






一、数据准备
1. 标注工具
标注工具github地址:https://github.com/HumanSignal/labelImg
2. 数据标注
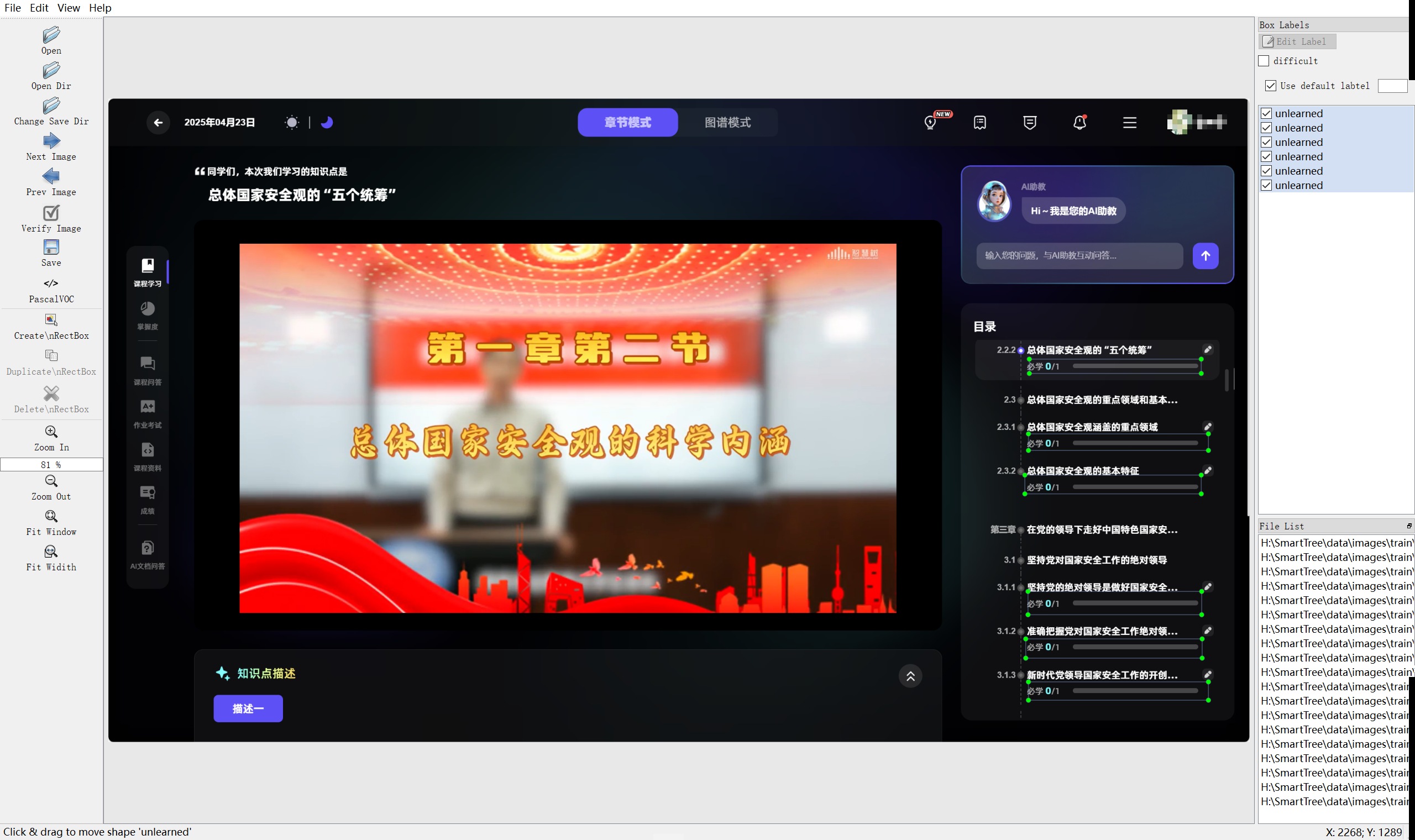
1. 从课程主页面截取图片并使用labeling软件进行标注并保存yolo格式的标注文件,如下图所示:
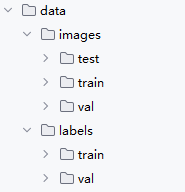
2. 将标注好的数据和训练数据存放到类似下图所示的目录结构中
二、训练推理
1. 训练模块
1. 使用YOLO Python 进行训练,可参考官方文档:Python 使用方法 -Ultralytics YOLO 文档,代码如下:
# 引入ultralytics 库
from ultralytics import YOLO
model = YOLO("yolo11n.yaml")
model = YOLO("yolo11n.pt") # 引入预训练文件
# 训练
results = model.train(
data="data_config.yaml",
epochs=200,
imgsz=1024,
batch=16,
seed=128,
device=0,
patience=30,
# 学习率设置
lr0=0.001,
lrf=0.005,
momentum=0.937,
weight_decay=0.0005,
warmup_epochs=3.0,
warmup_momentum=0.8,
warmup_bias_lr=0.1,
# 损失函数权重
box=0.05,
cls=0.7,
dfl=1.5,
pose=12.0,
kobj=1.0,
nbs=64,
# 图像增强
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
degrees=0.0,
translate=0.1,
scale=0.5,
shear=0.0,
perspective=0.0,
flipud=0.0,
fliplr=0.5,
bgr=0.0,
mosaic=0.5,
mixup=0.2
)2. data_config.yaml文件如下(注意Windows和Linux系统的路径格式):
path: /data/coding/data
train: images/train
val: images/val
nc: 1
names:
0: unlearned3. 训练结果如下图所示:

2. 推理模块
1. 训练完成后会在根目录生成一个runs目录,目录中的detect/train/weight/目录下有保存的best.pt文件,使用此文件对图片进行推理,代码如下:
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO("yolo11n.pt") # load an official model
model = YOLO("/data/coding/runs/detect/train/weights/best.pt") # load a custom model
metrics = model.val() # no arguments needed, dataset and settings remembered
