






PHP文章采集器,以PHP编程语言为基础,专为自动从互联网收集各种文章而设计的应用软件。它通过设置关键词、网站链接或是其他特定条件,实现快捷、精准地收集到所需的信息,进而整理成有条理的格式,以便后期的处理与分析。在当前信息量大幅增长的环境下,PHP文章采集器为广大用户提供了一个高效获取信息的有效手段,大大降低了人力物力的消耗。
在当今互联网时代,信息的重要性日益凸显。企业需及时掌握市场趋势,个人也需高效获取所需信息。此时,PHP文章采集器的出现,有效满足此类需求,为其提供便捷途径。
PHP文章采集器的工作原理
PHP文章采集器是利用模拟浏览器访问网页,分析页面内容并提取相关信息的方法来完成文章内容的收集。首先,根据用户预设的策略生成HTTP请求,获取所需网页的HTML源文件;然后,运用正则表达式,XPath或DOM技术对HTML文档进行解构,抽出用户关注的部分;最后,将整理后的数据进行保存,以便后续使用。
需关注的重点在于,在使用PHP文章采集器进行操作时,必须考虑到反爬虫机制和页面结构变动等多重因素。为确保高效执行数据采撷任务,开发者需持续改进代码逻辑,避开反爬虫策略,同时密切跟踪及适应目标网站的变更。

