







1.下载地址:https://mirrors.aliyun.com/apache/spark/spark-3.0.0/
下载这个:spark-2.2.1-bin-hadoop2.7.tgz
解压tar -zxvf 文件名,改名 mv 老名 新名
2.修改配置文件:
[root@node7-2 conf]# cp slaves.template slaves
[root@node7-2 conf]# cp spark-env.sh.template spark-env.sh
slavers:
node7-2
node7-3
node7-4
spark-env.sh:
SPARK_MASTER_HOST=node7-2
SPARK_MASTER_PORT=7077
分发:
[root@node7-2 spark]# scp -r spark-hadoop/ node7-3:`pwd`
[root@node7-2 spark]# scp -r spark-hadoop/ node7-4:`pwd`3.node7-2上启动:sbin/start-all.sh
三台虚拟机查看:jps
[root@node7-2 spark-hadoop]# jps
3125 Master
3351 Jps
3199 Worker
[root@node7-3 spark-hadoop]# jps
3089 Worker
3228 Jps
[root@node7-4 spark-hadoop]# jps
3173 Worker
3309 Jps
网址访问:http://node7-2:8080/
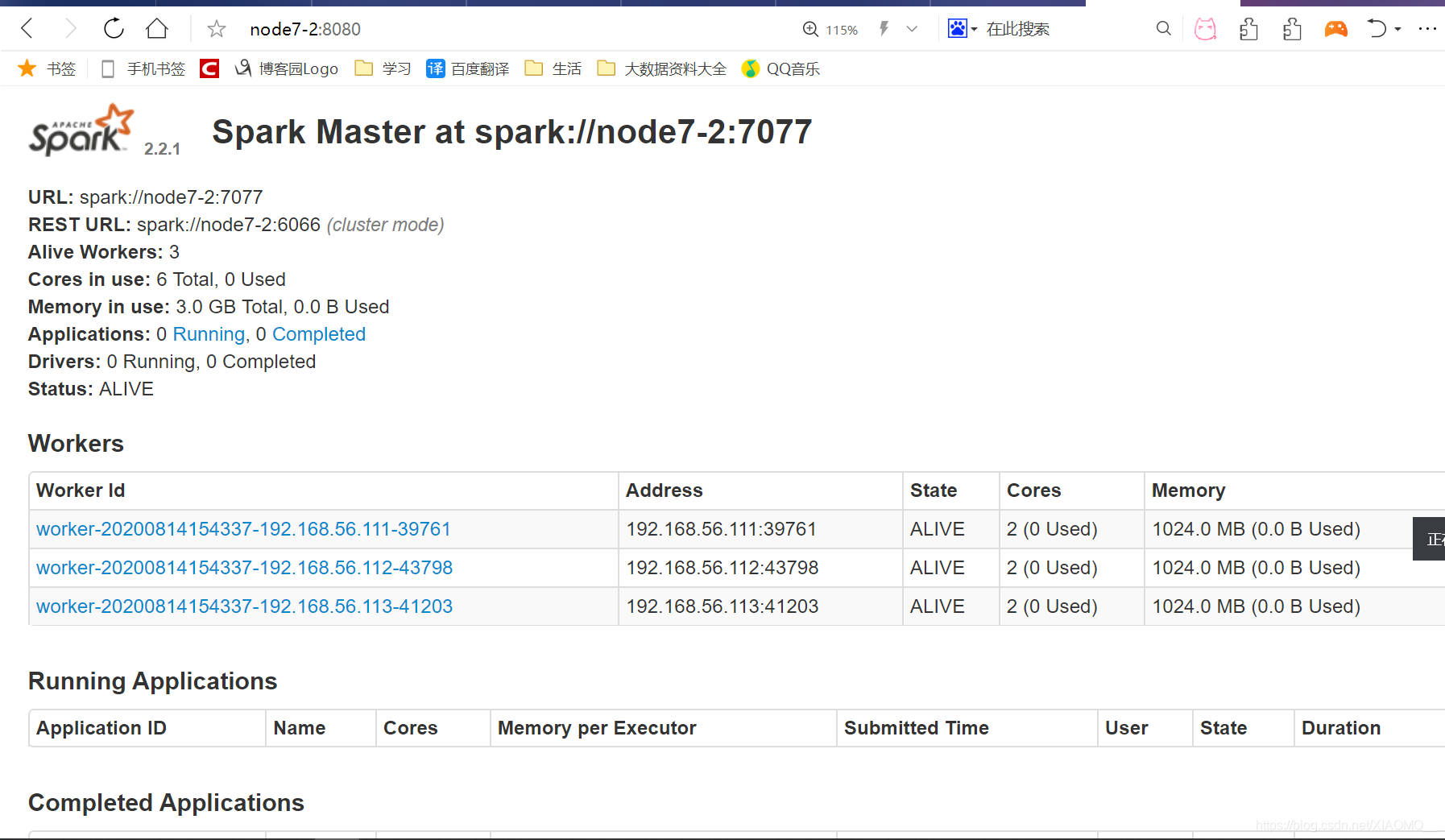
4.JobHistoryServer 配置:
文件复制:
