







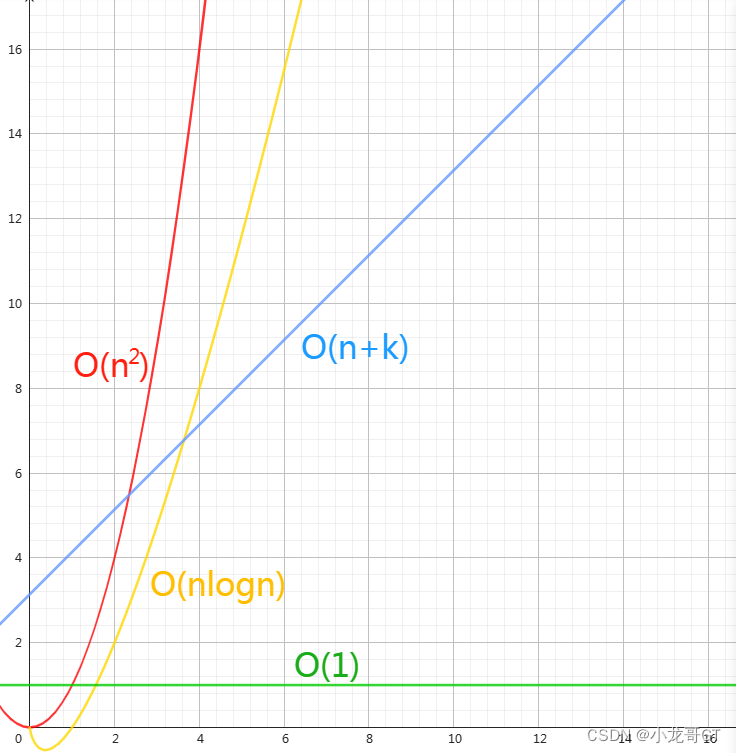
一、冒泡排序
冒泡排序(Bubble Sort)是排序算法里面比较简单的一个排序。它重复地走访要排序的数列,一次比较两个数据元素,如果顺序不对则进行交换,并一直重复这样的走访操作,直到没有要交换的数据元素为止。下面为各编程语言的实现案例。

二、选择排序
选择排序(Selection Sort)是一种简单直观的排序算法。它首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
