






赏心悦目
先来个人形代码适应适应
原图点赞后,私信我即可获取
CURD
数据库的增删改查都是比较慢的,都是比较吃硬件资源的,所以在使用中能省就尽量省点.
1.1新增
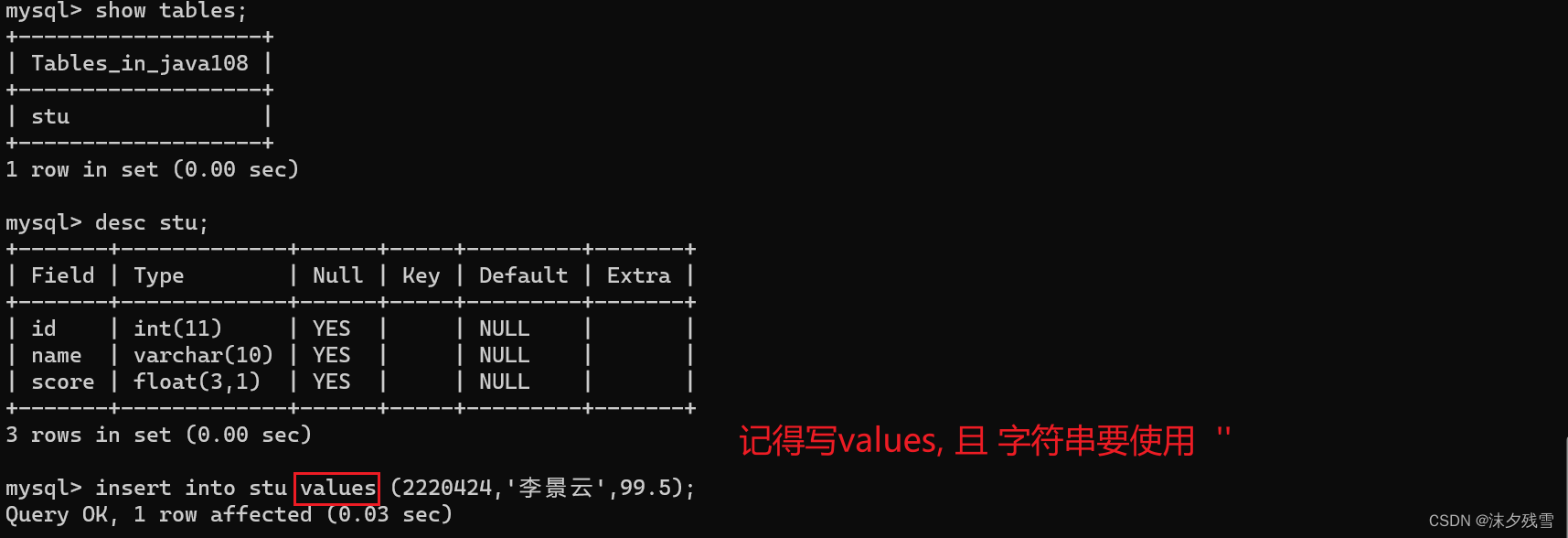
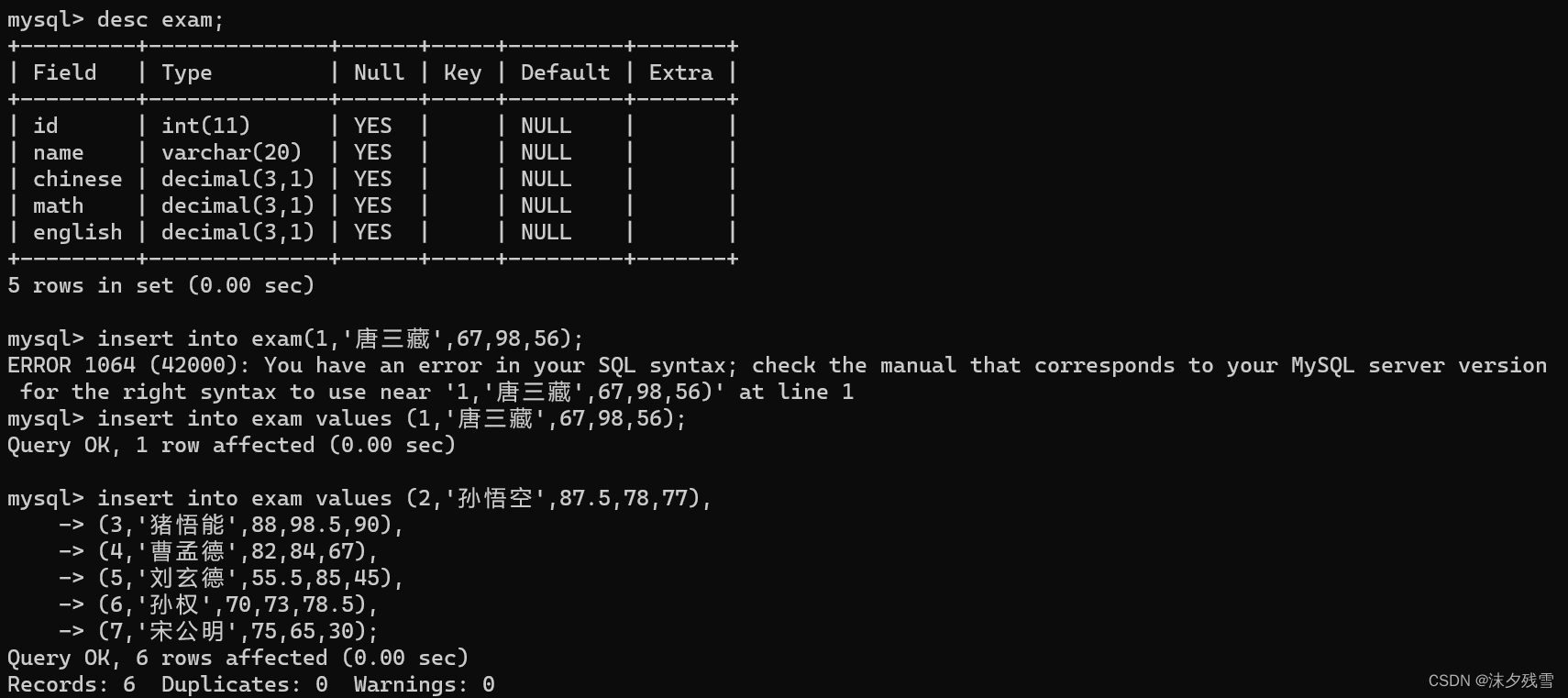
insert into 表名 values (值,值...);
#其中 insert into values 这些都是关键字,into可以省略
值要和你的数据表中的值的类型相匹配
在SQL中没有字符类型,SQL中表示字符串 '' 和 "" 都行
大部分没有字符串类型的编程语言,都是允许使用 单引号 或者 双引号 来表示字符串的 并且,单引号与双引号的效果通常是等价的
注意
要想正确插入中文,要求在创建数据库的时候指定编码:charset utf8
1.2指定列插入
insert into 表名 (列名,列名...) values (值,值...);
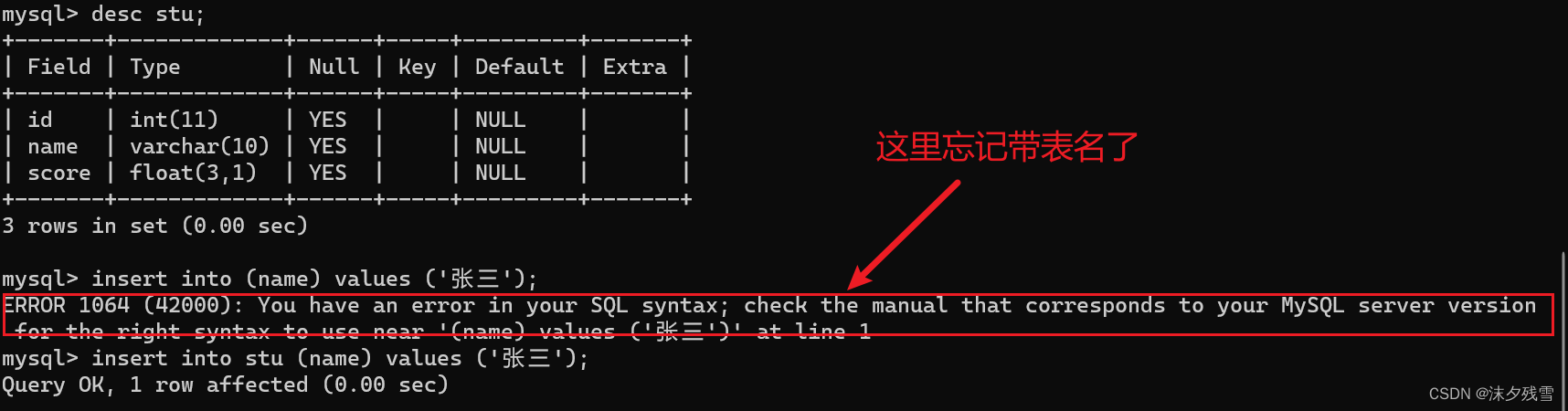

使用这个 () 来标识当前要针对哪些列进行插入
多个列名之间可以用 , 来分割,后续values里的列必须要和当前()里的列的个数和类型都匹配.
1.3一次插入多个记录
insert into 表名 values (值,值...),(值,值...)...;
values后面可以有多个(),每个()之间用 , 来分割,每一个()就是一条记录(也就是一行).

