







 PyramidBox 是一种环境辅助的单步人脸检测器,利用环境信息提升对小尺度、模糊和遮挡人脸的检测性能。通过环境 anchor、低层级特征金字塔网络和环境敏感预测模块,PyramidBox 在 WIDER FACE 和 FDDB 数据集上取得优秀表现,特别是在困难人脸检测上。此外,PyramidAnchors 提供额外的监督信息,而 data-anchor-sampling 策略增强了训练数据多样性。
PyramidBox 是一种环境辅助的单步人脸检测器,利用环境信息提升对小尺度、模糊和遮挡人脸的检测性能。通过环境 anchor、低层级特征金字塔网络和环境敏感预测模块,PyramidBox 在 WIDER FACE 和 FDDB 数据集上取得优秀表现,特别是在困难人脸检测上。此外,PyramidAnchors 提供额外的监督信息,而 data-anchor-sampling 策略增强了训练数据多样性。
PyramidBox:一个环境辅助的单步人脸检测器
文章目录
摘要
人脸检测研究了很多年,剩下的挑战是之一是在不受控制的环境下检测小的,模糊的和部分遮挡的面部。本文提出了一种新的环境辅助的单步人脸检测器,称为 PyramidBox,来解决这个问题。注意到环境的重要性,我们从三个方面提高对环境信息的利用。第一,我们设计了新的环境 anchor 来监督用半监督方法学习到的高层级的环境特征,称为 PyramidAnchors。第二,我们提出低层级特征金字塔网络来充分结合高层级环境语义特征和低层级面部特征,也让 PyramidBox 能够用单步预测所有尺度的面部。第三,我们阐述了一个环境敏感的结构来提升预测网络的能力和最终输出的准确度。除此之外,我们用 data-anchor-sampling 的方法来增加不同尺度的训练样本,提高了训练数据的多样性,包含小尺寸的人脸。通过利用环境信息,PyramidBox 在 FDDB 和 WIDER FACE 这两个常用的人脸检测基准上相比 state-of-the-art 表现优异。
1 简介
在各种人脸应用中,人脸检测是基本的和必需的任务。Viola 和 Jones 开创性地利用 AdaBoost 算法和哈尔特征训练了一个级联的有无人脸分类器。在那之后,许多后续的工作被提出来提升这个级联检测器的表现。然后,DPM 被用于人脸检测任务,通过建立可变形的面部部分的联系。这两类方法主要基于手工设计的特征,表示能力差并且需要分步训练。
随着 CNN 的突破性进展,近年来人脸检测取得了许多进展。现代的基于 CNN 的目标检测包括 R-CNN,SSD,YOLO,FocalLoss 和许多它们的扩展版本。受益于深度学习的强大和端到端的优势,基于 CNN 的人脸检测已经取得了好得多的效果,并且为后续的发展提供了基准。
基于 anchor 的检测框架致力于在不受控制的环境里检测有难度的面部,比如 WIDER FACE。SSH 和 S 3 F D S^3FD S3FD 开发了尺度不变网络在单个网络的不同层中检测不同尺度的面部。 Face R-FCN 对分数映射上的特征响应重新加权,并且通过位置敏感的平均池化消除了每个面部区域中的不均匀分布的影响。FAN 提出了一个 anchor 级的关注机制,通过高亮面部区域的特征来检测被遮挡的面部。