metrics.box.map # map50-95
metrics.box.map50 # map50
metrics.box.map75 # map75
metrics.box.maps # a list contains map50-95 of each category
# 对图片进行推理
results = model.predict(
source='/data/coding/data/images/test',
imgsz=1024,
conf=0.2,
iou=0.6,
save=True,
save_txt=True,
save_json=True,
project='/data/coding',
name="test_1_predictions", # 保存推理后的图像的位置
device="0"
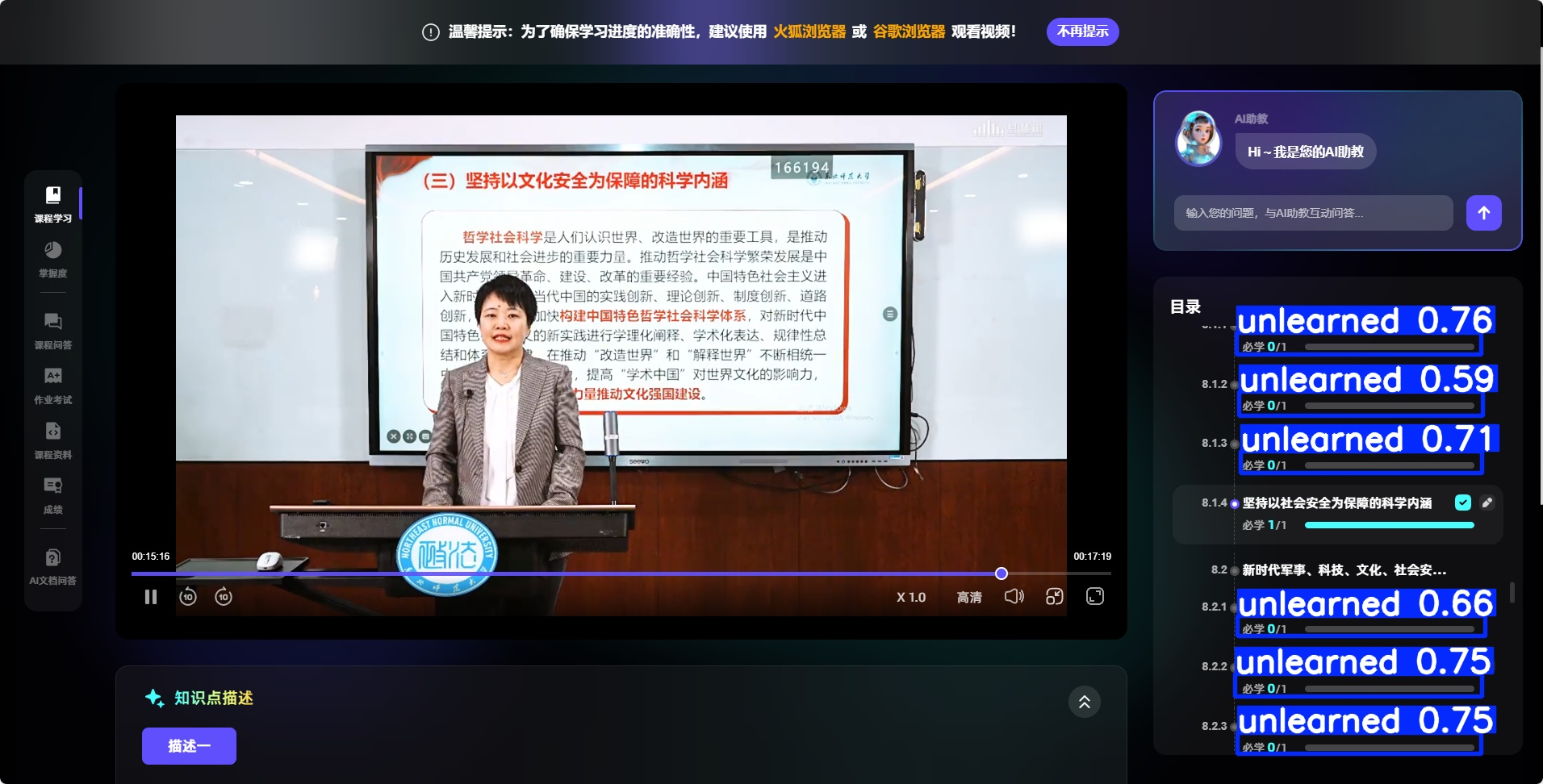
)结果如下图:
或者使用cv2对推理的图片画上边界框,代码如下:
import cv2
from ultralytics import YOLO
model = YOLO("/data/coding/runs/detect/train/weights/best.pt")
image = cv2.imread('img.png')
# print(image)
results = model(image)
unleared = results[0].boxes.xywh.cpu().numpy()
for face in unleared:
x_center, y_center, w, h = face
x1, y1 = int((x_center - w / 2)), int((y_center - h / 2))
x2, y2 = int((x_center + w / 2)), int((y_center + h / 2))
face_img = image[y1:y2, x1:x2]
# print(face_img)
print(x1, y1, x2, y2)
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 5)
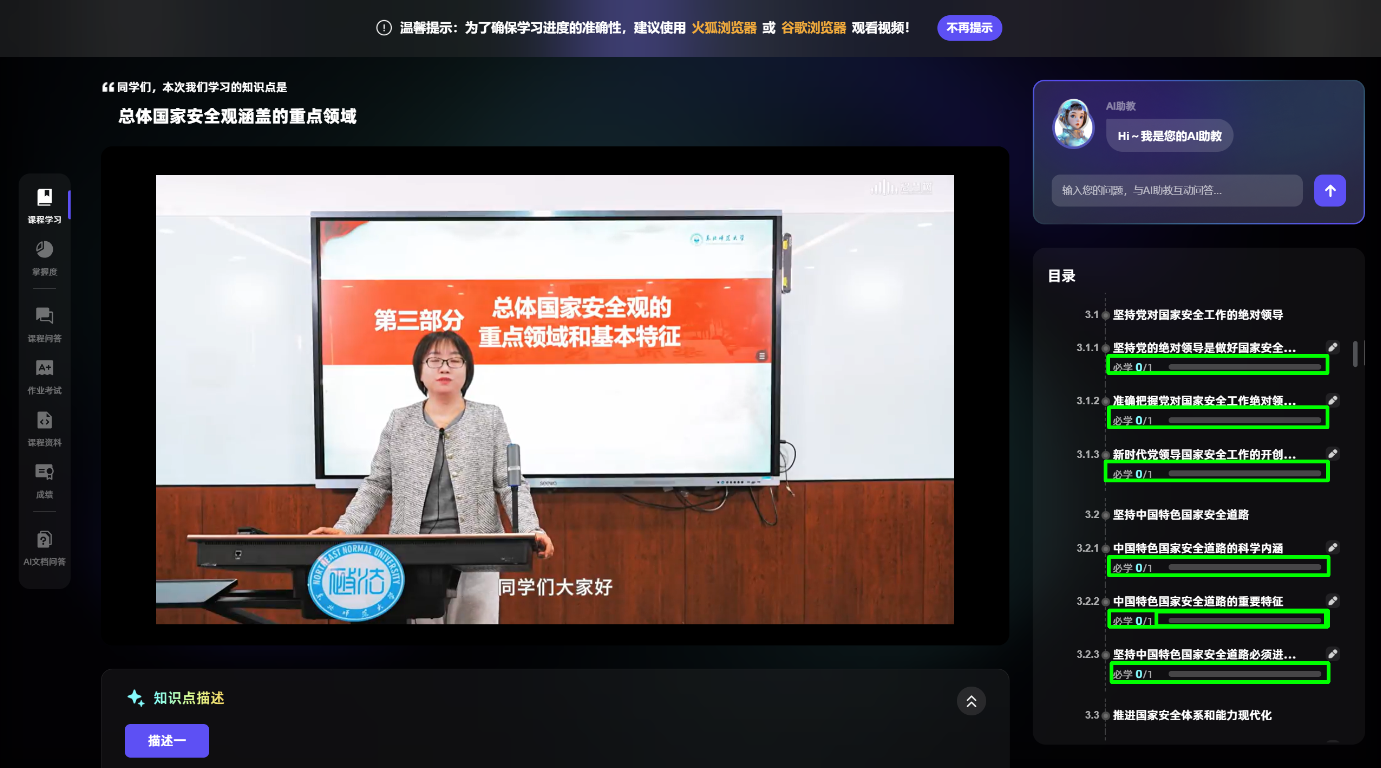
cv2.imwrite('output.png', image)结果如下:
三、自动化实现
1. 实现思路
观察发现此课程不受倍速限制,故可尝试使用浏览器倍速插件如:global speed和selenium库实现自动化。使用selenium库实现基本的登录、滚动滚动条、移动、点击等工作;对上述使用cv2的推理代码进行封装用来获得推理后图片的边界框的中心坐标,使用pyautogui库将鼠标移动此坐标后执行点击操作。
2. 具体流程
当登录进入该课程后,使用pyautogui库截取整张屏幕的图片上传到推理模块获取到所有未学习课程的中心坐标,并将其放到一个列表中,遍历此列表,执行点击操作,鼠标会依次移动到并点击每个未学习的课程。当遍历完列表时,列表清空执行滑动页面操作,并重复上述操作直到手动终止程序或者到设置的截止时间。
3. 实现代码
import cv2