三、插入排序
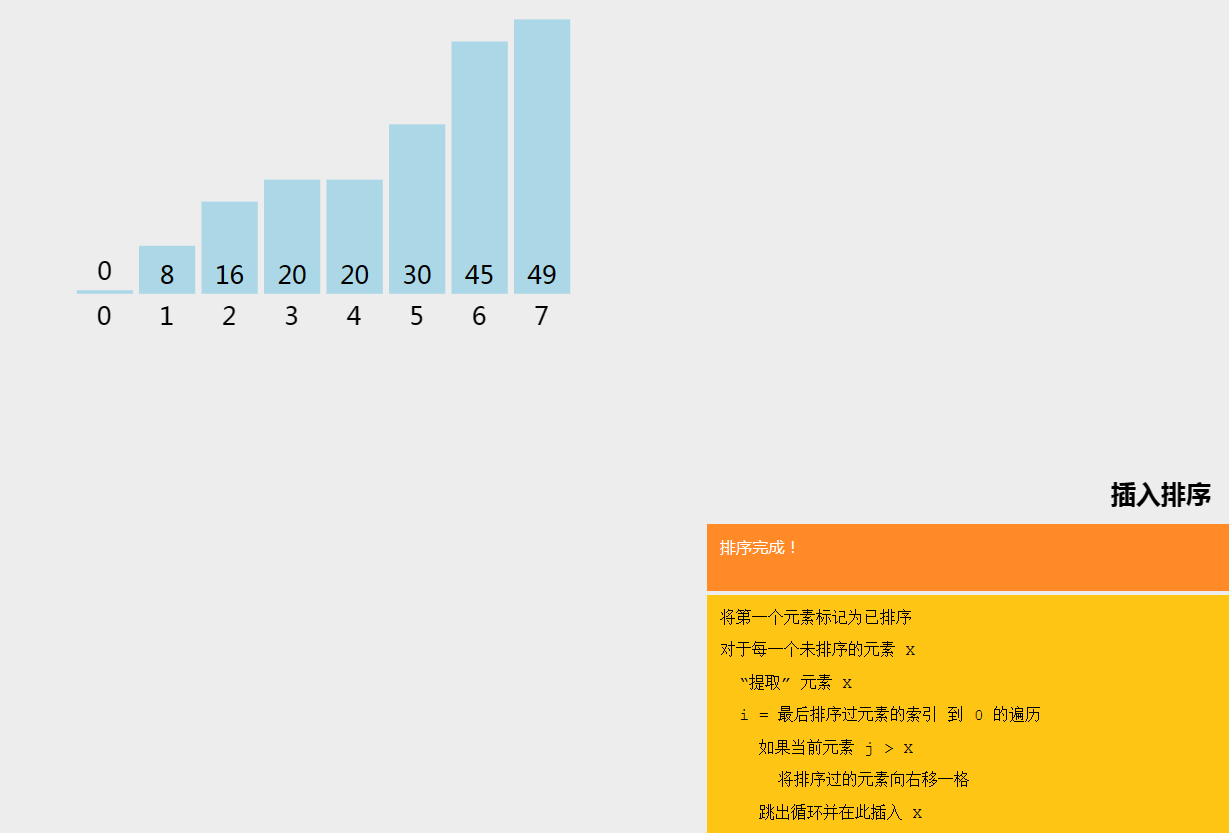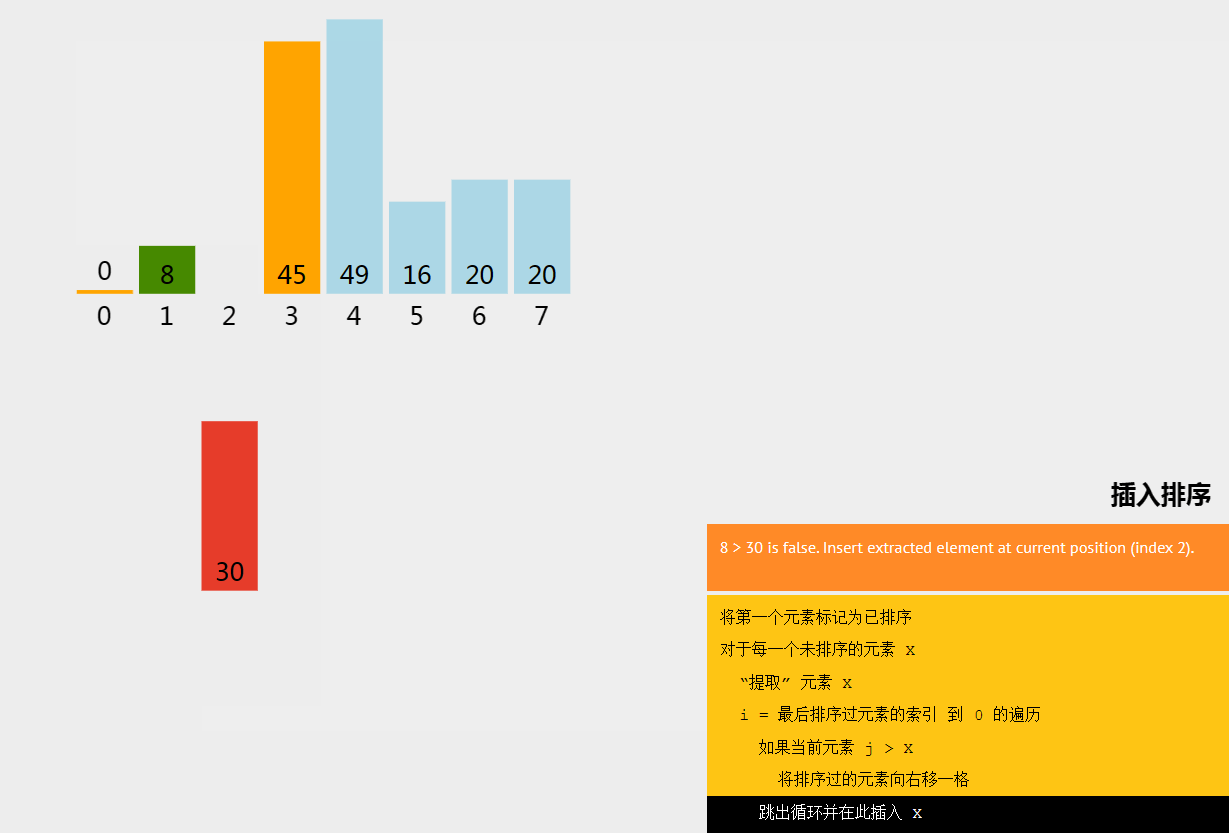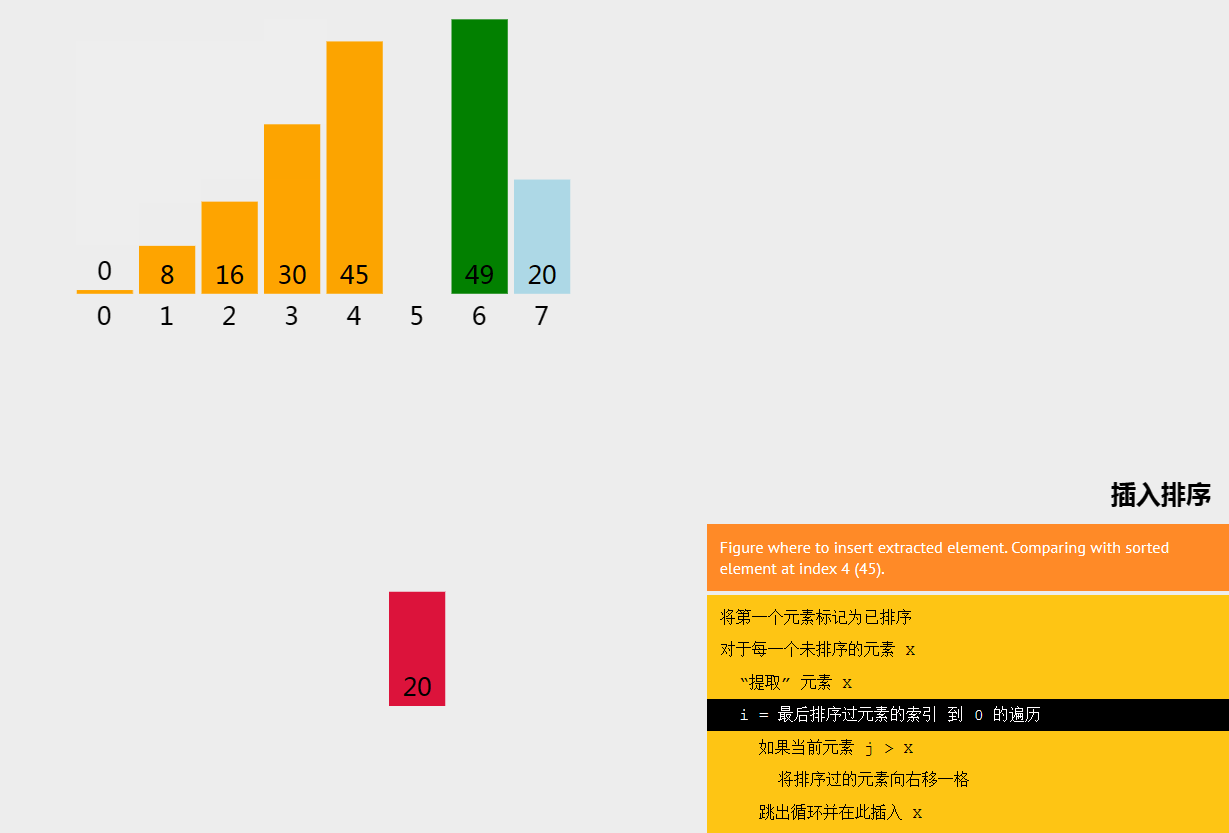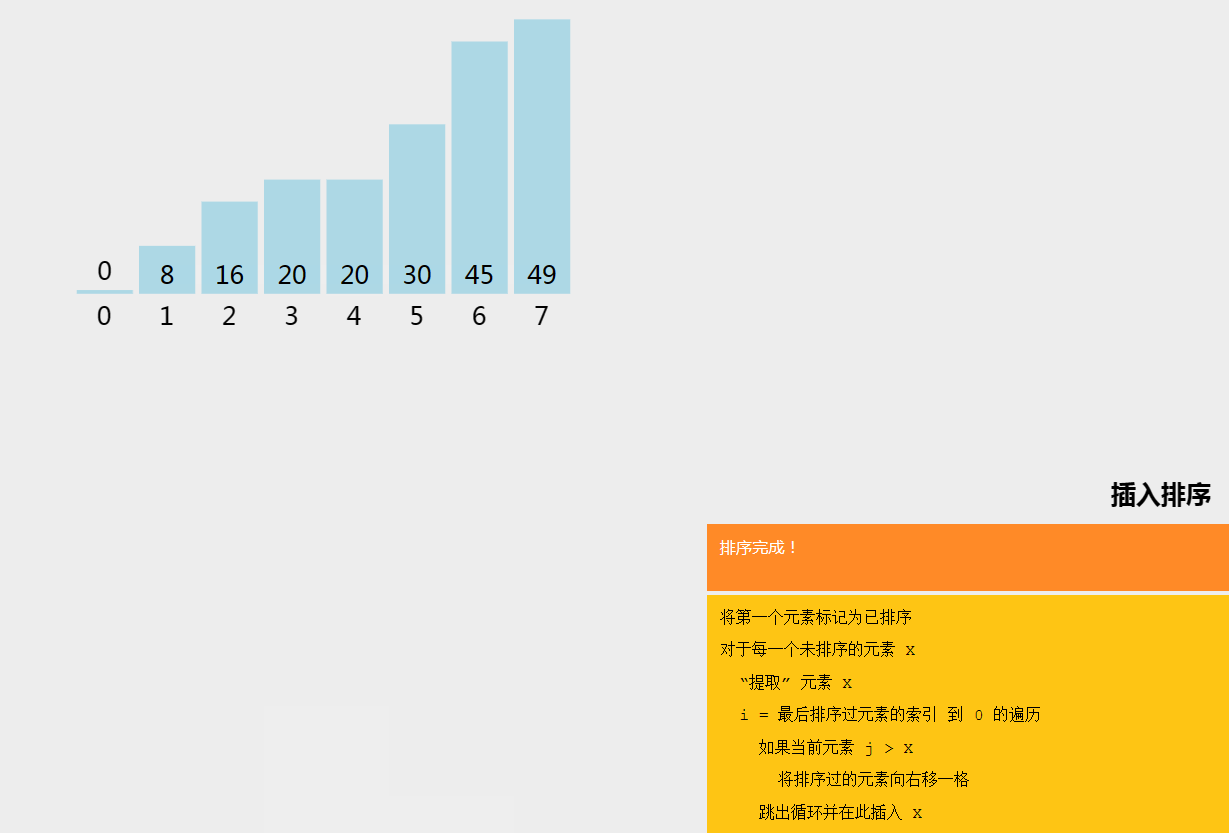
插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,直到整个数组有序。
