







1. 简介
-
CRUSH 算法能够根据每个存储设备的权重来分布数据对象,使得这个分布近似于均匀分布。
-
数据分布是由具有层级结构的 cluster map 来控制的,其表示了可用的存储资源,以及一些逻辑元素。
-
数据分布策略是根据放置规则来定义的,其指定了要从集群中选出多少个存储设备以存储数据副本,以及数据副本的存放限制(如,故障域隔离)。
-
输入一个整数 x x x(通常是对象的 ID),CRUSH 算法会输出一个大小为 n n n 的有序列表 R → \mathop{R} \limits ^{\rightarrow} R→,其中包含了 n n n 个不同的存储设备。CRUSH 算法所使用的哈希函数接受多个整数作为输入,包括 x x x、cluster map、放置规则;且它是一个确定性的映射函数,只要 cluster map 和放置规则不变,对于同一个输入 x x x,CRUSH 算法的输出结果总是一样的。
2. cluster map
-
cluster map 是由一系列的桶(bucket)和设备(device)组成的一棵树,且桶和设备各自都关联有 ID 和权重。在 Ceph 中,桶的 ID 为负数,设备的 ID 为正数。
-
桶作为树状结构的内部节点,可以包含多个设备或其它的桶。设备则是树状结构的叶子节点,是实际存储数据的地方。
-
权重用于控制一个设备相对地可以存储多少数据。一个桶的权重等于它所包含的所有 item 的权重之和。
-
此外,每个桶都关联有一个选择算法,用于指定如何从该桶中选出指定数目的 item。CRUSH 算法提供了四种类型的桶,每种类型的桶的选择算法各不相同。
-
cluster map 的每个层级分别代表了不同级别的故障域,如,数据中心、机房、机架、主机、设备等。

3. 数据放置
CRUSH 算法为数据分布策略定义了放置规则,以允许存储系统或管理员准确地指定应该如何放置数据对象。每个放置规则包含了一系列下述操作:
- take(a):选择 cluster map 中的一个 item(通常是某个 bucket),并将其存入输入向量 i n p u t _ v e c t o r input\_vector input_vector 中,以作为后续操作的输入。
- select(n,t):遍历输入向量 i n p u t _ v e c t o r input\_vector input_vector 中的每个 item,然后在以该 item 为根的子树中选出 n n n 个类型为 t t t 的不同的 item。
- emit():将 select 操作找到的 n × ∣ i n p u t _ v e c t o r ∣ n \times |input\_vector| n×∣input_vector∣ 个 item 存入结果向量 r e s u l t _ v e c t o r result\_vector result_vector。

每个操作的 Python 实现大致如下:
def CRUSH(cluster_map, placement_rule, x):
input_vector = []
output_vector = []
result_vector = []
buckets = cluster_map.buckets
policy = placement_rule.policy
def take(a):
nonlocal input_vector
input_vector = [a]
def select(n, t):
nonlocal input_vector
nonlocal output_vector
output_vector = []
for item in input_vector:
failure_count = 0
for replica_number in range(1, n+1):
replica_failure_count = 0
retry_descent = True
while retry_descent:
retry_descent = False
bucket = buckets(item)
retry_bucket = False
while retry_bucket:
retry_bucket = False
if policy == "first n":
replica_number_new = replica_number + failure_count
else:
replica_number_new = replica_number + replica_failure_count * n
output_item = bucket.choose(replica_number_new, x)
if output_item.type != t:
bucket = buckets(output_item)
retry_bucket = True
elif output_item in output_vector or is_failed(output_item) or is_overload(output_item):
replica_failure_count += 1
failure_count += 1
if output_item in output_vector and replica_failure_count < 3:
retry_bucket = True
else:
retry_descent = True
output_vector.append(output_item)
input_vector = output_vector
def emit():
nonlocal result_vector
nonlocal input_vector
result_vector.extend(input_vector)
-
当出现冲突(当前选出的 item 已存在于输出向量中)、失败(如,设备故障)或过载(一个设备已经承载了太多的数据)时,CRUSH 算法会再次尝试从当前桶中选出其他的 item,或继续往下遍历。
-
在基于主副本的冗余策略中,通常希望后面的副本能够在前面的副本失败后替代它。对于此类情况,CRUSH 能够使用 “first n” 个合适的目标设备来放置数据,对上述应代码中的
replica_number_new = replica_number + failure_count,意思是,出现多少次失败,便往后移多少个位置,如下图所示。 -
对于奇偶校验和纠删编码策略来说,因为每个设备存储不同的数据对象,因此目标存储设备在 CRUSH 的输出向量中的位置是比较关键的。对于此类情况,当一个存储设备失败时,应该原地替换该设备,以保持后续设备在输出向量中的位置不变。对应上述代码中的
replica_number_new = replica_number + replica_failure_count * n,意思是,每当出现失败时,便跳过 n 个位置(n 为数据对象总数),如下图所示。

4. 选择算法
原先的 CRUSH 算法提供了四种类型的桶,包括,uniform、list、tree 和 straw。每种类型的桶都有自己的选择算法,以从该桶中选出多个 item,对应上述代码中的 bucket.choose(replica_number_new, x)。
每种类型的桶的选择算法的时间复杂度,以及设备增减时数据重平衡操作的效率比较如下:
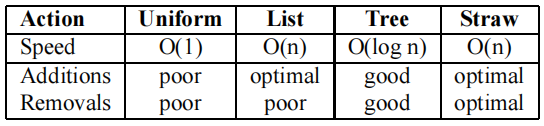
(因为 straw 类型的桶的数据重平衡操作效率最优,此处仅对 straw 选择算法进行阐述。)
straw
(1)从 straw 类型的桶中选出 item 的过程类似于抽签,每个 item 都有一个对应的签长。
(2)对于对象
x
x
x 的第
r
r
r 个副本来说,item
i
i
i 的初始签长为
hash
(
x
,
r
,
i
)
\text{hash}(x,r,i)
hash(x,r,i),然后使用 item
i
i
i 的权重
w
i
w_i
wi 对其签长进行缩放,故 item
i
i
i 的签长为
f
(
w
i
)
hash
(
x
,
r
,
i
)
f(w_i)\text{hash}(x,r,i)
f(wi)hash(x,r,i)。
(3)straw 算法会选出签长最大的 item,即,
max
i
(
f
(
w
i
)
hash
(
x
,
r
,
i
)
)
\max_i(f(w_i)\text{hash}(x,r,i))
maxi(f(wi)hash(x,r,i))。
但事实上, f ( w i ) f(w_i) f(wi) 的计算过程涉及到了其他的 item,所以实际上,数据重平衡过程会波及到其他的设备。因此,CRUSH 算法的作者提出了 straw2 选择算法。
straw2
straw2 的选择算法调整了 f ( w i ) f(w_i) f(wi) 的计算过程,使其只涉及到 item i i i,具体的选择过程如下:
def straw2(bucket, x, r):
max_straw_length = -1
target_item = -1
for item in bucket:
length = hash(x, r)
length = math.log(length/65536) / item.weight
if length > max_straw_length:
max_straw_length = length
target_item = item
return target_item
5. 例子
Ceph 中的 CRUSH map:
...
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host ceph {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.057
alg straw
hash 0 # rjenkins1
item osd.0 weight 0.019
item osd.1 weight 0.019
item osd.2 weight 0.019
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.057
alg straw
hash 0 # rjenkins1
item ceph weight 0.057
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type osd
step emit
}















 8146
8146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









