






 : 阿代,今天我们来讲下双数组字典树。
: 阿代,今天我们来讲下双数组字典树。
 :豆豆,字典树还不够用吗,为什么还要双数组字典树,它有什么优势吗?
:豆豆,字典树还不够用吗,为什么还要双数组字典树,它有什么优势吗?
 :
:
我们看到,前面的字典树还是有许多空间上的浪费的,双数组字典树可以大幅改善了经典字典树树的空间浪费,它由日本人JUN-ICHI AOE于1989年提出的,是字典树结构的压缩形式,仅用两个线性数组来表示Trie树,检索时间高效且空间结构紧凑。
 : 真厉害,他是怎么做到的呢?
: 真厉害,他是怎么做到的呢?
 :
:
他是通过两个数组base、check来实现。
先看下面的公式:
p = base[b] + c
check[p] = bbase数组中的b代表当前状态的下标,p代表转移状态的下标,c代表输入字符的数值
base[b] + c = p ,表示一次状态转移
由于转移后状态下标为p,且父子关系是唯一的,所以可通过检验当前元素的前驱状态确定转移是否成功。
check[p] = b ,检验状态转移是否成功。
 :好抽象,我不是很明白。
:好抽象,我不是很明白。
 :
:
我们举个具体的例子吧。
有下面几个词:
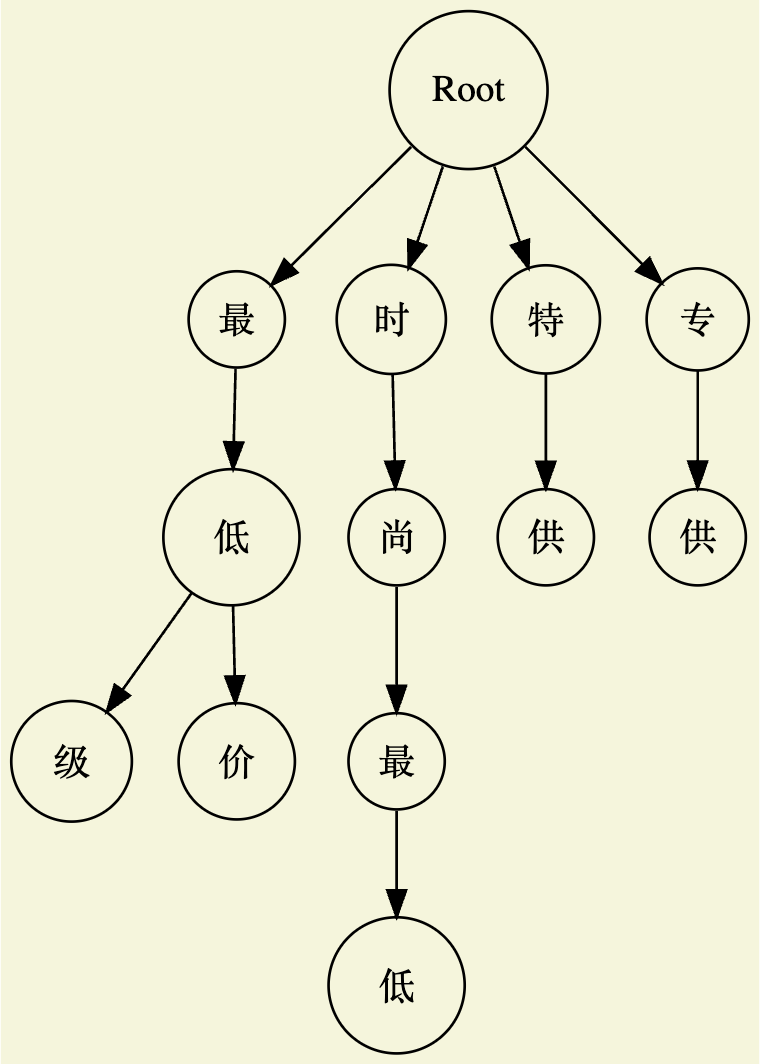
设例树的字符编码表为:
char | 最 | 低 | 级 | 时 | 尚 | 价 | 特 | 供 | 专 |
code | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
初始化root的base index为0,base值记为1。首先看root的所有子节点"最,时,特,专",对应编码“1,4,7,9”:
• base[0] + code(最) = 2,此时位置2空闲,因此“最”放入位置2
• base[0] + code(时) = 5,此时位置5空闲,因此“时”放入位置5
• base[0] + code(特) = 8,此时位置8空闲,因此“特”放入位置8
• base[0] + code(专) = 10,此时位置10空闲,因此“专”放入位置10
目前base array的情况如下:
position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
base | 1 | |||||||||||
char | root | 最 | 时 | 特 | 专 |
 :这里有什么疑问吗?