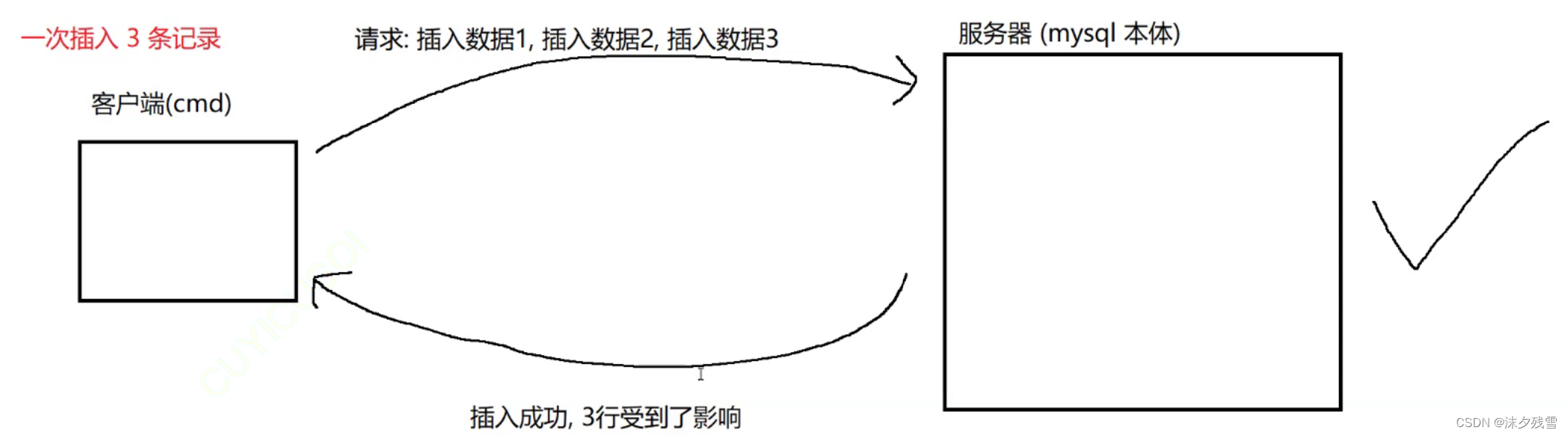
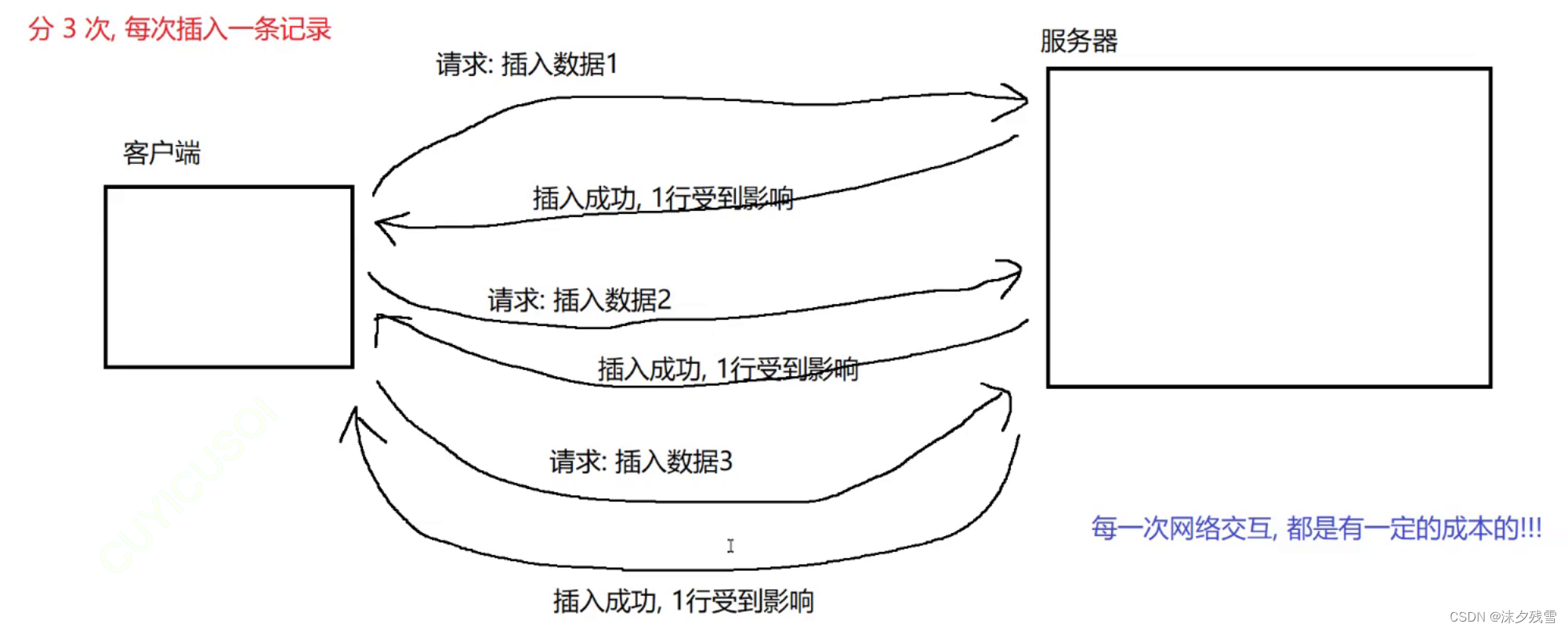
那么问题来了
一次插入三条数据 和 分三次,每次插入一条数据有什么区别?
分析与解答
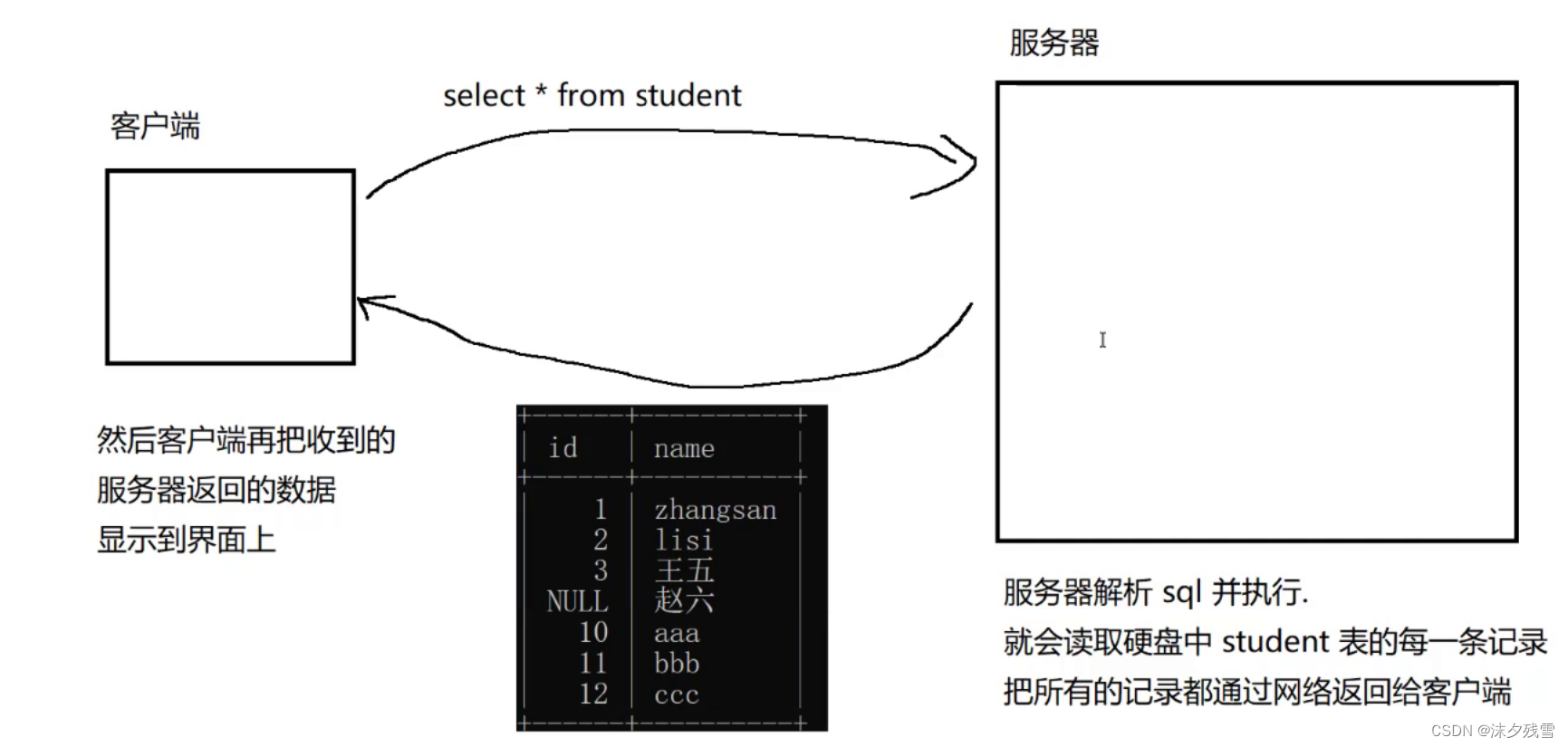
还是要注意,MySQL的本体是MySQL服务器,我们使用的cmd是他的客户端,客户端每次与服务器进行通信是通过网络进行的,也就是说每一次网络交互都是有一定的成本的.
所以在此,一次插入三条记录是比较好的
举个例子
快递发货,在同一个商家买了三次货,商家现在要把货给你,肯定是需要运输公司来参与的,那么你自己说,一次发三个包裹和发三次每次只发一个包裹,哪一个成本低?
我们的MySQL与之类似,我们每次与服务器进行通讯都是需要成本的(时间,硬件资源...),所以我们尽可能减少SQL的数量来减少成本,使得效率更高.
2.1查询
2.2全列查询
select * from 表名;
这个操作就是查询出该数据库中所有的行和所有的列
其中 * 是通配符

但是请注意:
select *
这个操作也是非常危险的!!!,假如我们的数据非常多(几十亿条)
这就导致服务器无法给外面的普通用户提供服务了(MySQL的服务器是一对多的形式,即一个服务器对应多个客户端),服务器就像"卡死"一样
这样就会导致这个服务器一瞬间,硬盘的带宽和网卡的带宽都被吃满了
什么叫带宽?
