







最近在学习博弈论和DQN时,无意中发现胜者的诅咒和DQN中过估计现象相通。特此记录。
胜者的诅咒

分析这个问题,假设每一个参与拍卖的买家对硬币数量的估计相互独立,并且都愿意出与他估计价值相当的价格。
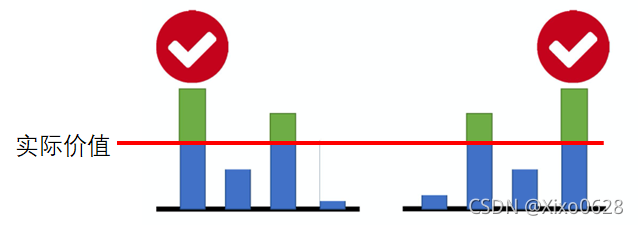
在上图中,红线为物品的实际价值,左右分别为两次拍卖不同买家的出价。因为我们每次都使用“价高者得”的方式,所以最终成功拍走物品的“胜者”永远是心目中对物品估价越多的人。当买家数量较多时,几乎可以肯定,胜者一定是过高估计物品价值的人。(而且是过高估计得最离谱的那个)所以在这个模型中,胜者永远是在做亏本买卖。
DQN
在介绍Double-DQN之前,先回顾一下DQN。
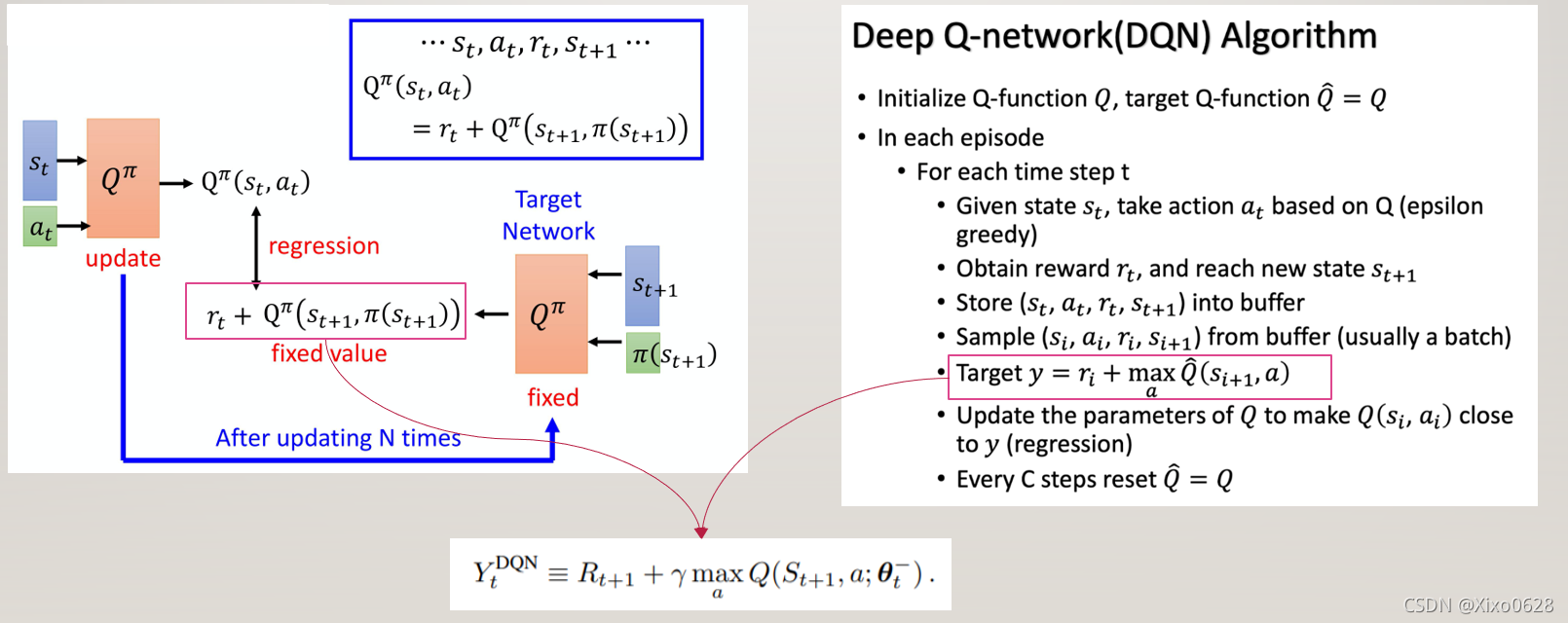
我们先来复习回顾一下DQN的基本算法。右图是伪代码,不作赘述。
在左图中,在我们每个循环更新参数的update网络在左上角,输入当前状态S和需要评估价值的动作a,经过网络即可输出估计的Q值。最后和目标网络计算出的下一时刻的Q值加上当前时刻的回报r相比较,最小化两者之间的差值。并在N次网络参数迭代后,更新target网络的参数为当前update网络。
核心步骤在图中已经标出,在target估算价值时,使用的就是遍历所有动作并求出其中的最大值。
这和拍卖模型非常相似。也就是说,选出的每一步对价值都是过于乐观了,这导致最后对于动作价值的判断过于乐观。即,使用Q网络对动作的估计价值,往往远高于动作真实的价值。
也就是价值的过估计(overestimate)。使用Double DQN可以很大程度上解决这个问题。
Double DQN
参考论文:https://arxiv.org/pdf/1509.06461.pdf