这些工作给出了设计 anchor 和相关网络来检测不同尺度人脸的有效方式,但是没有重点关注环境信息。然而环境信息在检测难度大的人脸时非常重要。实际上在现实世界中,人脸从不单独出现,而是一般和肩膀或者身体一起,提供了丰富的可利用的环境关联,尤其是面部纹理由于低分辨率,模糊或者遮挡不能被辨别时。我们提出了一个新的环境辅助的网络框架,充分利用了环境信号,步骤如下:
第一,网络不仅能学习面部特征,还能学习环境特征例如头部和身体。实现这个目标需要额外的标签,需要设计和这些部分匹配的 anchor。本文用半监督的方案来生成环境部分的近似的标签,构造一系列叫做 PyramidAnchors 的 anchors。PyramidAnchors 可以很容易地添加到一般的基于 anchor 的结构中。
第二,高层次的环境特征应该和低层级的充分结合。检测难度高和低的面部的外观非常不同,意味着不是所有高层级的语义特征都对检测小目标有利。我们研究特征金字塔网络 (FPN) 的性能,并把它改成了低层级的特征金字塔网络 (LFPN),以结合相互有帮助的特征。
第三,预测分支网络应该充分利用结合了的特征。我们采用环境敏感预测模块 (CPM) 用一个广而深的网络来吸收目标人脸周围的环境信息。同时,我们为预测模块引入了一个 max-in-out 层进一步提高分类网络的能力。
此外,我们提出了一种训练策略,叫做 data-anchor-sampling,来调整训练集的分布。为了学习更有代表性的特征,困难样本的多样性非常重要,可以通过交叉样本的数据增强实现。
为了更清晰地表述,将本研究的主要贡献总结为以下五点:
- 本文提出了一种基于 anchor 的环境辅助方法,即 PyramidAnchors,从而引入有监督的信息来为较小的、模糊的和部分遮挡的人脸学习环境特征。
- 我们设计了低层级特征金字塔网络 (LFPN) 来更好地融合环境特征和面部特征。同时,该方法可以在单步中较好地处理不同尺度的人脸。
- 我们提出了一种环境敏感的预测模型,该模型由混合网络结构和 max-in-out 层组成,从融合的特征中学习准确的定位和分类。
- 我们提出了一种关注尺度的 data-anchor-sampling 策略,改变训练样本的分布,重点关注较小的人脸。
- 在通用人脸检测基准 FDDB 和 WIDER FACE 上,我们达到了当前最佳水平。
本文的后续章节内容如下:第 2 章概述相关工作。第 3 章介绍提出的方法。第 4 章展示实验。第 5 章总结。
2 相关工作
基于 Anchor 的人脸检测器
