







基础知识总结
(1)机器翻译技术背景:基于词的翻译模型->基于短语的翻译模型->基于句法的翻译模型->神经网络翻译模型。
(2)译后编辑:
通过人工直接修改机器翻译的自动译文来完成翻译。译后编辑是最简单的人机交互方式。
优点:如果机器翻译的自动译文质量较高,人工修改量就比较少,这种方式可以有效提升译员的生产效率。
缺点:当前的机器翻译系统对应的译文质量远未达到人工翻译场景的用户期望。如果机器翻译的自动译文质量较差,译员不得不为了少打几个字而被迫分析和修改漏洞百出的整句译文,其代价远超过直接翻译。
目前神经网络翻译模型通常存在“顺而不信”和翻译结果难以预测等问题,将译后编辑应用于实践还有很多挑战。
(3)交互式机器翻译:通过翻译人员与机器翻译引擎之间的交互作用,从而实现人类译员的准确性和机器翻译引擎的高效性的有效整合。
交互式机器翻译的使用对象是:译员
一:PRIMT: A Pick-Revise Framework for Interactive Machine Translation
(1)解决的问题:传统的交互式机器翻译技术交互的顺序采用从左到右的顺序。
从左到右的顺序:从句子开头开始处理目标翻译句子,每次修改最左边的关键句子,这个方法以从目标翻译句子最开始 到已经修改的部分都是对的为前提。
缺点:很难直接修改句子末尾的关键错误。?延迟模糊点的修改,降低交互效率。
(2)提出的模型:Pick:选择关键错误+Revise:修改目标翻译句子+两个自动建议模型。

源语言句子:
s
1
.
.
.
s
n
s_1...s_n
s1...sn
第一步:利用约束解码器产生第一次目标翻译句子
e
1
.
.
.
e
n
e_1...e_n
e1...en
第二步:用户判断目标翻译句子是否可接受,若可接受则翻译结束,不可接受转第三步
第三步:Picking:寻找翻译中的关键错误。修改关键错误对翻译的提升效果比较大。Revising:用户通过推荐的更改或人工输入来更改目标翻译句子。
第四步:使用约束解码器来搜索具有先前PRP作为约束的最佳转换。忽略许多翻译选项,是的搜索空间比标准解码小的多。
future work:Model Adaption
(3)suggestion model:
Picking Suggestion Model:自动识别可能被错误翻译的短语,并建议用户选择这些短语。将源句短语分为:错误翻译的短语和正确翻译的短语。在修改后使用翻译质量增益作为衡量标准,将修改后能够提升翻译质量的短语作为错误翻译的短语。
建模需要的重要信息:短语是否难翻译;当前翻译选项是否正确。
Revising suggestion model:根据给定的背景选择给定短语的更正翻译。修改后模型能记住修改吗?
实验中使用的方法:模拟人工交互来进行Pick和Revise。选择基线翻译中的每个短语翻译结果,在修改时选择最长的翻译选项作为翻译结果。?
二:Interactive Neural Machine Translation from Both Ends
(1)问题:目前,最先进的Seq2Seq模型仍然无法像人类那样产生令人满意的句子。
单向交互模型:从左到右修改翻译输出。
单向交互模型可能存在的问题:
单向交互模型只能重新生成修改部分,而不是更新整个句子。造成了每次修改都应该修改最左边的错误的约束。
很少能利用修改后的句子。
(2)提出的方法:顺序双向解码器:从句子两端执行交互式NMT,修改句子两端的翻译,允许人们修改翻译的任意单词,在得到修改后更新整个句子。人工首先修改最关键的错误,然后模型更新整个句子,自动修复小错误。
分别使用在线学习(在先前修改的句子上微调Seq2Seq模型,使参数适应特定的话语或领域)和修订记忆方法的句子级别和单词级别的交互历史,避免在交互过程中出现相同的错误。

(3)Sequentional Bi-Directional Decoding
两个解码器:前向解码器
f
→
f^\rightarrow
f→和反向解码器
f
←
f^\leftarrow
f←,它们共享相同的编码器,但顺序工作。
在交互过程中,首先前向解码器作为生成基本翻译
y
=
y
1
,
.
.
.
,
y
j
,
.
.
.
y={y_1,...,y_j,...}
y=y1,...,yj,...的模型,给定要修改的部分为{
y
j
→
y
j
r
y_j\rightarrow{y_j^r}
yj→yjr},然后前向解码器更新翻译中修改的部分(和单向模型一样),那么前向解码器新的解码状态为:
s
→
′
=
f
→
(
y
j
r
,
s
j
,
c
j
+
1
′
)
s^{\rightarrow'}=f^\rightarrow(y_j^r,s_j,c^{'}_{j+1})
s→′=f→(yjr,sj,cj+1′)
新得到的翻译的句子为:
{
.
.
.
y
j
−
1
,
y
j
r
,
y
j
+
1
′
,
y
j
+
2
′
,
.
.
.
}
\{...y_{j-1},y_j^r,y_{j+1}^{'},y_{j+2}^{'},...\}
{...yj−1,yjr,yj+1′,yj+2′,...}
y
j
r
y_j^r
yjr右边的是新生成的。
将
{
.
.
.
y
j
−
1
,
y
j
r
,
y
j
+
1
′
,
y
j
+
2
′
,
.
.
.
}
\{...y_{j-1},y_j^r,y_{j+1}^{'},y_{j+2}^{'},...\}
{...yj−1,yjr,yj+1′,yj+2′,...}输入给反向解码器,产生:
s
j
−
1
←
′
=
f
l
e
f
t
a
r
r
o
w
(
y
j
r
,
s
j
′
,
c
j
−
1
′
)
s^{\leftarrow'}_{j-1}=f^{leftarrow}(y_{j}^r,s_j^{'},c_{j-1}^{'})
sj−1←′=fleftarrow(yjr,sj′,cj−1′)
由此反向解码器可以生成新的左部。
最终输出:
{
.
.
.
,
y
j
−
2
′
,
y
j
−
1
′
,
y
j
r
,
y
j
+
1
′
,
y
j
+
2
′
,
.
.
.
}
\{...,y_{j-2}^{'},y_{j-1}^{'},y_j^r,y_{j+1}^{'},y_{j+2}^{'},...\}
{...,yj−2′,yj−1′,yjr,yj+1′,yj+2′,...}
(4)针对一轮交互中存在多处修改提出的方法:
采用网格搜索俩存储包含先前修改的部分翻译,在网格搜索之后,所有先前的修改将包含在最终翻译输出中。
(5)句子级别的在线学习
目标函数:
L
O
=
1
J
′
∑
j
=
1
J
′
l
o
g
P
(
y
j
′
∣
y
<
j
′
,
x
)
L^O=\frac{1}{J^{'}}\sum^{J^{'}}_{j=1}logP(y_j^{'}|y^{'}_{<j},x)
LO=J′1j=1∑J′logP(yj′∣y<j′,x)
x
x
x:源句
根据此目标函数微调双向模型。
(6)单词级别的修订记忆?
将来自编辑的句子的新知识纳入翻译系统。通过在线学习技术纠正句子,在y上执行对模型的更新。
三.《Online Learning for Effort Reduction in Interactive Neural Machine Translation》
1. IMT模型