就好比公路,双行道比较慢(带宽小),八车道比较快(带宽大),但即使是八车道,假如你一瞬间涌上来一堆车,那必然会造成堵车,堵车时即使再快的八车道也会非常的慢(带宽吃满就相当于堵车)
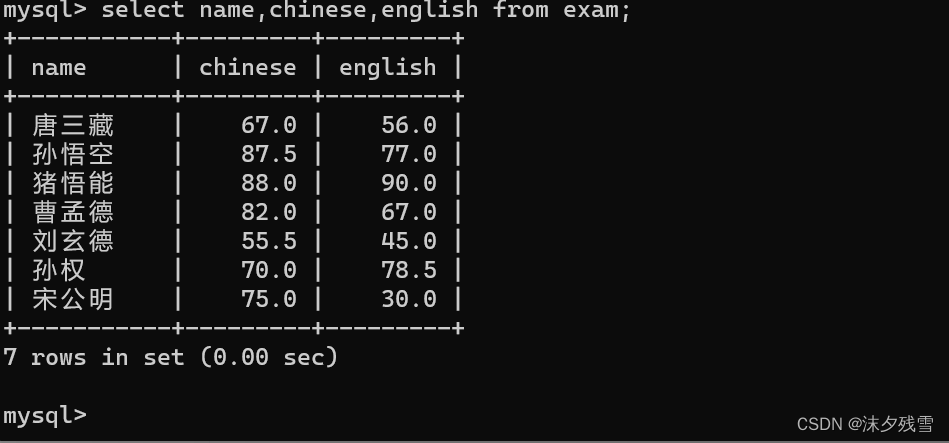
2.3指定列查询
select 列名,列名... from 表名;
手动指定数据库中的某一列或某几列

2.4查询字段为表达式(边查询边计算)
注意:只能数字+数字,其他的会报错.
SQL中四则运算只能针对数字进行
比如我们在查询数学成绩的时候,给数学成绩+10分
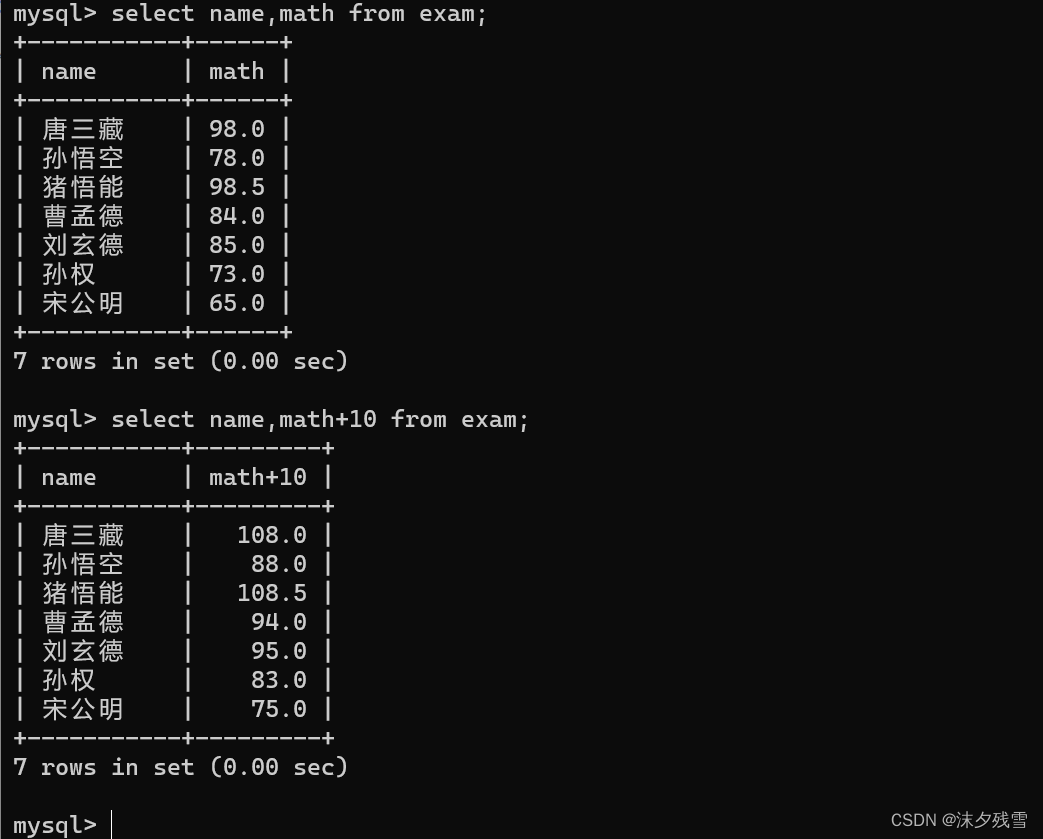
此处客户端显示的数据其实是一个"临时表"
select操作不管怎么写都不会影响到数据库服务器硬盘上原有的原始数据.
且临时表里面的数据类型和原始的数据类型也不一定完全一致
(我们当初是decimal(3,1),但是临时表中出现了108.0)
当然了也可以两列或多列进行计算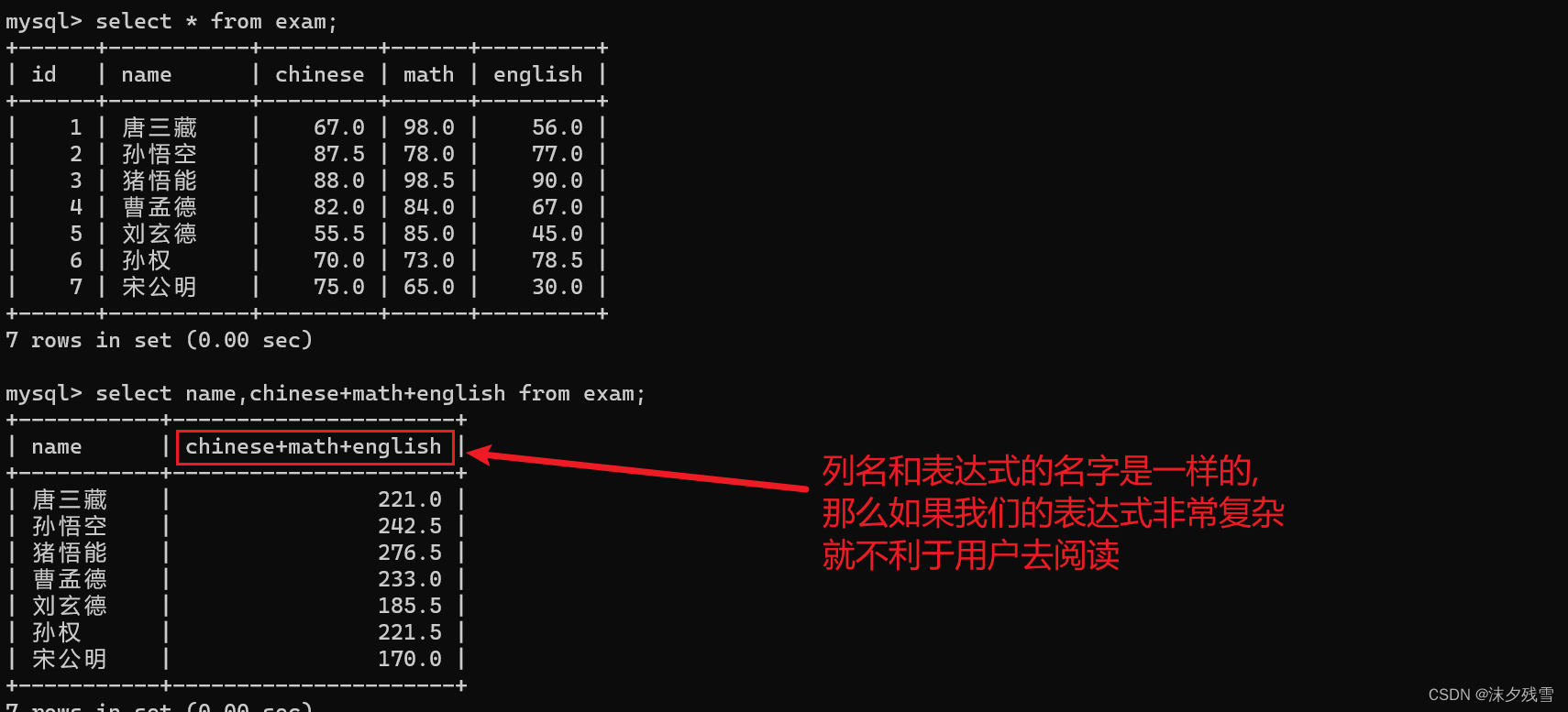
2.5查询的时候给列/表达式指定别名
select 列名 as 别名 from 表名
最后 别名 可以显示出来
as 可以省略,答案是为了区分,为了增加代码的可读性,这里不建议省略
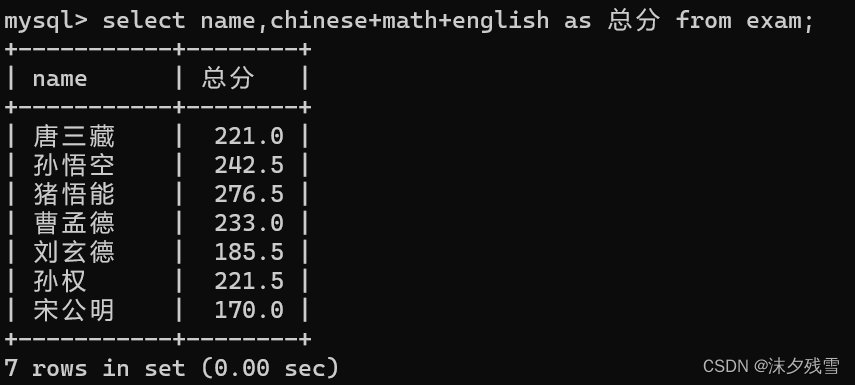
在SQL中 列名 和 表名 都是可以起 别名 的,也都是使用as.