:这里有什么疑问吗?
 :似乎没什么问题?请豆豆继续讲。
:似乎没什么问题?请豆豆继续讲。
 :
:
接下来遍历第二层的节点"低,尚,供",对应编码“2,5,8”:
• base[2] + code(低) = 3,此时位置3空闲,因此“最低”放入位置3
• base[5] + code(尚) = 6,此时位置6空闲,因此“时尚”放入位置6
• base[8] + code(供) = 9,此时位置9空闲,因此“特供”放入位置9
• base[10] + code(供) = 9,冲突,base[10]修改为2,此时和位置10冲突,base[10]修改改为3,”专供”放到位置11
目前base array的情况如下:
position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
base | 1 | 3 | ||||||||||
char | root | 最 | 最低 | 时 | 时尚 | 特 | 特供 | 专 | 专供 |
 :base[2]为什么初始值会是1呢?还有,对于您刚才说的冲突,一般是怎么处理的?
:base[2]为什么初始值会是1呢?还有,对于您刚才说的冲突,一般是怎么处理的?
 :
:
每次遍历完一个节点的所有子节点,只可以确认当前节点的base值,以及它的子节点的index位置,子节点的base值此时会默认继承当前节点的base值,这里base[2]继承base[0], 初始值为1。
但在遍历子节点的子节点时,一旦有冲突,子节点的base值就会做相应修改,这里是加1。
接下来来遍历第三层的节点"级,价,最",对应编码“3,6,1“:
• base[3] + code(级) = 4,此时位置4空闲,因此“最低级”放入位置4
• base[3] + code(价) = 7,此时位置7空闲,因此“最低价”放入位置7
• base[6] + code(最) = 2,冲突, 因此 base[6] 修改为2;base[6] + code(最) = 3,还是冲突!base[6] 修改为3,base[6] + code(最) = 4,还是冲突!base[6] 修改为4,base[6] + code(最) = 5,还是冲突!直到base[6] 修改为11,base[6] + code(最) = 12。
目前base array的情况如下:
position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
base | 1 | 11 | 3 | ||||||||||
char | root | 最 | 最低 | 最低级 | 时 | 时尚 | 最低价 | 特 | 特供 | 专 | 专供 | 时尚最 |
再来遍历第四层,“低”,编号2
base12为11,base[12] + code(低) = 13,不冲突
此时节点已经遍历完,剩余base值未确定的都是尾节点了,因为它们都没用子节点了,所以不存在位置冲突,因此可以直接继承父节点的base值:
position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
base | 1 | 1 | 1 | 1 | 1 | 11 | 1 | 1 | 1 | 3 | 3 | 11 | 11 | |
char | root | 最 | 最低 | 最低级 | 时 | 时尚 | 最低价 | 特 | 特供 | 专 | 专供 | 时尚最 | 时尚最低 |
 :
:
接下来,我们趁热打铁,来构建check array,check array的构建比较简单,只需要将子节点index的check值设为父节点的base值即可。
对照公式:
p = base[b] + c
check[p] = b所以有:
position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
base | 1 | 1 | 1 | 1 | 1 | 11 | 1 | 1 | 1 | 3 | 3 | 11 | 11 | |
check | 0 | 2 | 3 | 0 | 5 | 3 | 0 | 8 | 0 | 10 | 6 | 12 | ||
char | root | 最 | 最低 | 最低级 | 时 | 时尚 | 最低价 | 特 | 特供 | 专 | 专供 | 时尚最 | 时尚最低 |
 :嗯,现在字典树已经构建好了,那怎么查询呢?