from ultralytics import YOLO
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pyautogui
model = YOLO("best.pt") # 使用训练好的best.pt文件
option = webdriver.ChromeOptions()
option.add_argument("--mute-audio")
option.add_argument("--user-data-dir=C:/Users/25401/AppData/Local/Google/Chrome/User Data/") # 换成自己的电脑路径,以便使用倍速插件
option.add_experimental_option("excludeSwitches", ['enable-automation'])
option.add_experimental_option("useAutomationExtension", False)
browser = webdriver.Chrome(options=option)
actions = ActionChains(browser)
browser.maximize_window()
wait = WebDriverWait(browser, 60)
browser.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """Object.defineProperty(navigator, 'webdriver', {get: () => undefined})""",
})
browser.get('https://onlineweb.zhihuishu.com/onlinestuh5')
USERNAME = '你自己的用户名' # username改成你自己的用户名
PASSWORD = '你自己的密码.' # password改成你自己的密码
time.sleep(2)
browser.find_element(By.XPATH, value='//*[@id="lUsername"]').send_keys(USERNAME)
time.sleep(0.1)
browser.find_element(By.XPATH, value='//*[@id="lPassword"]').send_keys(PASSWORD)
time.sleep(0.1)
browser.find_element(By.XPATH, value='//*[@id="f_sign_up"]/div[1]/span').click()
time.sleep(5)
wait.until(
EC.element_to_be_clickable((By.XPATH, '//*[@id="sharingClassed"]/div[2]/ul[1]/div/dl/dt/div[1]/div[1]'))).click()
time.sleep(20)
print("20s later")
sit_list = []
count = 1
def scroll():
scrollable_area = browser.find_element(By.XPATH,
