







Collectors中的方法使用
数据集合
ArrayList<Person> list = new ArrayList<>(10);
list.add(new Person().setId(0).setAge(10).setName("a"));
list.add(new Person().setId(1).setAge(11).setName("b"));
list.add(new Person().setId(2).setAge(12).setName("c"));
list.add(new Person().setId(3).setAge(13).setName("d"));
list.add(new Person().setId(4).setAge(14).setName("e"));
list.add(new Person().setId(5).setAge(15).setName("f"));
list.add(new Person().setId(6).setAge(16).setName("g"));
list.add(new Person().setId(7).setAge(17).setName("h"));
list.add(new Person().setId(8).setAge(18).setName("i"));
list.add(new Person().setId(9).setAge(19).setName("j"));
averaging 求平均值

示例代码:
System.out.println(list.stream().collect(Collectors.averagingInt(Person::getAge)));
运行结果:
14.5
collectionAndThen
先将数据用Collectors进行操作,再将其返回值用于下一个函数的操作
示例代码:
Optional<Person> optionalPerson = list.stream().collect(Collectors.collectingAndThen(Collectors.reducing((person1, person2) -> {
return new Person().setAge(person1.getAge() + person2.getAge());
}), person -> person));
optionalPerson.ifPresent(System.out::print);
运行结果:
Person(id=0, age=145, name=null)
示例代码:
Double collect = list.stream().collect(Collectors.collectingAndThen(Collectors.averagingInt(Person::getAge), ave -> ave));
Iterator<Person> collect1 = list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::iterator));
counting
示例代码:
System.out.println(list.stream().collect(Collectors.counting()));
运行结果:
10
groupingBy

方法一:
根据分组属性,将具有相同属性的归为一组。
示例代码:
list.add(new Person().setId(7).setAge(17).setName("h"));
Map<Integer, List<Person>> map = list.stream().collect(Collectors.groupingBy(Person::getAge));
for (Map.Entry<Integer, List<Person>> entry : map.entrySet()) {
System.out.println(entry.getKey()+ " " + entry.getValue());
}
运行结果:
16 [Person(id=6, age=16, name=g)]
17 [Person(id=7, age=17, name=h), Person(id=7, age=17, name=h)]
18 [Person(id=8, age=18, name=i)]
19 [Person(id=9, age=19, name=j)]
10 [Person(id=0, age=10, name=a)]
11 [Person(id=1, age=11, name=b)]
12 [Person(id=2, age=12, name=c)]
13 [Person(id=3, age=13, name=d)]
14 [Person(id=4, age=14, name=e)]
15 [Person(id=5, age=15, name=f)]
方法二:
将数据进行分组再将分组后得到的map的值作为流传递给第二个Collector类型函数进行操作,并将得到的返回值作为新的值。
相当于分组后把值作为流分别进行一次collect操作将得到的结果作为新的值。
示例代码:
Map<Integer, Double> map = list.stream().collect(Collectors.groupingBy(Person::getAge, Collectors.averagingInt(Person::getAge)));
for (Map.Entry<Integer, Double> entry : map.entrySet()) {
System.out.println(entry.getKey()+ " " + entry.getValue());
}
运行结果:
16 16.0
17 17.0
18 18.0
19 19.0
10 10.0
11 11.0
12 12.0
13 13.0
14 14.0
15 15.0
示例代码:
Map<Integer, List<Person>> map = list.stream().collect(Collectors.groupingBy(Person::getAge, Collectors.toList()));
for (Map.Entry<Integer, List<Person>> entry : map.entrySet()) {
System.out.println(entry.getKey()+ " " + entry.getValue());
}
运行结果:
16 [Person(id=6, age=16, name=g)]
17 [Person(id=7, age=17, name=h), Person(id=7, age=17, name=h)]
18 [Person(id=8, age=18, name=i)]
19 [Person(id=9, age=19, name=j)]
10 [Person(id=0, age=10, name=a)]
11 [Person(id=1, age=11, name=b)]
12 [Person(id=2, age=12, name=c)]
13 [Person(id=3, age=13, name=d)]
14 [Person(id=4, age=14, name=e)]
15 [Person(id=5, age=15, name=f)]
方法三:
在方法二的基础上添加了自定义map类型的功能
方法一和方法二返回的类型为Map
示例代码:
HashMap<Integer, List<Person>> map = list.stream().collect(Collectors.groupingBy(Person::getAge, HashMap::new, Collectors.toList()));
for (Map.Entry<Integer, List<Person>> entry : map.entrySet()) {
System.out.println(entry.getKey()+ " " + entry.getValue());
}
partitioningBy

