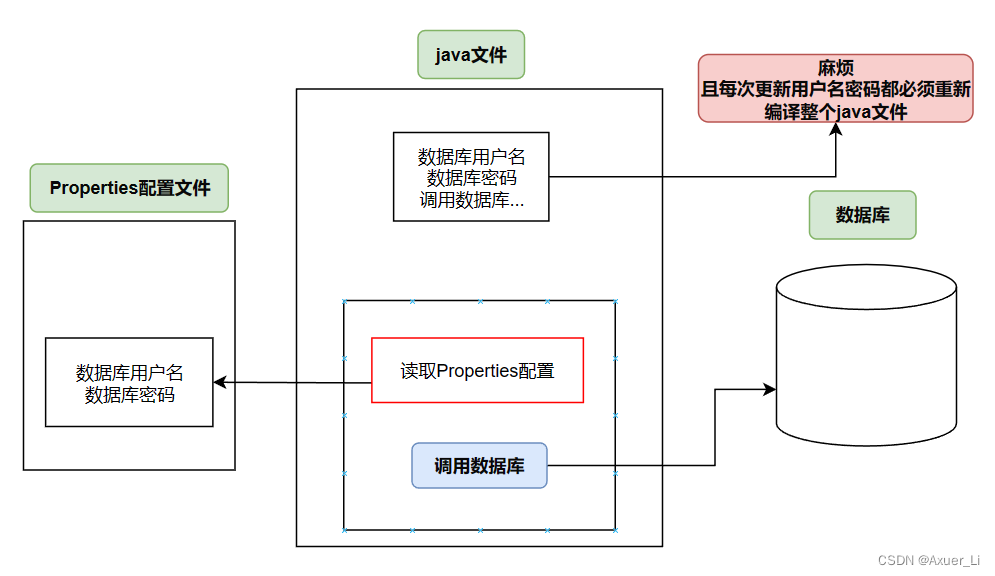
2、基本使用
put//增加
- Properties 继承 Hashtable
- 可以通过 k-v 存放数据,但key 和 value 不能为 null
-
get/getProterty通过k 获取对应值 -
remove删除
@SuppressWarnings({"all"})
public class Properties_ {
public static void main(String[] args) {
//解读
//1. Properties 继承 Hashtable
//2. 可以通过 k-v 存放数据,当然key 和 value 不能为 null
//增加
Properties properties = new Properties();
//properties.put(null, "abc");//抛出 空指针异常
//properties.put("abc", null); //抛出 空指针异常
properties.put("john", 100);//k-v
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//如果有相同的key , value被替换
System.out.println("properties=" + properties);
//查找,通过k 获取对应值
System.out.println(properties.get("lic"));//88
System.out.println(properties.getProperty("lic"));//88
//删除
properties.remove("lic");
System.out.println("properties=" + properties);
//修改
properties.put("john", "约翰");
System.out.println("properties=" + properties);
}
}
八、TreeSet
-
当我们使用无参构造器,创建TreeSet时,仍然是无序的
-
老师希望添加的元素,按照字符串大小来排序
-
使用TreeSet 提供的一个构造器,可以传入一个比较器(匿名内部类)
并指定排序规则 -
Comparator也相当于一个自定义的hashCode和equals方法:作用 -》重复的元素不能加入TreeMap中(这里的‘重复’是自己定义的,比如数组长度相同,则定义为重复)
-
TreeSet底层是TreeMap
@SuppressWarnings({"all"})
public class TreeSet_ {
public static void main(String[] args) {
//解读
//1. 当我们使用无参构造器,创建TreeSet时,仍然是无序的
//2. 老师希望添加的元素,按照字符串大小来排序
//3. 使用TreeSet 提供的一个构造器,可以传入一个比较器(匿名内部类)
// 并指定排序规则
//4. 简单看看源码
//老韩解读
/*
1. 构造器把传入的比较器对象,赋给了 TreeSet的底层的 TreeMap的属性this.comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 在 调用 treeSet.add("tom"), 在底层会执行到
if (cpr != null) {//cpr 就是我们的匿名内部类(对象)
do {
parent = t;
//动态绑定到我们的匿名内部类(对象)compare
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果相等,即返回0,这个Key就没有加入
return t.setValue(value);
} while (t != null);
}
*/
// TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面 调用String的 compareTo方法进行字符串大小比较,若字符串内容完全相同,则不再添加
//如果老韩要求加入的元素,按照长度大小排序,若长度相同则不再添加
//return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();
}
});
//添加数据.