value='//*[@id="app"]/div/div[2]/div/div[3]/div/div/div[2]/div[2]/div[2]/div[3]/div')
actions.move_to_element(scrollable_area).click_and_hold().move_by_offset(0, 25).release().perform()
def get_center_sit():
global count
screenshot = pyautogui.screenshot()
screenshot.save(f'./screenshot/input/{count}.png')
img = cv2.imread(f'./screenshot/input/{count}.png')
results = model(img)
unlearned = results[0].boxes.xywh.cpu().numpy()
for box in unlearned:
x_center, y_center, w, h = box
x1, y1 = int((x_center - w / 2)), int((y_center - h / 2))
x2, y2 = int((x_center + w / 2)), int((y_center + h / 2))
sit_list.append((x_center, y_center))
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 5)
cv2.imwrite(f'./screenshot/output/{count}.png', img)
count += 1
print(sit_list)
def move_and_click(x, y):
pyautogui.moveTo(x, y)
pyautogui.click()
# 无限循环,终止程序需手动结束,亦可自己设置终止时间
if __name__ == '__main__':
while True:
get_center_sit()
time.sleep(2)
if len(sit_list) > 0:
for sit in sit_list:
move_and_click(sit[0], sit[1])
print('next')
time.sleep(60)
sit_list = []
scroll()
time.sleep(1)
四、总结
上述通过使用yolo11和selenium以及pyautogui实现了智慧树的国家安全教育课程自动化,解放双手。同时也可当做入门yolo或selenium的一个小实践。
注:上述代码中均在linux环境下实现,使用Windows系统的用户需注意路径格式。使用Selenium库需下载浏览器驱动程序,如果使用的是Chrome浏览器,需下载chromedriver。selenium代码没有包含登录时的滑动验证码操作也没有包含刚进入视频界面时关闭弹窗的操作,需手动操作。后附主要代码文件。
代码文件提取码:VIXu


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