Anchor 在 Faster R-CNN 中首次被提出,然后别广泛用于两阶段和单步的目标检测。基于 anchor 的目标检测在近年来取得了很大进展。与 FPN 类似,Lin 使用了 translation-invariant anchor boxes,Zhang设计了 anchors 的不同尺度使检测器能够应对不同尺度的人脸。FaceBoxes 采用 anchor densification 使得不同类型的 anchor 在图像上有相同的密度。 S 3 F D S^3FD S3FD 提出 anchor 匹配策略提高较小的人脸的召回率。
尺度不变的人脸检测器
为了提高检测器检测不同尺度人脸的能力,许多最先进的研究在相同的框架里构建不同的结构来检测不同大小的人脸,设计高层级的特征检测较大的人脸,低层级的特征检测较小的人脸。为了将高层级语义特征整合到有更高分辨率的低等级的层中,FPN 提出了一种自上而下的结构,利用了所有尺度的高层级语义特征。最近,FPN 类型的框架在目标检测和人脸检测上表现出色。
环境辅助的人脸检测器
最近,环境信息的重要性在一些研究中表现出来,尤其在检测较小的,模糊的和被遮挡的人脸时。CMS-RCNN 使用 Faster R-CNN 在人脸检测任务中结合身体环境信息。Hu 等人针对不同的尺度单独训练了检测器。SSH 在每个预测模块上用大过滤器获取环境信息。FAN 提出了一个 anchor 级的关注机制,通过高亮面部区域的特征来检测被遮挡的人脸。
3 PyramidBox
本章介绍了环境辅助的单步检测器,PyramidBox。3.1 节中简要介绍了网络结构。3.2 节中展示了一个环境辅助的预测模块。3.3 节提出了一个新的anchor方法,称为 PyramidAnchors。3.4 节展示了联合的训练方法包括 data-anchor-sampling 和 max-in-out。(笔者注:max-in-out 实际并不在 3.4 节中,而在 3.2 节中。)
3.1 网络结构
基于 anchor 的拥有复杂 anchor 设计的目标检测框架已被证明在不同层级的特征图上执行预测时,可以有效地处理可变尺度的人脸。同时,FPN 结构在融合高层级和低层级特征时表现出很大的优势。PyramidBox 的结构 (图 1) 使用了与 S 3 F D S^3FD S3FD 相同的扩展 VGG16 主干架构和 anchor 尺度设计,可以生成不同层级的特征图和等比例间距的 anchor。低层级特征金字塔网络 (FPN) 被添加到这个主干架构上,并且用一个环境敏感的预测模块 (CPM) 接受每个检测层的输出,来获得最终的输出。本结构的关键在于我们设计了一种新型的金字塔式的 anchor 方法,它可以在不同层级为每一张人脸生成一系列的 anchor。架构中每个组件的细节如下:
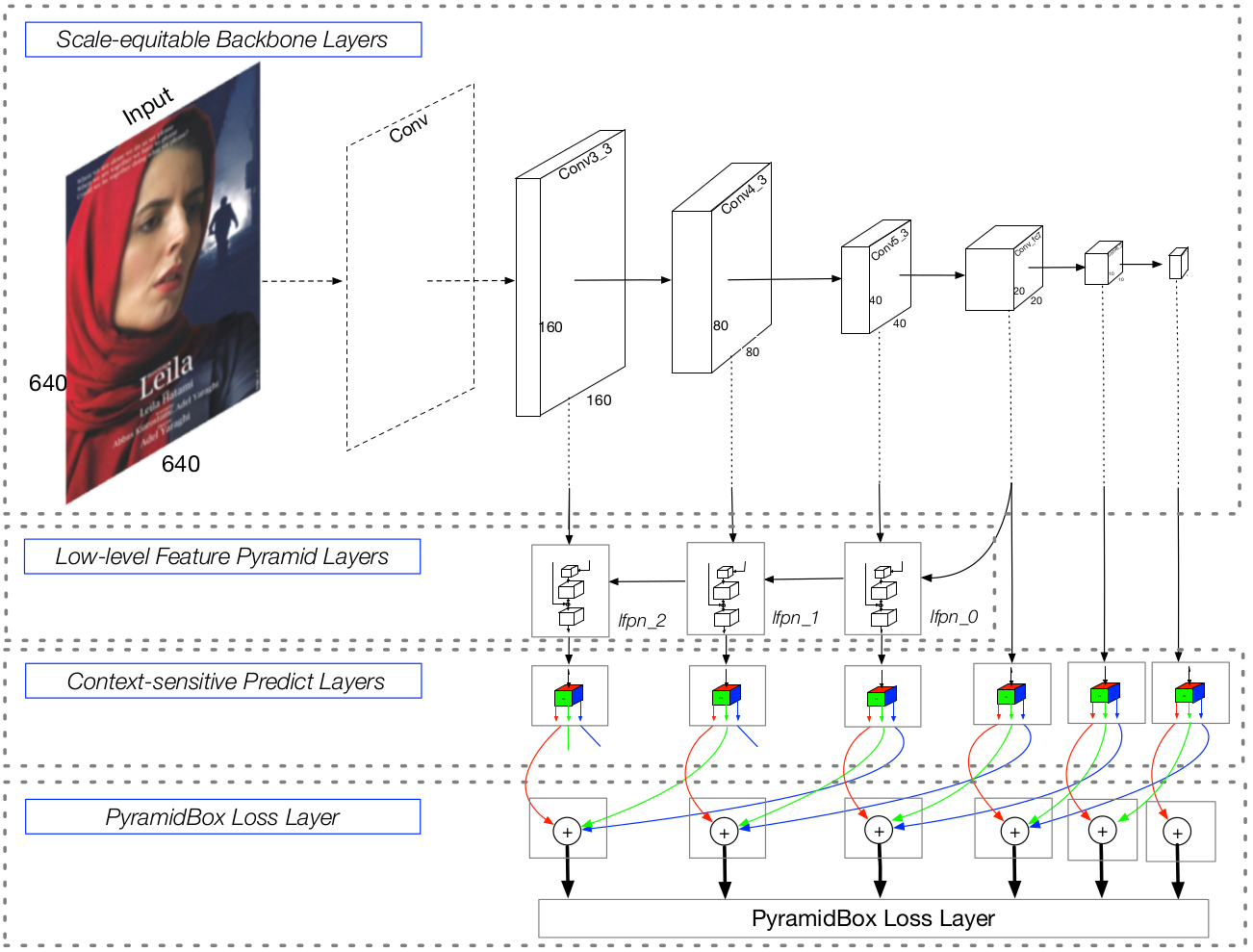
图 1:PyramidBox 架构。它包含尺度合理的主干网络层、低层级特征金字塔网络层 (LFPN)、环境敏感的预测网络层和 PyramidBox 损失层。
尺度合理的主干网络层
我们使用了与 S 3 F D S^3FD S3FD 完全相同的主干网络,包括基础卷积层和额外卷积层。其中基础卷积层即为 VGG16 中的 conv1_1 层到 pool5 层,额外卷积层将 VGG16 中的 fc6 层和 fc7 层转换为 conv_fc 层,又添加了更多的卷积层使网络变得更深。
