







主串和模式串
在开始讲解这个算法之前,我先定义两个概念,方便我后面讲解。它们分别是主串和模式串。这俩概念很好理解,我举个例子你就懂了。
比方说,我们在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串。我们把主串的长度记作 n,模式串的长度记作 m。因为我们是在主串中查找模式串,所以 n>m。
BF 算法
BF 算法中的 BF 是 Brute Force 的缩写,中文叫作暴力匹配算法,也叫朴素匹配算法。从名字可以看出,这种算法的字符串匹配方式很“暴力”,当然也就会比较简单、好懂,但相应的性能也不高。
作为最简单、最暴力的字符串匹配算法,BF 算法的思想可以用一句话来概括,那就是,我们在主串中,检查起始位置分别是 0、1、2…n-m 且长度为 m 的 n-m+1 个子串,看有没有跟模式串匹配的。我举一个例子给你看看,你应该可以理解得更清楚。
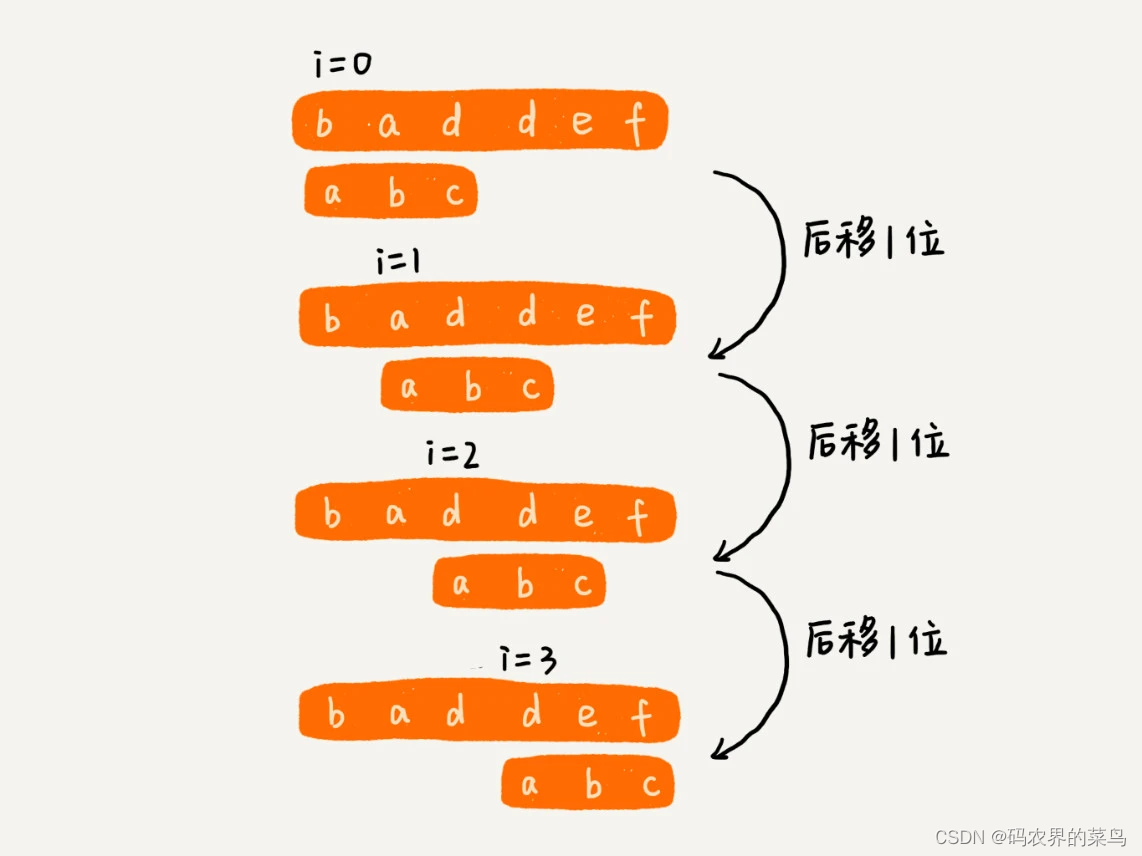
从上面的算法思想和例子,我们可以看出,在极端情况下,比如主串是“aaaaa…aaaaaa”(省略号表示有很多重复的字符 a),模式串是“aaaaab”。我们每次都比对 m 个字符,要比对 n-m+1 次,所以,这种算法的最坏情况时间复杂度是 O(n*m)。
尽管理论上,BF 算法的时间复杂度很高,是 O(n*m),但在实际的开发中,它却是一个比较常用的字符串匹配算法。为什么这么说呢?原因有两点。
第一,实际的软件开发中,大部分情况下,模式串和主串的长度都不会太长。而且每次模式串与主串中的子串匹配的时候,当中途遇到不能匹配的字符的时候,就可以就停止了,不需要把 m 个字符都比对一下。所以,尽管理论上的最坏情况时间复杂度是 O(n*m),但是,统计意义上,大部分情况下,算法执行效率要比这个高很多。
第二,朴素字符串匹配算法思想简单,代码实现也非常简单。简单意味着不容易出错,如果有 bug 也容易暴露和修复。在工程中,在满足性能要求的前提下,简单是首选。这也是我们常说的KISS(Keep it Simple and Stupid)设计原则。
所以,在实际的软件开发中,绝大部分情况下,朴素的字符串匹配算法就够用了。
RK 算法
RK 算法的全称叫 Rabin-Karp 算法,是由它的两位发明者 Rabin 和 Karp 的名字来命名的。这个算法理解起来也不是很难。我个人觉得,它其实就是刚刚讲的 BF 算法的升级版。
我在讲 BF 算法的时候讲过,如果模式串长度为 m,主串长度为 n,那在主串中,就会有 n-m+1 个长度为 m 的子串,我们只需要暴力地对比这 n-m+1 个子串与模式串,就可以找出主串与模式串匹配的子串。
但是,每次检查主串与子串是否匹配,需要依次比对每个字符,所以 BF 算法的时间复杂度就比较高,是 O(n*m)。我们对朴素的字符串匹配算法稍加改造,引入哈希算法,时间复杂度立刻就会降低。
RK 算法的思路是这样的:我们通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小。如果某个子串的哈希值与模式串相等,那就说明对应的子串和模式串匹配了(这里先不考虑哈希冲突的问题,后面我们会讲到)。因为哈希值是一个数字,数字之间比较是否相等是非常快速的,所以模式串和子串比较的效率就提高了。

不过,通过哈希算法计算子串的哈希值的时候,我们需要遍历子串中的每个字符。尽管模式串与子串比较的效率提高了,但是,算法整体的效率并没有提高。有没有方法可以提高哈希算法计算子串哈希值的效率呢?
