







9点49,老婆孩子都睡着了, 继续搞。
第1篇写了访问百度并打印页面源码,似乎没什么实际意义,这次弄个有点用的,就是百度中输入指定关键词后搜索,然后获取搜索结果第一页(翻页后面会陆续写)。
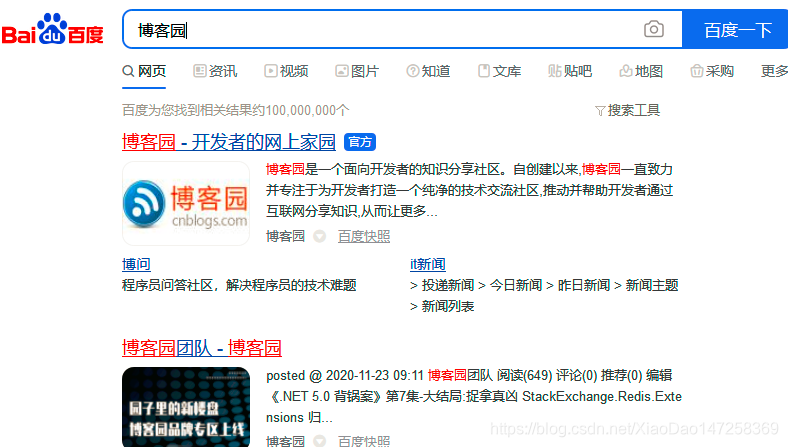
比如我们输入‘博客园’,下面是查询结果(为啥写博客园不写CSDN呢,因为最早是博客是在博客园里写的,现在自己转发到CSDN,不改了):
这个时候我们看下浏览器中url地址 ,大概是这个样子的

好老长,我们去除掉一些看不懂的部分,只保留ie 和wd 这2个参数试下能否正常访问
可以的访问,现在我们把这个url复制到 代码中看下
https://www.baidu.com/s?ie=utf-8&wd=%E5%8D%9A%E5%AE%A2%E5%9B%AD
发现变化了没,wd=博客园 变成了 wd= %E5%8D%9A%E5%AE%A2%E5%9B%AD,这个是浏览器对url做了编码转换。
所以当写爬虫时也需要将含中文或者特殊字符的关键词参数做编码转换,上代码:
复制代码
from urllib.request import urlopen
from urllib.request import Request
from fake_useragent import UserAgent
from urllib.parse import urlencode
#设置request header
ua = UserAgent()
headers = {
"User-Agent":ua.random
}
#拼接url
args = {
"ie":"utf-8",
"wd":"博客园"
}
url = "https://www.baidu.com/s?{}".format(urlencode(args))
#封装request
request = Request(url,headers=headers)
# 发送请求,获取服务器给的响应
response = urlopen(request)
# 读取结果,无法正常显示中文
html = response.read()
# 进行解码操作,转为utf-8
html_decode = html.decode()
# 打印结果
print(html_decode)














 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