treeSet.add("jack");
treeSet.add("tom");//3
treeSet.add("sp");
treeSet.add("a");
treeSet.add("abc");//在添加前,进行了compare方法
//其中abc的长度和tom长度相等,所以abc直接return返回
//并没有被加入treeSet中
System.out.println("treeSet=" + treeSet); //treeSet=[a, sp, tom, jack]
}
}
九、TreeMap
@SuppressWarnings({"all"})
public class TreeMap_ {
public static void main(String[] args) {
//使用默认的构造器,创建TreeMap, 是无序的(也没有排序)
/*
要求:按照传入的 k(String) 的大小进行排序
*/
// TreeMap treeMap = new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照传入的 k(String) 的大小进行排序
//按照K(String) 的长度大小排序
//return ((String) o2).compareTo((String) o1);
return ((String) o2).length() - ((String) o1).length();
}
});
treeMap.put("jack", "杰克");
treeMap.put("tom", "汤姆");
treeMap.put("kristina", "克瑞斯提诺");
treeMap.put("smith", "斯密斯");
treeMap.put("hsp", "韩顺平");//加入不了
System.out.println("treemap=" + treeMap);
/*
老韩解读源码:
1. 构造器. 把传入的实现了 Comparator接口的匿名内部类(对象),传给给TreeMap的comparator
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
2. 调用put方法
2.1 第一次添加, 把k-v 封装到 Entry对象,放入root
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
2.2 以后添加
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do { //遍历所有的key , 给当前key找到适当位置
parent = t;
cmp = cpr.compare(key, t.key);//动态绑定到我们的匿名内部类的compare
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else //如果遍历过程中,发现准备添加Key 和当前已有的Key 相等,就不添加
return t.setValue(value);
} while (t != null);
}
*/
}
}
十、开发中如何选择集合实现类

十一、Collections工具类
1、Collections基本介绍
2、Collections常用方法
reverse(List)//反转 List 中元素的顺序shuffle(List)//对 List 集合元素进行随机排序sort(List)//根据元素的自然顺序对指定 List 集合元素按升序排序sort(List,Comparator)//根据指定的 Comparator 产生的顺序对 List 集合元素进行排序swap(List,int, int)//将指定 list 集合中的 i 处元素和 j 处元素进行交换Object max(Collection)//根据元素的自然顺序,返回给定集合中的最大元素Object max(Collection,Comparator)//根据 Comparator 指定的顺序,返回给定集合中的最大元素Object min(Collection)//根据元素的自然顺序,返回给定集合中的最小元素Object min(Collection,Comparator)//根据 Comparator 指定的顺序,返回给定集合中的最小元素int frequency(Collection,Object)//返回指定集合中指定元素的出现次数void copy(List dest,List src)//将src中的内容复制到dest中boolean replaceAll(List list,Object oldVal,Object newVal)//使用新值替换 List 对象的所有旧值
@SuppressWarnings({"all"})
public class Collections_ {
public static void main(String[] args) {
//创建ArrayList 集合,用于测试.
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
//1. reverse(List):反转 List 中元素的顺序
Collections.reverse(list);
System.out.println("===反转后===");
System.out.println("list=" + list);
//2. shuffle(List):对 List 集合元素进行随机排序
Collections.shuffle(list);
System.out.println("===随机排序后===");
System.out.println("list=" + list);
//3. sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);
System.out.println("===自然排序后===");
System.out.println("list=" + list);
//4. sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//我们希望按照 字符串的长度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校验代码.
