







 本文探讨了如何利用知识图谱在NLP任务中增强模型理解力,特别是在推荐系统和文本匹配中的应用。RippleNet通过知识图谱进行用户偏好推理,提高推荐准确性;Entity-Duet模型利用知识库增强文本匹配的语义理解;ERNIE则在预训练阶段融入知识,提升下游任务效果。引入知识图谱的实体信息和结构,有望进一步提升模型性能。
本文探讨了如何利用知识图谱在NLP任务中增强模型理解力,特别是在推荐系统和文本匹配中的应用。RippleNet通过知识图谱进行用户偏好推理,提高推荐准确性;Entity-Duet模型利用知识库增强文本匹配的语义理解;ERNIE则在预训练阶段融入知识,提升下游任务效果。引入知识图谱的实体信息和结构,有望进一步提升模型性能。
前言
NLP任务中,常见的做法是根据当前输入进行建模,进而设计出我们的模型,通常用到的信息只有当前局部的信息。这和人类最大的区别就是我们在理解语言的时候,我们会用到我们之前学习到的知识,比如说到“自然语言处理”,我们就可以联想到“文本匹配”、“阅读理解”、“BERT”等等,而我们会利用这些外部知识来加强自己的理解,如果没有用额外的知识,比如接触到我们一个不熟悉的领域,我们也很难完全理解语义。而目前NLP常见做法只利用了输入信息,没用利用外部知识,理解层次偏低,举个例子,文本匹配任务中:
| Query | Title |
|---|---|
| 新冠肺炎可以通过完好的皮肤传播吗 | 新型肺炎会通过皮肤传播吗 |
| IPhone手机多少钱 | IPhone手机壳多少钱 |
一般的文本匹配模型很容易误判上面Query-title为匹配,因为上述Query-title文本字面组成非常相似,比如新冠肺炎和新型肺炎,IPhone手机和IPhone手机壳的embedding可能非常相似,导致模型计算出来的相似度很高,其中一个原因就是因为模型没有先验知识,并不知道IPhone手机和IPhone手机壳是两个不同的东西,如果能在模型中引入外部知识,让模型提前了解IPhone手机和IPhone手机壳的概念,那么就提高的模型的理解层次,也能提高任务效果。
