










目录
前面内容请移步
资源下载+毕业论文+答辩
4.2 系统异常处理
系统在运行过程中因为复杂的运行环境,可能会产生种种异常问题。
4.2.1 爬虫异常总体概况
爬虫异常总体概况就是能让爬虫的维护人员能及时了解爬虫的整体运行状态,例如当前爬虫是否处于阻塞状态,阻塞的原因是什么,目前已经爬取了多少内容,还有多少内容有待爬取?当前爬虫正在爬取哪个页面?爬虫在进行数据存储的过程中有哪些异常?通过上面的数据可以得到下列结论:
爬虫程序的健壮性。观察爬虫爬取的网页文档数据,通过分析就能够得出爬虫在网页文档数据的时候出现的各种异常问题,便于爬虫系统代码的优化。
爬虫程序的爬取效率。通过log系统记录爬虫爬取网页时打印的Log,经过一些统计整合,可以得出爬虫的数据采集能力究竟有多强,如果采集速度太慢,可以进行一些多线程方面的优化处理,同时也要检查是否是代码某处出的BUG。
爬虫对客体网站的影响。如果发现爬虫运行一段时间后,无法再从某个网站中采集到网页文档数据,这时候就算考虑下是否是爬虫爬取网页文档数据过于频繁而被网站管理员封锁。
4.2.2 爬虫访问网页被拒绝
爬虫大量爬取网站时,会对网站资源占用严重,所以很多网站加入了反爬虫机制,大量爬取网站数据时,会出现Access Denied一类的错误,网页服务器直接拒绝了访问,这时候爬虫就得需要能伪装的像一个真正的浏览器一样,有如下方法:
(1)伪装User-Agent
User-Agent标明了浏览器的类型,以便Web网站服务器能识别不同类型的浏览器。为什么要识别不同类型的浏览器呢?现在主流的优秀浏览器有windows10的Edge浏览器、微软的IE系列浏览器、谷歌的Chrome浏览器、Mozilla的FireFox浏览器,还有来自挪威的Opera浏览器,这些浏览器五花八门,分别出自各自的厂家,所以面对同样的html元素,他们的解析效果有可能是非常不同的,甚至会出现无法解析一些Html元素的情况,正式因为如此,所以Web网站服务器要判断不同的浏览器以便提供不同支持方案(例如CSS中针对不同的浏览器可能需要不同的标注)。
所以现在绝大部分的爬虫为了能够及时获取网站的数据,通常会设置一个某种浏览器的User-Agent以此来“欺骗”网站,告诉Web网站服务器自己是某一种浏览器,然后网站Web服务器才会返回真实的网页数据,一般比较常见几个浏览器的User-Agent如下:
Chrome的User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36
火狐的User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0
IE的User-Agent:Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; .NET4.0E; .NET4.0C; .NET CLR 3.5.30729; .NET CLR 2.0.50727; .NET CLR 3.0.30729; rv:11.0) like Gecko
HttpClient设置User Agent的方法如下:
HttpGet getMethod = new HttpGet("URL");