cp spark-defaults.conf.template spark-defaults.confspark-defaults.conf:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node7-2:8020/directoryspark-env.sh:
SPARK_MASTER_HOST=node7-2
SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://node7-2:8020/directory"
启动hadoop并在hdfs创建/directory目录:
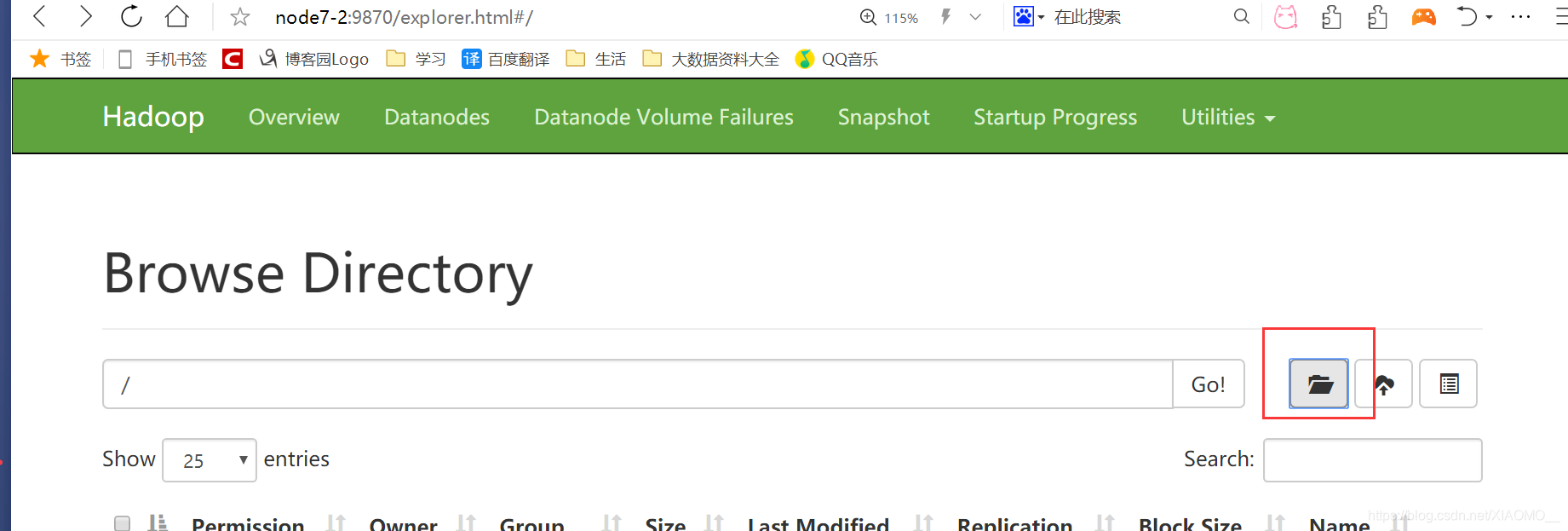
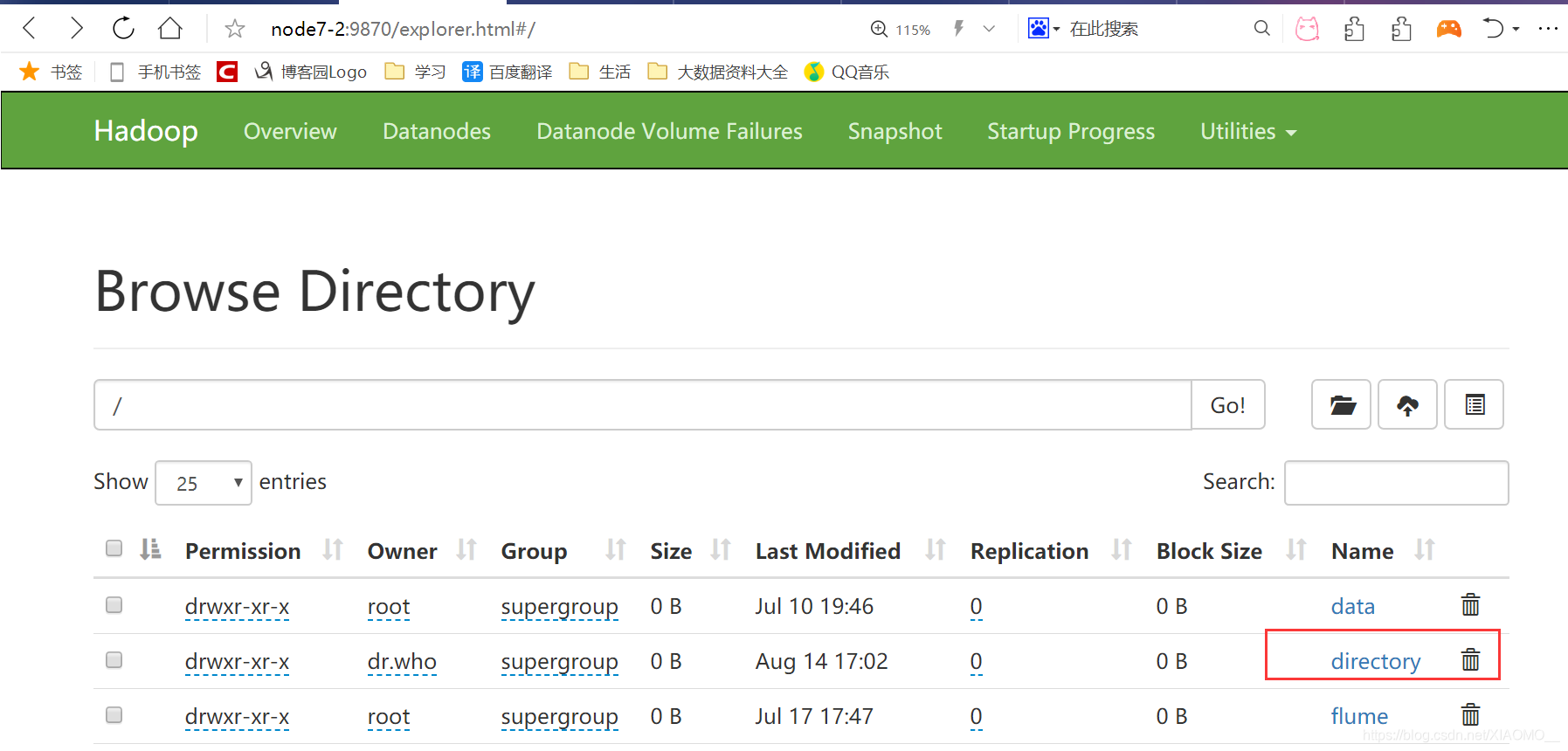
启动history: sbin/start-history-server.sh
jps:
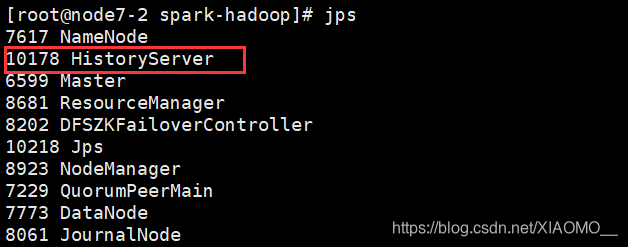
查看到后,输入网址:http://node7-2:18080/
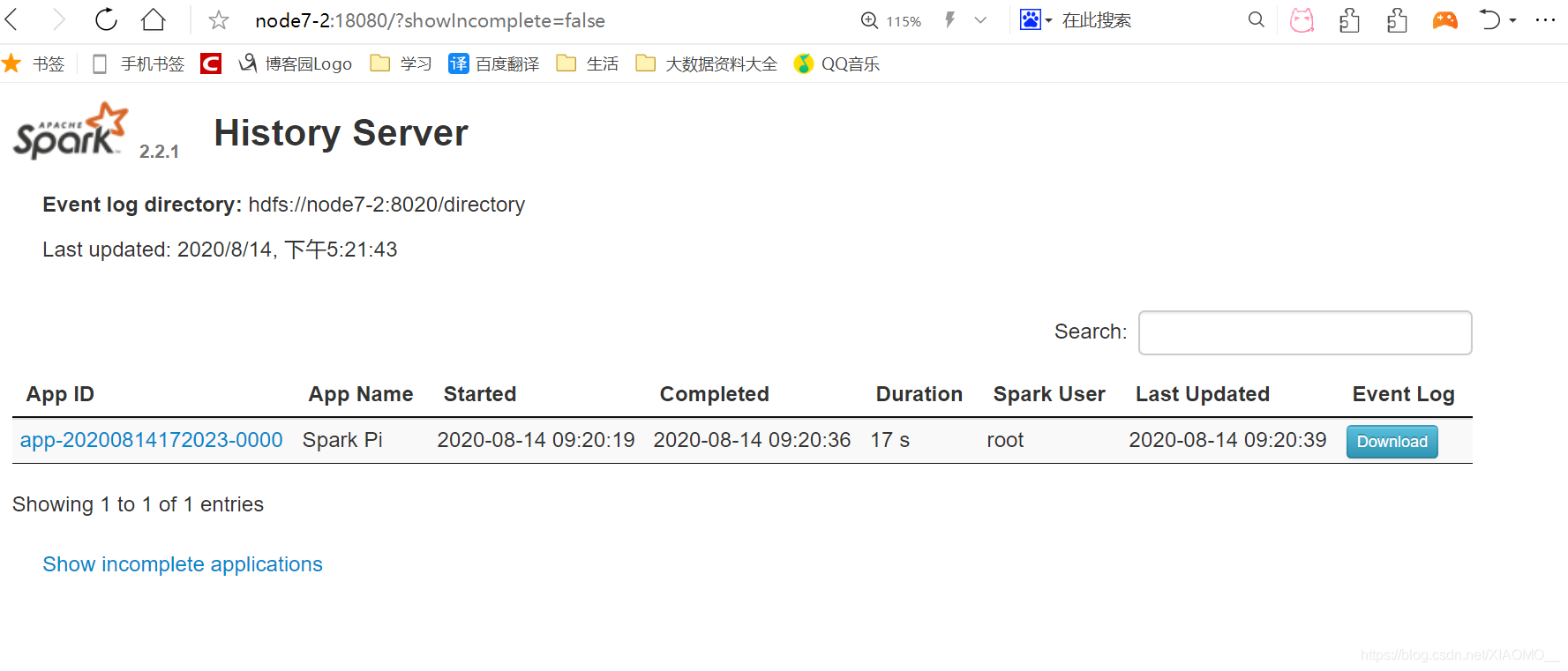
运行一段代码:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://node7-2:7077 --executor-memory 1G --total-executor-cores 2 ./examples/jars/spark-examples_2.11-2.2.1.jar成功后显示
5.高可用
配置文件:vim spark-env.sh
SPARK_MASTER_HOST=node7-2
SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://node7-2:8020/directory"
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node7-2分发到3,4:
[root@node7-2 conf]# scp -r spark-env.sh node7-3:`pwd`
spark-env.sh 100% 4142 1.9MB/s 00:00
[root@node7-2 conf]# scp -r spark-env.sh node7-4:`pwd`
spark-env.sh 100% 4142 3.0MB/s 00:00node7-2:sbin/start-all.sh
node7-3: sbin/start-master.sh
spark HA 集群访问:
oot@node7-2 spark-hadoop]# bin/spark-shell --master spark://node7-2:7077,node7-3:7077 --executor-memory 2g --total-executor-cores 2
Spark context Web UI available at http://192.168.56.111:4040
Spark context available as 'sc' (master = spark://node7-2:7077,node7-3:7077, app id = app-20200814173518-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_251)
Type in expressions to have them evaluated.
Type :help for more information.
scala> yarn:
yarn-site.xml在hadoop中:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值, 则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,大数据技术之 Spark 基础解析 ————————————————————————————— 13 则直接将其杀掉,默认是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
spark-env.sh,并分发3,4:YARN_CONF_DIR=/data/hadoop/hadoop/etc/hadoop
执行一个小任务:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.2.1.jar 100
日志查看:3台都改
spark-defaults.conf
spark.yarn.historyServer.address=node7-2:18080
spark.history.ui.port=18080
重启 spark 历史服务:(在2中)
sbin/stop-history-server.sh
sbin/start-history-server.sh
提交任务:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.11-2.1.1.jar 100















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