这就需要哈希算法设计的非常有技巧了。我们假设要匹配的字符串的字符集中只包含 K 个字符,我们可以用一个 K 进制数来表示一个子串,这个 K 进制数转化成十进制数,作为子串的哈希值。表述起来有点抽象,我举了一个例子,看完你应该就能懂了。
比如要处理的字符串只包含 a~z 这 26 个小写字母,那我们就用二十六进制来表示一个字符串。我们把 a~z 这 26 个字符映射到 0~25 这 26 个数字,a 就表示 0,b 就表示 1,以此类推,z 表示 25。
在十进制的表示法中,一个数字的值是通过下面的方式计算出来的。对应到二十六进制,一个包含 a 到 z 这 26 个字符的字符串,计算哈希的时候,我们只需要把进位从 10 改成 26 就可以。
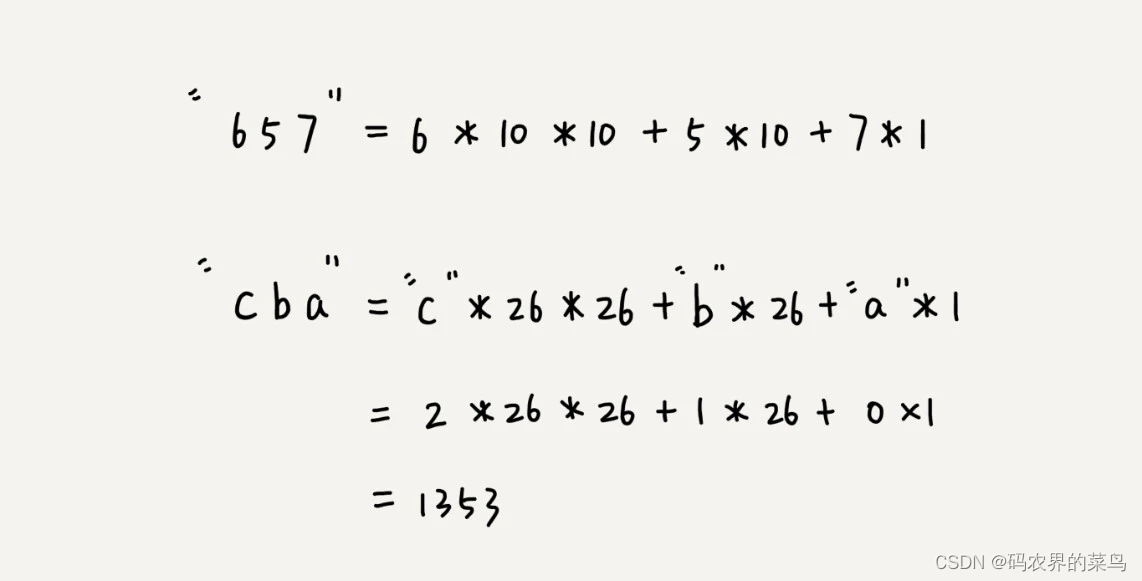
这个哈希算法你应该看懂了吧?现在,为了方便解释,在下面的讲解中,我假设字符串中只包含 a~z 这 26 个小写字符,我们用二十六进制来表示一个字符串,对应的哈希值就是二十六进制数转化成十进制的结果。
这种哈希算法有一个特点,在主串中,相邻两个子串的哈希值的计算公式有一定关系。我这有个例子,你先找一下规律,再来看我后面的讲解。
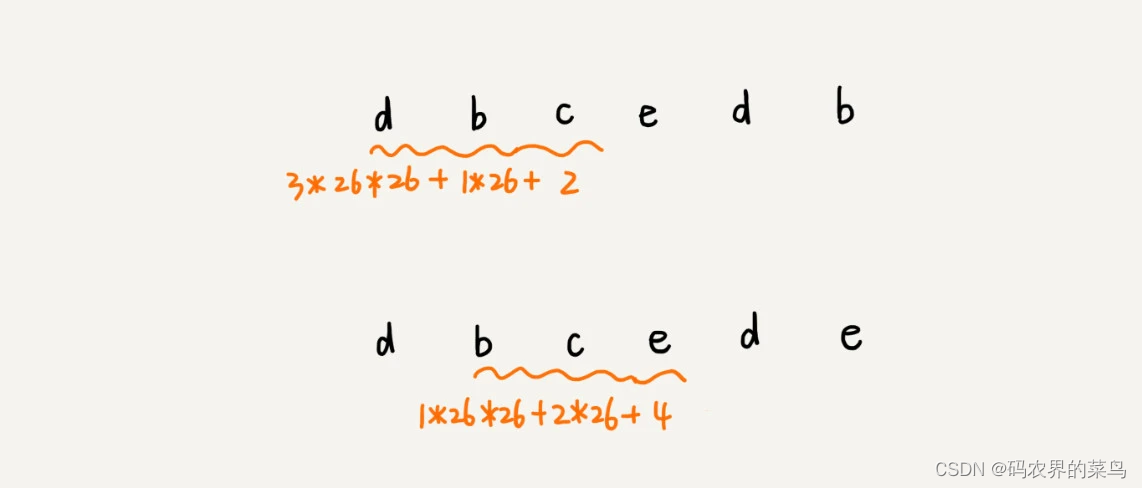
从这里例子中,我们很容易就能得出这样的规律:相邻两个子串 s[i-1]和 s[i](i 表示子串在主串中的起始位置,子串的长度都为 m),对应的哈希值计算公式有交集,也就是说,我们可以使用 s[i-1]的哈希值很快的计算出 s[i]的哈希值。如果用公式表示的话,就是下面这个样子:

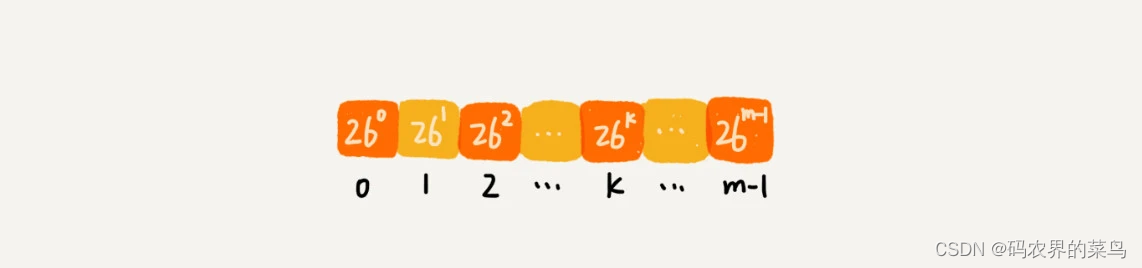
不过,这里有一个小细节需要注意,那就是 26(m-1) 这部分的计算,我们可以通过查表的方法来提高效率。我们事先计算好 260、261、262……26(m-1),并且存储在一个长度为 m 的数组中,公式中的“次方”就对应数组的下标。当我们需要计算 26 的 x 次方的时候,就可以从数组的下标为 x 的位置取值,直接使用,省去了计算的时间。
我们开头的时候提过,RK 算法的效率要比 BF 算法高,现在,我们就来分析一下,RK 算法的时间复杂度到底是多少呢?