getMethod.setHeader("User-Agent", "user agent内容");
(2)需要登录后才能访问网页数据
虽然绝大部分网站不登陆就能访问各个页面的内容,随着各个研究机构对互联网数据的需求越来越多的情况下,各种各样的爬虫随之诞生,但是一部分爬虫会无节制的爬取网站,大大地消耗了网站的带宽,导致正常的用户都无法访问网站,所以现在的绝大部分网站都相应推出了一些防护“恶意爬虫”的策略,例如网站一旦检测到某个IP的访问量有异常,就会要求这个IP访问的时候必须登录后才能访问。不过这样也有解决方法,可以直接在该IP所在主机上用浏览器登录,登录成功之后,如果浏览器是Chrome或者firefox那么可以直接查看浏览器的cookie,用HttpClient设置cookie即可访问即可。不过还有一些检测机制特别严格的网站,登录网站的时候必须填写随机验证码,这类网站的爬取难度可就大了,需要能识别网站随机扭曲的验证码,这些问题在本文不做讨论。
(3)使用代理IP访问
如果网站服务器维护人员用某段时间内某IP的访问次数来判定爬虫,然后将这些爬虫的IP都封掉的话,以上伪装就失效了。为了解决爬虫的IP被相关网站封停,仔细一想,如果爬虫能模拟出一批用户来访问该网站不就能解决这个问题吗?具体应该如何模拟呢?首先需要模拟出一个一个分散而又独立的用户,这就需要随机而又分散到全国各地的IP代理,爬虫运行的时候从这些IP代理中随机选取一部分IP作为代理使用,这样就能比较完美地解决单IP高频率高流量访问网站的问题了。
拥有了这些IP代理之后,应该如何去管理这些代理IP呢?这里可以做一个类似于数据库连接池的东西,当然这里存放的不是数据库连接,而是一个一个的代理IP,然后指定相关的代理IP分配策略。代理IP池做好之后,要做一个负载均衡,每次轮流使用代理IP池中可以正常使用的IP做循环访问,这样单一IP对网页服务器会迅速下降,非常明显。
5 软件测试
软件测试是软件系统开发的一系列流程与活动中的最后一个部分也是最重要的一个部分,是一种为了能保证软件的逻辑上的严密性、严谨性、高可用性的解决方案。通过对软件的逻辑分支的校验,来确定软件是否能达到需求分析中的要求,并且在最大程度上能保证软件不会带来其他的BUG。只有通过了软件测试,整个软件工程的最终产物才能交付给用户使用。
5.1 白盒测试
白盒测试是一种基于软件逻辑结构设计的测试,在整个测试过程中,测试的参与者是完全熟知整个系统的逻辑分支的。白盒测试的盒子是指被测试的软件系统,白盒指的是程序结构与逻辑代码是已知的,非常清楚盒子内部的逻辑结构以及运行逻辑的。“白盒”法全面了解程序内部逻辑结构、对所有逻辑路径都进行相关测试。“白盒测试”会争取能够测试完软件系统中所有的可能的逻辑路径。使用白盒测试的方式时,一定要先画出软件所有的逻辑顺序结构与设计,然后再分别设计出合适而又全面的测试用例,最终完成白盒测试。
5.1.1 爬虫系统测试结果
因为爬虫系统逻辑设计相对来说是比较简单的,不涉及到基本路径法,因为整个正序只需要定时运行就行,不像其他软件系统那样,有较深的用户需求根基,需要相关人员配合使用。本次开发的爬虫系统是全自动的,所以百合测试结果与黑盒测试结果一致。
下图为爬虫系统的百合测试结果截图,测试方法即定时运行爬虫即可,下图中的条目为爬虫此次执行所爬取到结果中的一部分,爬取结果如图5-1所示。