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("===按照字符串长度大小排序===");
System.out.println("list=" + list);
//5. swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
Collections.swap(list, 0, 1);
System.out.println("===0、1位置交换后===");
System.out.println("list=" + list);
System.out.println("=====================================");
//6. Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list));
//7. Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//比如,我们要返回长度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("长度最大的元素=" + maxObject);
//8. Object min(Collection)
//9. Object min(Collection,Comparator)
//上面的两个方法,参考max即可
//10. int frequency(Collection,Object):返回指定集合中指定元素的出现次数
System.out.println("tom出现的次数=" + Collections.frequency(list, "tom"));
//11. void copy(List dest,List src):将src中的内容复制到dest中
ArrayList dest = new ArrayList();
//注意:为了完成一个完整拷贝,我们必须先给dest 赋值,大小和list.size()一样
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷贝
Collections.copy(dest, list);
System.out.println("将list拷贝到dest后,dest=" + dest);
//12. boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
Collections.replaceAll(list, "tom", "汤姆");//如果list中,有tom 就替换成 汤姆
System.out.println("list替换后=" + list);
}
}
十二、章作业
【第一题】

public class Test {
public static void main(String[] args) {
ArrayList arrayList = new ArrayList();
arrayList.add(new News("新冠确诊病例超千万,数百万印度教信徒赴恒河“圣浴”引民众担忧"));
arrayList.add(new News("男子突然想起2个月前钓的鱼还在网兜里,捞起一看赶紧放生"));
//3. 倒序遍历
for (int i = arrayList.size()-1; i >=0 ; i--) {
News news = (News)arrayList.get(i);
String title = news.getTitle();
System.out.println(processTitle(title));
}
}
public static String processTitle(String title) {
if(title.length() > 15) {
return title.substring(0,15) + "...";
} return title;
}
}
class News {
private String title;
private String content;
public News(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "news{title='" + title + "'}";
}
}
【第二题】

public class Test {
public static void main(String[] args) {
Map m = new HashMap();
m.put("jack", 650); //int->Integer(自动装箱)
m.put("tom", 1200);
m.put("smith", 2900);
m.put("jack",2600);
Set entryset = m.entrySet();
for (Object entry : entryset) {
Map.Entry e = (Map.Entry) entry;
e.setValue((Integer)e.getValue() + 100);
}
//遍历员工
for (Object entry : entryset) {
Map.Entry e = (Map.Entry) entry;
System.out.println(e.getKey() + " " + e.getValue());
}
//遍历工资
Collection values = m.values();