整个 RK 算法包含两部分,计算子串哈希值和模式串哈希值与子串哈希值之间的比较。第一部分,我们前面也分析了,可以通过设计特殊的哈希算法,只需要扫描一遍主串就能计算出所有子串的哈希值了,所以这部分的时间复杂度是 O(n)。
模式串哈希值与每个子串哈希值之间的比较的时间复杂度是 O(1),总共需要比较 n-m+1 个子串的哈希值,所以,这部分的时间复杂度也是 O(n)。所以,RK 算法整体的时间复杂度就是 O(n)。
这里还有一个问题就是,模式串很长,相应的主串中的子串也会很长,通过上面的哈希算法计算得到的哈希值就可能很大,如果超过了计算机中整型数据可以表示的范围,那该如何解决呢?
刚刚我们设计的哈希算法是没有散列冲突的,也就是说,一个字符串与一个二十六进制数一一对应,不同的字符串的哈希值肯定不一样。因为我们是基于进制来表示一个字符串的,你可以类比成十进制、十六进制来思考一下。实际上,我们为了能将哈希值落在整型数据范围内,可以牺牲一下,允许哈希冲突。这个时候哈希算法该如何设计呢?
哈希算法的设计方法有很多,我举一个例子说明一下。假设字符串中只包含 a~z 这 26 个英文字母,那我们每个字母对应一个数字,比如 a 对应 1,b 对应 2,以此类推,z 对应 26。我们可以把字符串中每个字母对应的数字相加,最后得到的和作为哈希值。这种哈希算法产生的哈希值的数据范围就相对要小很多了。
不过,你也应该发现,这种哈希算法的哈希冲突概率也是挺高的。当然,我只是举了一个最简单的设计方法,还有很多更加优化的方法,比如将每一个字母从小到大对应一个素数,而不是 1,2,3……这样的自然数,这样冲突的概率就会降低一些。