2.6查询时去重
select distinct 列名 from表名;
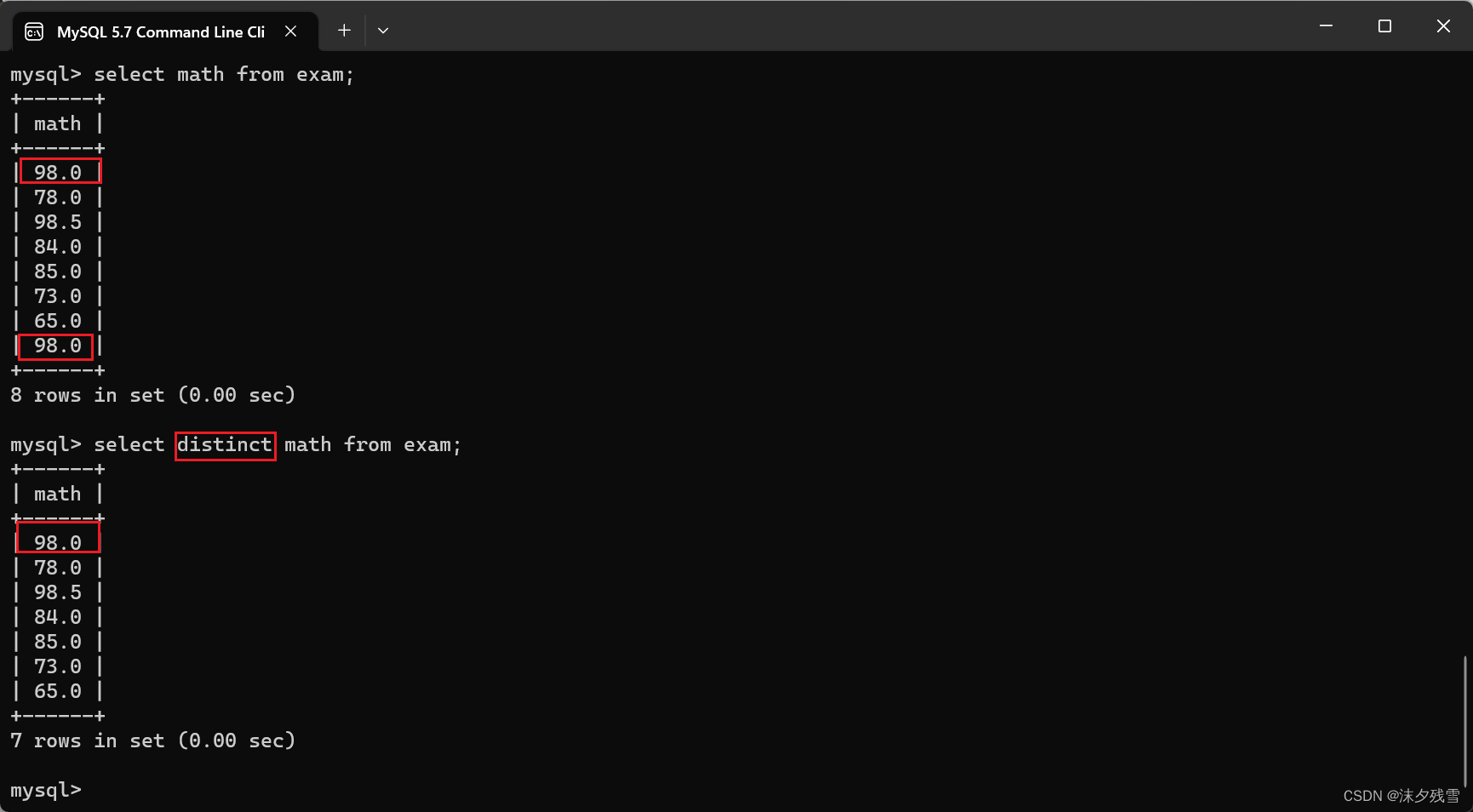
distinct后面的列名,也可以是多个(要求,必须所有的列的值都相同才算"重复")
2.7排序查询
针对查询到的结果进行排序
MySQL是一个客户端-服务器结构的程序
因此这里的排序也是只针对临时表进行的,对于数据库服务器上的原始数据没有任何顺序上的影响
select 列名 from 表名 order by 列名;
或者
select 列名 from 表名 order by 列名 asc;
ascend:上升,升高
在上述语法中,第二个 "列名" 是一个规范,也就是说按照这个列来排序(升序)
不写升降序的关键字默认是排升序
排序之前,现在按照英语成绩升序排序
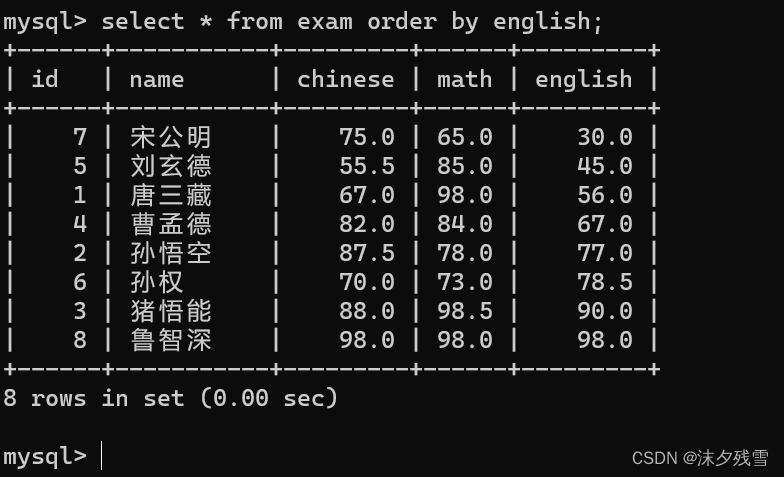
那么我们如何排降序呢?
select 列名 from 表名 order by 列名 desc;
descend:下降,降序
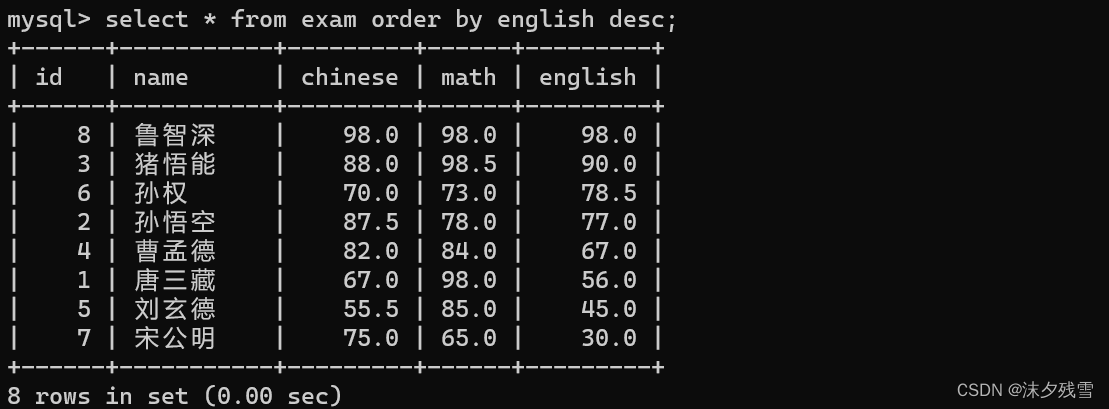
注意:如果SQL中没有指定 order by ,此时我们的代码中就不应该依赖结果集合(临时表)的顺序!!!,MySQL并不承诺,这个不带 order by的查询结果是带有一定顺序的
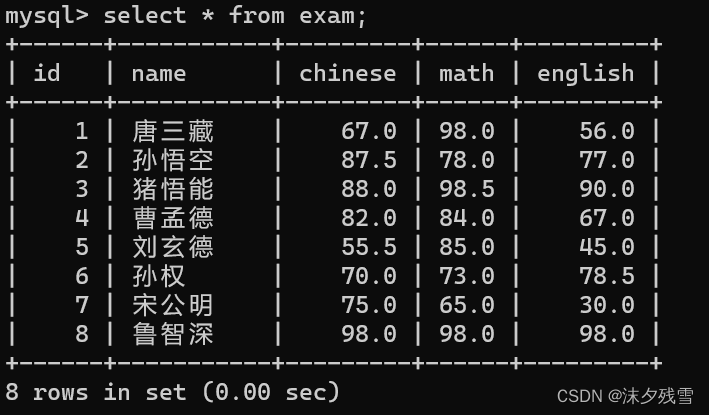
2.8指定多个列排序
select 列名 from 表名 order by 列名,列名...;
在这里, order by 后的列名与列名之间是有优先级关系的
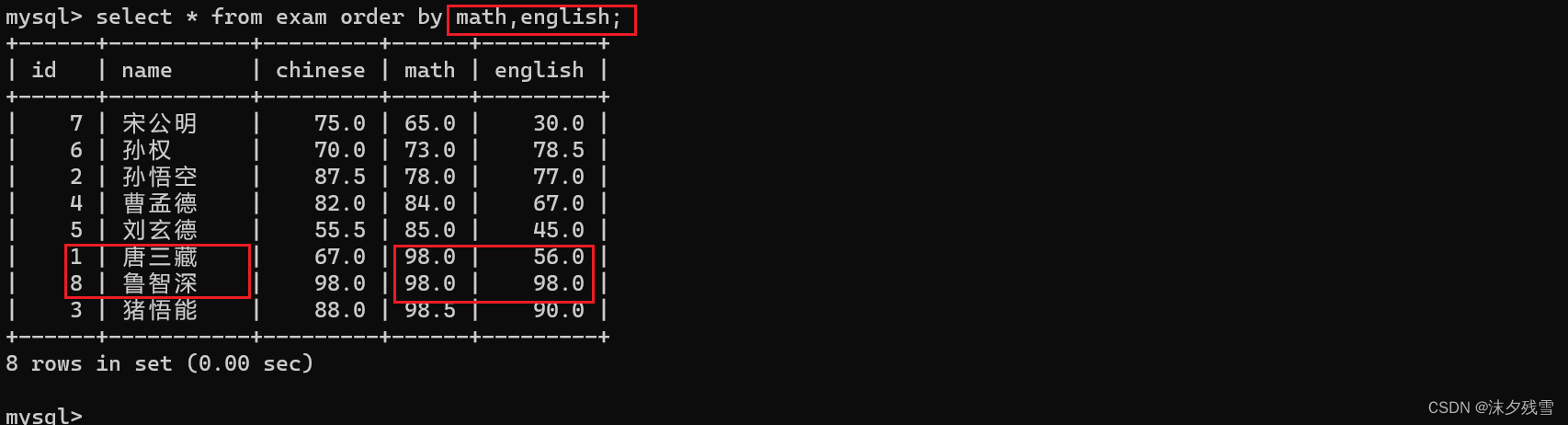
这是什么意思呢?