四、归并排序
归并排序(Merge Sort)的思想是将一个大的问题分解成两个或多个小问题,然后将这些小问题的解合并成整个问题的解。具体来说,归并排序将一个未排序的数组分成两个子数组,对每个子数组进行排序,然后将两个排好序的子数组合并成一个排好序的数组。
五、快速排序
快速排序(Quick Sort)是一种分治的排序算法。快速排序算法会选择数组中的一个元素作为枢轴(pivot),将数组中所有其他元素与该枢轴元素进行比较,按照顺序将其放在枢轴的两边。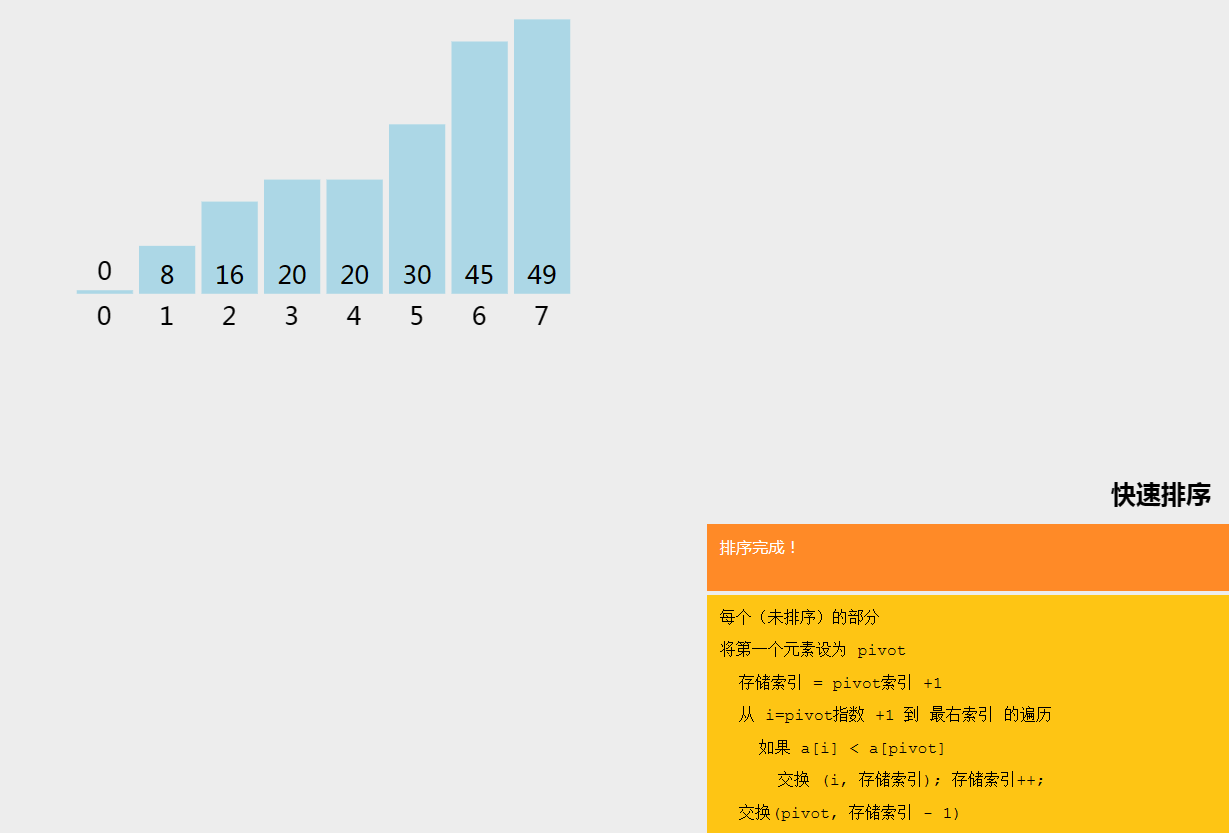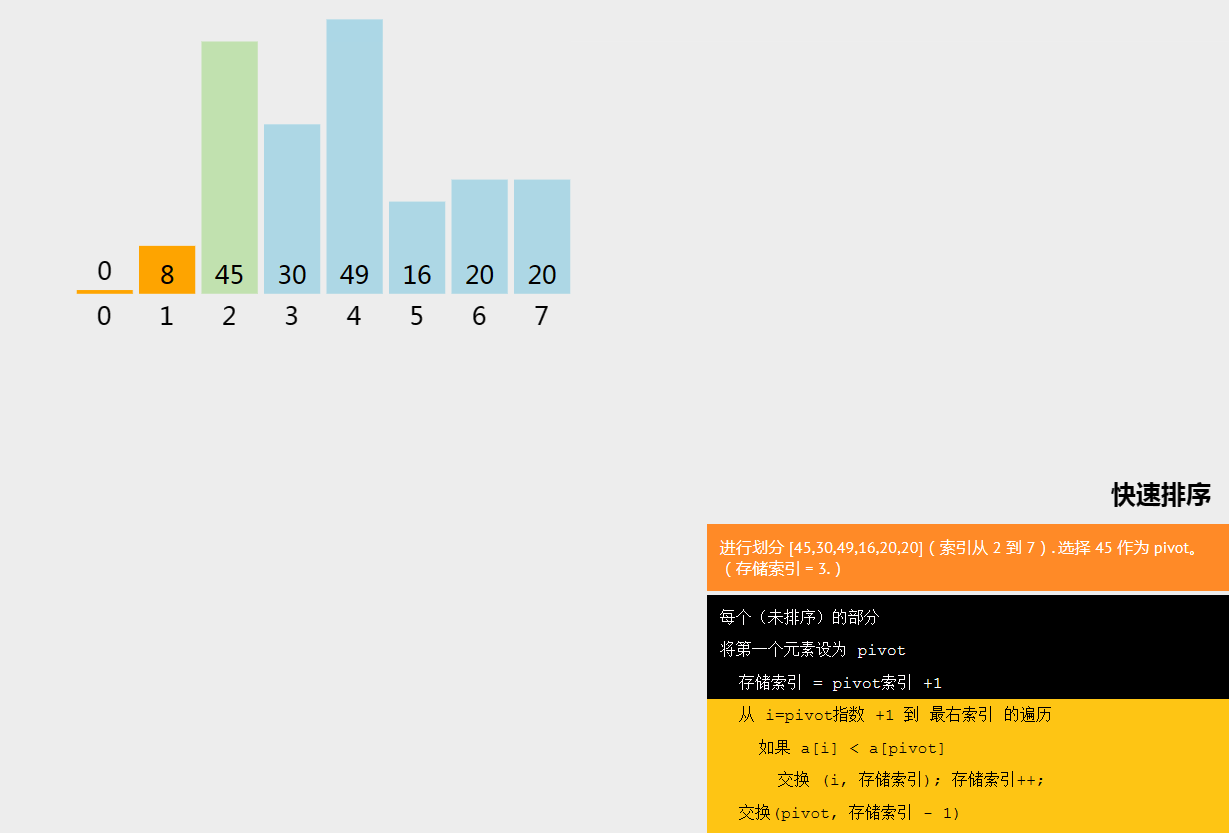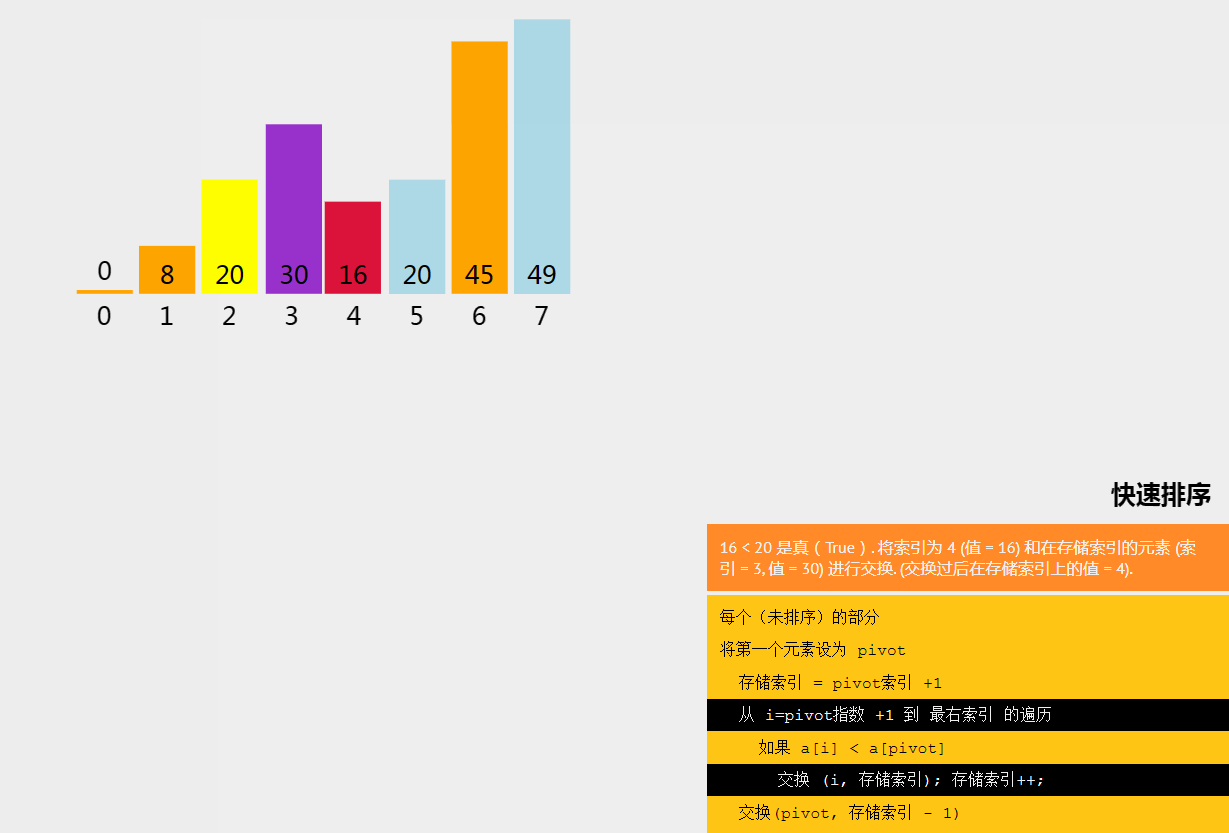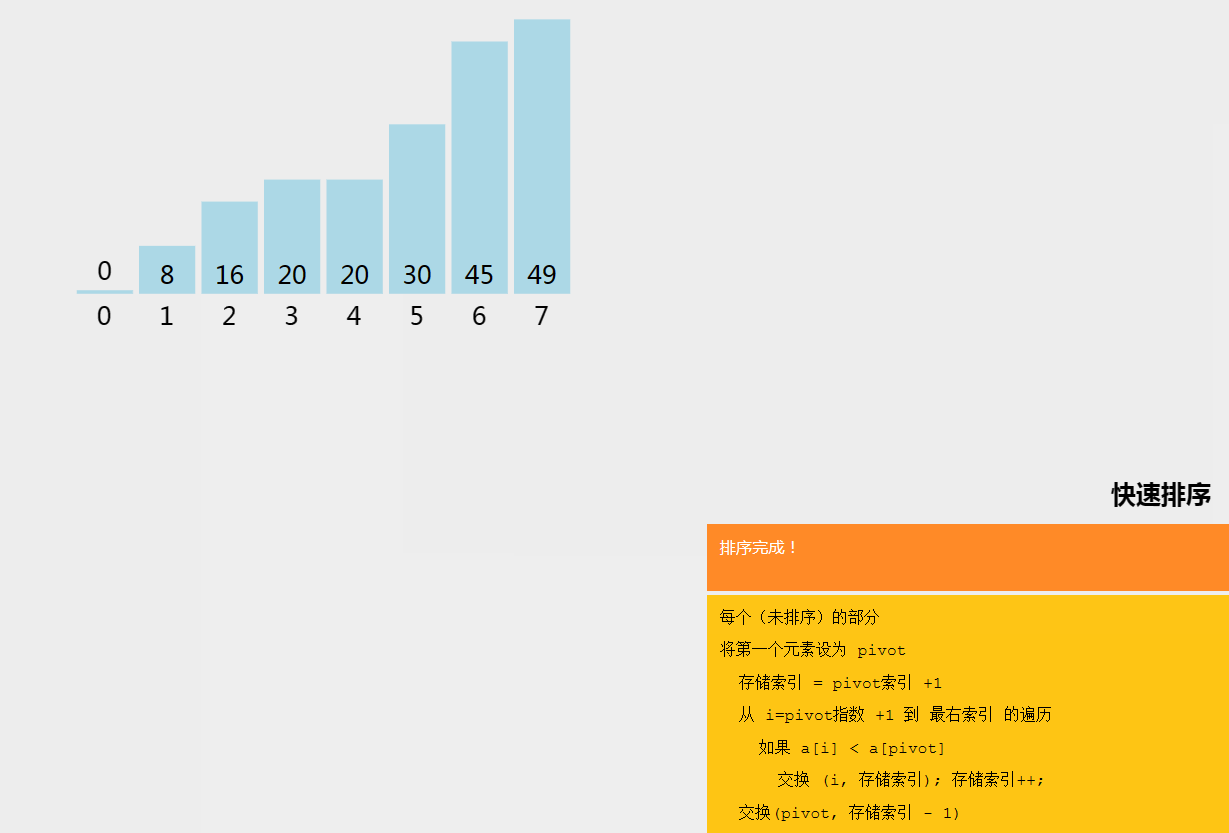
六、随机快速排序
随机快速排序(Randomized Quicksort)是快速排序的一种变种,其基本思想是在快速排序的基础上,通过随机选择枢轴元素来避免最坏情况的发生,从而提高算法的平均性能。