应用领域与价值
PHP文章采集器具有多领域的应用价值,如电商行业可运用其捕捉竞品价格与用户评价,以辅助制定营销策略;新闻传媒领域则可借助其完成新闻摘要自动生成及舆情监控任务;而在学术研究领域,PHP文章采集器有助于学者快速收集相关文献和研究成果等信息。
PHP文章采集器在SEO优化、内容整合以及数据分析领域拥有广泛用途,借助其功能,使用者能以更高效的方式完成信息收集与处理,在日趋竞争激烈的市场形势中抢占先机。
如何选择合适的PHP文章采集器
为用户选取适宜的PHP文章采集器时,应着重考虑其性能与操作简易度。强大的功能可适应多种复杂情况,而简便的操作可以降低学习成本;其次,注意其可靠性及拓展能力。稳定的运作能确保长久无损的使用体验,而良好的拓展性则方便进行进阶开发与量身定制。
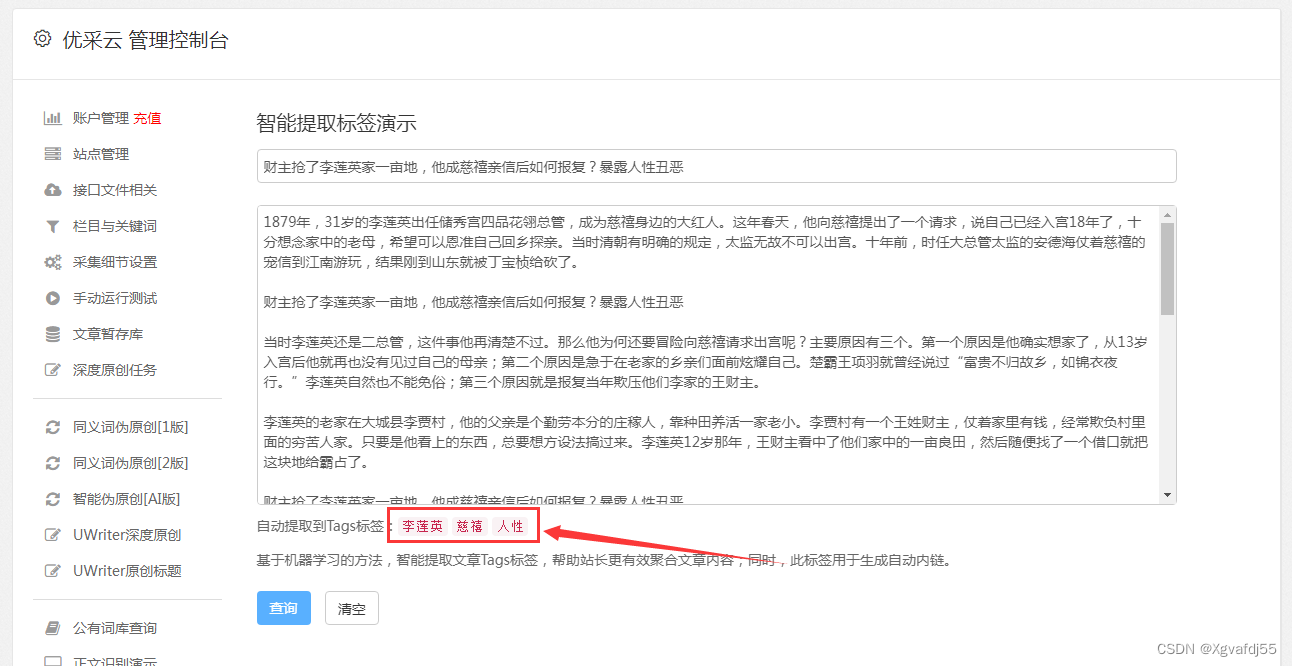
在选取PHP文章采集器时,应注重其能否实现多格式数据导出、拥有高效的反爬虫功能以及优良的技术服务和社区环境等要素。充分斟酌后再行决定,方能以最优方式运用该采集器。
常见问题与解决方法
在利用PHP文章采集工具进行任务时,可能会遭遇如网页架构变动导致数据抽取失败,以及反爬虫技术阻挠数据获取等挑战。对此,可尝试如下策略以应对:
网页布局监测与规则更新:仔细核查目标站点的页面布局变动,并适时调整相关规则。
防范爬虫技术措施:通过设定适当的访问频率,利用代理IP资源库以及仿真人工操作等手段以规避反爬虫系统。
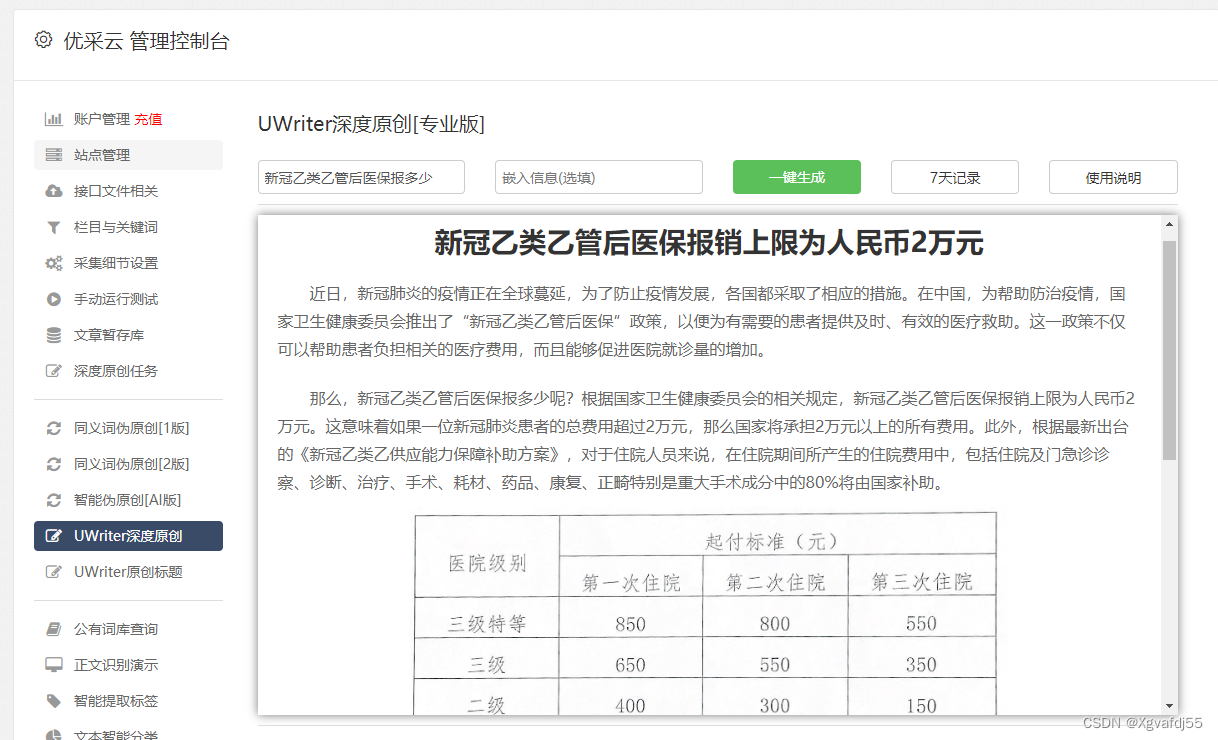
数据净化:对捕获数据进行去重复化和去除噪音操作,以保证数据质量的优良性。
经验累积与技术优化相互结合,方能有效应对各项挑战,充分发挥PHP文章采集器的真正价值。
未来发展趋势展望
随着互联网信息膨胀与智能科技发展,PHP文章采集器必将开创更为广阔前景。预计未来AI技术及大数据分析的深入推进,将使PHP文章采集器走向智能化、定制化,能应对各类复杂应用环境与用户需求。
在日益重视隐私的大环境下,未来的PHP文章采集器需要更加关注用户数据安全及隐私保护的问题。唯有持续创新,紧跟时代步伐,方能为满足用户需求提供更优质的服务,进而推动整个行业的繁荣进步。















 791
791











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