partitioningBy的key只有true/false两种情况,true的部分即符合分区条件集合,false部分为不符合分区条件的集合。
方法一:
示例代码:
Map<Boolean, List<Person>> map = list.stream().collect(Collectors.partitioningBy(person -> person.getAge() > 14));
for (Map.Entry<Boolean, List<Person>> entry : map.entrySet()) {
System.out.println(entry.getKey()+ " " + entry.getValue());
}
运行结果:
false [Person(id=0, age=10, name=a), Person(id=1, age=11, name=b), Person(id=2, age=12, name=c), Person(id=3, age=13, name=d), Person(id=4, age=14, name=e)]
true [Person(id=5, age=15, name=f), Person(id=6, age=16, name=g), Person(id=7, age=17, name=h), Person(id=8, age=18, name=i), Person(id=9, age=19, name=j)]
方法二:
示例代码:
Map<Boolean, Long> map = list.stream().collect(Collectors.partitioningBy(person -> person.getAge() > 14, Collectors.counting()));
for (Map.Entry<Boolean, Long> entry : map.entrySet()) {
System.out.println(entry.getKey()+ " " + entry.getValue());
}
运行结果:
false 5
true 5
joining

方法一:
示例代码:
System.out.println(Stream.of("a", "b", "c", "d").collect(Collectors.joining()));
运行结果:
abcd
方法二:
示例代码:
System.out.println(Stream.of("a", "b", "c", "d").collect(Collectors.joining("--")));
运行结果:
a--b--c--d
方法三:
示例代码:
System.out.println(Stream.of("a", "b", "c", "d").collect(Collectors.joining("--", "pre-", "-suf")));
运行结果:
pre-a--b--c--d-suf
mapping

将流使用第一个函数进行处理,再将处理后获得的流进行collect操作
示例代码:
System.out.println(list.stream().collect(Collectors.mapping(Person::getId, Collectors.toList())));
运行结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 7]
示例代码:
System.out.println(list.stream().collect(Collectors.mapping(Person::getAge, Collectors.reducing((item1, item2) -> item1 + item2))));
maxBY和minBy
示例代码:
System.out.println(list.stream().collect(Collectors.maxBy(Comparator.comparingInt(Person::getAge))));
System.out.println(list.stream().collect(Collectors.minBy(Comparator.comparingInt(Person::getAge))));
运行结果:
Optional[Person(id=9, age=19, name=j)]
Optional[Person(id=0, age=10, name=a)]
reducing
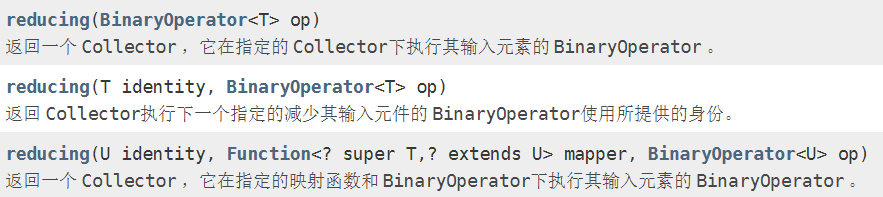
summarizing

示例代码:
IntSummaryStatistics collect = list.stream().collect(Collectors.summarizingInt(Person::getAge));
System.out.println(collect.getSum());
System.out.println(collect.getCount());
System.out.println(collect.getAverage());
System.out.println(collect.getMax());
System.out.println(collect.getMin());
运行结果:
145
10
14.5
19
10
summing

示例代码:
System.out.println(list.stream().collect(Collectors.summingInt(Person::getAge)));
运行结果:
145
toList
List<String> list = stream.collect(Collectors.toList());
toSet
Set<String> collect = stream.collect(Collectors.toSet());
toMap

方法一:
Map<String, String> map = Stream.of("a", "b", "c", "a").collect(Collectors.toMap(x -> x, x -> x + x,(oldVal, newVal) -> newVal));
方法二:
自定义map类型
HashMap<String, String> map = Stream.of("a", "b", "c", "a").collect(Collectors.toMap(x -> x, x -> x + x,(oldVal, newVal) -> newVal, HashMap::new));
当toMap中没有用合并函数时,出现key重复时,会抛出异常
toCollection
保存到指定的集合中
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









