







链表和顺序表的区别
不同点 顺序表 链表 存储空间上 物理上一定连续 逻辑上连续,但物理上不一定连续 随机访问(用下标随机访问) 支持O(1) 不支持:O(N) 任意位置插入或者删除 可能需要搬移元素,效率低O(N) 只需修改指针指向 插入 动态顺序表,空间不够时需要扩容(扩容本身有消耗、空间浪费) 没有容量的概念(按需申请释放) 应用场景 元素高效存储+频繁访问 任意位置插入或删除频繁 缓存利用率(cpu高速缓存) 高 低
- 总结:顺序表在尾插尾删,随机访问时适合使用。
- 链表在中间插入、不需要随机访问时适合使用。
缓存利用率:
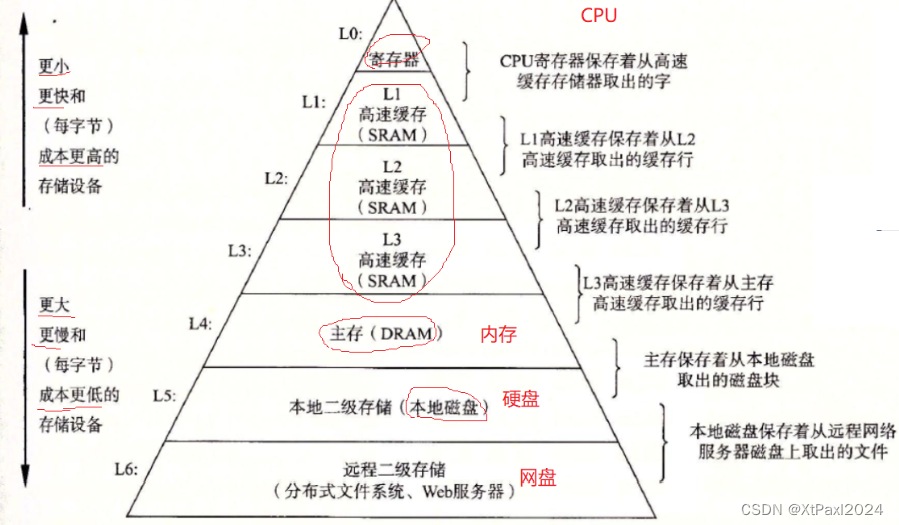
简单解释一下:cpu访问数据嫌内存太慢了,会把数据加载到缓存在访问,不在的话先加载,在的话直接访问,其次cpu读这块数据的时候不会按照需要的长度去读,而是按照cpu的字长去读,比如说它是一辆大巴,拉4个字节也是拉,拉100个字节也是拉,所以它干脆拉100个,因为它觉得你访问当前位置大概率也访问后面的位置,实践当中确实也是这样的,但是这个作用在链表上面就出现了反作用,因为链表是靠地址链接连续的,地址之间可能间距小也可能间距很大,所以不仅每次不命中,还会把没用的东西也弄过去,所以链表的命中率低。
栈的介绍
栈的概念及结构
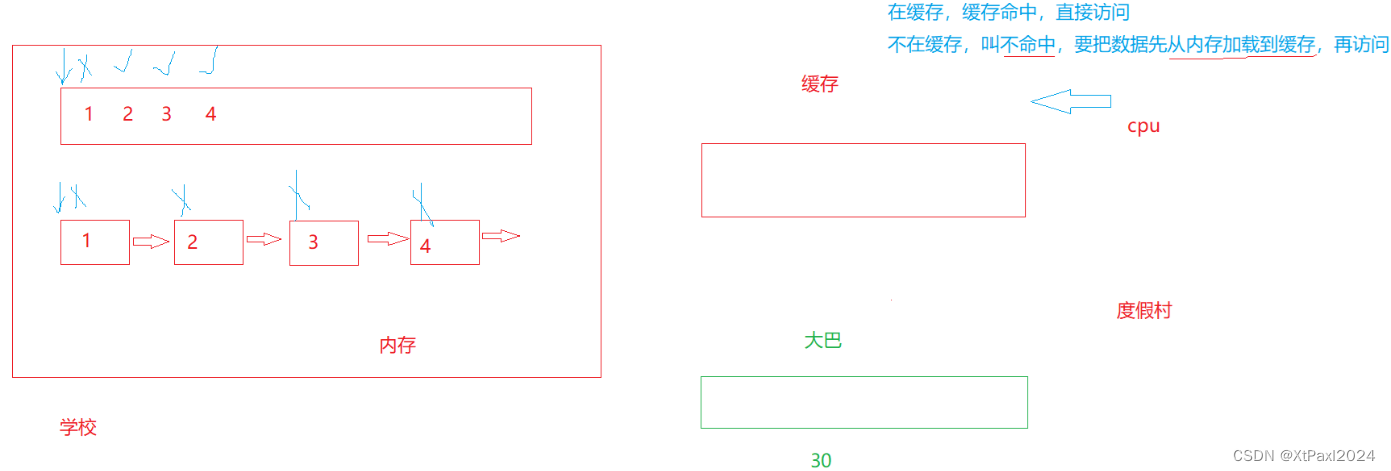
- 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
- 压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
- 出栈:栈的删除操作叫做出栈。出数据也在栈顶。

实现栈的三种形式,双链,单链,数组,哪种更好呢?