低层级特征金字塔网络层
为了提高人脸检测器处理不同尺度的人脸的能力,高分辨率的低层级特征扮演着关键角色。因此,很多当前最佳的研究在相同的框架内构建了不同的结构来检测不同尺寸的人脸,其中高层级特征被用于检测尺寸较大的人脸,而低层级特征被用于检测尺寸较小的人脸。为了将高层级特征整合到高分辨率的低层级上,FPN 提出了一种自顶向下的架构来利用所有尺度的高层级语义特征图。最近 FPN 类型的框架在目标检测和人脸检测上都有不错的表现。
众所周知,所有这些研究都是从顶层开始建立 FPN,然而不是所有的高层级特征都一定对检测较小的人脸有帮助。首先,较小的,模糊的,被遮挡的人脸与较大的,清晰的,完整的人脸有不同的纹理特征。所以,直接用高层级特征来提升检测器在较小人脸上的表现是过于简单粗暴的。第二,高层级特征是从缺少环境的区域中提取出来的,并且可能引入噪声信息。比如,在 PyramidBox 的主干层里,层级最高的两层 conv7_2 和 conv6_2 的感受野分别是 724 和 468,而训练图像的输入尺寸是 640。这意味着上面两层只包含大尺度的人脸而且缺少环境特征,所以可能对检测中等和小尺寸的人脸没什么帮助。
我们建立的低层级特征金字塔网络 (LFPN) 提供了另外一个选择。LFPN 是从中间层而不是顶层开始的自上而下的结构,这个中间层的感受野接近输入尺寸的一半。此外,每个 LFPN 块的结构和 FPN 一样,更多细节可见图 2(a)。
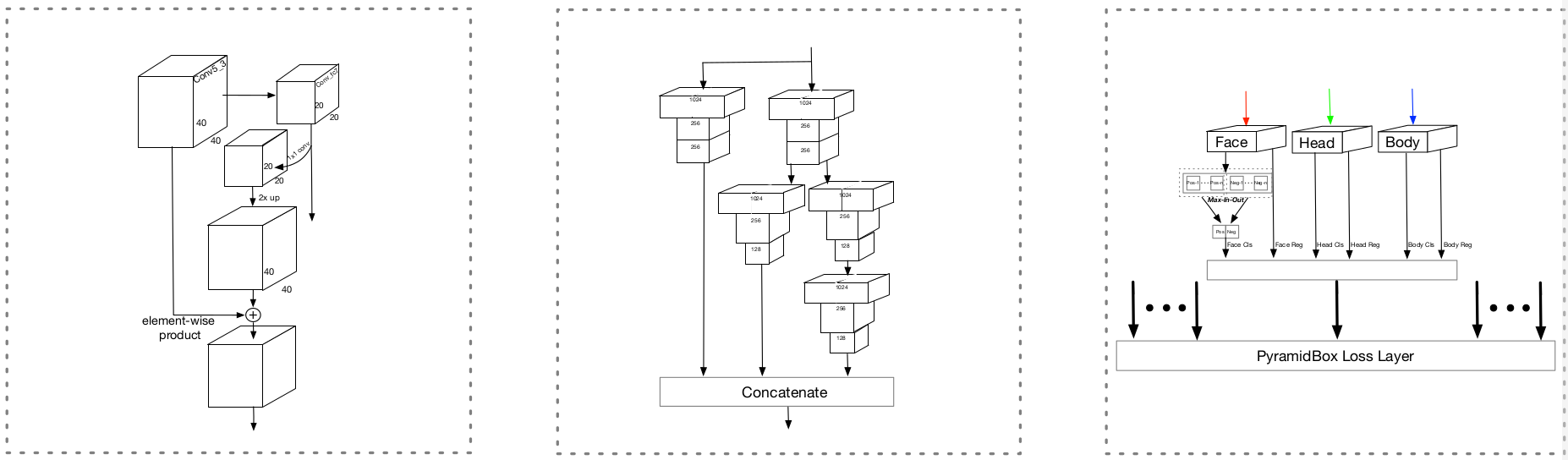
图 2:(a) 特征金字塔网络 (b) 环境敏感的预测模块 © PyramidBox 损失。
金字塔检测层
我们选择 lfpn_2,lfpn_1,lfpn_0,conv_fc7,conv6_2 和 conv7_2 作为检测层,它们的 anchor 尺寸分别为 16,32,64,128,256 和 512。这里 lfpn_2,lfpn_1 和 lfpn_0 是 LFPN 的输出层,分别对应 conv3_3,conv4_3 和 conv5_3。此外,与其他 SSD 类型的方法类似,我们对 LFPN 层使用 L2 归一化。
预测层
每个检测层后面都有一个环境敏感的预测模块 (CPM),详见 3.2 节。注意 CPM 的输出被用于监督pyramid anchors,详见 3.3 节,在我们的实验中 anchor 近似覆盖脸,头和身体区域。第 l l l 个 CPM 的输出尺寸是 w l × h l × c l , ( l = 0 , 1 , . . . , 5 ) w_l \times h_l \times c_l, (l = 0, 1, ..., 5) wl×hl×cl,(l=0,1,...,5),其中 w l = h l = 640 / 2 2 + l w_l = h_l = 640/2^{2+l} wl=hl=640/22+l 是对应的特征尺寸,通道尺寸 c l = 20 c_l = 20 cl=20。这里每个通道的特征分别被用来分类和回归面部,头部和身体。人脸的分类需要 4 ( = c p l + c n l ) ( = cp_l + cn_l) (=cpl+cnl) 个通道,其中 c p l cp_l cpl 和 c n l cn_l cnl 分别是前景和背景的 max-in-out 标签,满足