:嗯,现在字典树已经构建好了,那怎么查询呢?
 :
:
还是举个例子,这时如果有一个词“最专”,我们要查询它是否在双数组trie里面,那么首先从root出发,由于”最”的code是1,因此会走到 base[0]+code(低) = 2,这里要用check数组检查位置2上的节点其父节点是否是位置0上的节点:check[2] = 0,等式成立!
然后继续看“专”:base[2]+code(专) = 10,再检查位置10上的节点的父节点是否是位置2上的节点:check[10] = 0 !=2 ,检查发现不满足,因此"最专"不在该trie里面。
不过这里双数组树这里还有一个比较严重的问题,你猜猜是什么?
 :
:
让我想想。
过去n分钟
……
……
…...
 :假如加入了一个新的词,这颗树的结构会有很大的调整。
:假如加入了一个新的词,这颗树的结构会有很大的调整。
 :
:
不错,假如这时候来了一个不速之客,比如是“低级”,
base[0] + code(低) = 3,冲突!base[0]改成2,base[0] + code(低) =4,冲突!直到base[0]=12,base[0] + code(低) =14,冲突才解决。base[0] 变成12,它恰好是根节点,很多子节点都要调整,整棵树都要重构,所以我们建议实际应用中应首先构建所有词的首字,然后逐一构建各个节点的子节点,这样一旦产生冲突,可以将冲突的处理局限在单个父节点和子节点之间,而不至于导致大范围的节点重构。还有别的问题吗?
 摇摇头。
摇摇头。
 :
:
好,我们接着讲,Base Array 同样也需要负责叶子节点的表达。这时候有两种方法:
* 将每个词的词尾设置为特殊字符(/0),因为最后一个字已经不需要状态转移,所以可以这样构造,但是增加了节点的数量,构建字典时会造成消耗。
* 将每个词的词尾设置为转移基数的负数(只有词尾为负值),这样能够节省构建时间,不过进行转移时要将状态转移函数改为|base[s]|+code(字符)。
我们选择后一种方法,basearray 变这样:
position | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
base | 1 | 1 | 1 | -1 | 1 | 11 | -1 | 1 | -1 | 3 | -3 | 11 | -11 | |
check | 0 | 2 | 3 | 0 | 5 | 3 | 0 | 8 | 0 | 10 | 6 | 12 | ||
char | root | 最 | 最低 | 最低级 | 时 | 时尚 | 最低价 | 特 | 特供 | 专 | 专供 | 时尚最 | 时尚最低 |
 :想不到双数组树要考虑的点这么多。
:想不到双数组树要考虑的点这么多。
 :
:
还有一点,由于冲突发生时,程序总是向后寻找空地址,导致数组不可避免的出现空置,因此空间上还是会有些浪费。另外, 随着节点的增加,冲突的产生几率也会越来越大,字典构建的时间因此越来越长,为了改善这些问题,有人想到对双数组 Trie 进行尾缀压缩,具体做法是:将非公共前缀的词尾合并为一个节点(tail 节点),以此大幅减少节点总数,从而改善树的构建速度;
同时将合并的词尾单独存储在另一个数组之中(Tail array), 并通过 tail 节点的 base 值指向该数组的相应位置,这个你稍后可以自己仔细想想,今天讲的已经够你消化了。
 :
:
好的,谢谢豆豆!
参考链接:
https://turbopeter.github.io/2013/09/02/prefix-match/
https://www.cnblogs.com/en-heng/p/6265256.html














 1317
1317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