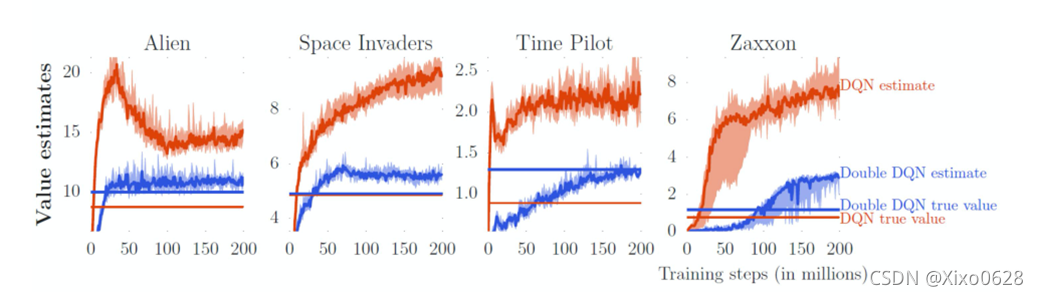
上图展示了四个小游戏中,DQN和double DQN的对比。
不难看出,实际DQN对于动作价值的预估(estimate),远大于行动的真实价值(true value),也就是说DQN网络特别爱吹牛。而DoubleDQN基本上解决了这个问题。并且由于克服了过分乐观的缺点,实际训练出来行为的价值高于DQN,显得double DQN又强又谦虚。
那么这种又强又谦虚的网络是怎么训练的呢?
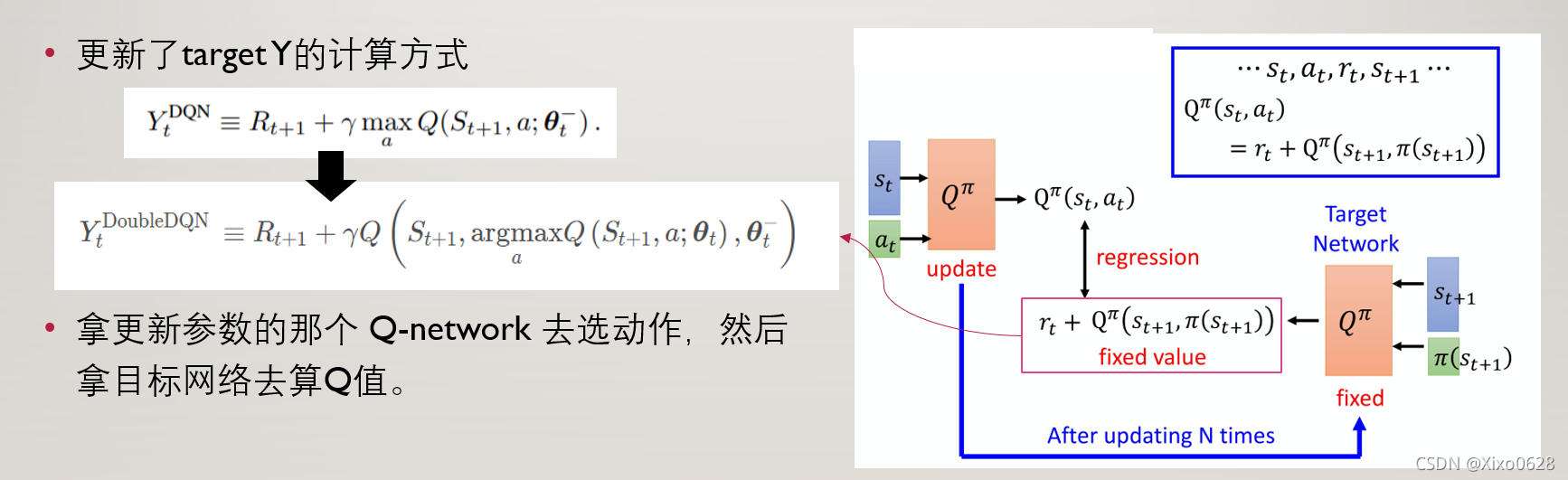
其实这个网络相比DQN并没有改变多少。只改变了一步:原本最优动作选择和最优动作价值都是用目标网络Target Network计算实现的,现在最优动作选择权交给了updateNetwork。如果我们假设两个网络相互独立,那么Target Network对这个最优动作价值的估计就是无偏的。即使可能某些时候会高估,但有时也会低估,最终就不会像原版的DQN一样一直高估。
反思回顾
无意中打通学科的壁垒其实是一件很爽的事情。比如本文的灵感就是用博弈论中的胜者的诅咒解释DQN中状态-动作价值高估。
另外在Double DQN中,价值估计是无偏的充要条件就是两个网络参数相互独立,但这其实是绝对不可能的一件事。因为每过N次迭代,target 网络参数就会被update 网络参数完全替换。也就是说,两个网络其实具有非常强的相似性。
进一步地,也就是说DQN容易高估价值的毛病其实并没有完全被解决。只是从“吹牛大王”级别,降到了“比较自信”级别。实际工程中,更正确地认识动作价值,确实也会一定程度上提高“策略”的强度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