c p l = { 1 , i f l = 0 , 3 , o t h e r w i s e . cp_l = \begin{cases} 1, &if \ l = 0, \\ 3, &otherwise. \end{cases} cpl={
1,3,if l=0,otherwise.
此外,头部和身体的分类各需要两个通道,面部、头部和身体的定位各需要 4 个通道。
PyramidBox 损失层
对每一个目标人脸,我们有一系列的 pyramid anchors 来同时监督分类和回归任务,详见 3.3 节。我们设计了一个 PyramidBox 损失函数,其中对分类使用 softmax 损失,对回归使用平滑 L1 损失,详见 3.4 节。
3.2 环境敏感的预测模块
预测模块
在原始的基于 anchor 的检测器,比喻 SSD 和 YOLO 中,目标函数被直接应用在选定的特征图上。MS-CNN 中提出,扩大每个任务的子网络可以提高精度。最近,SSH 通过在层上配置更宽的不同步长的卷积预测模块增大了感受野。DSSD 为每个预测模块增加了残差块。实际上,SSH 和 DSSD 分别使预测模块更宽和更深,使预测模块得到更好的特征用于分类和定位。
受 Inception-ResNet 启发,我们当然可以既获得网络变宽的收益又获得网络变深的收益。我们设计了环境敏感的预测模块 (CPM),见图 2(b)。在这个模块中,我们用 DSSD 中的残差预测模块替换了 SSH 中的环境模块的卷积层。这让我们的 CPM 既具备 DSSD 模块方法的所有优势,又从 SSH 环境模块中保留了丰富的环境信息。
Max-in-out
Maxout 的概念由 Goodfellow 等人率先提出。最近, S 3 F D S^3FD S3FD 应用了 max-out 背景标签来减少对较小的负样本的误检。在本研究中,我们在正负样本上都使用这个策略,把它叫做 max-in-out,参见图 2©。我们首先为每个预测模块预测一个 c p + c n c_p + c_n cp+cn 分数,然后选择最大的 c p c_p cp 作为正分数,最大的 c n c_n cn 作为负分数。在我们的实验中,我们设置第一个预测模块中的 c p = 1 , c n = 3 c_p = 1, c_n = 3 cp=1,cn=3,因为较小的anchors有更复杂的背景;然而设置其他预测模块中的 c p = 3 , c n = 1 c_p = 3, c_n = 1 cp=3,c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









