







十大基础实用算法及其拓展
前言:
- 在程序的世界里面, 算法可以说是无处不在的,但是需要去弄清楚所有的算法吗,感觉也是不太需要的,所以我们要去分析一些基础的算法,由此去类推一些复杂的问题。Big-man在这里总结了十大基础算法的概念以及基本实现。
快速排序:
- 快速排序是由东尼·霍尔所发明的一种排序算法。
快速排序概念:
- 在平均状况下,排序 n 个项目要
Ο(nlogn)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。 - 事实上,快速排序通常明显比其他
Ο(nlogn)算法更快,因为它的内部循环(innerloop)可以在大部分的架构上很有效率地被实现出来。 - 快速排序使用分治法(
Divideandconquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
算法步骤:
- 1、从数列中挑出一个元素,称为「基准」(
pivot), - 2、重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(
partition)操作。 - 3、递归地(
recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。 - 递归的最底部情形,是数列的大小是
零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。如下图所示:
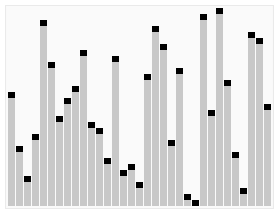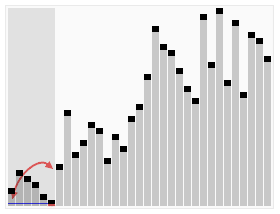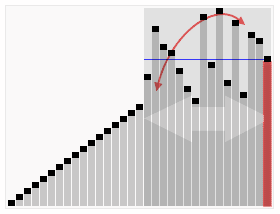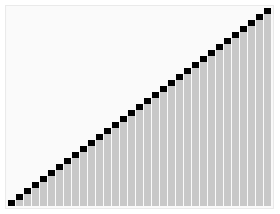
代码实现:
- 就来解决一道曾经Big-man解决过的一道快速排序题吧, 题目在这里2388。
Who's in the Middle
Time Limit: 1000MS Memory Limit: 65536K
Total Submissions: 43968 Accepted: 25356
Description:
FJ is surveying his herd to find the most average cow.
He wants to know how much milk this 'median' cow gives: half of the cows give as much or more than the median; half give as much or less.
Given an odd number of cows N (1 <= N < 10,000) and their milk output (1..1,000,000), find the median amount of milk given such that at least half the cows give the same amount of milk or more and at least half give the same or less.
Input:
* Line 1: A single integer N
* Lines 2..N+1: Each line contains a single integer that is the milk output of one cow.
Output:
* Line 1: A single integer that is the median milk output.
Sample Input:
5
2
4
1
3
5
Sample Output:
3
Hint:
INPUT DETAILS:
Five cows with milk outputs of 1..5
OUTPUT DETAILS:
1 and 2 are below 3; 4 and 5 are above 3.题目分析:
- 奶牛只是一个场景,真正的意义在于数字的变化:
- 输入一个奇数
n(这个奇数n)代表的是输入的数量; - 要求就是在这堆数中找出一个数,这个数需要同时满足一半数大于等于它,另一半数小于等于它。
解决方法:(别人写的)
#include<stdio.h>
#include<algorithm>
using namespace std;
int main()
{
int n,i;
int a[10000];
while(scanf("%d",&n)!=EOF)
{
for(i=0;i<n;i++)
scanf("%d",&a[i]);
sort(a,a+n); //直接排序
printf("%d\n",a[n/2]);
}
return 0;
}#include <iostream>
#include <algorithm>
using namespace std;
const int N = 10000;
int a[N];
int main()
{
int n;
// 输入数据
while(cin >> n) {
for(int i=0; i<n; i++)
cin >> a[i];
// 排序
sort(a, a+n);
// 输出结果
cout << a[n / 2] << endl;
}
return 0;
} 数组合并-顺序输出:
- Big-man这里需要额外地插入一下自己的书写的数组合并-顺序输出的方法:
C语言实现:
#include <stdio.h>
#include <stdlib.h>
int main(void) {
int a[5], b[5], c[10], k=0;
printf("Enter the number of arrays a :\n");
for(int i=0; i < 5; i++) {
scanf("%d", &a[i]);
}
printf("Enter the number of arrays b : \n");
for(int j=0; j < 5; j++) {
scanf("%d", &b[j]);
}
while(k!=9) {
printf("a[%d]=%d\n", i, a[i]);
printf("b[%d]=%d\n", j, b[j]);
if(a[i] < b[j]) {
c[k] = a[i];
i++;
k++;
} else {
c[k] = b[j];
j++;
k++;
}
if(i>4 || j>4) break;
}
printf("i=%d, j=%d, k=%d\n", i, j, k);
if(i > j) {
printf("i>j:i=%d, j=%d\n", i, j);
for(k; k < 10; k++) {
printf("k=%d\n", k);
c[k] = b[i++];
}
} else {