- 首先排除双链,因为双向链表里有俩个指针,浪费空间,保存地址的指针只有两种情况,32为环境下占4字节,64位环境下占8字节。
- 单链和数组的区别不大,但因为CPU高速缓存对数组命中率高,栈的插入删除都是在栈顶进行操作的,只在一段,用尾端做栈顶的话,它正好都是完全符合数组的优点,所以选数组,如果没有高速缓存的概念,链表比数组有节省空间的优势。
静态栈和动态栈
- 栈和顺序表一样都有两种实现方式,但因为静态使用起来空间固定不推荐使用,使用动态更灵活。
栈的实现
Stack.h(头文件声明)
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
typedef int STDataType; //将变量类型定义成DataTy 方便更改类变量类型
typedef struct Stack //结构体创建一个栈 需要包括栈的基本内容(栈,栈顶,栈的容量)。
{
STDataType* a; //栈
int top; //标识栈顶数据
int capacity; //用计数的方式来计算结构体内的容量大小
}ST; //typedef将结构体类型重命名位ST,方便使用
void STInit(ST* pst); //初始化
void STDesTroy(ST* pst); //销毁
void Push(ST* pst,STDataType x);//插入
void STPop(ST* pst); //删除数据、出栈
STDataType STTop(ST* pst); //获取栈顶数据
bool STEmpty(ST* pst); //判断栈里为不为空
int STSize(ST* pst); //获取数据个数栈顶在哪呢?
- 栈顶在哪是根据底层结构定义的:
- 数组的栈顶是尾部。
链表的栈顶是头部,因为链表是通过next指针找到下一个节点位置的,从后找前一个节点会很麻烦,栈是后进先出,把要存储的值逆置存到节点中,才能实现先出去的是最后一个值,所以要从链表尾节点开始插入,自然头部就是栈顶了 。
Stack.c
初始化栈
首先,我们需要用结构体创建一个栈,这个结构体需要包括栈的基本内容(栈,栈顶,栈的容量),在头文件里已经创建好了这里再写一下。
typedef int STDataType;//栈中存储的元素类型(这里用整型举例)
typedef struct Stack
{
STDataType* a;//栈
int top;//栈顶
int capacity;//容量,方便增容
}ST;
然后,我们需要一个初始化函数,对刚创建的栈进行初始化。
//初始化栈
void STInit(ST* pst)
{
assert(pst);
pst->a = NULL; //初始化栈可存储0个元素(可以先开 也可以不开)
pst->top = pst->capacity = 0; //初始时栈中无元素,栈顶为0;容量为0;
}top初始化为-1和初始化为0的区别:
这里要先思考一个问题,top指向哪里呢?是尾还是尾的下一个?(尾指的是栈顶)
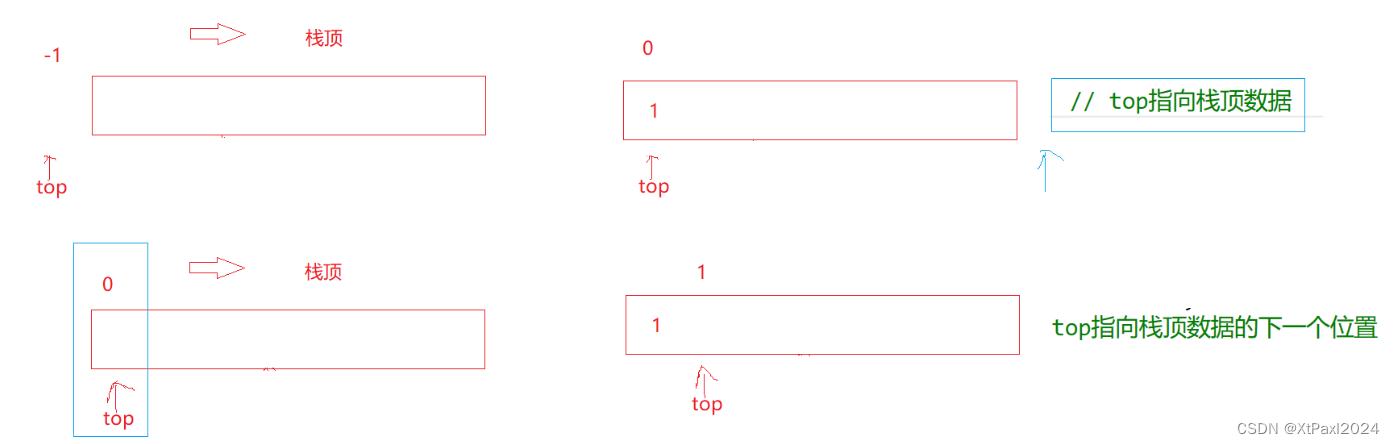
- top初始化为-1,随着存入数据指针++,指向的是栈顶数据,即栈顶数据的下标。
- top初始化为0,和size没什么区别,指向的是栈顶数据的下一个位置。
- 注:数组元素下标是从0开始的。
销毁栈
因为栈的内存空间是动态开辟出来的,当我们使用完后必须释放其内存空间,避免内存泄漏。
//销毁栈
