







CRUSH详解
CRUSH简介
CRUSH全称Controlled Replication Under Scalable Hashing,是一种数据分发算法,类似于哈希和一致性哈希。哈希的问题在于数据增长时不能动态加Bucket,一致性哈希的问题在于加Bucket时数据迁移量比较大,其他数据分发算法依赖中心的Metadata服务器来存储元数据效率较低,CRUSH则是通过计算、接受多维参数的来解决动态数据分发的场景。
算法基础
在学习CRUSH之前,需要了解以下的内容。
CRUSH算法接受的参数包括cluster map,也就是硬盘分布的逻辑位置,例如这有多少个机房、多少个机柜、硬盘是如何分布的等等。cluster map是类似树的多层结果,子节点是真正存储数据的device,每个device都有id和权重,中间节点是bucket,bucket有多种类型用于不同的查询算法,例如一个机柜一个机架一个机房就是bucket。
另一个参数是placement rules,它指定了一份数据有多少备份,数据的分布有什么限制条件,例如同一份数据不能放在同一个机柜里等的功能。每个rule就是一系列操作,take操作就是就是选一个bucket,select操作就是选择n个类型是t的项,emit操作就是提交最后的返回结果。select要考虑的东西主要包括是否冲突、是否有失败和负载问题。
算法的还有一个输入是整数x,输出则是一个包含n个目标的列表R,例如三备份的话输出可能是[1, 3, 5]。

图虽然很复杂,但如果理解了几个基本操作的含义就很好读下来了,这里是三个操作的伪代码,take和emit很好理解,select主要是遍历当前bucket,如果出现重复、失败或者超载就跳过,其中稍微复杂的“first n”部分是一旦遇到失败,第一种情况是直接使用多备份,第二种情况是使用erasing code基本可以忽略。看着下面的图就更好理解具体的算法了。
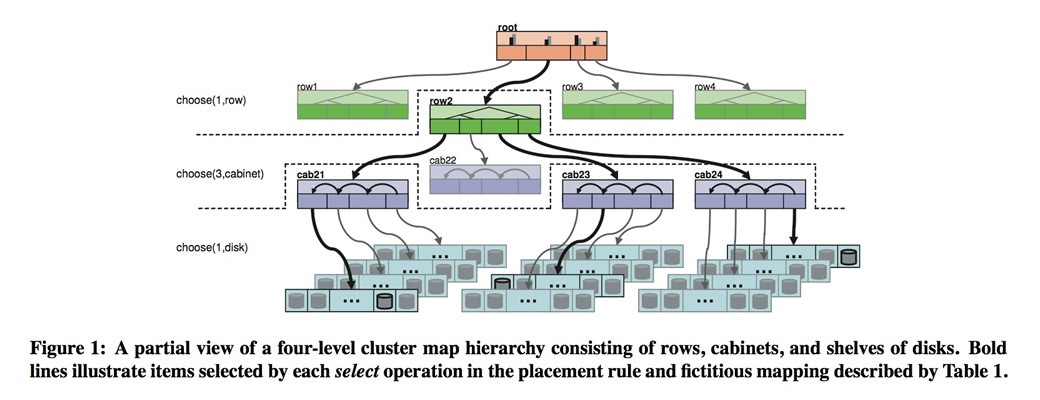
MAP改变和数据迁移
当添加移除存储设备,或有存储设备发生故障时(cluster map发生改变时),存储系统中的数据会发生迁移。好的数据分布算法可以最小化数据迁移大小
Bucket的类型
CRUSH映射算法解决了效率和扩展性这两个矛盾的目标。而且当存储集群发生变化时,可以最小化数据迁移,并重新恢复平衡分布。CRUSH定义了四种具有不同算法的的buckets。每种bucket基于不同的数据结构,并有不同的c(r,x)伪随机选择函数。
不同的bucket有不同的性能和特性:
- Uniform Buckets:适用于具有相同权重的item,而且bucket很少添加删除item。它的查找速度是最快的。
- List Buckets:它的结构是链表结构,所包含的item可以具有任意的权重。CRUSH从表头开始查找副本的位置,它先得到表头item的权重Wh、剩余链表中所有item的权重之和Ws,然后根据hash(x, r, item)得到一个[0~1]的值v,假如这个值v在[0~Wh/Ws)之中,则副本在表头item中,并返回表头item的id。否者继续遍历剩余的链表。
- Tree Buckets:链表的查找复杂度是O(n),决策树的查找复杂度是O(log n)。item是决策树的叶子节点,决策树中的其他节点知道它左右子树的权重,节点的权重等于左右子树的权重之和。CRUSH从root节点开始查找副本的位置,它先得到节点的左子树的权重Wl,得到节点的权重Wn,然后根据hash(x, r, node_id)得到一个[0~1]的值v,假如这个值v在[0~Wl/Wn)中,则副本在左子树中,否者在右子树中。继续遍历节点,直到到达叶子节点。Tree Bucket的关键是当添加删除叶子节点时,决策树中的其他节点的node_id不变。决策树中节点的node_id的标识是根据对二叉树的中序遍历来决定的(node_id不等于item的id,也不等于节点的权重)。
- Straw Buckets:这种类型让bucket所包含的所有item公平的竞争(不像list和tree一样需要遍历)。这种算法就像抽签一样,所有的item都有机会被抽中(只有最长的签才能被抽中)。每个签的长度是由length = f(Wi)hash(x, r, i) 决定的,f(Wi)和item的权重有关,i是item的id号。c(r, x) = MAXi(f(Wi) hash(x, r, i))。

不同Bucket的算法复杂度和数据迁移大小
要根据存储系统中设备的情况和预期扩展计划来选择不同的bucket。
算法流程
假设我组建一套存储系统,有3个机架(host),每个机架上有4台主机(host),每个主机上有2个磁盘(device),则一共有24个磁盘。预计的扩展方式是添加主机或者添加机架。
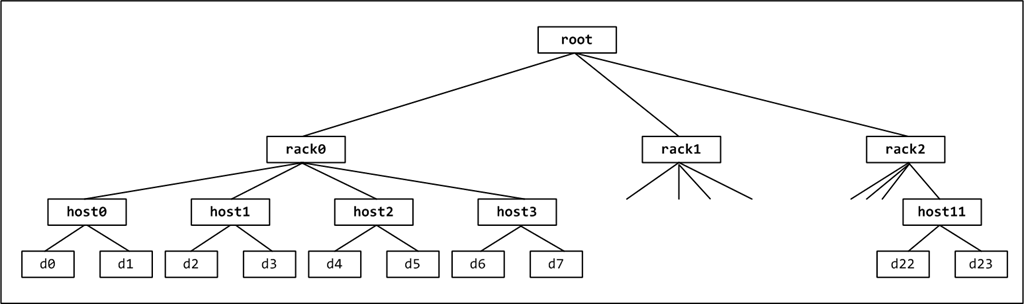
我们的bucket有三种: root、rack、host。root包含的item是rack,root的结构是straw。rack包含的item是host,rack的结构是tree。host包括的item是device,host的结构式uniform。这是因为每个host包括的device的数量和权重是一定的,不会改变,因此要为host选择uniform结构,这样计算速度最快。
参考
[1]Ceph From Scratch CRUSH详解
https://tobegit3hub1.gitbooks.io/ceph_from_scratch/content/architecture/crush.html
[2]ceph的CRUSH数据分布算法介绍
http://way4ever.com/?p=122
[3]ceph的CRUSH算法的源码分析
http://way4ever.com/?p=123















 3078
3078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