那现在新的问题来了。之前我们只需要比较一下模式串和子串的哈希值,如果两个值相等,那这个子串就一定可以匹配模式串。但是,当存在哈希冲突的时候,有可能存在这样的情况,子串和模式串的哈希值虽然是相同的,但是两者本身并不匹配。
实际上,解决方法很简单。当我们发现一个子串的哈希值跟模式串的哈希值相等的时候,我们只需要再对比一下子串和模式串本身就好了。当然,如果子串的哈希值与模式串的哈希值不相等,那对应的子串和模式串肯定也是不匹配的,就不需要比对子串和模式串本身了
所以,哈希算法的冲突概率要相对控制得低一些,如果存在大量冲突,就会导致 RK 算法的时间复杂度退化,效率下降。极端情况下,如果存在大量的冲突,每次都要再对比子串和模式串本身,那时间复杂度就会退化成 O(n*m)。但也不要太悲观,一般情况下,冲突不会很多,RK 算法的效率还是比 BF 算法高的。
BM算法
我们把模式串和主串的匹配过程,看作模式串在主串中不停地往后滑动。当遇到不匹配的字符时,BF 算法和 RK 算法的做法是,模式串往后滑动一位,然后从模式串的第一个字符开始重新匹配。我举个例子解释一下,你可以看我画的这幅图。
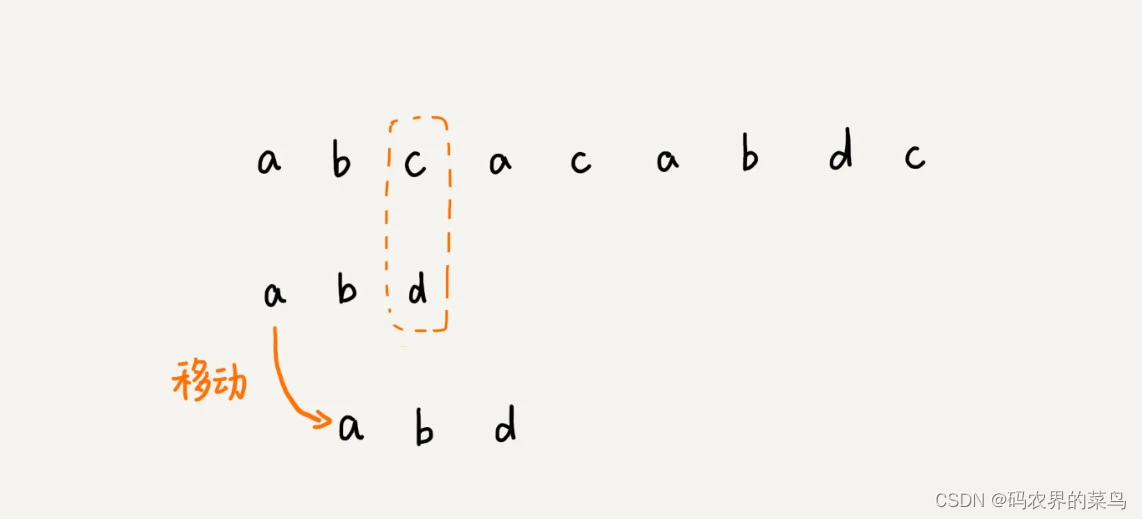
在这个例子里,主串中的 c,在模式串中是不存在的,所以,模式串向后滑动的时候,只要 c 与模式串没有重合,肯定无法匹配。所以,我们可以一次性把模式串往后多滑动几位,把模式串移动到 c 的后面。
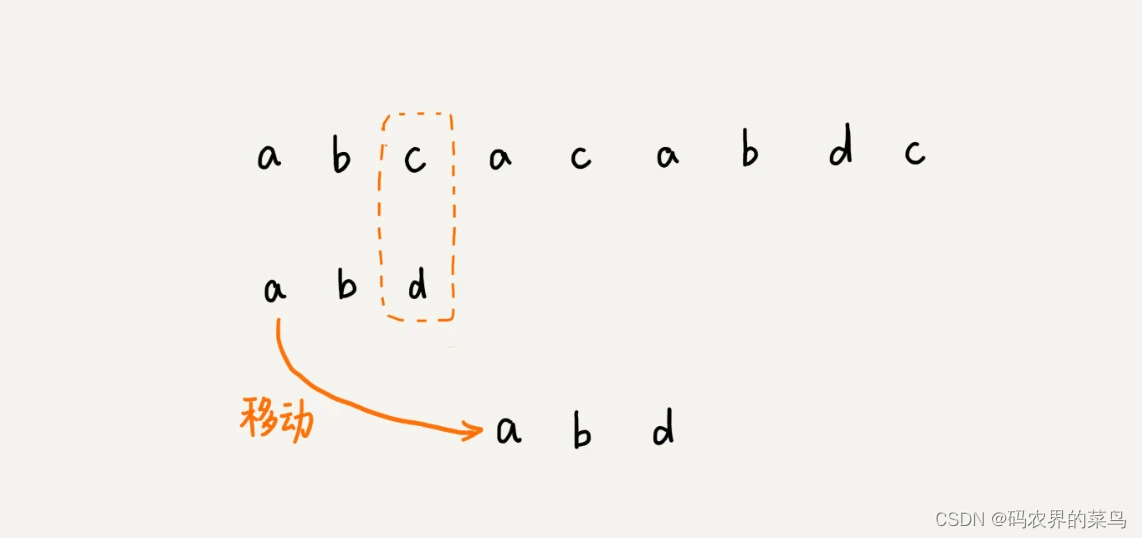
BM 算法包含两部分,分别是坏字符规则(bad character rule)和好后缀规则(good suffix shift)。我们下面依次来看,这两个规则分别都是怎么工作的。