void StackDestroy(Stack* pst)
{
assert(pst);
free(pst->a);//释放栈
pst->a = NULL;//及时置空
pst->top = 0;//栈顶置0
pst->capacity = 0;//容量置0
}
入栈
//入栈
void StackPush(ST* pst, STDataType x)
{
assert(pst);
if (pst->top == pst->capacity)//栈已满,需扩容
{
STDataType* tmp = (STDataType*)realloc(pst->a, sizeof(STDataType)*pst->capacity * 2);
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
pst->a = tmp;
pst->capacity *= 2;//栈容量扩大为原来的两倍
}
pst->a[pst->top] = x;//栈顶位置存放元素x
pst->top++;//栈顶上移
}
- 插入之前要先判断空间够不够,当top和capacity相等的时候就需要扩容,注意 :这里如果top指向的是栈顶数据就需要+1才跟容量相等,因为数组下标从0开始。
- 当空间满了时,先定义一个新capacity保存pst->capacity的值也就是定义一个新容量保存原有栈的容量,防止开辟失败原容量被改变,但因为初始化容量为0的话无法二倍扩容,就需要用三目操作符判断容量是否为0为0的话给个4字节大小的空间,不为0扩容2倍,再定义个临时接收开辟空间地址的指针,防止原有空间因为开辟失败而被改变,再判断开辟是否成功,成功后将临时容量迭给原有的容量和栈指针。
-
pst->a[pst->top] = x;//栈顶位置存放元素x pst->top++;//栈顶上移 - 这里分两种情况:top初始化为-1时需要先++再赋值,因为top指向的是栈顶。
- top初始化为0是先赋值再++,因为top指向的是栈顶的下一个位置。
出栈
出栈操作比较简单,即让栈顶的位置向下移动一位即可。但需检测栈是否为空,若为空,则不能进行出栈操作。
//出栈
void StackPop(ST* pst)
{
assert(pst);
assert(!StackEmpty(pst));//检测栈是否为空
pst->top--;//栈顶下移
}
获取栈顶元素
获取栈顶元素,即获取栈的最上方的元素。若栈为空,则不能获取。
//获取栈顶元素
STDataType StackTop(ST* pst)
{
assert(pst);
assert(!StackEmpty(pst));//检测栈是否为空
return pst->a[pst->top - 1];//返回栈顶元素
}
检测栈是否为空
检测栈是否为空,即判断栈顶的位置是否是0即可。若栈顶是0,则栈为空。
//检测栈是否为空
bool StackEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;
}
获取栈中有效元素个数
因为top记录的是栈顶,使用top的值便代表栈中有效元素的个数。
//获取栈中有效元素个数
int StackSize(ST* pst)
{
assert(pst);
return pst->top;//top的值便是栈中有效元素的个数
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