先根据math进行排序,当math相等时再根据english进行排序,比如这里的唐三藏和鲁智深
2.9条件查询
指定一个筛选条件,把符合条件的结果保留下来,不符合的就剔除掉
关系运算符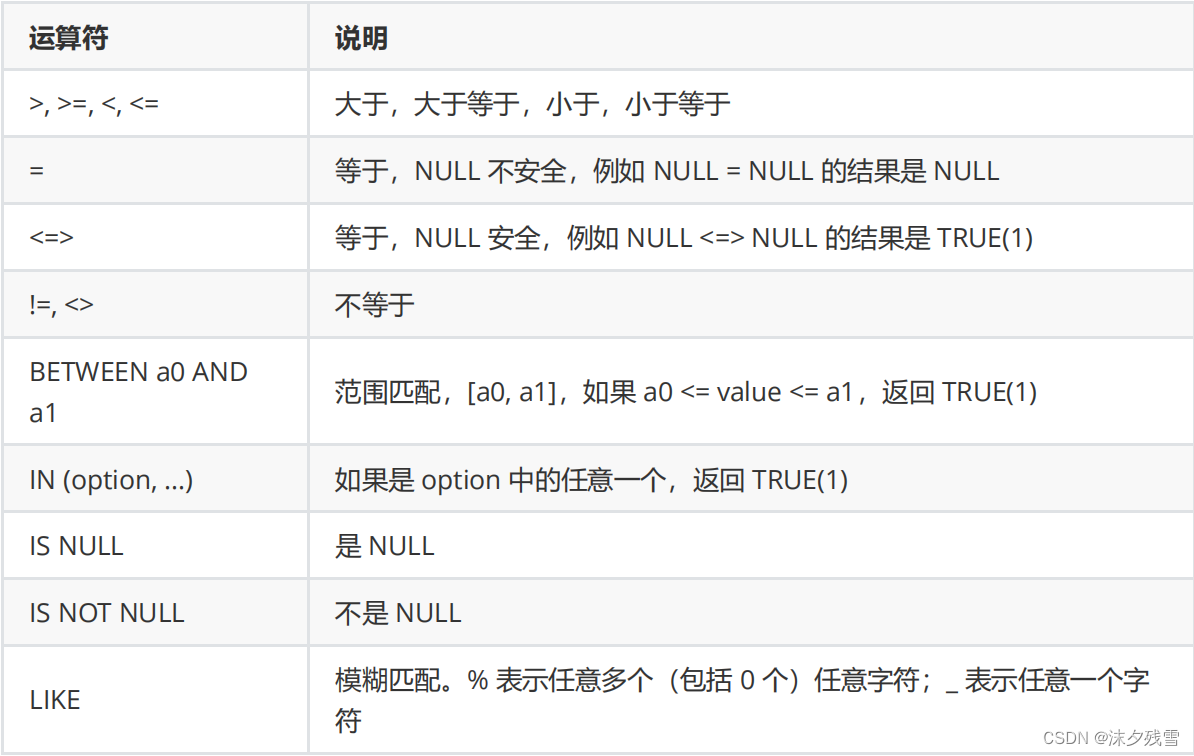
这里需要注意的是在SQL中没有 == 只有 = ,等号在SQL中表示相等的意思.而是可以比较空值的
我们已知,在SQL中有些值是可以不填的(不填默认为NULL)
NULL参与的各种运算,结果还是NULL
<=>
例如:NULL=NULL
结果:NULL
为什么?
对于NULL而言,NULL相当于false
对于 = 而言,得条件成立才可比较,但是NULL都为false了,那当然就不能比较了.
而
NULLNULL
结果:true
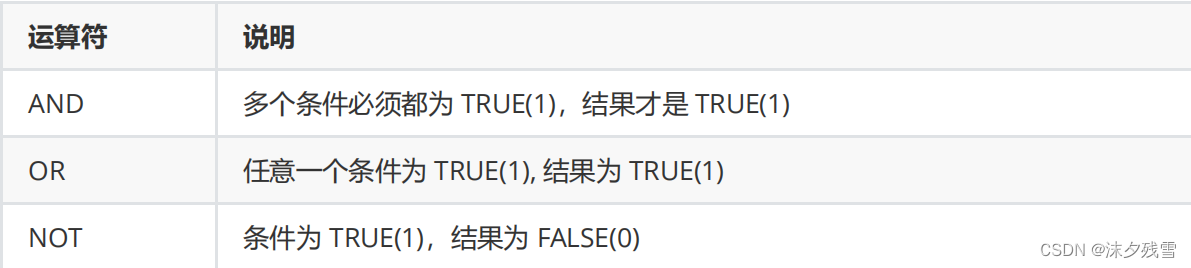
逻辑运算符
例:
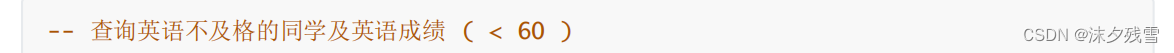
注意:条件比较的时候需要有where关键字
注意理解查询语句的执行的过程
1.服务器需要先遍历表中的每一个记录
2.针对当前记录,带入条件,看是否成立
3.如果条件成立,则这一条记录加入结果集,并返回给客户端.如果条件不成立,则这一纪录跳过
![]()
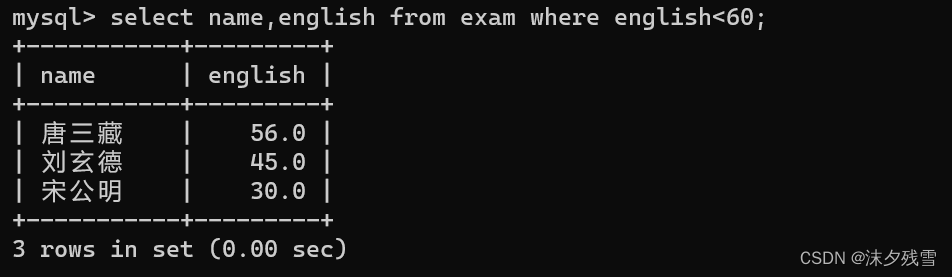
条件比较的时候,并不只是使用列名和常量比较.也可以使用列名和其他列名比较.
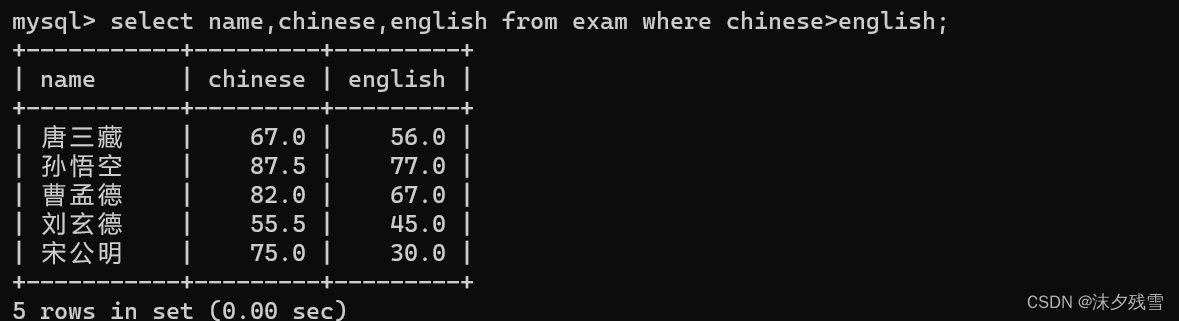
![]()

在MySQL的where条件中无法使用列的别名!!!
为什么?
解释一:
语法规定,不为什么
解释二:
站在SQL的执行顺序上边来看
select语句执行顺序
1.遍历某个指定的行
2.带入条件筛选
3.条件为true,被筛选成功后,再计算select列名这里的表达式...
(显然,先带入条件筛选,在计算表达式,带带入条件时SQL并不知道 别名 是什么,所以无法通过别名来筛选)
AND

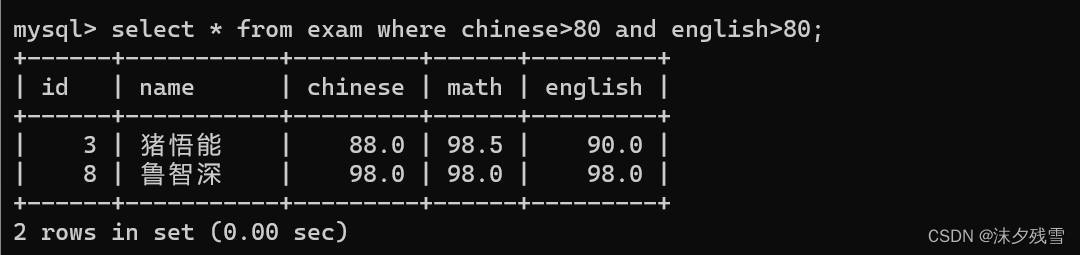
OR
![]()
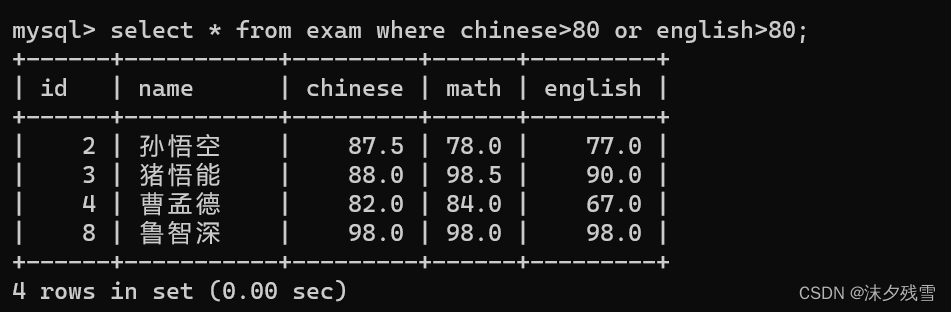
BETWEEN...AND...
