







前言
python怎么样打包成exe文件?
好啦。今天我来分享给大家,教大家如何打包好文件,顺便在展示一下,如何替换好图标
首先把你的代码准备好,尽量不要中文路径,容易报错

模块
Pyinstaller
它不是Python默认有的模块,所以需要我们安装一下,直接 pip install Pyinstaller
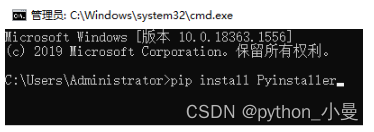
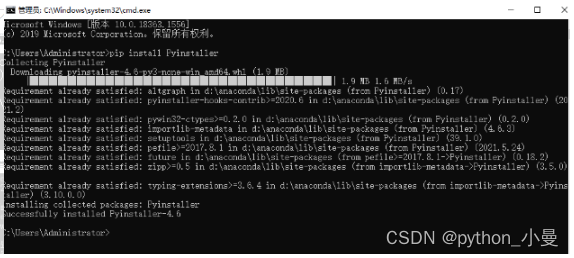
打包
模块安装好后我们开始打包,注意,所有的文件都尽量用英文,免得报错了。
首先我们在CMD里面把目录切换到你的代码存放的那个盘,比如我的是放在C盘,输入C: ,当然,我这里已经在C盘了所以不用切换。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1738
1738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









