







原文链接
作者:大馋愚
链接:https://www.jianshu.com/p/2e498b5350b5
1. 名词解释
- Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
- Producer:负责发布消息到Kafka broker
- Consumer:消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
2. Kafka架构
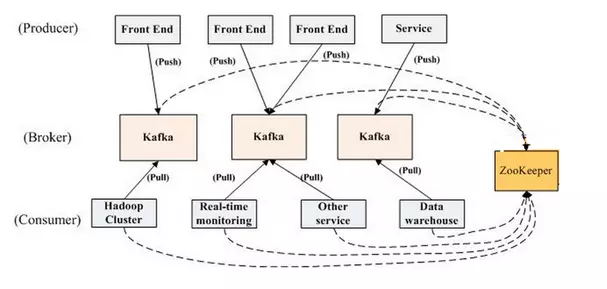
Kafka的整体架构非常简单,是显式分布式架构,producer、broker(kafka)和consumer都可以有多个。Producer,consumer实现Kafka注册的接口,数据从producer发送到broker,broker承担一个中间缓存和分发的作用。broker分发注册到系统中的consumer。broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单,高性能,且与编程语言无关的TCP协议。
3. kafka的存储
Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。若创建topic1和topic2两个topic,且分别有13个和19个分区,则整个集群上会相应会生成共32个文件夹。Producer集群通过zookeeper(实际中写的是broker list)获取所写topic对应的partition列表,然后顺序发送消息(支持自己实现分发策略),broker集群负责消息的存储和传递,支持Master Slaver模型,可分布式扩展;Consumer集群从zookeeper上获取topic所在的partition列表,然后消费,一个partition只能被一个consumer消费。
4. Partition的数据文件
如果客户端不指定Patition,也没有指定Key的话,使用自增长的数字取余数的方式实现指定的Partition。这样Kafka将平均的向Partition中生产数据。kafka只能保证分区内的有序性。
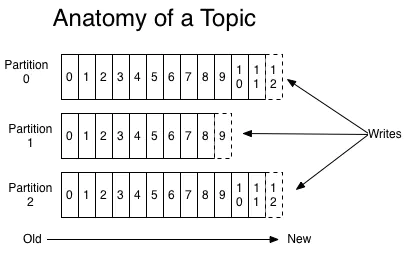
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。因此,可以认为offset是partition中Message的id。partition中的每条Message包含了以下三个属性:
Offset、MessageSize、data
其中offset为long型,MessageSize为int32,表示data有多大,data为message的具体内容。它的格式和Kafka通讯协议中介绍的MessageSet格式是一致。
它的主要方法如下:
append: 把给定的ByteBufferMessageSet中的Message写入到这个数据文件中。
searchFor: 从指定的startingPosition开始搜索找到第一个Message其offset是大于或者等于指定的offset,并返回其在文件中的位置Position。它的实现方式是从startingPosition开始读取12个字节,分别是当前MessageSet的offset和size。如果当前offset小于指定的offset,那么将position向后移动LogOverHead+MessageSize(其中LogOverHead为offset+messagesize,为12个字节)。
read:准确名字应该是slice,它截取其中一部分返回一个新的FileMessageSet。它不保证截取的位置数据的完整性。
sizeInBytes: 表示这个FileMessageSet占有了多少字节的空间。
truncateTo: 把这个文件截断,这个方法不保证截断位置的Message的完整性。
readInto: 从指定的相对位置开始把文件的内容读取到对应的ByteBuffer中。
partition是分段的,每个段叫LogSegment,包括了一个数据文件和一个索引文件,下图是某个partition目录下的文件:

index文件中并没有为数据文件中的每条Message建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
Partition设置:
分区多吞吐量更高
一个话题topic的各个分区partiton之间是并行的。在producer和broker方面,写不同的分区是完全并行的。因此一些昂贵的操作比如压缩,可以获得更多的资源,因为有多个进程。在consumer方面,一个分区的数据可以由一个consumer线程在拉去数据。分区多,并行的consumer(同一个消费组)也可以多。因此通常,分区越多吞吐量越高。
基于吞吐量可以获得一个粗略的计算公式。先测量得到在只有一个分区的情况下,Producer的吞吐量§和Consumer的吞吐量©。那如果总的目标吞吐量是T的话,max(T/P,T/C)就是需要的最小分区数
分区多需要的打开的文件句柄也多
每个分区都映射到broker上的一个目录,每个log片段都会有两个文件(一个是索引文件,另一个是实际的数据文件)。分区越多所需要的文件句柄也就越多,可以通过配置操作系统的参数增加打开文件句柄数。
分区多增加了不可用风险
kafka支持主备复制,具备更高的可用性和持久性。一个分区(partition)可以有多个副本,这些副本保存在不同的broker上。每个分区的副本中都会有一个作为Leader。当一个broker失败时,Leader在这台broker上的分区都会变得不可用,kafka会自动移除Leader,再其他副本中选一个作为新的Leader。Producer和Consumer都只会与Leader相连。
一般情况下,当一个broker被正常关机时,controller主动地将Leader从正在关机的broker上移除。移动一个Leader只需要几毫秒。然当broker出现异常导致关机时,不可用会与分区数成正比。假设一个boker上有2000个分区,每个分区有2个副本,那这样一个boker大约有1000个Leader,当boker异常宕机,会同时有1000个分区变得不可用。假设恢复一个分区需要5ms,1000个分区就要5s。
分区越多,在broker异常宕机的情况,恢复所需时间会越长,不可用风险会增加。
5. Consumers分组
发布-订阅模式中消息被广播到所有的consumer中。Consumers可以加入一个consumer 组,共同竞争一个topic,topic中的消息将被分发到组中的一个成员中。同一组中的consumer可以在不同的程序中,也可以在不同的机器上。如果所有的consumer都在一个组中,这就成为了传统的队列模式,在各consumer中实现负载均衡。如果所有的consumer都不在不同的组中,这就成为了发布-订阅模式,所有的消息都被分发到所有的consumer中。更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。
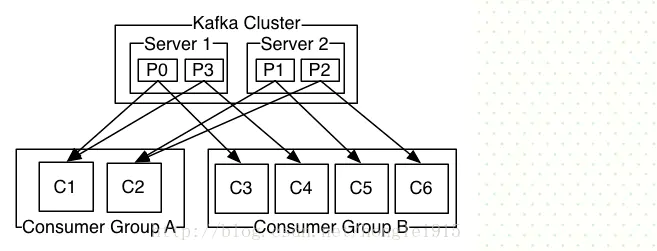
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的。
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