![]()
在计算机中我们谈到区间一般是前闭后开[ )
但是between...and...是一个闭区间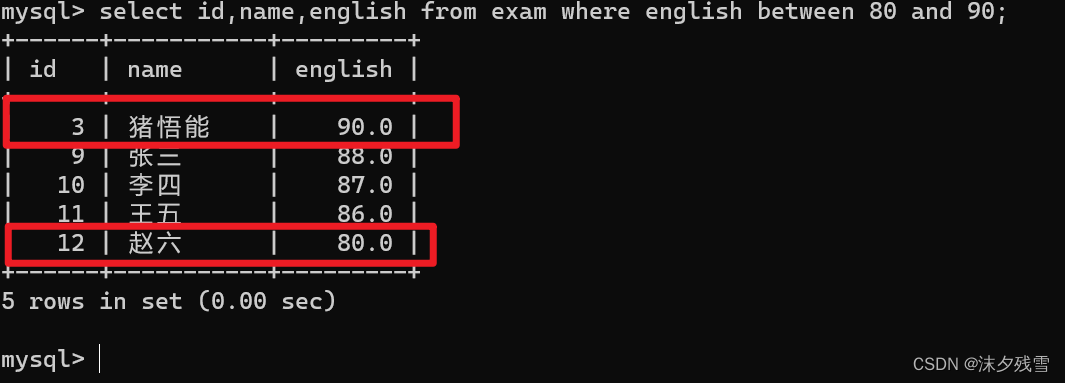
上述是筛选英语成绩在[80,90]之间的数据,可见between...and...是一个闭区间
IN

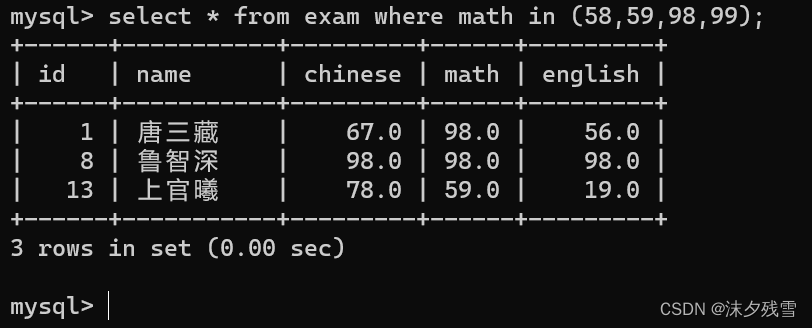
当然,面对这个问题我们还可以使用 OR 这个关键字来解决
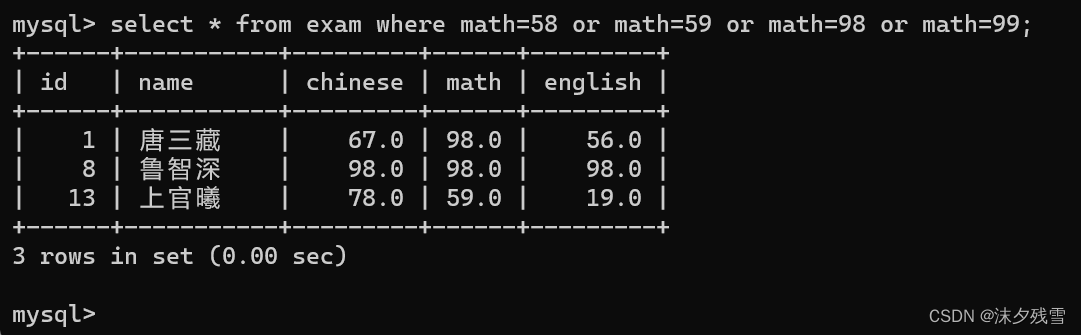
模糊查询 LIKE
% 匹配0个 或任意个 任意字符
_ 匹配1个 任意字符
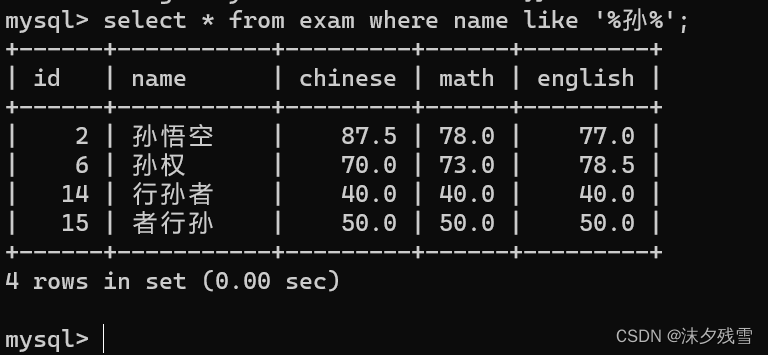
例:查询名字的第一个字为'孙'的数据
这里我们使用了 % 可以看出,%可以表示 任意个 任意字符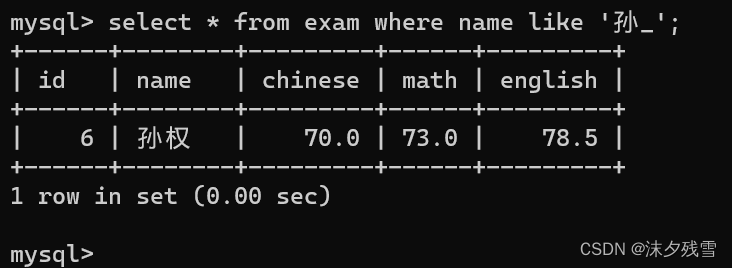
而当我们使用了 _ 可以看出,_可以表示 1个 任意字符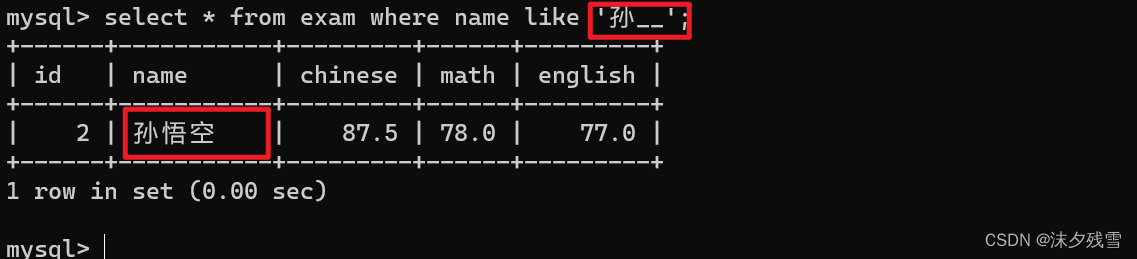
两个 _ 可以表示 2个 任意字符
%孙:以孙结尾的
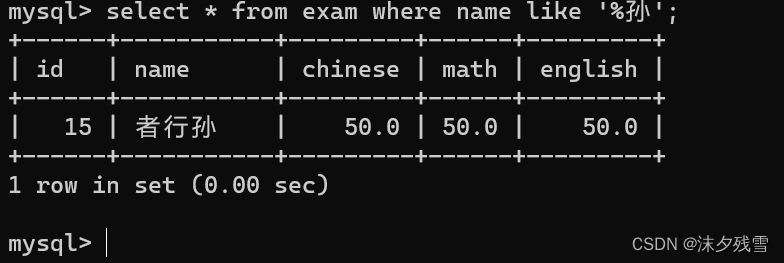
%孙%:包含 孙 的
注意:MySQL进行模糊查询是一个比较慢的操作!!尤其是针对一些比较长的字符串,因为MySQL在工作中本来也就要频繁地与硬盘进行交互.
NULL的查询:IS [NOT] NULL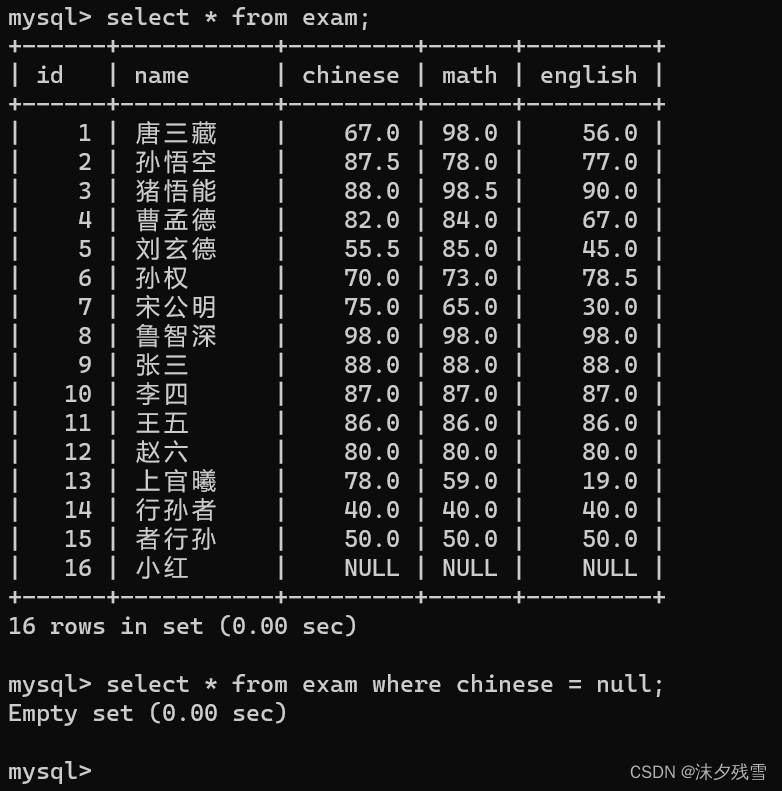
如上图所示我们不能使用=来比较null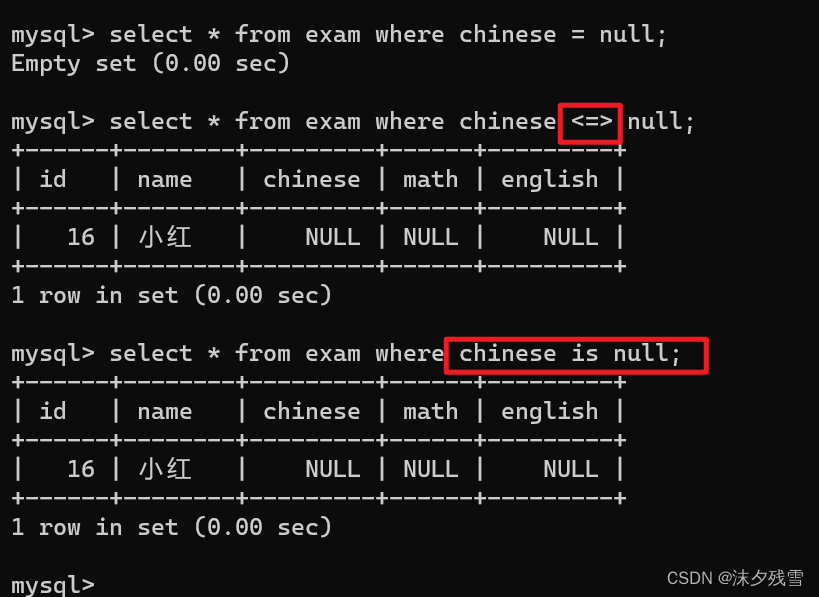
但我们可以用如上两种方式来比较null
那么用 比较与用 is null 来比较有什么不一样呢?