1. 坏字符规则
前面两节讲的算法,在匹配的过程中,我们都是按模式串的下标从小到大的顺序,依次与主串中的字符进行匹配的。这种匹配顺序比较符合我们的思维习惯,而 BM 算法的匹配顺序比较特别,它是按照模式串下标从大到小的顺序,倒着匹配的。我画了一张图,你可以看下。
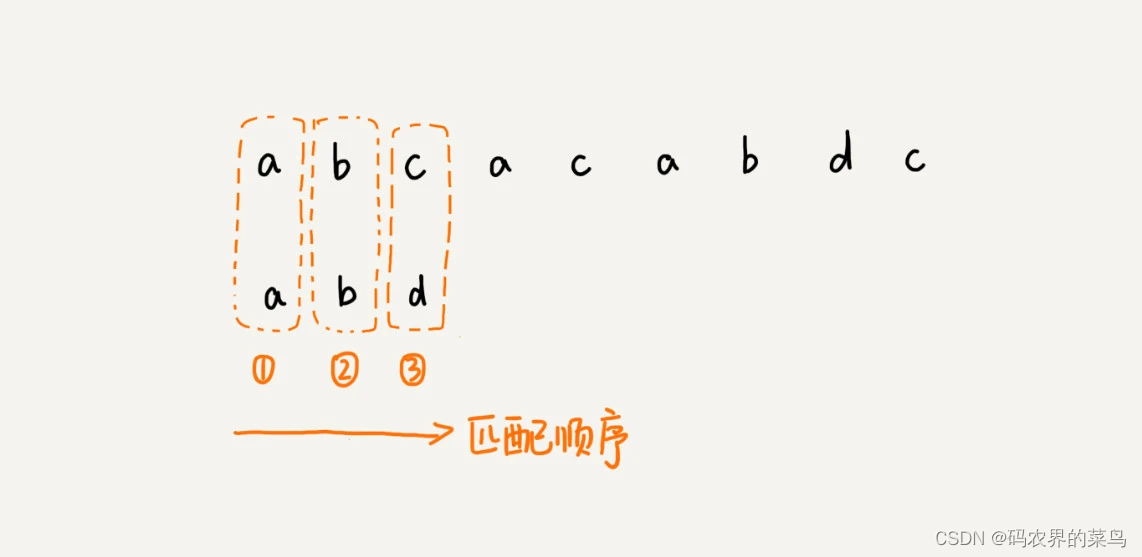
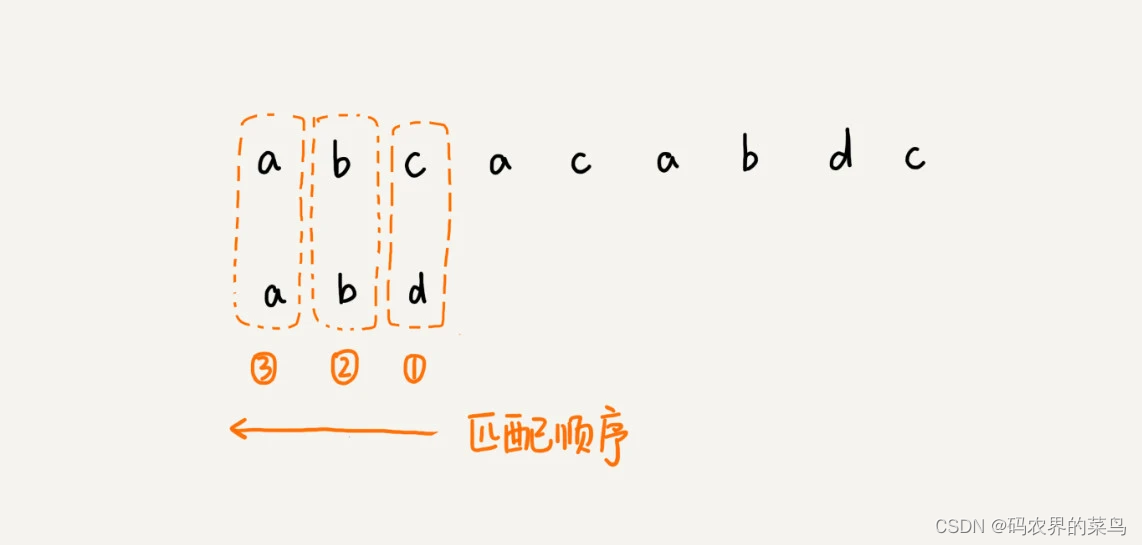
从模式串的末尾往前倒着匹配,当发现某个字符没法匹配的时候,我们把这个没有匹配的字符叫作坏字符(主串中的字符)。
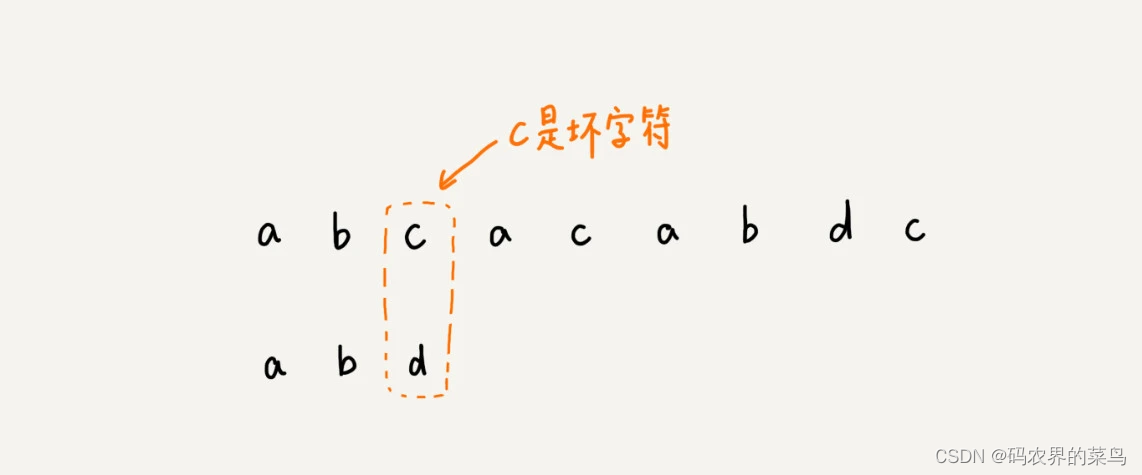
我们拿坏字符 c 在模式串中查找,发现模式串中并不存在这个字符,也就是说,字符 c 与模式串中的任何字符都不可能匹配。这个时候,我们可以将模式串直接往后滑动三位,将模式串滑动到 c 后面的位置,再从模式串的末尾字符开始比较。
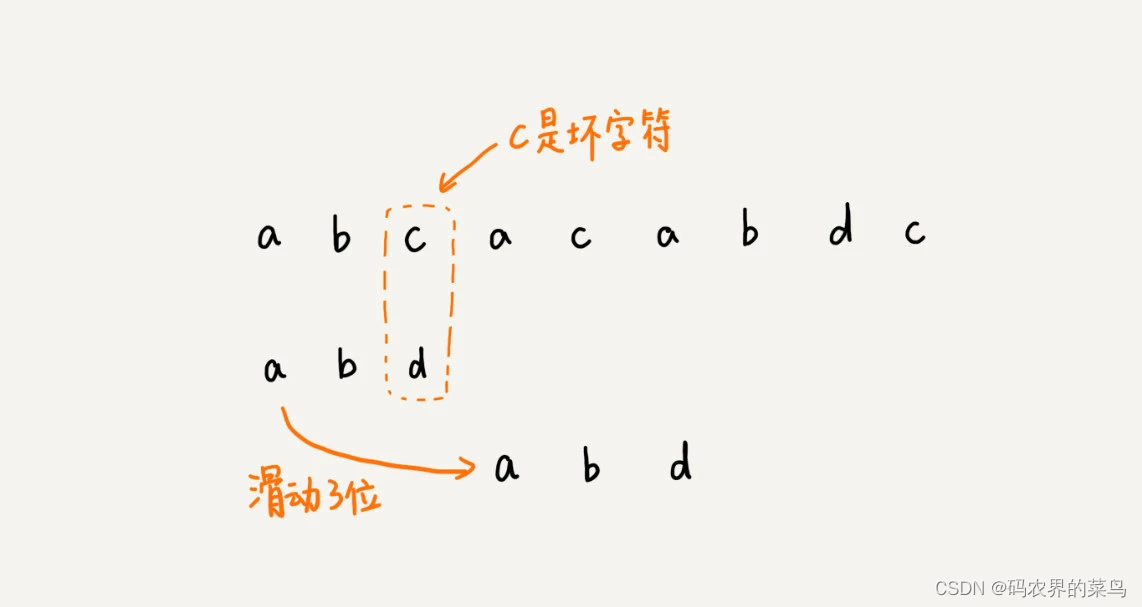
这个时候,我们发现,模式串中最后一个字符 d,还是无法跟主串中的 a 匹配,这个时候,还能将模式串往后滑动三位吗?答案是不行的。因为这个时候,坏字符 a 在模式串中是存在的,模式串中下标是 0 的位置也是字符 a。这种情况下,我们可以将模式串往后滑动两位,让两个 a 上下对齐,然后再从模式串的末尾字符开始,重新匹配。
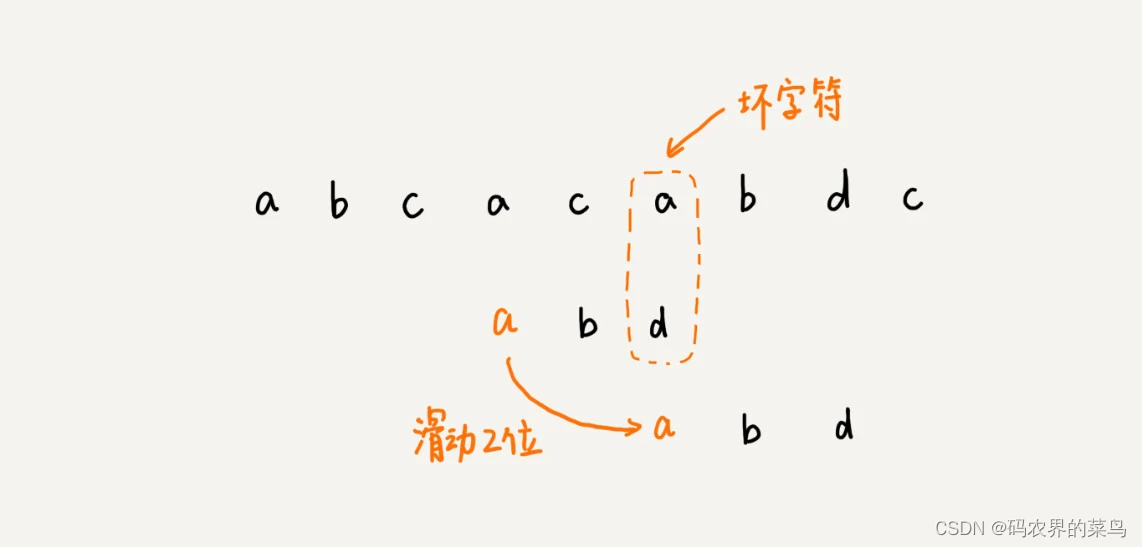
第一次不匹配的时候,我们滑动了三位,第二次不匹配的时候,我们将模式串后移两位,那具体滑动多少位,到底有没有规律呢?
