









我是目录
前言
《MATLAB Deep Learning》,Phil Kim. 这本书实在太适合入门了,作者用平实易懂的语言由浅入深地介绍了深度学习的各个方面。书中并没有太多的公式,配套代码也很简洁。不过,若是想进一步深究背后的数学原理,还得参考其他书籍、文献。
Ch1 - Machine Learning
关于人工智能、机器学习和深度学习的关系,一句话概括就是:“Deep Learning is a kind of Machine Learning, and Machine Learning is a kind of Artificial Intelligence.”
机器学习能解决规则和逻辑推理(如早期的专家系统)解决不了的问题,Machine Learning has been created to solve the problems for which analytical models are hardly available.
机器学习面临的挑战:训练数据与真实数据之间的差异,过拟合 Over-fitting.
过拟合应对方案,为了提高泛化 Generalization 能力:在训练集中留出验证集 Validation,交叉验证 Cross-validation,正则化(这章好像还没讲到)。
机器学习还有三个细分领域:Supervised learning, Unsupervised learning and Reinforcement learning.

分类问题与回归问题:The only difference is the type of correct outputs—classification employs classes, while the regression requires values.
Ch2 - Neural Network
计算机将信息存储在内存单元中的特定位置,而人脑记忆信息靠的是更改神经元之间的联系(方式),人工神经网络的设计 “模拟” 了大脑的这个过程。

神经网络的发展:single-layer neural network, shallow neural network(含隐藏层), deep neural network.
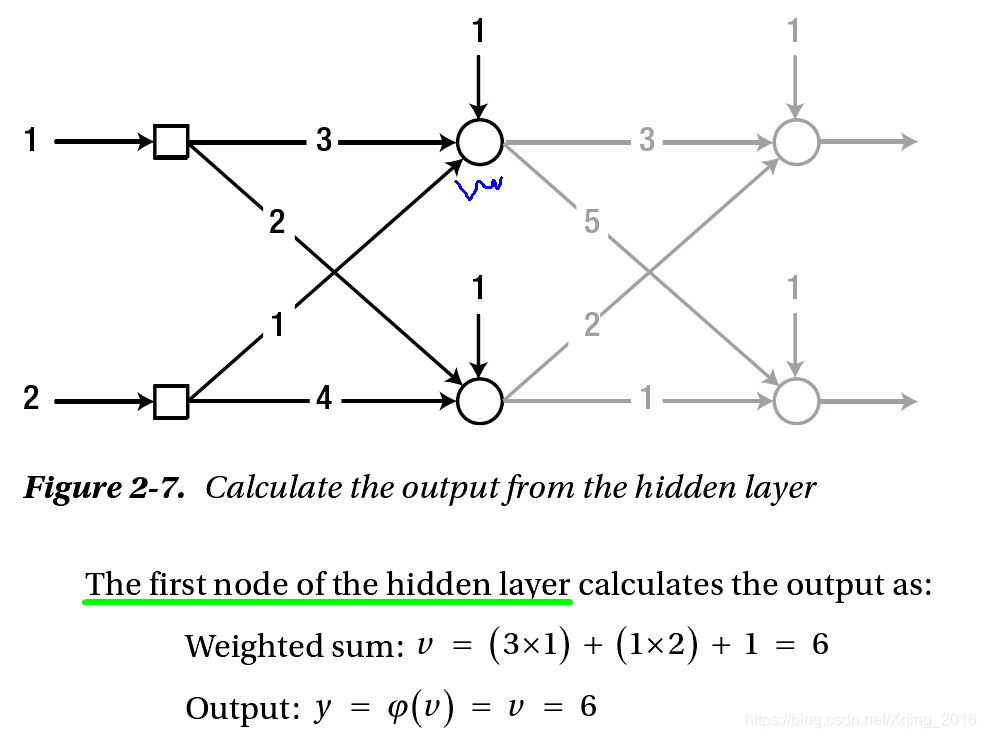
注意,当隐藏层的激活函数是线性函数(如
φ
(
x
)
=
x
\varphi(x) = x
φ(x)=x)时,隐藏层的作用就失效了,这相当于直接从输入层到输出层的线性变换。
delta 法则

考虑损失函数
l
(
x
,
w
i
)
=
1
2
(
d
i
−
y
i
)
2
l(x, w_{i})=\frac{1}{2}(d_{i}-y_{i})^{2}
l(x,wi)=21(di−yi)2,激活函数
φ
(
v
)
=
v
\varphi(v) = v
φ(v)=v,
y
i
=
φ
(
v
i
)
y_{i}=\varphi(v_{i})
yi=φ(vi),
v
i
=
∑
j
=
1
n
w
i
j
x
j
v_{i}=\sum_{j=1}^nw_{ij}x_j
vi=∑j=1nwijxj。其中
d
i
d_{i}
di是样例真实值,
y
i
y_{i}
yi是估计值,
e
i
=
d
i
−
y
i
e_{i}=d_{i}-y_{i}
ei=di−yi是估计误差。那么,
∂
l
∂
w
i
j
=
−
(
d
i
−
y
i
)
φ
′
(
v
i
)
=
−
e
i
x
j
\frac{\partial l}{\partial w_{ij}}=-(d_{i}-y_{i})\varphi^{'}(v_{i})=-e_{i}x_{j}
∂wij∂l=−(di−yi)φ′(vi)=−eixj
由于要向损失减小的方向更新梯度,上述结果取其相反数。可以看出 delta 法则实际上是激活函数为
φ
(
v
)
=
v
\varphi(v) = v
φ(v)=v 时的特例,更为一般的形式为如下:

SGD, Batch, and Mini Batch
随机梯度下降 SGD 即对每一个样例都计算一次梯度,而 Batch 使用所有的训练数据但只更新一次梯度,Mini Batch 是它们二者的折中。

SGD 的收敛速度更快,而 Batch 更加稳定,Mini Batch 结合了二者的优点。
Ch3 - Training of Multi-Layer Neural Network
由于单层神经网络不能解决非线性问题(如 XOR 问题),由此引发多层神经网络的思考。考虑到篇幅过长,这篇博客到此为止。待续…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









