







文章目录
三、分片算法配置
3.1 数据分片
理解数据分片有助于后续分片算法的配置和设计出适配分库分表的SQL语句和业务逻辑。推荐阅读原文
- https://shardingsphere.apache.org/document/5.2.1/cn/features/sharding/
这里摘要一些精华片段
传统的将数据集中存储至单一节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足海量数据的场景。
…
从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。 数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
…
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
3.1.2 垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 ……下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
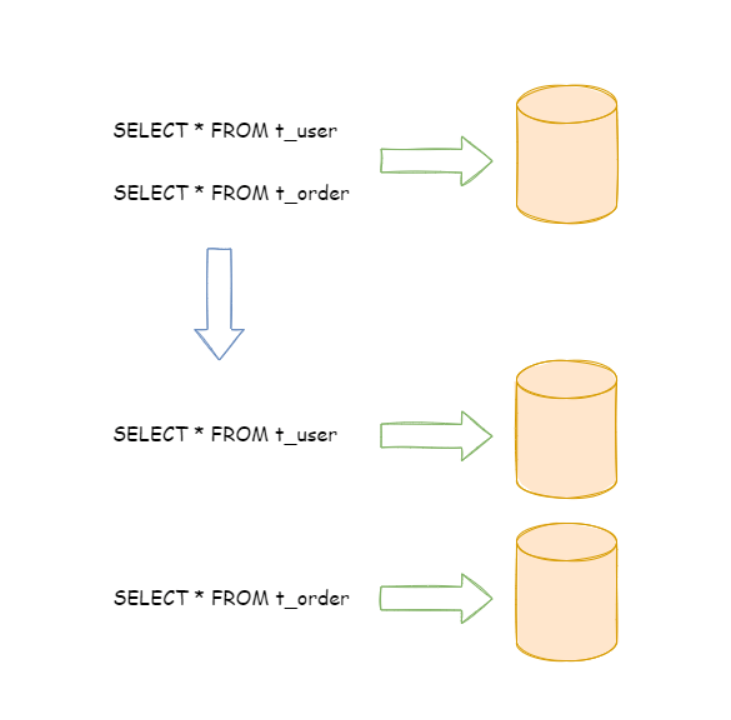
优点:垂直分片在不借助专业的分片设计组件实现根据业务拆分数据库
缺点:垂直分片往往需要对架构和设计进行调整;通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。
技术选型:借助多数据源组件和业务逻辑的修改即可实现,比较常见的微服务架构在考虑模块区分时一般也会将数据库按模块进行划分,这就是一种常见的垂直分片设计。
3.1.2 水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。
例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
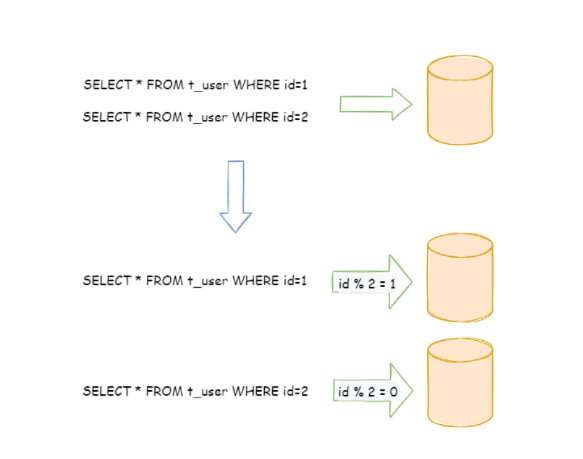
优点:水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是数据分片的标准解决方案。
缺点&挑战:
-
面对如此散乱的分片之后的数据,应用开发工程师和数据库管理员对数据库的操作变得异常繁重就是其中的重要挑战之一。 他们需要知道数据需要从哪个具体的数据库的子表中获取。
-
另一个挑战则是,能够正确的运行在单节点数据库中的 SQL,在分片之后的数据库中并不一定能够正确运行。 例如,分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理。
-
跨库事务也是分布式的数据库集群要面对的棘手事情。…… 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务……不能避免跨库事务的场景,有些业务仍然需要保持事务的一致……互联网巨头大多采用最终一致性的柔性事务代替强一致事务。
ShardingSphere的设计目的:
尽量透明化分库分表所带来的影响,让使用方尽量像使用一个数据库一样使用水平分片之后的数据库集群,是 Apache ShardingSphere 数据分片模块的主要设计目标。
3.2 (标准)分片算法
官方提供了很多算法,具体可以看官方文档,在实际开发场景中可以根据业务实际情况来选择分片算法;这里主要介绍一下常用的几类标准分片算法。
3.2.1 INLINE 基于行表达式的分片算法 (必须掌握)
使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持,只支持单分片键。 对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的 Java 代码开发,如: t_user_$->{u_id % 8} 表示 t_user 表根据 u_id 模 8,而分成 8 张表,表名称为 t_user_0 到 t_user_7。
可用的配置参数如下:
| 属性名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
| algorithm-expression | String | 分片算法的行表达式 | |
| allow-range-query-with-inline-sharding (?) | boolean | 是否允许范围查询。注意:范围查询会无视分片策略,进行全路由 | false |
举例:想上面快速开始中的配置
#...