当发生不匹配的时候,我们把坏字符对应的模式串中的字符下标记作 si。如果坏字符在模式串中存在,我们把这个坏字符在模式串中的下标记作 xi。如果不存在,我们把 xi 记作 -1。那模式串往后移动的位数就等于 si-xi。(注意,我这里说的下标,都是字符在模式串的下标)
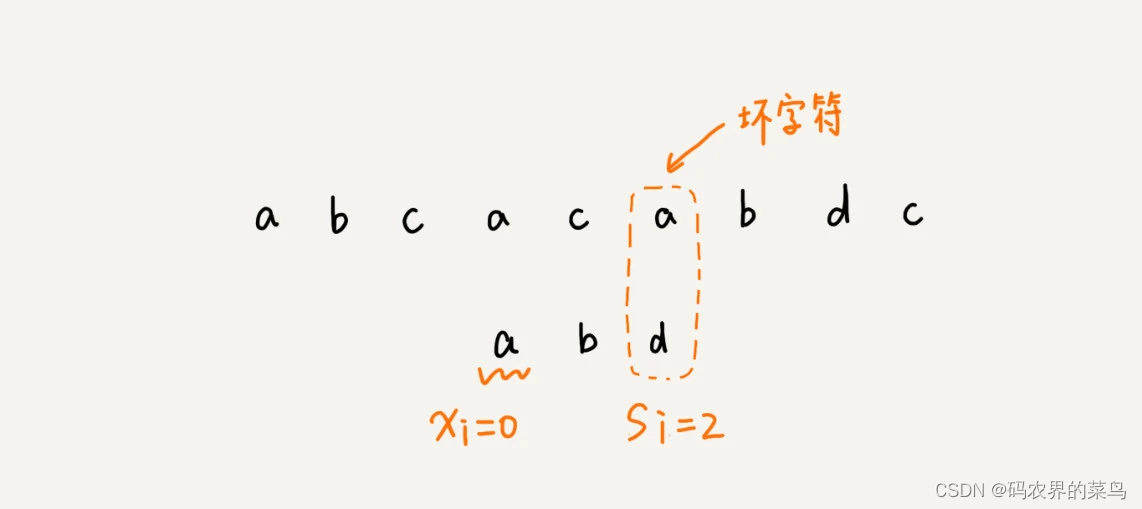
这里我要特别说明一点,如果坏字符在模式串里多处出现,那我们在计算 xi 的时候,选择最靠后的那个,因为这样不会让模式串滑动过多,导致本来可能匹配的情况被滑动略过。
利用坏字符规则,BM 算法在最好情况下的时间复杂度非常低,是 O(n/m)。比如,主串是 aaabaaabaaabaaab,模式串是 aaaa。每次比对,模式串都可以直接后移四位,所以,匹配具有类似特点的模式串和主串的时候,BM 算法非常高效。
不过,单纯使用坏字符规则还是不够的。因为根据 si-xi 计算出来的移动位数,有可能是负数,比如主串是 aaaaaaaaaaaaaaaa,模式串是 baaa。不但不会向后滑动模式串,还有可能倒退。所以,BM 算法还需要用到“好后缀规则”。
2. 好后缀规则
好后缀规则实际上跟坏字符规则的思路很类似。你看我下面这幅图。当模式串滑动到图中的位置的时候,模式串和主串有 2 个字符是匹配的,倒数第 3 个字符发生了不匹配的情况。
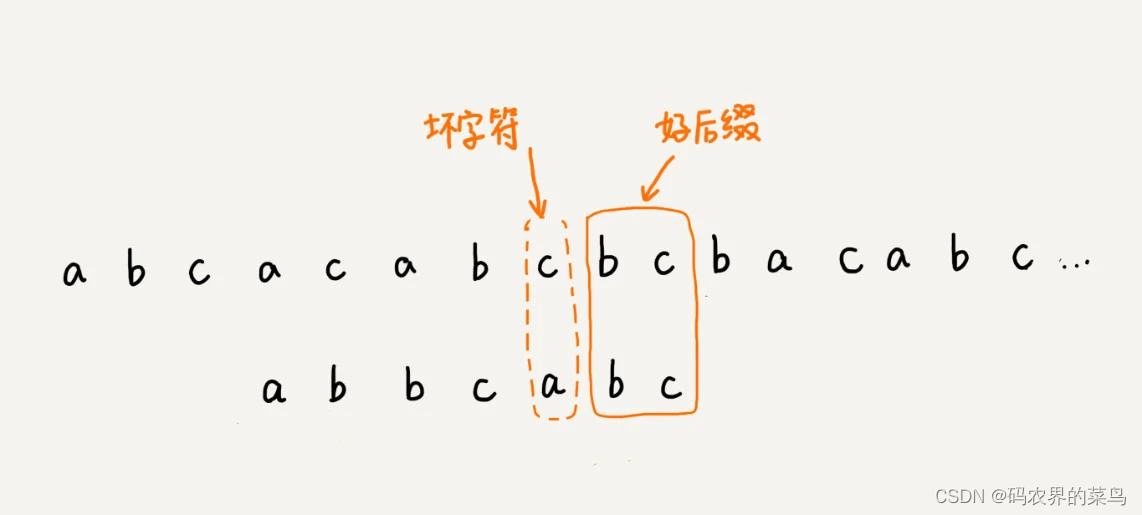
这个时候该如何滑动模式串呢?当然,我们还可以利用坏字符规则来计算模式串的滑动位数,不过,我们也可以使用好后缀处理规则。两种规则到底如何选择,我稍后会讲。抛开这个问题,现在我们来看,好后缀规则是怎么工作的?
