






1、学习目标
1、熟练数据集,了解数据集,对数据集进行验证来确定所获的数据集为接下来的机器学习或者深度学习使用。
2、学会去了解变量间的相互关系以及变量与预测值之间的存在关系。
3、了解数据处理以及特征工程的步骤。
2、内容介绍
- 载入各种数据科学以及可视化库:
- 数据科学库 pandas、numpy、scipy;
- 可视化库 matplotlib、seabon;
- 载入数据:
- 载入训练集和测试集;
- 简略观察数据(head()+shape);
- 数据总览:
- 通过describe()来熟悉数据的相关统计量
- 通过info()来熟悉数据类型
- 判断数据缺失和异常
- 查看每列的存在nan情况
- 异常值检测
- 了解预测值的分布
- 总体分布概况
- 查看skewness and kurtosis
- 查看预测值的具体频数
3、熟悉分析流程
1、导入训练集、测试集查看数据集的基本情况:行列信息,首尾数据
import pandas as pd
import matplotlib.pyplot as plt
train_data =pd.read_csv('./train.csv')
test_data = pd.read_csv('./testA.csv')
print(train_data.head().append(train_data.tail())) #观察train首尾数据
print(train_data.shape() ) #观察数据集的行列信息

从输出结果看出,训练数据有100000行,3列。
列标签有:
id - 心跳信号分配的唯一标识
heartbeat_signals - 心跳信号序列
abel - 心跳信号类别(0、1、2、3)
#观察testA中数据集的行列值
print(test_data.head().append(test_data.tail()))
print(test_data.shape())
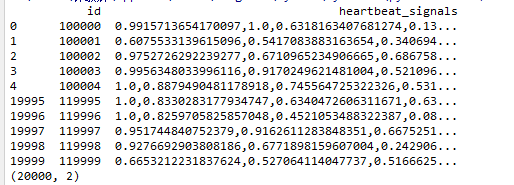
观察到test_data中数据有20000行,2列
列标签为:
id、heartbeat_singnals
2、总览数据概况
学习到的两个函数
describe
infor
data.describe() —获取数据的相关统计量
示例:
- 对于数字数据

返回的结果包括计数、平均数、标准差(std)、最小值、较低百分位25%和50%(和中位数一样),较高百分位75%
- 对于字符串数据或时间戳数据

- 对于DataFrame(默认只返回数字列的相关统计量)

返回所有列的统计信息

#详细使用文档参考
链接: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.describe.html
data.info() —获取数据类型
日常工作中,通常使用它来查看数据的基本统计信息(如索引、列数、列名、数据量、数据类型、缺失值、内存等)。
##结合本案例使用观察数据集信息:
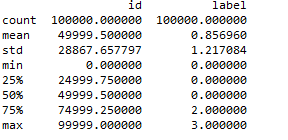
获取train数据的相关统计量
train_data.describe()
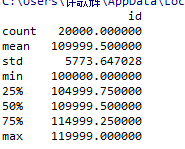
获取testA数据的相关统计量
test_data.describe()
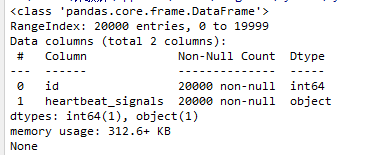
获取testA的数据类型
test_data.info()
3、判断数据缺失和异常
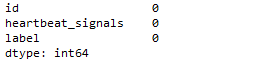
data.isnull().sum() —查看每列的存在NaN情况
查看train每列的存在NaN情况
train_data.isnull().sum()
4、了解预测值的分布
train_data['label']
train_data['label'].value_counts() #计算每个不同值在该列中有多少重复值。

总体分布概况(无界约翰逊分布等)
import scipy.stats as st
y = Train_data['label']
plt.figure(1); plt.title('Default')
sns.distplot(y, rug=True, bins=20)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)



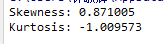
查看skewness and kurtosis
##偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。定义上偏度是样本的三阶标准化矩。
##峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观看来,峰度反映了峰部的尖度。随机变量的峰度计算方法为:随机变量的四阶中心矩与方差平方的比值。
sns.distplot(train_data['label']);
print("Skewness: %f" % train_data['label'].skew())
print("Kurtosis: %f" % train_data['label'].kurt())
print(train_data.skew(), train_data.kurt())

sns.distplot(train_data.kurt(),color='orange',axlabel ='Kurtness')
查看预测值的具体频数
plt.hist(train_data['label'], orientation = 'vertical',histtype = 'bar', color ='red')
##绘制直方图观察
plt.show()

4、学习总结
1、了解了EDA的过程,掌握分析数据集的基础办法,知道了要从哪些方面入手。
2、作为小白了解到了在探索分析数据是常用的一些方法。
- data.head().append(data.tail())查看首尾数据;
- data.shape() 观察数据集的行列信息;
- data.describe() 获取数据的相关统计量;
- data.info() 获取数据类型;
- data.isnull().sum() 查看每列的存在NaN情况;
- 查看skewness 和 kurtosis
- 用直方图查看预测值的具体频数















 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