Iterator iterator = values.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
}
}
【第三题】

- HashSet:
- 先重写
hashCode(),使相同元素一定有相同的hash值,存放在table表的同一个位置,保证table表头不重复 - 再重写
equals(),使在同一链表中比较元素时,相同的元素不能插入。保证一条链表上没有重复元素
- 先重写
- TreeSet:
- 重写
Comparator匿名对象,如果方法返回0,就认为是相同元素,比较到相同元素则不能添加。如果没有传入一个Comparator匿名对象,则以你添加的对象实现的Comparable接口的compareTo去重 - PS:添加第一个元素时,没有调用Comparator,但会调用compare方法检验添加的值是否为空。不为空=》即使compare方法返回0也还是会添加该元素
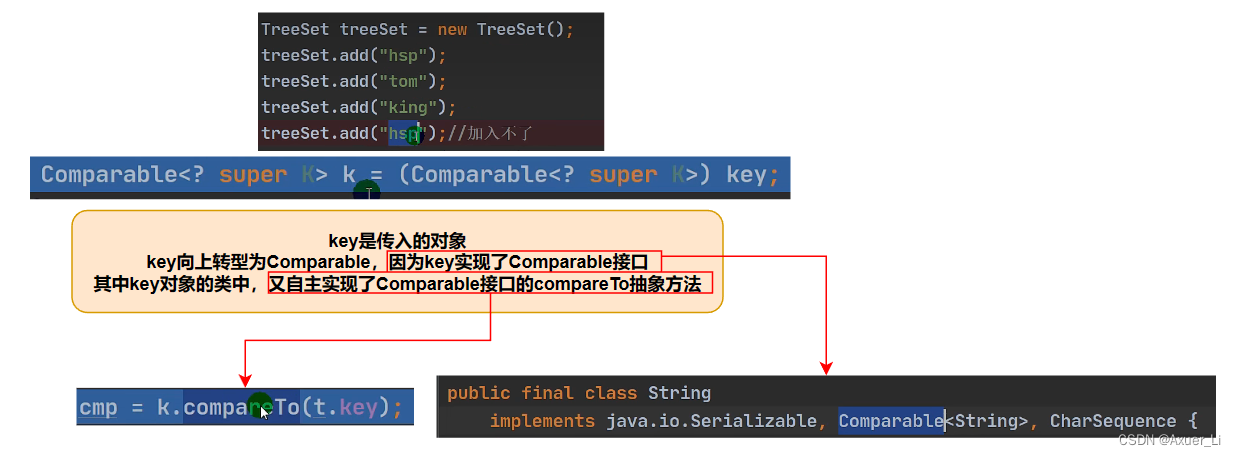
- 重写
【第四题】

会抛出异常,因为Person没有实现Comparable接口,(Person没有实现Comparable接口的compareTo方法)
在下面这一步会报错ClassCastException

解决办法:让Person类实现Comparable接口方法
public class Test {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();
treeSet.add(new Person()); //添加第一个元素时,不会用Comparator进行比较(也就是即使compare返回0也还是会添加元素),但会用compare检验是否添加的值为空
//下面的都加不进去
treeSet.add(new Person());
treeSet.add(new Person());
treeSet.add(new Person());
treeSet.add(new Person());
treeSet.add(new Person());
System.out.println(treeSet);
}
}
class Person implements Comparable{
@Override
public int compareTo(Object o) {
return 0;
}
}
【第五题】
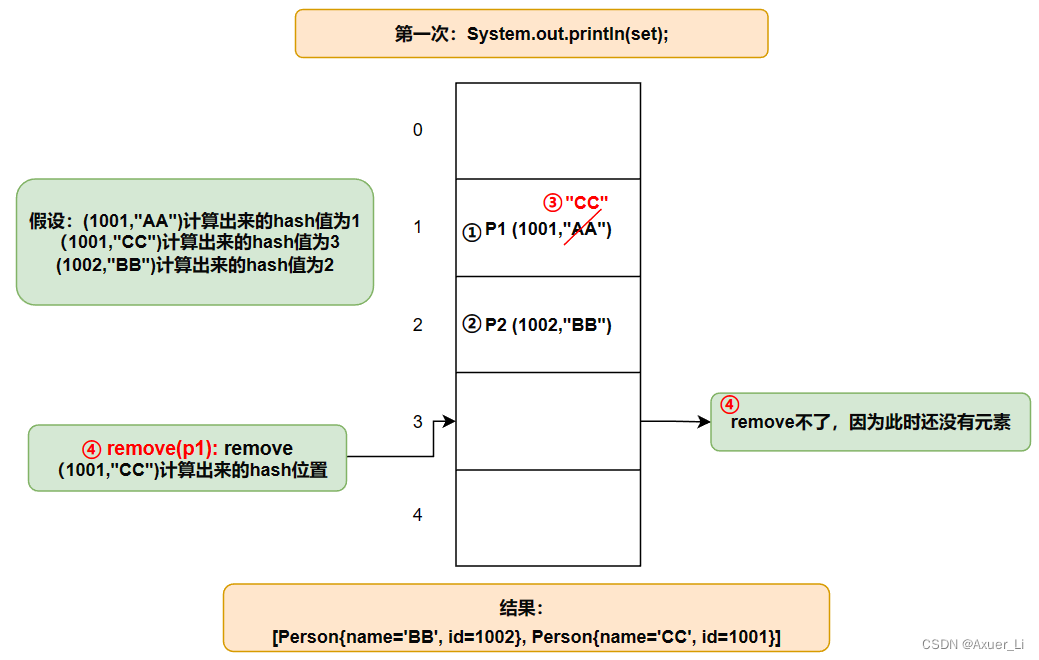
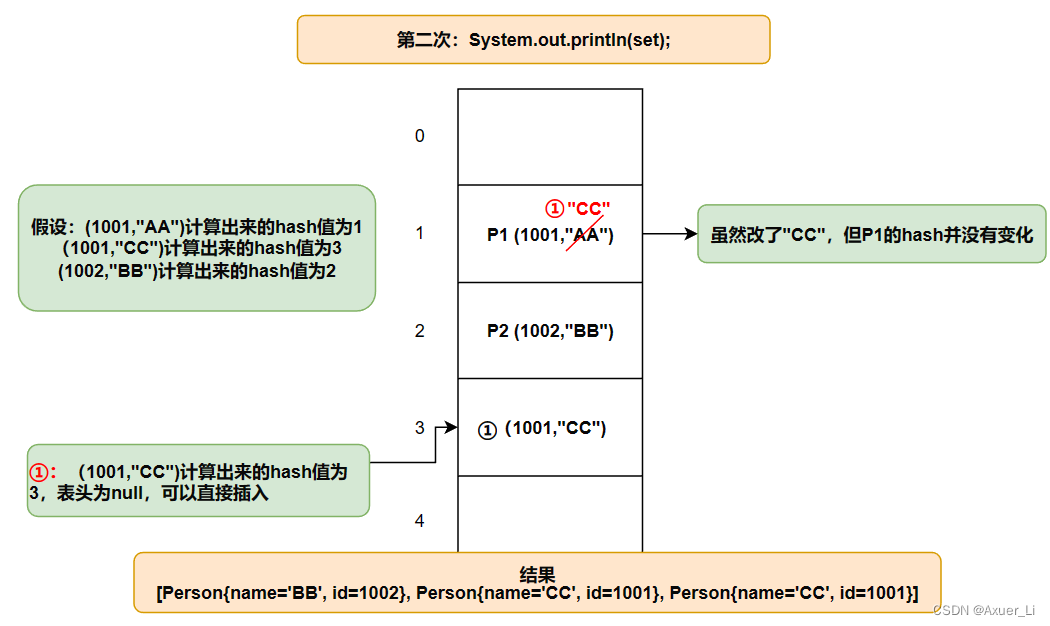
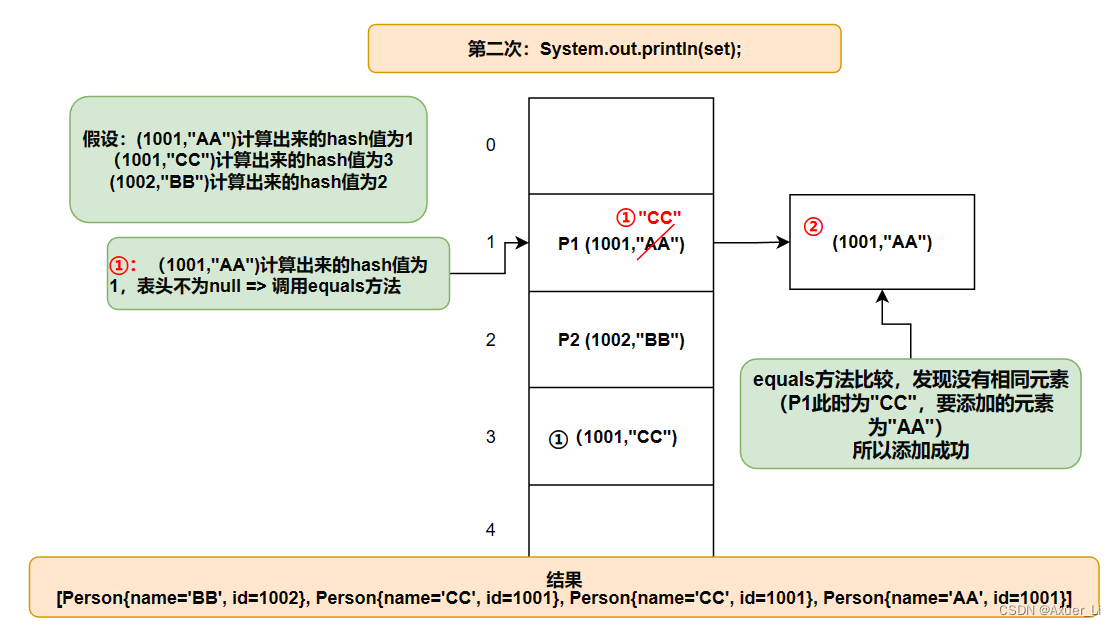
① 在set.remove(p1)时候,因为p1的name已经改变了,remove时会根据p1此时的name和id来计算hash值,索引,计算出的位置与添加进去时候的位置不同,没找到,所以删除失败;