printf("i < j:i=%d, j=%d\n", i, j);
for(k; k<10; k++) {
printf("k=%d\n", k);
c[k] = a[i++];
}
}
for(k=0; k<10; k++) {
printf("%4d", c[k]);
}
printf("\n");
}java代码实现:
public int[] getNewArrays(int[] one, int[] two) {
int len = one.length;
int len2 = two.length;
int len3 = len + len2;
int [] = newArray = new int [len3];
for(int i=0; i<len3; i++) {
if(i < len) {
newArray[i] = one[i];
continue;
}
int t = i-len;
newArray[i] = two[t];
}
Arrays.sort(newArray); //对第三个数组进行排序; 此处使用的是java自带的sort方法;
return newArray;
}JavaScript代码实现:
- JS中的数组合并方法:
- 1、
concat:
var c = a.concat(b);
a;// [1,2,3,4,5,6,7,8,9]
b;// ["foo","bar","baz","bam","bun","fun"]
c;//[1,2,3,4,5,6,7,8,9,"foo","bar","baz","bam","bun","fun"]- 正如上面展示的那样,c是一个全新的数组,表示a和b两个数组的组合,并让a和b不变。
- 但如果a有100, 000个元素,而b也有100, 000元素,c就会有200, 000个元素,所以a和b的内存使用就会翻倍。
- 所以Big-man就想了一个垃圾回收机制,把a和b设置为null,问题解决了!
a = b = null; // 'a'和'b'就被回收了对于只有几个元素的小数组,这没啥问题。但对于大数组,或者在内存有限的系统中需要经常重复这个过程,其实还有很多改进的地方。
循环插入:
// b into a
for(var i=0; i<b.length; i++) {
a.push(b[i]);
}
a;//[1,2,3,4,5,6,7,8,9,"foo","bar","baz","bam","bun","fun"]
b = null;- 现在,数组a有了数组b的内容。
似乎有更好的内存占用。但如果a数组比较小?出于内存和速度的原因,可能要把更小的a放到b的前面,只需要将
push()换成unshift()就可以了。功能技巧:
- 不过
for循环确实使用起来比较丑, 而且不好维护。
// b into a
a = b.reduce(function(coll, item) {
coll.push(item);
return coll;
}, a);
a;//[1,2,3,4,5,6,7,8,9,"foo","bar","baz","bam","bun","fun"]// a into b
b = a.reduceRight( function(coll,item){
coll.unshift( item );
return coll;
}, b );
b;//[1,2,3,4,5,6,7,8,9,"foo","bar","baz","bam","bun","fun"]Array#reduce(..)和Array#reduceRight(..)是不错的,但他们是一点点笨拙。ES6=>的箭头函数将减少一些代码量,但它仍然需要一个函数,每个元素都需要调用一次,不是很完美。
那这个怎么样:
// `b` into `a`:
a.push.apply( a, b );
a;//[1,2,3,4,5,6,7,8,9,"foo","bar","baz","bam","bun","fun"]// or `a` into `b`:
b.unshift.apply( b, a );
b; // [1,2,3,4,5,6,7,8,9,"foo","bar","baz","bam","bun","fun"]- 因为
unshift()方法在这里并不需要担心前面的反向排序。 ES6的spead操作会更漂亮:a.push( ...b )或b.unshift( ...a)数组最大长度限制。 - 第一个主要的问题是,内存使用量增长了一倍(当然只是暂时的!)被追加内容基本上是通过函数调用将元素复制到堆栈中。此外,不同的JS引擎都有拷贝数据长度的限制。
- 所以,如果数组有一百万个元素,你肯定会超出了
push(...)或unshift(...)允许调用堆栈的限制。唉,处理几千个元素它会做得很好,但你必须要小心,不能超过合理的长度限值。 - 注意: 你可以尝试一下
splice(...),它跟push(...)和unshift(...)一样都有这种问题。 - 有一种方法可以避免这种最大长度限制。
function combineInto(a,b) {
var len = a.length;
for (var i=0; i < len; i=i+5000) {
b.unshift.apply( b, a.slice( i, i+5000 ) );
}
}堆排序算法:
- 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质: 即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序的平均时间复杂度为
O(nlogn)。
算法步骤:
- 1、创建一个堆H[0..n-1];
- 2、把堆首(最大值)和堆尾互换;
- 3、把堆的尺寸缩小1, 并调用shift_down(0), 目的是把新的数组顶端数据调整到相应位置;
- 4、重复步骤2, 直到堆的尺寸为1。

堆排序代码实现:
- 问题描述:
The Average
Time Limit: 6000MS Memory Limit: 10000K
Total Submissions: 11898 Accepted: 3563
Case Time Limit: 4000MS
Description
In a speech contest, when a contestant finishes his speech, the judges will then grade his performance. The staff remove the highest grade and the lowest grade and compute the average of the rest as the contestant’s final grade. This is an easy problem because usually there are only several judges.