图5-1 爬虫爬取结果
5.1.2 中文分词系统测试结果
中文分词系统测试也比较简单,没有复杂的业务逻辑,结果基本呈线程顺序,且执行路径唯一,下图为中文分词系统的白盒测试结果,首先是测试的语料的截图,如图5-2所示。
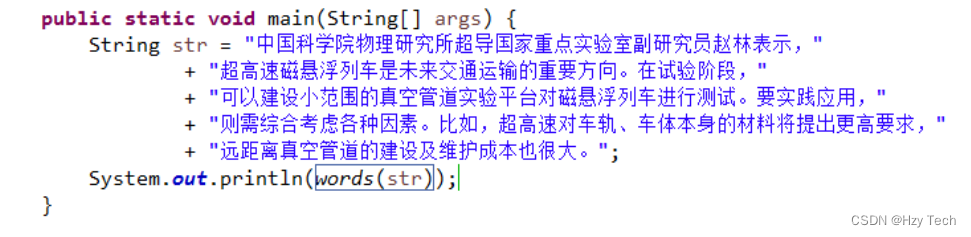
图5-2 中文分词原文
最终的分词结果如下,目前想要提高分词结果非常困难,需要加大词库的准确性,白盒测试结果如图5-3所示:

图5-3 中文分词结果
5.1.3 中文文章相似度匹配系统测试结果
中文文章相似度计算方法采用了余弦定理计算两篇文章所对应的汉语词语的词频向量的夹角的余弦值,在经过大量的试验后发现其准确率还是非常非常高的,测试结果如图5-4所示。

图5-4 余弦定理相似度匹配
可以看出,“国家专项计划引苏鄂家长担忧教育部回应”这篇新闻与“向中西部调剂生源致高考减招数万?湖北江苏连夜回应”两条新闻均是有关高考的,完美匹配到了一起,其次不排除有些极端的情况,导致匹配结果不正确,这个也会继续研究,提高准确率。
5.1.4 相似新闻趋势展示系统测试结果
相似新闻的展示采用了JfreeChart作为白盒测试的测试对象,测试结果如下图所示,精确显示了每一条新闻的关注度走势,如图5-5所示。
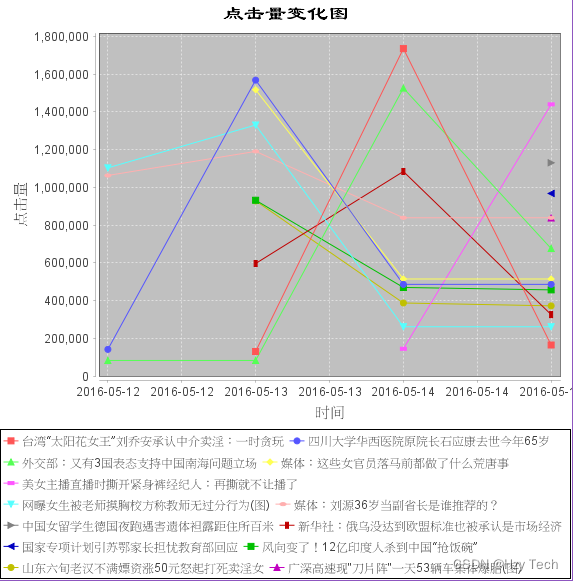
图5-5 JfreeChart测试图
5.2 黑盒测试
黑盒测试与白盒测试恰好相反,从名字就能看出,一黑一白,白盒测试者熟悉盒子中的内容,而黑盒测试者是完全不知道盒子中的内容的。黑盒测试主要是面向程序的功能实现而进行的测试,例如检验程序是否具有某一功能,而完全不必关心程序的逻辑设计。也就是说,整个黑盒测试关注的是软件系统的功能完整性,而不考虑程序逻辑上的BUG等问题。
5.2.1 爬虫系统测试结果
上面已经提到,本爬虫系统逻辑较为简单,白盒测试结果与黑盒测试结果一致,结果如图5-6所示。
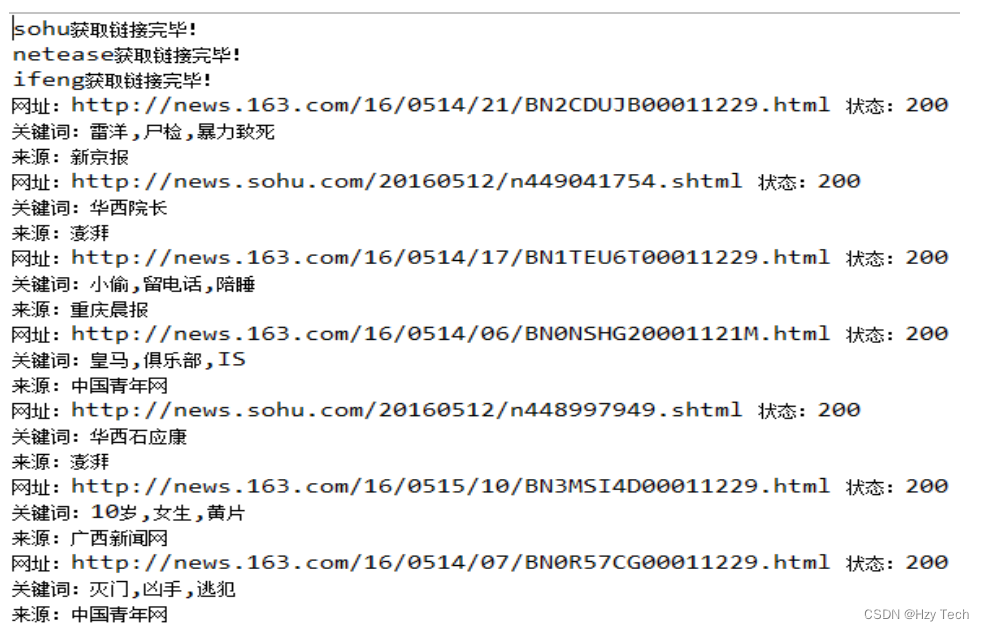
图5-6 爬虫系统黑盒测试
5.2.2 中文文章相似度匹配系统测试结果
总体来说,黑盒测试的结果也是比较令人满意的,同样,瑕疵还是有的,这也是编程的挑战与乐趣所在之处,黑盒测试结果如图5-7所示。