我们把已经匹配的 bc 叫作好后缀,记作{u}。我们拿它在模式串中查找,如果找到了另一个跟{u}相匹配的子串{u*},那我们就将模式串滑动到子串{u*}与主串中{u}对齐的位置。
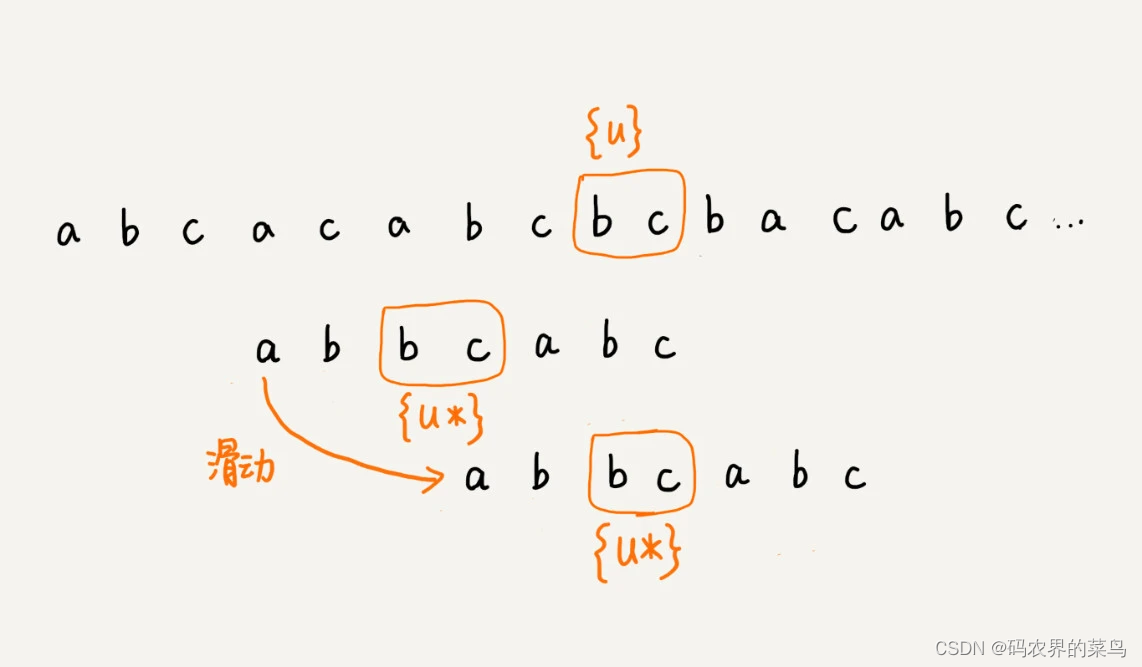
如果在模式串中找不到另一个等于{u}的子串,我们就直接将模式串,滑动到主串中{u}的后面,因为之前的任何一次往后滑动,都没有匹配主串中{u}的情况。
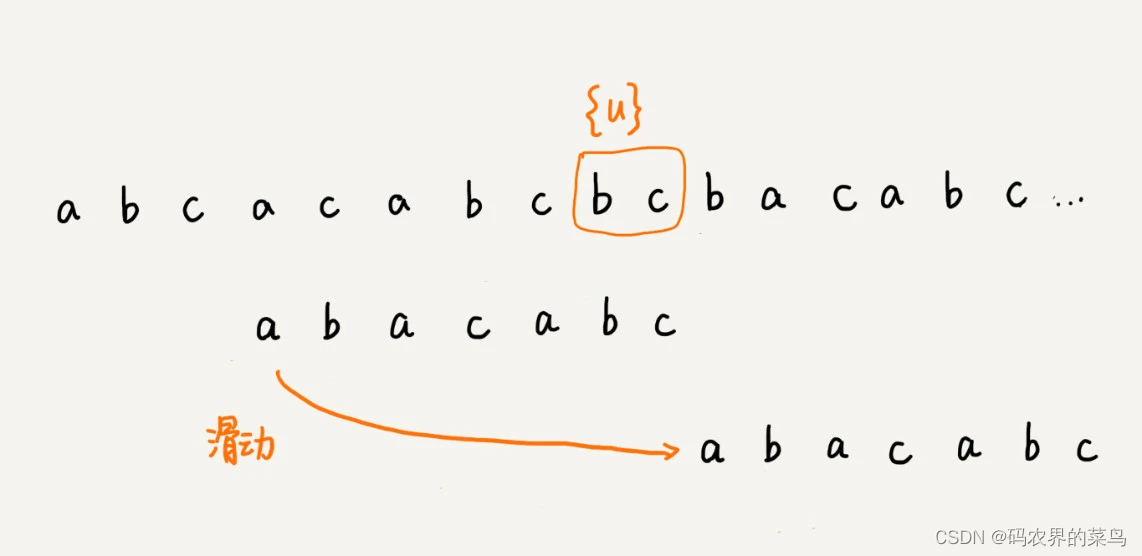
不过,当模式串中不存在等于{u}的子串时,我们直接将模式串滑动到主串{u}的后面。这样做是否有点太过头呢?我们来看下面这个例子。这里面 bc 是好后缀,尽管在模式串中没有另外一个相匹配的子串{u*},但是如果我们将模式串移动到好后缀的后面,如图所示,那就会错过模式串和主串可以匹配的情况。
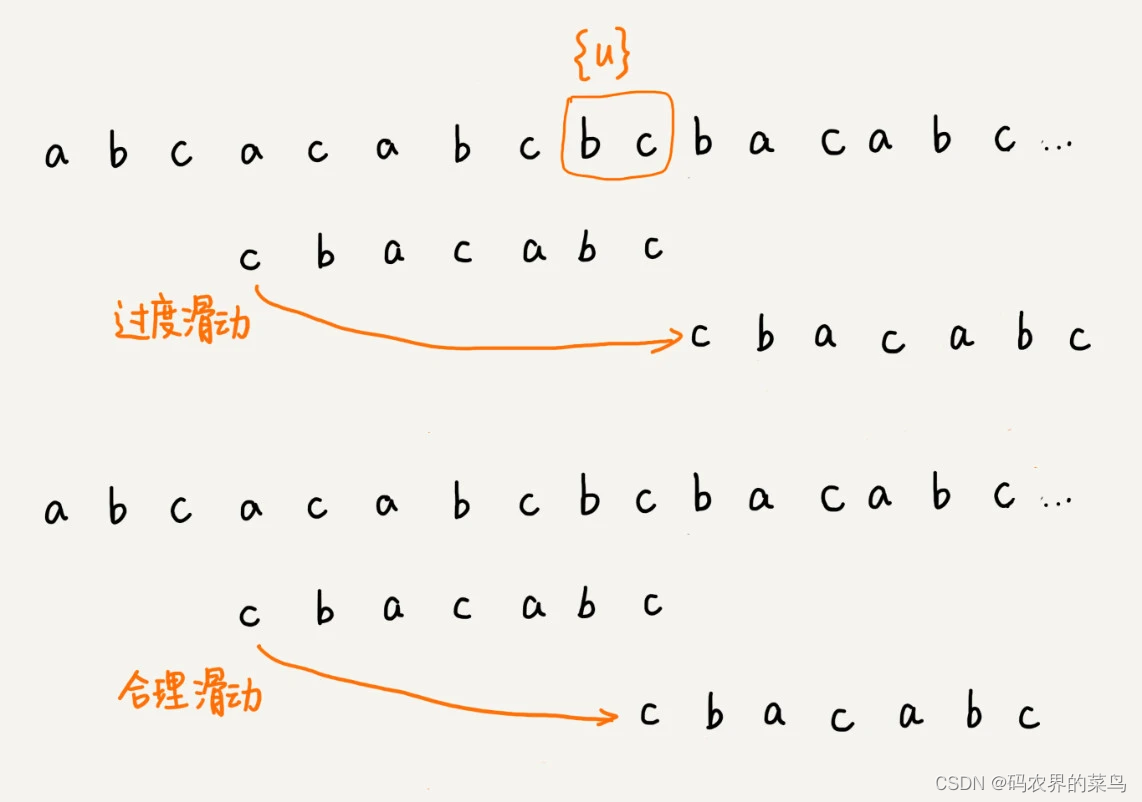
如果好后缀在模式串中不存在可匹配的子串,那在我们一步一步往后滑动模式串的过程中,只要主串中的{u}与模式串有重合,那肯定就无法完全匹配。但是当模式串滑动到前缀与主串中{u}的后缀有部分重合的时候,并且重合的部分相等的时候,就有可能会存在完全匹配的情况。