② set.add(new Person(1001,“CC”))时候,虽然与此时的p1的name和id一样,但是p1的hash值和索引已经在改变p1name前就确定了,所有在添加这个新对象时候检测的hash值和索引值与p1的不一样,可以加入;
③ set.add(new Person(1001,“AA”))时候,虽然此时新对象的hash值和索引值与p1的一样,但是
它们的name不一样,就equals不同,所以它加在p1的链表后面,可以加入。
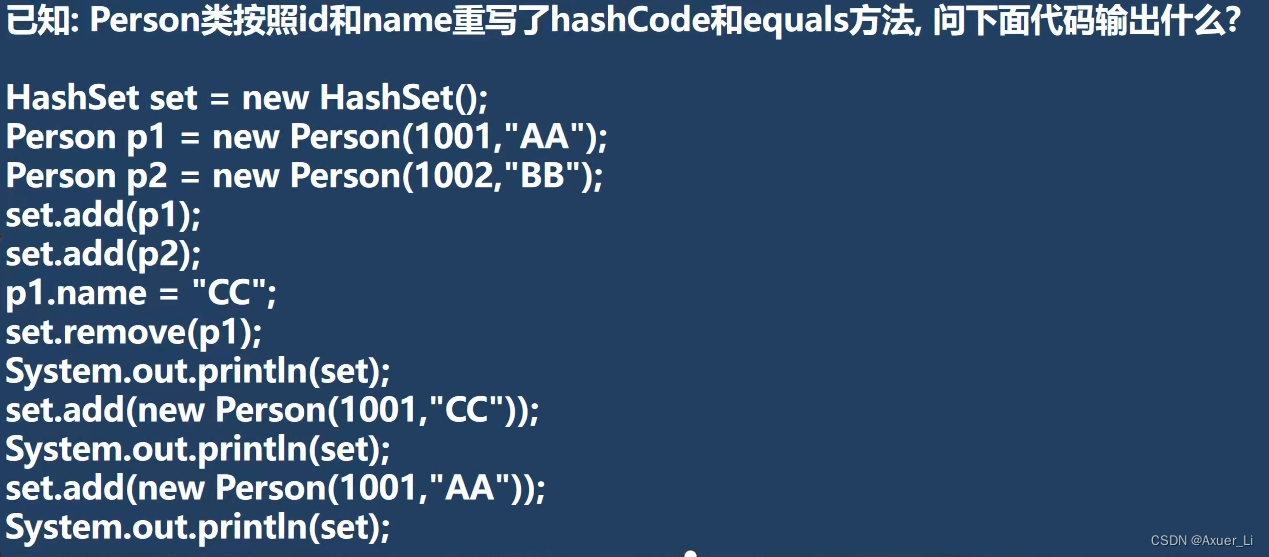
public class Test {
public static void main(String[] args) {
@SuppressWarnings({"all"})
HashSet set = new HashSet();//ok
Person p1 = new Person(1001, "AA");//ok
Person p2 = new Person(1002, "BB");//ok
set.add(p1);//ok
set.add(p2);//ok
p1.name = "CC";
set.remove(p1);
System.out.println(set);//2
set.add(new Person(1001, "CC"));
System.out.println(set);//3
set.add(new Person(1001, "AA"));
System.out.println(set);//4
}
}
class Person {
public String name;
public int id;
public Person(int id, String name) {
this.name = name;
this.id = id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id &&
Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, id);
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", id=" + id +
'}';
}
}
十三、集合类常用快捷键
1、迭代器Iterator模板快捷键
输入itit回车即可。
2、增强for模板快捷键
输入大写I即可。
3、显示所有快捷键的快捷键
按ctrl + j 即可。















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