图5-7 中文匹配黑盒测试
5.2.3 相似新闻趋势展示系统测试结果
黑盒测试相似新闻趋势展示系统测试了Echarts的效果,以便能跟白盒测试JfreeChart区别开来,测试结果如图5-8所示。

图5-8 黑盒测试新闻排行
点击上面的相关新闻会出现单个新闻的趋势发展图,如图5-9所示。
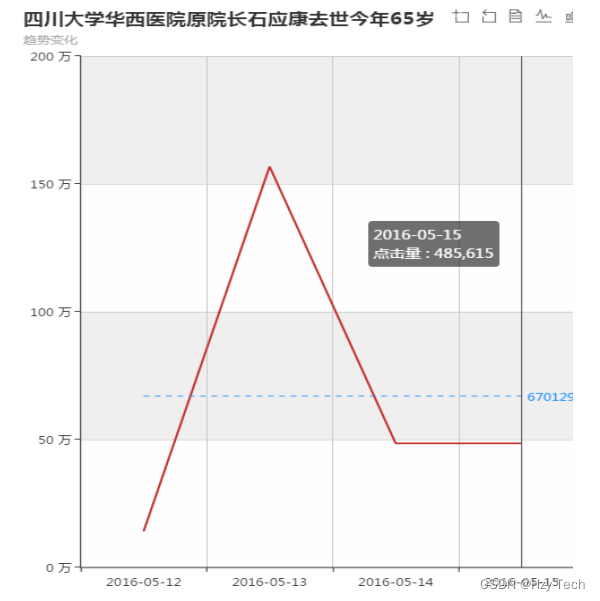
图5-9 echarts黑盒测试
参考文献
- 于娟,刘强. 主题网络爬虫研究综述[J]. 计算机工程与科学, 2015, 37(02):231-237.
- 张红云. 基于页面分析的主题网络爬虫的研究[D]. 武汉理工大学, 2010.
- 张莹. 面向动态页面的网络爬虫系统的设计与实现[D]. 南开大学, 2012.
- 张晓雷. 面向Web挖掘的主题网络爬虫的研究与实现[D]. 西安电子科技大学, 2012.
- 奉国和,郑伟. 国内中文自动分词技术研究综述[J]. 图书情报工作, 2011, 55(2):41-45.
- 许智宏,张月梅,王一. 一种改进的中文分词在主题搜索中的应用[J]. 郑州大学学报, 2014(5):44-48.
- 欧振猛,余顺争. 中文分词算法在搜索引擎应用中的研究[J]. 计算机工程与应用, 2000, 36(08):80-82.
- Batsakis.S, Petrakis E G M, Milios E. Improving the performance of focused web crawlers[J]. Data & knowledge engineering, 2009, 68(10):1001-1013.
- Pant.G, Menczer F. MySpiders:Evolve Your Own Intelligent Web Crawlers[J]. Autonomous agents and multi-agent systems, 2002, 5(2):221-229.
- Ahmadi-Abkenari F, Ali S. A Clickstream-based Focused Trend Parallel Web Crawler[J]. International Journal of Computer Applications, 2010, 9(5):24-28.















 8408
8408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