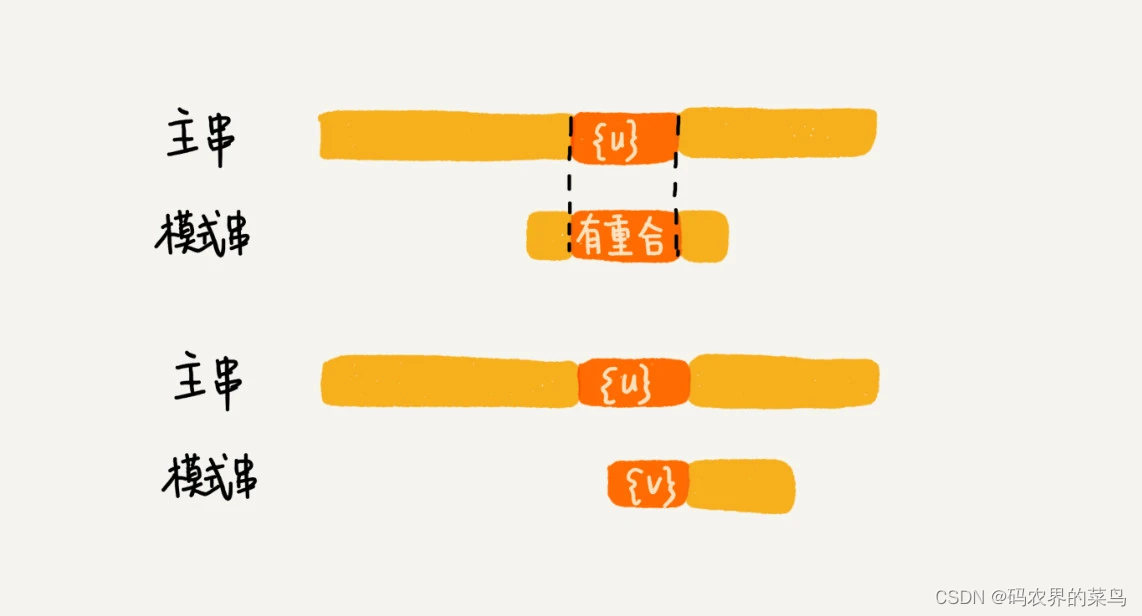
所以,针对这种情况,我们不仅要看好后缀在模式串中,是否有另一个匹配的子串,我们还要考察好后缀的后缀子串,是否存在跟模式串的前缀子串匹配的。
所谓某个字符串 s 的后缀子串,就是最后一个字符跟 s 对齐的子串,比如 abc 的后缀子串就包括 c, bc。所谓前缀子串,就是起始字符跟 s 对齐的子串,比如 abc 的前缀子串有 a,ab。我们从好后缀的后缀子串中,找一个最长的并且能跟模式串的前缀子串匹配的,假设是{v},然后将模式串滑动到如图所示的位置。
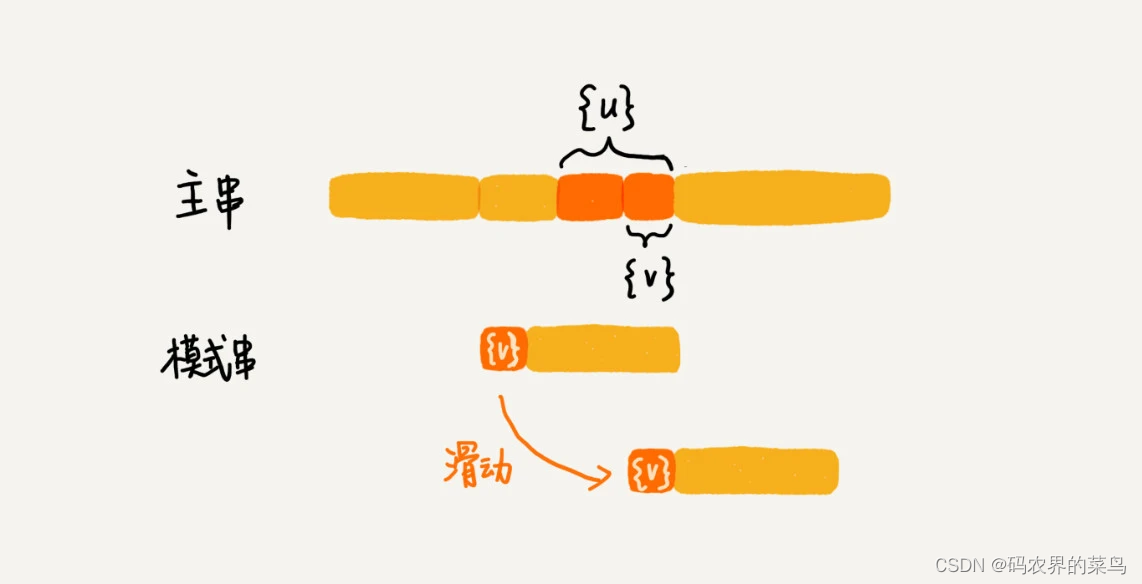
坏字符和好后缀的基本原理都讲完了,我现在回答一下前面那个问题。当模式串和主串中的某个字符不匹配的时候,如何选择用好后缀规则还是坏字符规则,来计算模式串往后滑动的位数?
我们可以分别计算好后缀和坏字符往后滑动的位数,然后取两个数中最大的,作为模式串往后滑动的位数。这种处理方法还可以避免我们前面提到的,根据坏字符规则,计算得到的往后滑动的位数,有可能是负数的情况。
















 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