: 可以比较两个列
is null: 只能是一个列与null进行比较
分页查询limit
针对查询出来的结果进行截取,取出其中的一个部分
例: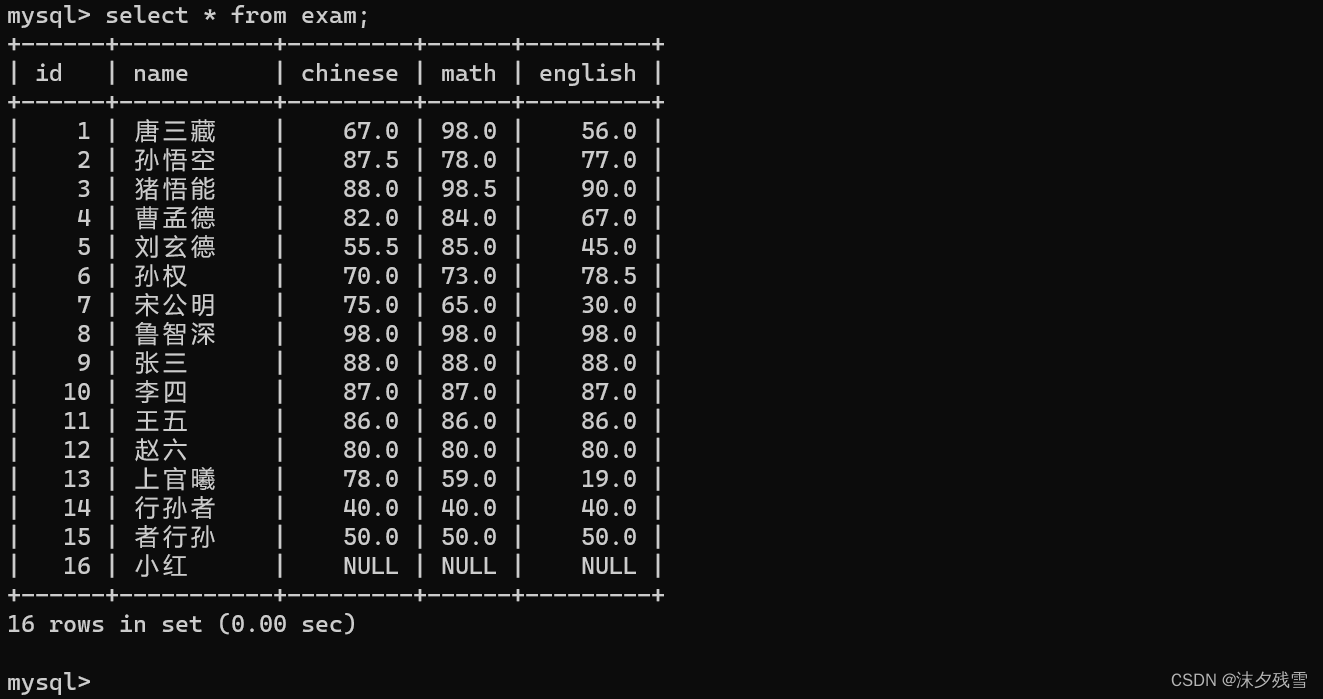
现在我们一共有16条记录
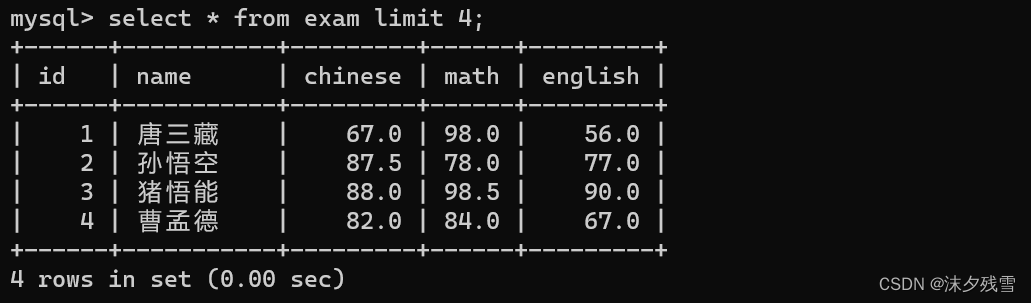
select * from exam limit 4;
这行语句告诉我们,我们现在可以取出exam中的所有数据,但是limit限制了我们一次只能取出4条数据

offset 描述了当前的结果是从哪一条记录开始算的,这里的offset 4 就可以理解为从下标为4的地方开始算(注意:下标从0开始)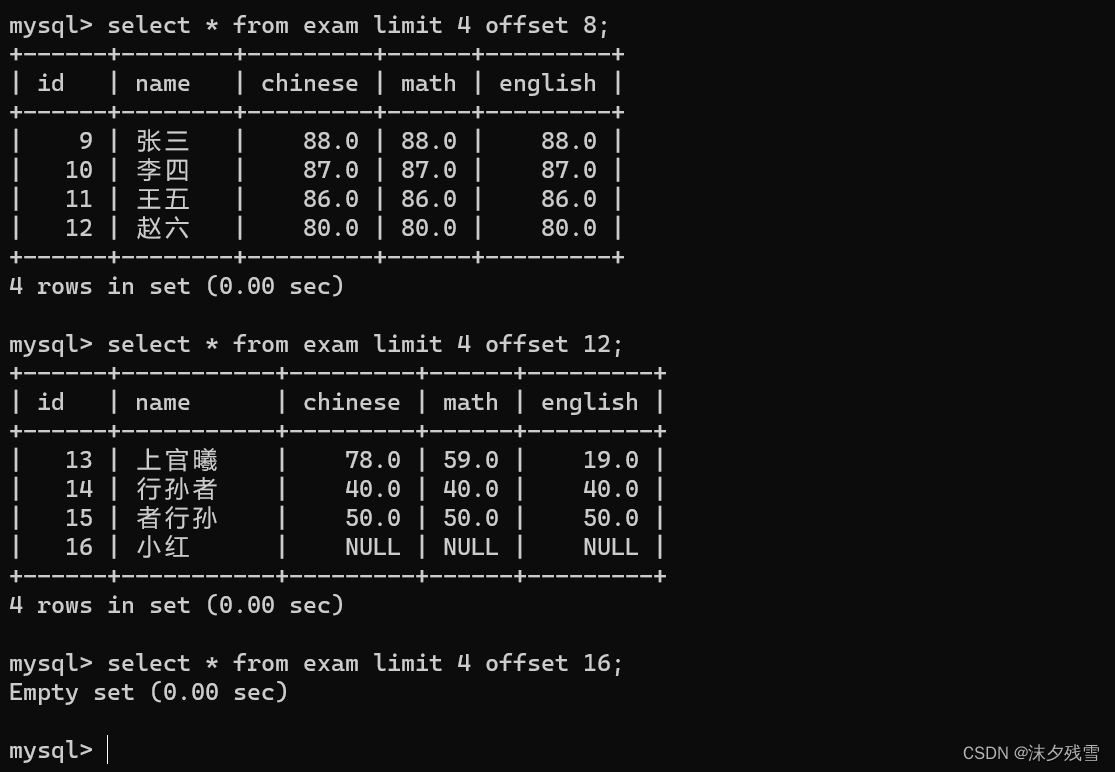
这里分别是第3页和第4页,当我们尝试访问第5页的时候,因为我们压根没有第5页,所以这里会出现Empty.