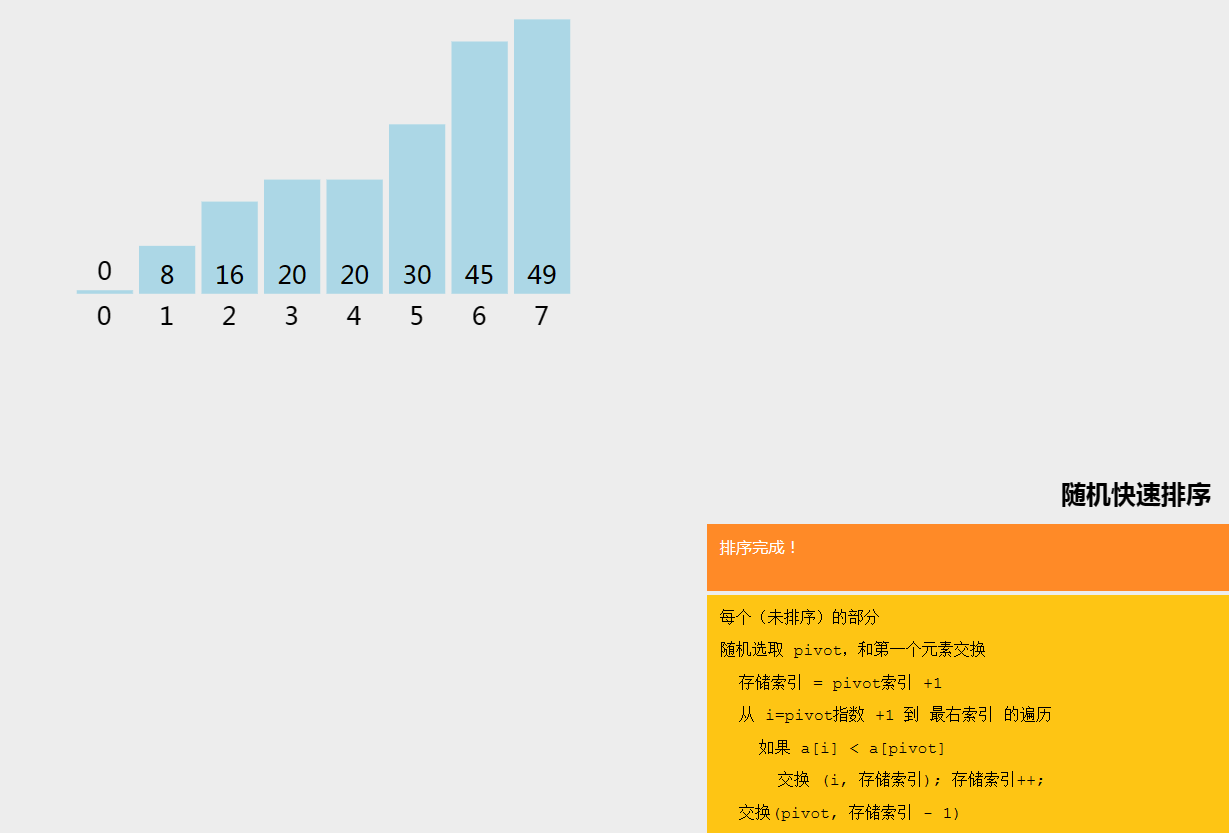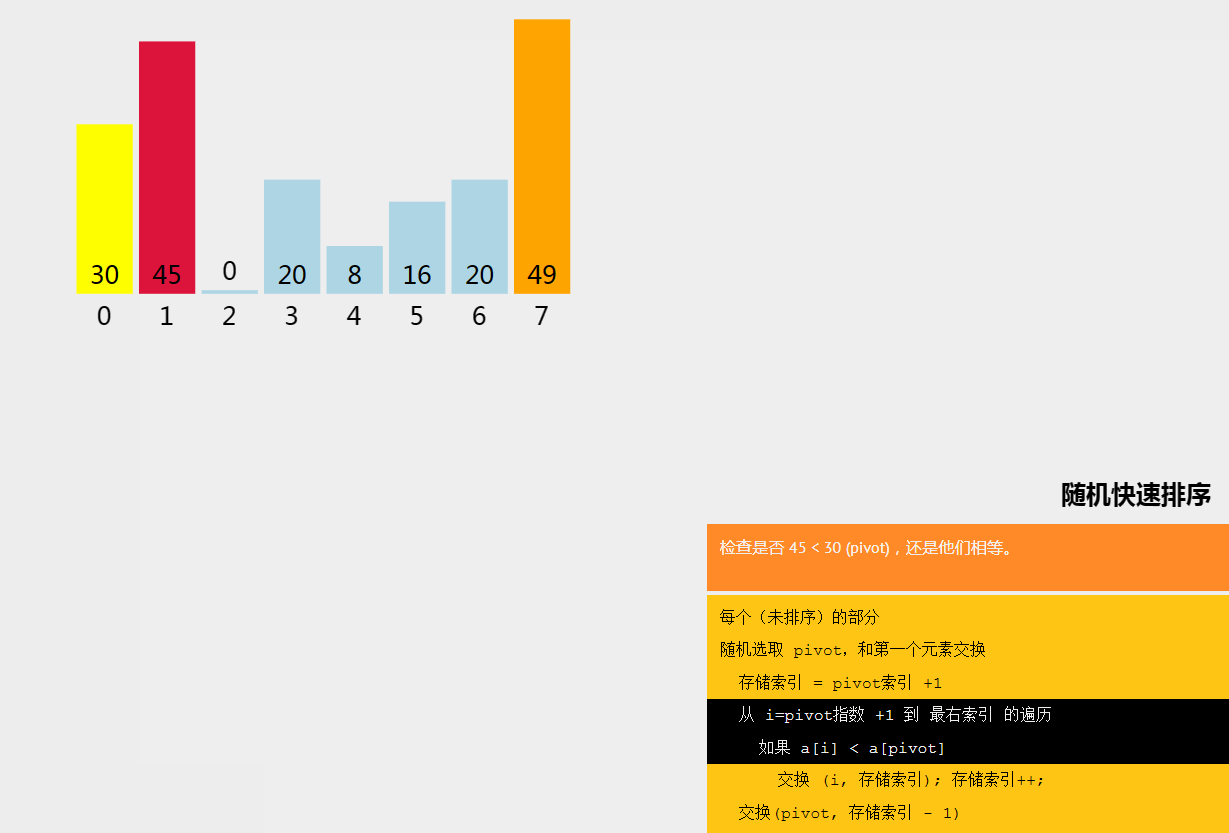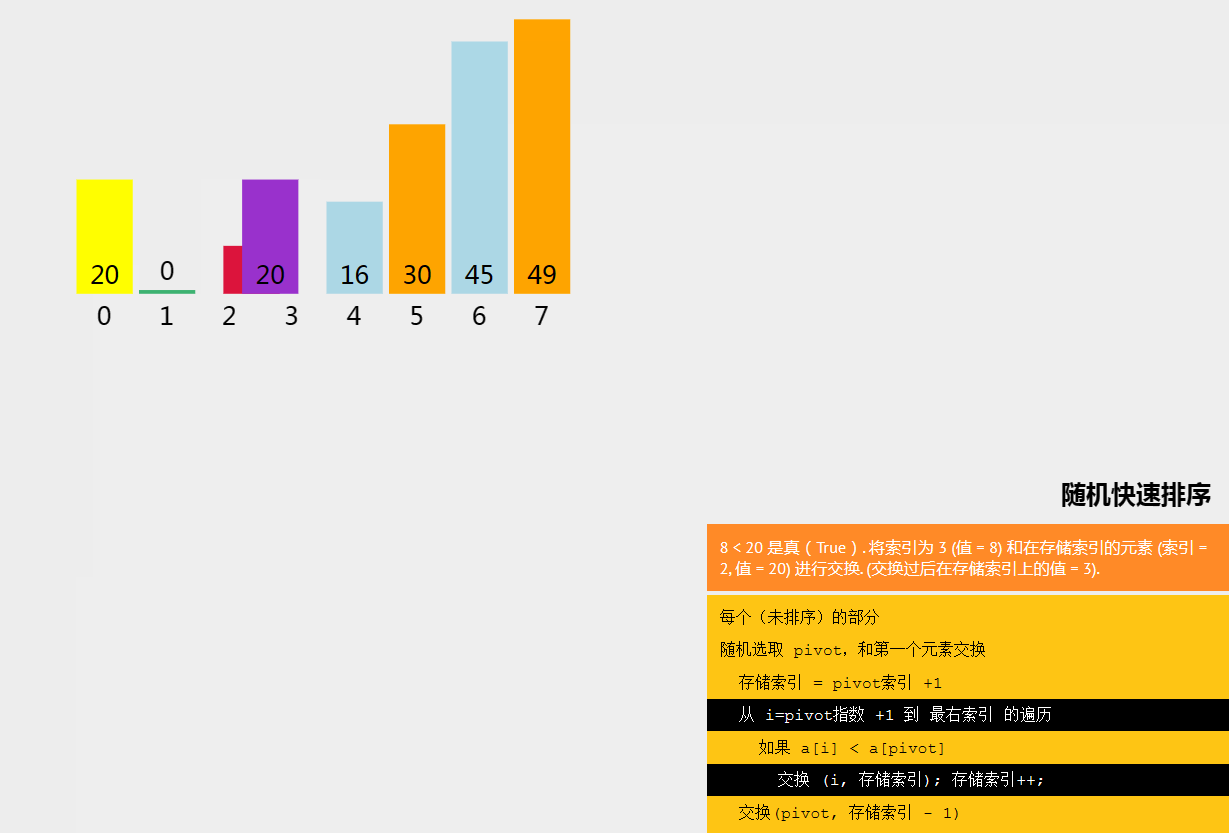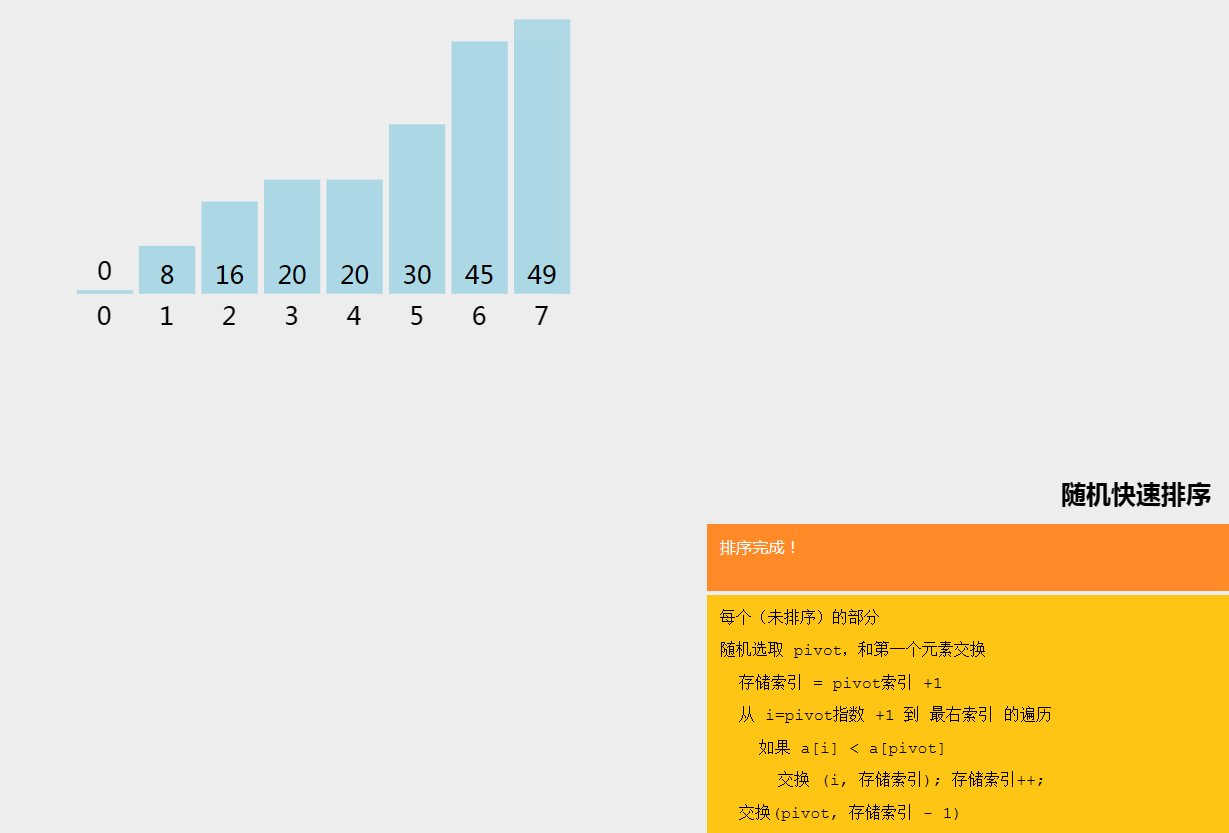
七、计数排序
计数排序(Counting Sort)是一种直观的排序算法。