Let’s consider a generalized form of the problem above. Given n positive integers, remove the greatest n1 ones and the least n2 ones, and compute the average of the rest.
Input
The input consists of several test cases. Each test case consists two lines. The first line contains three integers n1, n2 and n (1 ≤ n1, n2 ≤ 10, n1 + n2 < n ≤ 5,000,000) separate by a single space. The second line contains n positive integers ai (1 ≤ ai ≤ 108 for all i s.t. 1 ≤ i ≤ n) separated by a single space. The last test case is followed by three zeroes.
Output
For each test case, output the average rounded to six digits after decimal point in a separate line.
Sample Input
1 2 5
1 2 3 4 5
4 2 10
2121187 902 485 531 843 582 652 926 220 155
0 0 0
Sample Output
3.500000
562.500000
Hint
This problem has very large input data. scanf and printf are recommended for C++ I/O.
The memory limit might not allow you to store everything in the memory.分析题目当中的含义:
- 题目给出的意思是输入
n个数; - 去掉其中
n1个最大数; - 去掉其中
n2个最小数; 1 <= n1, n2 <= 10;n1 + n2 <= n <= 5, 000, 000;- 所以下面的提示给出如果是
C++语言建议用scanf和printf来处理I/O, 输入与输出。
- 题目给出的意思是输入
代码:
#include<iostream>
#include<algorithm>
#include<iomanip>
using namespace std;
int cmp(int a,int b) {
return a>b;
}
int main() {
long int n;
int n1,n2;
scanf("%d%d%ld",&n1,&n2,&n);
while(1) {
long int minheap[14],maxheap[14];
fill(minheap,minheap+14,0);
fill(maxheap,maxheap+14,100000001);
long long sum=0;
if(n1==0 && n2==0 && n==0) break;
int max_len=0,min_len=0;
bool flag1=0,flag2=0;
for(int i=0; i<n; i++) {
int temp;
scanf("%d",&temp);
if(temp<maxheap[0]){
maxheap[0]=temp;
make_heap(maxheap,maxheap+n2);
}
if(temp>minheap[0]){
minheap[0]=temp;
make_heap(minheap,minheap+n1,cmp);
}
sum+=temp;
}
for(int i=0; i<n1; i++)
sum-=minheap[i];
for(int i=0; i<n2; i++)
sum-=maxheap[i];
printf("%.6lf\n", 1.0*sum/(n-n1-n2));
scanf("%d%d%ld",&n1,&n2,&n);
}
return 0;
} 归并排序算法:
- 归并排序(Merge sort, 也称做”合并排序”)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(
Divide and Conquer)的一个非常典型的应用。 - 算法步骤:
- 1、申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列。
- 2、设定两个指针,最初位置分别为两个已经排序序列的起始位置。
- 3、比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置。
- 4、重复步骤3直到某一指针达到序列尾。
- 5、将另一序列剩下的所有元素直接复制到合并序列尾。
- 题目POJ1804:

Brainman
Time Limit: 1000MS Memory Limit: 30000K
Total Submissions: 11271 Accepted: 5804
Description:
Background
Raymond Babbitt drives his brother Charlie mad. Recently Raymond counted 246 toothpicks spilled all over the floor in an instant just by glancing at them. And he can even count Poker cards. Charlie would love to be able to do cool things like that, too. He wants to beat his brother in a similar task.
Problem
Here's what Charlie thinks of. Imagine you get a sequence of N numbers. The goal is to move the numbers around so that at the end the sequence is ordered. The only operation allowed is to swap two adjacent numbers. Let us try an example:
Start with: 2 8 0 3
swap (2 8) 8 2 0 3
swap (2 0) 8 0 2 3
swap (2 3) 8 0 3 2
swap (8 0) 0 8 3 2
swap (8 3) 0 3 8 2
swap (8 2) 0 3 2 8
swap (3 2) 0 2 3 8
swap (3 8) 0 2 8 3
swap (8 3) 0 2 3 8
So the sequence (2 8 0 3) can be sorted with nine swaps of adjacent numbers. However, it is even possible to sort it with three such swaps:
Start with: 2 8 0 3
swap (8 0) 2 0 8 3
swap (2 0) 0 2 8 3
swap (8 3) 0 2 3 8
The question is: What is the minimum number of swaps of adjacent numbers to sort a given sequence?Since Charlie does not have Raymond's mental capabilities, he decides to cheat. Here is where you come into play. He asks you to write a computer program for him that answers the question. Rest assured he will pay a very good prize for it.