3.修改
update 表名 set 列名 = 值 where 条件...;
此时 = 是赋值的意思
update 可以理解为 先查询 后修改
注意:修改是修改MySQL服务器上的数据(保存在硬盘上,持久存在)
需要明确的一些信息
1.改那个表
2.改这个表的哪个列/哪些列,改成什么
3.修改这个表的哪些行
例:

一次修改多个数据
![]()
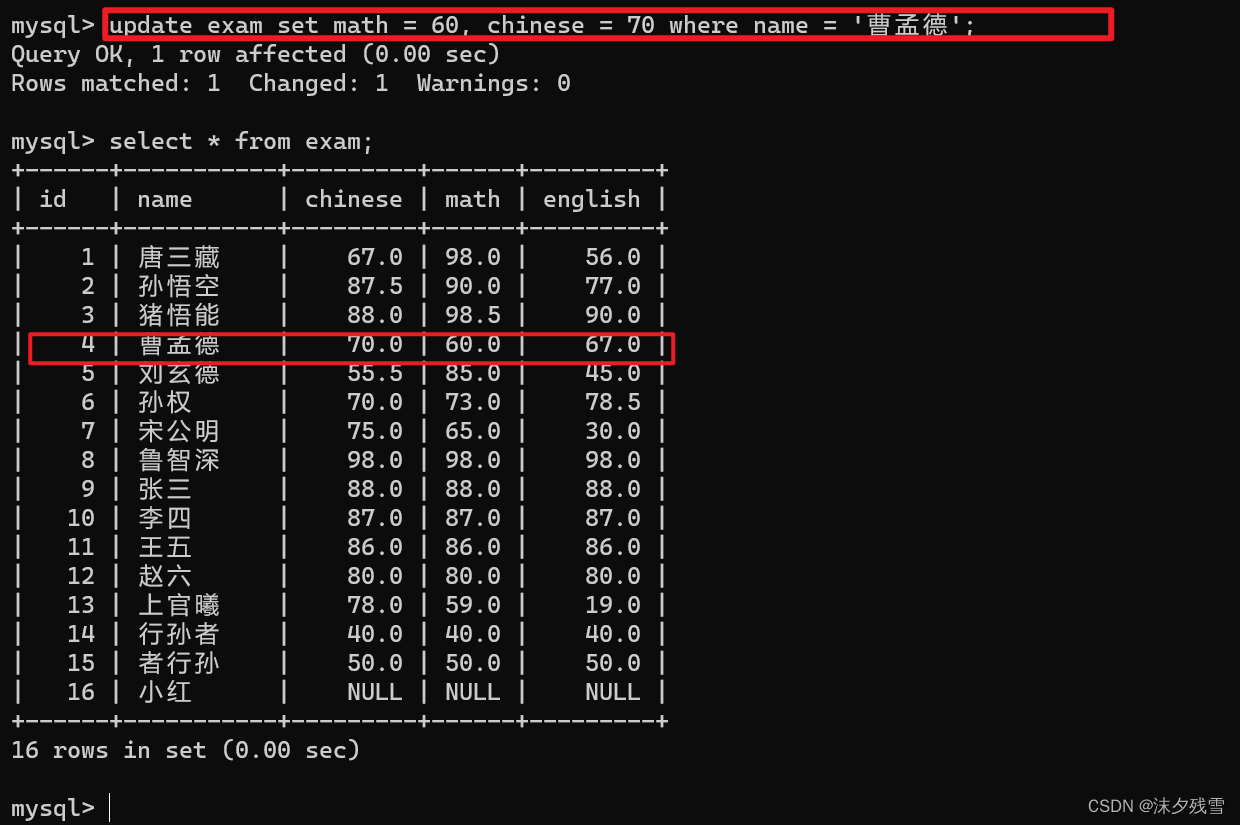
![]()
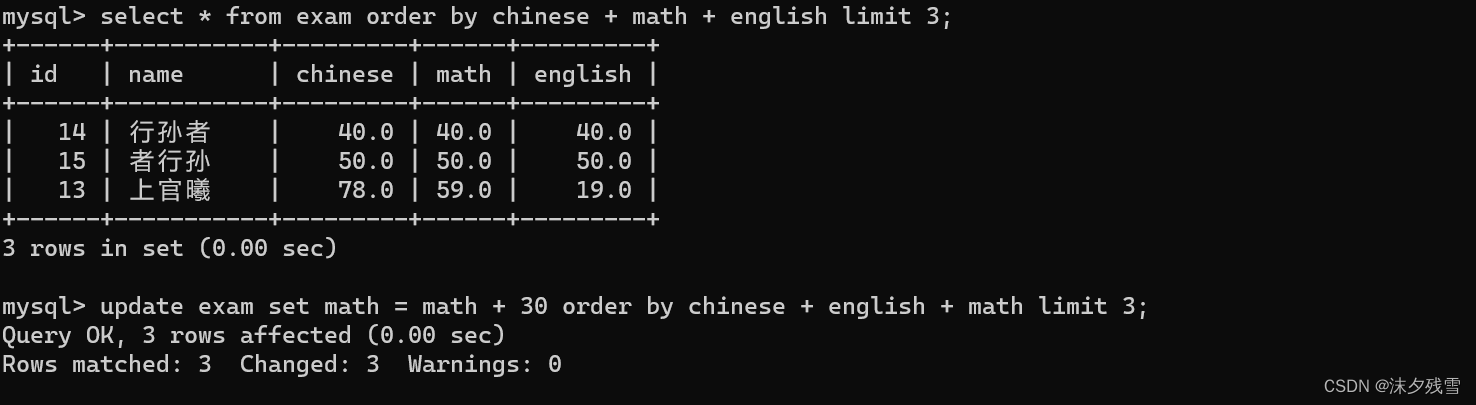
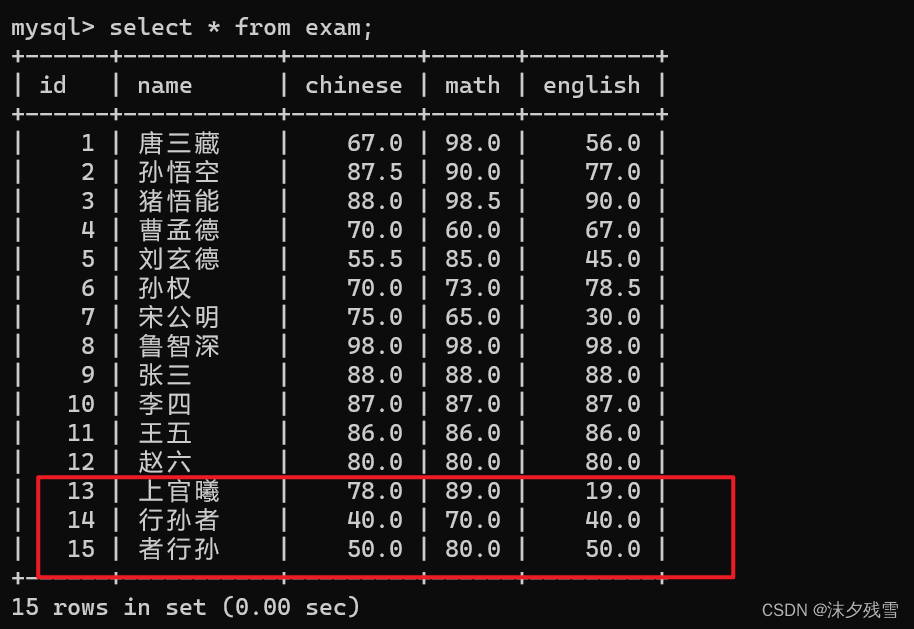
4.删除
delet form 表名 where 条件;
例:假如我们现在要删除'行孙者'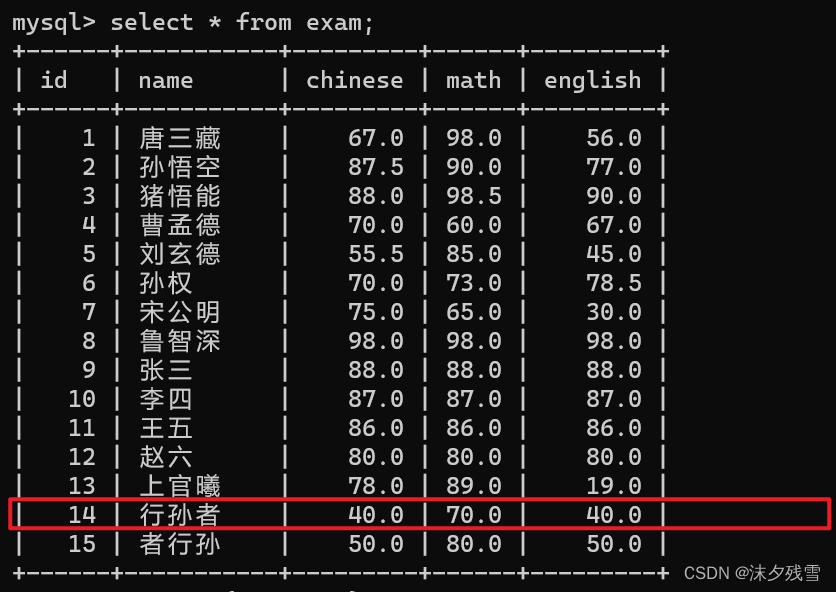
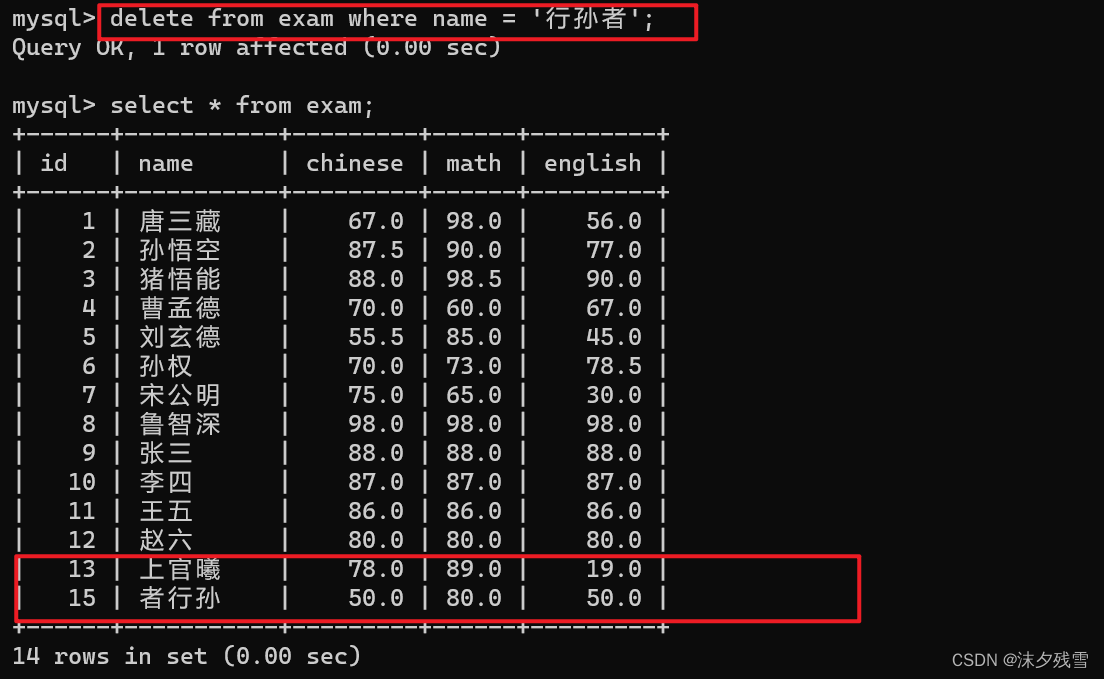
由此,我们可以看出,删除是按照行来删除的,我们无法删除某些列
delete 和 drop 的区别
注意:如果我们在 delete 的时候没有指定条件,则会把整张表的数据都删除,效果和 drop 是差不多的.但是请注意,delete 是删除整张表的数据(表还在)而 drop 是删除整个表(表都没了).
都看到这里了,不点个赞再走嘛~~

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