现在知识图谱,图卷积神经网络也是非常热门,知识图谱作为一个常用的外部知识库,有很多工作都在研究如何将其引入各种NLP任务进行知识增强,最近也是看了几篇论文,在这里做一下总结。
当推荐系统遇上知识图谱
(RippleNet) Wang, H., Zhang, F., Wang, J., Zhao, M., Li, W., Xie, X., & Guo, M. (2018). RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems. Proceedings of the 27th ACM International Conference on Information and Knowledge Management…[PDF]
这篇论文在推荐系统的排序任务上引入了知识图谱的信息进行任务增强,主要是从下面三个方面考虑:
- 知识图谱可以引入各个Item之间的语义相关性,有助于找到潜在的联系,从而提高推荐的准确性
- 知识图谱还可以通过类型关系,来合理扩展用户的兴趣,增加推荐项目的多样性
- 知识图谱还可以连接用户的历史记录和推荐记录,从而解决推荐系统冷启动问题,并且可解释性好
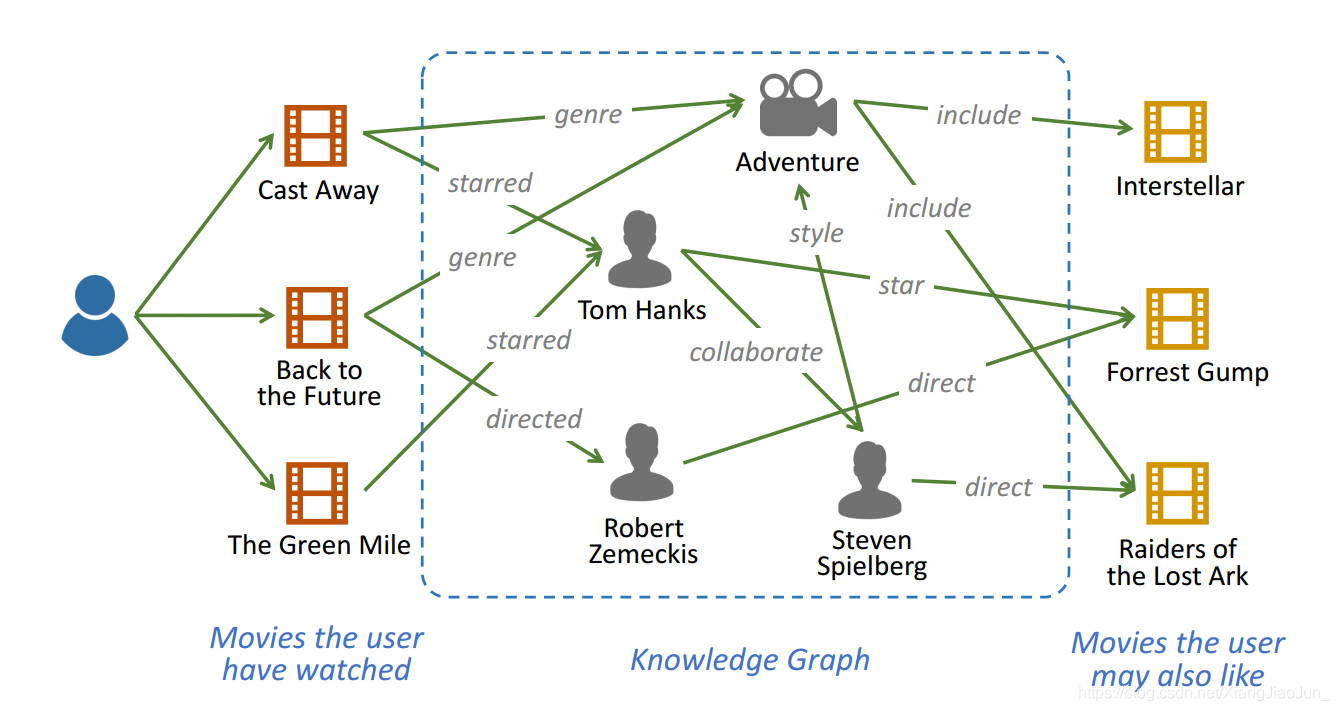
从上面可以看出,通过知识图谱我们可以推理出用户看过电影的导演、或者类型,并且可以进一步得到同导演或者同类型的电影,从而对用户进行推荐。
模型结构
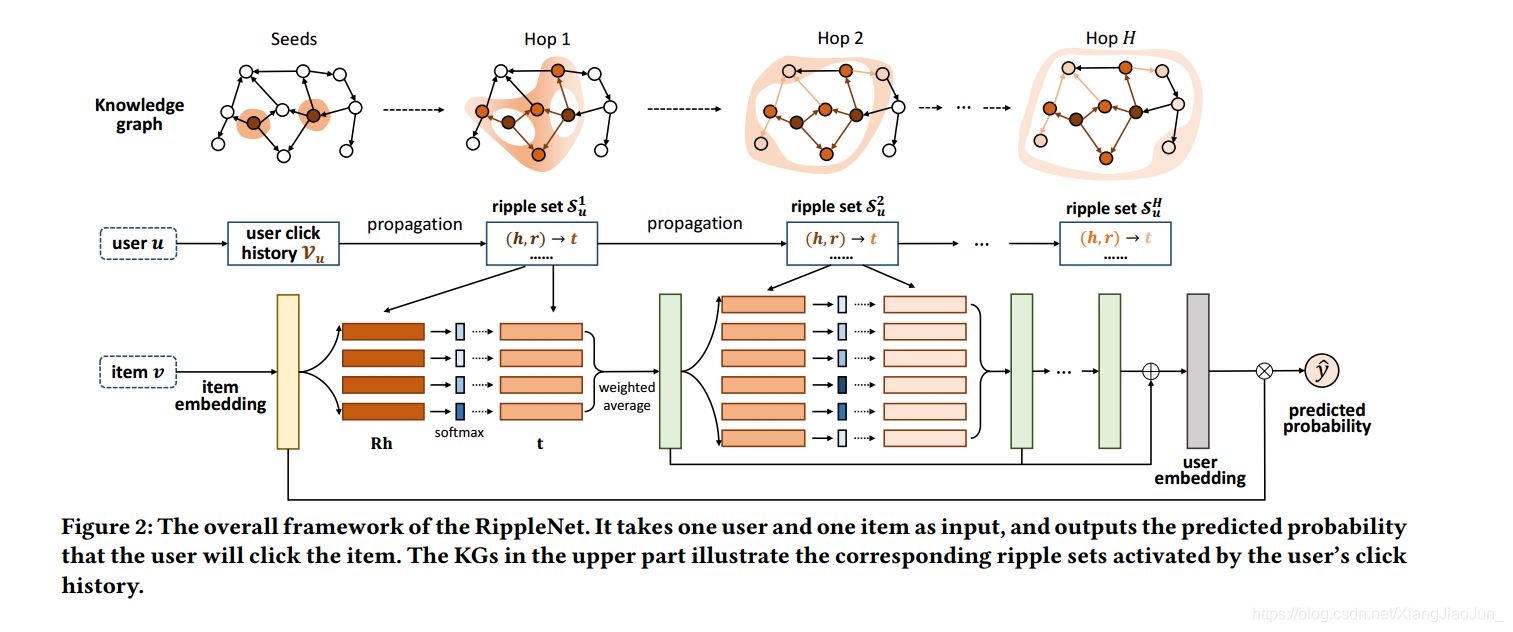
论文中提出的RippleNet结构如上图所示,之所以叫Ripple是因为信息在知识图谱上的传播就像雨滴落在水面形成的Ripple,每次都会往外传播一层,并且越外部的信息作用越小。整个模型输入为用户 u \bold u u和物品 v \bold v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