Input
The first line contains the number of scenarios.
For every scenario, you are given a line containing first the length N (1 <= N <= 1000) of the sequence,followed by the N elements of the sequence (each element is an integer in [-1000000, 1000000]). All numbers in this line are separated by single blanks.
Output
Start the output for every scenario with a line containing "Scenario #i:", where i is the number of the scenario starting at 1. Then print a single line containing the minimal number of swaps of adjacent numbers that are necessary to sort the given sequence. Terminate the output for the scenario with a blank line.
Sample Input
4
4 2 8 0 3
10 0 1 2 3 4 5 6 7 8 9
6 -42 23 6 28 -100 65537
5 0 0 0 0 0
Sample Output
Scenario #1:
3
Scenario #2:
0
Scenario #3:
5
Scenario #4:
0
- 代码:
#include<cstdio>
#define N 1000+10
int ans=0;
int f[N],t[N];
void Merge(int l,int m,int r) //左右两个表合并成一个表
{
int i=l,j=m+1,cnt=0;
while(i<=m && j<=r)
{
if(f[i]<=f[j])
t[cnt++]=f[i++];
else
{
ans+=m-i+1;
t[cnt++]=f[j++]; //核心代码,求解逆序数个数。
}
}
while(i<=m) //若左表不空
t[cnt++]=f[i++];
while(j<=r) //若右表不空
t[cnt++]=f[j++];
for(int k=0;k<cnt;) //修改原数组
f[l++]=t[k++];
}
void Merge_sort(int l,int r) //归并排序
{
if(l==r)
return ;
else
{
int m=(l+r)>>1;
Merge_sort(l,m);
Merge_sort(m+1,r);
Merge(l,m,r);
}
}
int main()
{
int T,cas=0;
scanf("%d",&T);
while(T--)
{
int n;
scanf("%d",&n);
for(int i=0;i<n;i++)
scanf("%d",&f[i]);
ans=0;
Merge_sort(0,n-1);
printf("Scenario #%d:\n%d\n\n",++cas,ans);
}
return 0;
}- 题目POJ2299:
Ultra-QuickSort
Time Limit: 7000MS Memory Limit: 65536K
Total Submissions: 64907 Accepted: 24242
Description:
In this problem, you have to analyze a particular sorting algorithm. The algorithm processes a sequence of n distinct integers by swapping two adjacent sequence elements until the sequence is sorted in ascending order. For the input sequence
9 1 0 5 4 ,
Ultra-QuickSort produces the output
0 1 4 5 9 .
Your task is to determine how many swap operations Ultra-QuickSort needs to perform in order to sort a given input sequence.
Input
The input contains several test cases. Every test case begins with a line that contains a single integer n < 500,000 -- the length of the input sequence. Each of the the following n lines contains a single integer 0 ≤ a[i] ≤ 999,999,999, the i-th input sequence element. Input is terminated by a sequence of length n = 0. This sequence must not be processed.
Output
For every input sequence, your program prints a single line containing an integer number op, the minimum number of swap operations necessary to sort the given input sequence.
Sample Input
5
9
1
0
5
4
3
1
2
3
0
Sample Output
6
0- 代码:
#include<cstdio>
#define N 500000+10
long long ans=0;
int f[N],t[N];
void Merge(int l,int m,int r)
{
int i=l,j=m+1,cnt=0;
while(i<=m && j<=r)
{
if(f[i]<=f[j])
t[cnt++]=f[i++];
else
{
ans+=m-i+1;
t[cnt++]=f[j++];
}
}
while(i<=m)
t[cnt++]=f[i++];
while(j<=r)
t[cnt++]=f[j++];
for(int k=0;k<cnt;)
f[l++]=t[k++];
}
void Merge_sort(int l,int r)
{
if(l==r)
return ;
else
{
int m=(l+r)>>1;
Merge_sort(l,m);
Merge_sort(m+1,r);
Merge(l,m,r);
}
}
int main()
{
int n;
while(scanf("%d",&n),n)
{
for(int i=0;i<n;i++)
scanf("%d",&f[i]);
ans=0;
Merge_sort(0,n-1);
printf("%lld\n",ans);
}
return 0;
}- 题目HDU4911:
Inversion
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)
Total Submission(s): 5251 Accepted Submission(s): 1846
Problem Description:
bobo has a sequence a1,a2,…,an. He is allowed to swap two adjacent numbers for no more than k times.
