







要求:
针对实验1和实验2构建的数据集信息分析
设计实现通过数据简介进行大类分类的程序
代码实现:
训练集数据获取:
read_data.py
import json
import pickle
def read_intro():
data = []
trypath=r"E:\Procedure\Python\Experiment\first.json"
filepath=r"E:\Procedure\Python\Experiment\res1.json"
with open(filepath, 'r', encoding='utf-8') as file:
for line in file:
record = json.loads(line)
if record.get('intro')!='':
data.append(record)
return data
def store_model(model):
# 加载模型
file=r'E:\Procedure\Python\Experiment\Machine_Learning\model1.pkl'
try:
# 尝试以 'xb' 模式打开文件,如果文件不存在则创建新文件
with open(file, 'wb') as file:
# 使用 pickle 序列化模型并写入文件
pickle.dump(model, file)
except FileExistsError:
print("File already exists. Cannot overwrite existing file.")
except Exception as e:
print("An error occurred:", e)
# 使用加载的模型进行预测
#predictions = loaded_model.predict(X_test)
def store_report(report):
file=r"E:\Procedure\Python\Experiment\Machine_Learning\class_report.txt"
with open(file,'w')as file:
file.write(report)
return
def get_model():
m_path=r'E:\Procedure\Python\Experiment\Machine_Learning\model1.pkl'
try:
with open(m_path,'rb')as file:
loaded_model=pickle.load(file)
return loaded_model
except Exception as e:
print(e)
return None
训练模型:
多项式朴素贝叶斯模型用于单一标签文本分类
# 导入所需的库
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import read_data
import random
data=read_data.read_intro()
random.shuffle(data)
X = [item['intro'] for item in data]
y = [item['mainclass'] for item in data]
# 文本向量化
vectorizer = TfidfVectorizer()
X_vectorized = vectorizer.fit_transform(X)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_vectorized, y, test_size=0.2, random_state=42)
# 初始化朴素贝叶斯分类器
model = read_data.get_model()
#model = MultinomialNB()
# 训练模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
read_data.store_model(model)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 打印分类报告
print("\nClassification Report:")
report=classification_report(y_test, y_pred,zero_division=0)
print(report)
read_data.store_report(report)
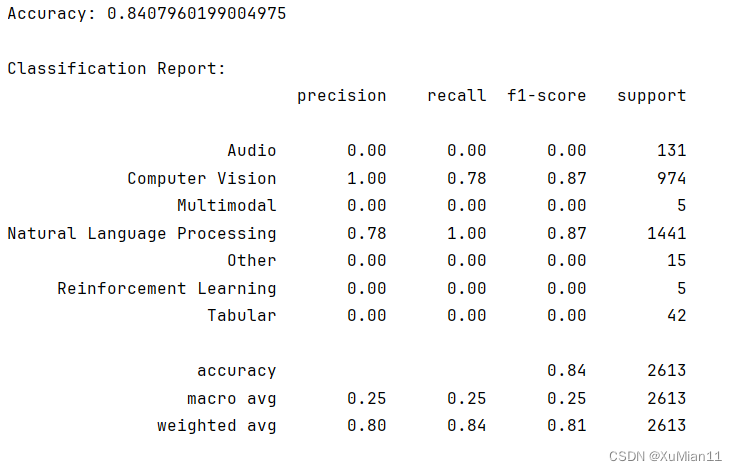
结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