x
t
x_t
xt:源句
y
t
y_t
yt:翻译假设
f
f
f:反馈
过程:输入源句到系统,产生翻译假设,人工代理检查假设并提供反馈信号f(反馈信号的范围可以从简单的单词校正到复杂的,不确定的单词校正) 。新假设优于旧假设此过程一直迭代,指导用户接受系统提供的翻译假设。论文中使用键盘和鼠标向INMT系统引入反馈。
基于统计翻译的IMT模型:
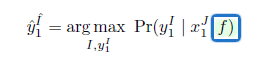
f
f
f包含位于位置
t
′
t^{'}
t′的翻译假设中最左边的错误单词的校正,将其看做用户认证了的前缀
y
l
^
t
′
\widehat{y_l}^{t^{'}}
yl
t′。
则:
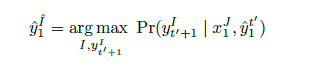
字符级INMT的词汇掩蔽
论文中用户提供的反馈信号处于字符级别。使用基于前缀的交互,用户将从左到右校正假设。
在字符级INMT中,用户的反馈信号为:
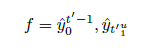
u
u
u:第
t
′
t^{'}
t′个词中的u位置
y
0
t
′
−
1
^
\widehat{y_0^{t^{'}-1}}
y0t′−1
:一直到
t
′
−
1
t^{'}-1
t′−1的已验证过的序列。
y
t
1
′
u
^
\widehat{y_{t_1^{'u}}}
yt1′u
:第
t
′
t^{'}
t′个词的正确部分。
例子:

这里mask就是int,作为前缀看哪些词compatible。
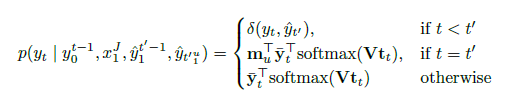
y
t
ˉ
\bar{y_t}
ytˉ:one-hot表示。
V
t
t
Vt_t
Vtt:NMT系统输出层。
2.在线学习方法
OL是一种机器学习范例,其中数据可以顺序获得,模型以递增方式更新,从样本到样本。
1.向系统提供样本。
2.系统提供此样本的预测。
3.向系统提供正确的预测。
4.系统使用正确的预测来调整其模型。
后编辑中的在线学习
1.新的源语句
x
t
x_t
xt到系统。
2.系统产生翻译假设
y
t
y_t
yt。
3.人工代理修改此假设并纠正系统所犯的错误或交互式翻译源句,然后模型生成正确的翻译
y
t
y_t
yt。
4.系统使用校正后的样本来调整其模型。

四.QuickEdit: Editing Text & Translations by CrossingWords Out
QuickEdit:Sequence-to-Sequence.
Multihop architecture+Dual attention

输入:源语句和有更改标记的初始猜测目标语句。
初始猜测目标语句:

l
g
l_g
lg:length
t
i
t_i
ti:target vocabulary index
c
i
c_i
ci:二进制变化标签(1表示用户请求改变这个词;0无需改变)
序列---->编码器(第一层)----->目标字嵌入+位置嵌入(分为
c
i
=
0
c_i=0
ci=0和
c
i
=
1
c_i=1
ci=1两种位置嵌入)—>key and value pairs

编码器每一层产生的注意力权值:

得出注意力权值后,
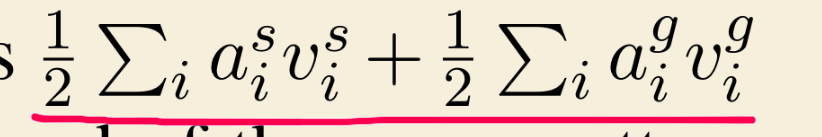
训练过程:
先在训练语料上训练一个翻译模型(得到guess(模拟的后期编辑:guess中不属于参考翻译的词全部都进行标记(change label))),再进行QUickEdit的训练。















 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