Find the minimum number of inversions after his swaps.
Note: The number of inversions is the number of pair (i,j) where 1≤i<j≤n and ai>aj.
Input
The input consists of several tests. For each tests:
The first line contains 2 integers n,k (1≤n≤105,0≤k≤109). The second line contains n integers a1,a2,…,an (0≤ai≤109).
Output
For each tests:
A single integer denotes the minimum number of inversions.
Sample Input
3 1
2 2 1
3 0
2 2 1
Sample Output
1
2
- 代码:
#include<cstdio>
#define N 500000+10
long long ans=0;
int f[N],t[N];
void Merge(int l,int m,int r)
{
int i=l,j=m+1,cnt=0;
while(i<=m && j<=r)
{
if(f[i]<=f[j])
t[cnt++]=f[i++];
else
{
ans+=m-i+1;
t[cnt++]=f[j++];
}
}
while(i<=m)
t[cnt++]=f[i++];
while(j<=r)
t[cnt++]=f[j++];
for(int k=0;k<cnt;)
f[l++]=t[k++];
}
void Merge_sort(int l,int r)
{
if(l==r)
return ;
else
{
int m=(l+r)>>1;
Merge_sort(l,m);
Merge_sort(m+1,r);
Merge(l,m,r);
}
}
int main()
{
int n,k;
while(scanf("%d%d",&n,&k)==2)
{
for(int i=0;i<n;i++)
scanf("%d",&f[i]);
ans=0;
Merge_sort(0,n-1);
if(ans>k) printf("%lld\n",ans-k);
else printf("0\n");
}
return 0;
}二分查找算法:
- 二分查找算法是一种在有序数组中查找某一特定元素的搜索算法。
- 算法过程:
- 搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或者等于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。
- 如果在某一步骤数组为空,则代表找不到。
- 这种搜索算法每一次比较都使搜索范围缩小一半。
- 折半搜索每次把搜索区域减少一半,时间复杂度为
O(log2n)。 如图所示:
题目POJ1019:

Number Sequence
Time Limit: 1000MS Memory Limit: 10000K
Description:
A single positive integer i is given. Write a program to find the digit located in the position i in the sequence of number groups S1S2...Sk. Each group Sk consists of a sequence of positive integer numbers ranging sefrom 1 to k, written one after another.
For example, the first 80 digits of the sequence are as follows:
11212312341234512345612345671234567812345678912345678910123456789101112345678910
Input
The first line of the input file contains a single integer t (1 ≤ t ≤ 10), the number of test cases, followed by one line for each test case. The line for a test case contains the single integer i (1 ≤ i ≤ 2147483647)
Output
There should be one output line per test case containing the digit located in the position i.
Sample Input
2
8
3
Sample Output
2
2题目分析:
- 第一个
number表示的是test cases; - 第二个
number表示的是i;
- 这个
i表示的是在这个11212312341234512345612345671234567812345678912345678910123456789101112345678910数字串中的位置;
- 这个
- 打印出这个位置的数字。
- 第一个
代码:
#include <iostream>
#include <algorithm>
#include <cmath>
#include <vector>
#include <string>
#include <cstring>
#pragma warning(disable:4996)
using namespace std;
int c[52850];
long long s[52850];
int n[52850];
int num;
int length(int x)
{
int sum=0;
while (x != 0)
{
x /= 10;
sum++;
}
return sum;
}
void init()
{
int i;
c[0] = 0;
s[0] = 0;
for (i = 1; i <= 52849; i++)
{
n[i] = length(i);
}
for (i = 1; i <= 52849; i++)
{
c[i] = c[i - 1] + n[i];
}
for (i = 1; i <= 52849; i++)
{
s[i] = s[i - 1] + c[i];
}
}
int main()
{
init();
int Test,left,pos;
int i;
scanf("%d", &Test);
while(Test--)
{
scanf("%d", &num);
left = lower_bound(s + 1, s + 52845, num) - (s + 1);
pos = num - s[left];
left= lower_bound(c + 1, c + 52845, pos) - (c + 1);
pos = pos - c[left];
left++;
pos = n[left] - pos +1;
i = 1;
while (i < pos)
{
left /= 10;
i++;
}
cout << left % 10<<endl;
}
return 0;
} JackDan9 Thinking
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