# 配置分片算法
sharding-algorithms:
# 分库策略:根据age取余2
student_age_inline:
type: INLINE
props:
algorithm-expression: ds$->{age % 2}
# 分表策略:根据classid取余2
student_class_id_inline:
type: INLINE
props:
algorithm-expression: student$->{class_id % 2}
关于是否开启范围查找
-
允许范围查询:当设置为
true时,这个配置项允许使用行表达式分片算法的表进行范围查询。范围查询是指查询条件中包含大于(>)、小于(<)、大于等于(>=)、小于等于(<=)等操作符的查询。 -
限制:默认情况下,行表达式分片算法不支持范围查询,因为范围查询可能涉及多个分片,而简单的行表达式分片算法通常只能将查询路由到单个分片。如果设置为
false(默认值),则范围查询会被限制,只能针对单个分片进行,这可能会导致查询结果不完整或者查询失败。
举个例子,比如分片键为字段age,要执行SQL语句
SELECT id,name,age,class_id FROM student WHERE (age BETWEEN ? AND ?)
如果不开启该项,运行相关的sql则会报错

修改配置后则会看到正确的运行了范围查询语句
Actual SQL: ds0 ::: SELECT id,name,age,class_id FROM student0 WHERE (age BETWEEN ? AND ?) UNION ALL SELECT id,name,age,class_id FROM student1 WHERE (age BETWEEN ? AND ?) ::: [20, 30, 20, 30]
Actual SQL: ds1 ::: SELECT id,name,age,class_id FROM student0 WHERE (age BETWEEN ? AND ?) UNION ALL SELECT id,name,age,class_id FROM student1 WHERE (age BETWEEN ? AND ?) ::: [20, 30, 20, 30]
3.2.2 INTERVAL 时间范围分片算法
源码位置:org.apache.shardingsphere.sharding.algorithm.sharding.datetime.IntervalShardingAlgorithm
| 属性名称 | 数据类型 | 说明 | 默认值 |
|---|---|---|---|
| datetime-pattern | String | 分片键的时间戳格式,必须遵循 Java DateTimeFormatter 的格式。例如:yyyy-MM-dd HH:mm:ss,yyyy-MM-dd 或 HH:mm:ss 等。但不支持与 java.time.chrono.JapaneseDate 相关的 Gy-MM 等 | |
| datetime-lower | String | 时间分片下界值,格式与 datetime-pattern 定义的时间戳格式一致 | |
| datetime-upper (?) | String | 时间分片上界值,格式与 datetime-pattern 定义的时间戳格式一致 | 当前时间 |
| sharding-suffix-pattern | String | 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM | |
| datetime-interval-amount (?) | int | 分片键时间间隔,超过该时间间隔将进入下一分片 | 1 |
| datetime-interval-unit (?) | String | 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS | DAYS |
官方对于该算法的描述是在让人看不懂,我尝试通过一个测试可行的例子 帮助理解;
创建表结构如下,在同一个数据源中创建若干个表结构一样的打卡表
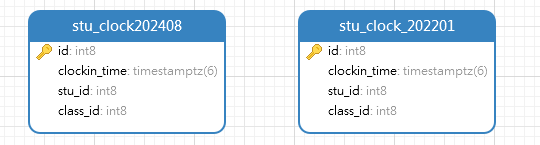
实现目标:使用时间间隔分片算法,根据打卡时间进行分库(分表)
yaml配置文件
rules:
sharding:
tables:
# ...
stu_clock:
actual-data-nodes: dsmain.stu_clock${202301..202501}
key-generate-strategy:
column: id
key-generator-name: snowflake
table-strategy:
standard:
sharding-column: clockin_time
sharding-algorithm-name: student_clock_interval
# 配置分片算法
sharding-algorithms:
# 声明一个时间间隔算法
student_clock_interval:
type: INTERVAL
props:
# 时间分片下界值,格式与 datetime-pattern 定义的时间戳格式一致
datetime-pattern: 'yyyy-MM-dd HH:mm:ss'
datetime-lower: '2023-01-01 00:00:00'
# 时间分片上界值,格式与 datetime-pattern 定义的时间戳格式一致 默认当前时间
datetime-upper: '2025-01-01 00:00:00'
# 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM
sharding-suffix-pattern: 'yyyyMM'
# 分片键时间间隔,超过该时间间隔将进入下一分片
datetime-interval-amount: 1
# 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS
datetime-interval-unit: 'MONTHS'
配置解释
INTERVAL算法的核心是让数据根据分片键按一定间隔规律进行分库分表,比如在上述配置中,
-
我们声明了一个
stu_clock表根据分片键【打卡时间】clockin_time进行【分表】配置; -
分片规则是按月份作为分片键间隔单位
datetime-interval-unit: 'MONTHS' -
并且声明了间隔单位为1,即每隔一个月就进入下一个分片
datetime-interval-amount: 1声明了间隔和单位后,我们已经可以推测出一定的分片规则,但是仍然有几个问题需要解决->
- 如何体现当前分片
- 解决“由于起终时间不同,间隔相同时,分片不确定的”问题
-
所以进一步需要 :声明时间分片上下界值和分片数据源或真实表的后缀格式
进行测试:
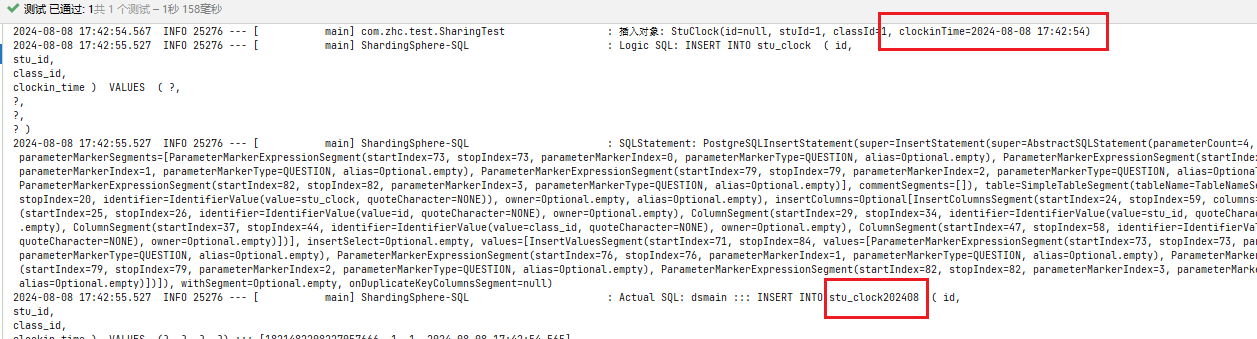
插入打卡时间为2024-08-08 17:42:54数据,SS根据分片算法识别到stu_clock202408 并成功插入数据
















 1926
1926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