它首先在待排序的数组中找到最大和最小的元素,然后统计数组中每个元素值出现的次数,最后根据每个元素值出现的次数来排序数组。
八、基数排序
基数排序(Radix Sort)是一种非比较排序算法,它根据数字的每一位来对元素进行排序。基数排序适用于整数排序,其中数字的每一位都代表了一个特定的“基数”。
复杂度一览
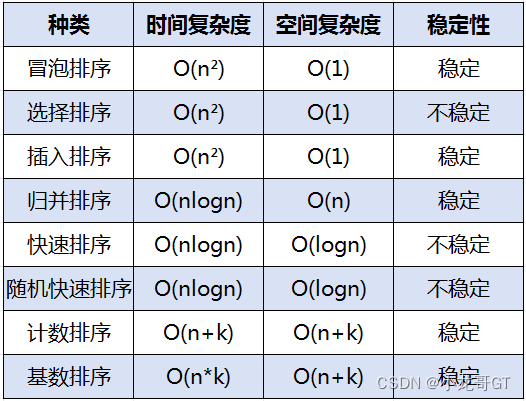
时间复杂度:当输入规模增大时,算法运行时间的增长速度。
空间复杂度:当输入规模增大时,算法所需额外空间的增长速度。
O:用于表示算法的时间 / 空间复杂度。它表示当输入数据的规模增大时,算法的运行时间 / 所需额外空间的增长趋势。
n:表示输入数据的规模,通常指数组的长度。
k:通常表示一个常数,它与输入数据的规模无关。常数项在时间 / 空间复杂度的分析中通常被忽略,因为它们对算法的运行时间 / 所需的额外空间的影响相对较小。例如,O(n+k) 可以简化为O(n),因为k是一个常数,对算法的运行时间 / 所需的额外空间的增长趋势没有实质性的影响。
对于一个复杂度为 O(n)或O(n+k)的算法,当输入规模增大时,算法运行时间 / 所需的额外空间将以线性的速度增长。而对于一个复杂度为 O(n²)的算法,当输入规模增大时,算法运行时间 / 所需的额外空间将以平方的速度增长。
稳定性:当a=b时,稳定的排序方式不会调换a和b的位置,而不稳定的排序方式有可能调换a和b的位置。















 961
961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









