






强化学习(Reinforcement Learning,RL)作为求解最优控制问题的核心方法之一,其算法设计的关键在于对最优性条件的深刻理解与巧妙运用。目前,最优控制领域存在两类经典最优性条件:庞特里亚金最大值原理(Pontryagin’s maximum principle, PMP)和哈密顿-雅克比-贝尔曼(Hamilton-Jacobi-Bellman, HJB)方程。它们分别从“极值控制”和“动态规划”的视角刻画了最优策略的数学本质为众多主流控制算法奠定了理论基础。值得注意的是,现代强化学习的核心——贝尔曼(Bellman)方程,正是HJB方程在离散情况下的具体表现形式。
然而令人疑惑的是,最大值原理在强化学习中的应用却长期处于边缘地位。这一现象背后存在双重原因:一方面,PMP仅描述“最优控制”,而RL在训练过程中需要迭代提升“非最优策略”;另一方面,PMP适用于“开环控制”,而RL倾向于采用“闭环策略”(即动作与状态显式相关)。针对这一理论鸿沟,本研究从哈密顿力学视角重构PMP框架,将其拓展至非最优策略与闭环控制的情况,通过建立协态变量与价值函数偏导数之间的等价性,揭示PMP与HJB方程的内在统一性。
庞特里亚金最大值原理(PMP)
最大值原理由苏联数学家庞特里亚金(Pontryagin)等人在1960年提出,它在古典变分法上进行了改进,证明了最优控制量 使哈密顿量
取得全局最大值。PMP的数学表述如下:
令 为最优控制函数,
为对应的最优轨迹,则存在函数
,使得对任意
,如下条件均成立:
(1) 满足正则方程:
其中 称为哈密顿函数,
为系统的损失函数,
为动力学方程。变量
被称为协态变量。
(2) 对于给定时间 ,函数
作为
的函数在
处取得最大值,即:
哈密顿-雅克比-贝尔曼(HJB)方程
HJB方程起源于贝尔曼对多步决策问题的研究时提出的动态规划思想。随后,卡尔曼发现了此方程与哈密顿-雅可比方程的相似结构,并将其首次命名为HJB方程。贝尔曼首次引入了价值函数的概念,在有限时域问题中,该函数被定义为:
当策略达到最优时,价值函数满足如下偏微分方程:
重定义协态变量
为了扩展最大值原理中的协态变量,研究者将最优控制问题与带有非完整约束的拉格朗日力学系统建立了对偶关系。通过将最优控制下的轨迹视为拉格朗日力学的真实轨迹,非最优轨迹视为可能轨迹,并分别采用Weierstrass条件和固定控制量条件作为拉格朗日系统的非完整约束,可以自然地将协态变量在开环、闭环、最优和非最优下重新定义为系统状态导数的 Legendre 变换:
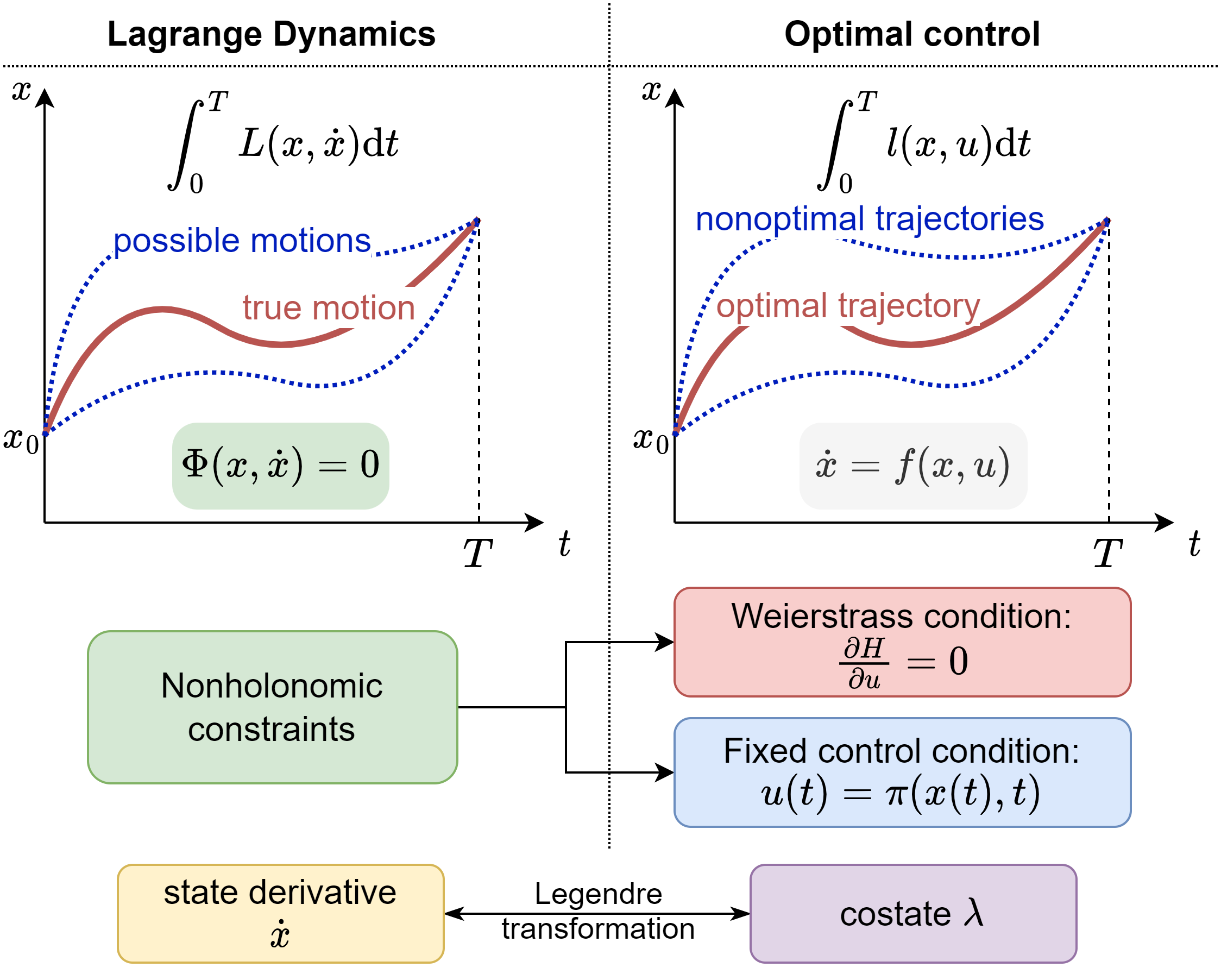
在这一定义下,状态变量 和协态变量
在任意时刻都满足正则方程:
最优控制问题的守恒性关系
最优控制问题中存在两种守恒关系:哈密顿函数守恒和辛形式守恒。前者仅在策略达到最优时成立。
当策略 为非最优策略时,哈密顿量
随时间的导数为:
该式说明,若非最优策略与时间显式相关,则哈密顿函数在状态变量演化期间不守恒。在哈密顿系统中,辛形式是一个非退化的 2-形式,描述了系统的状态变量与协态变量之间形成的平行四边形的有向面积:
其中 表示
的单位矩阵。
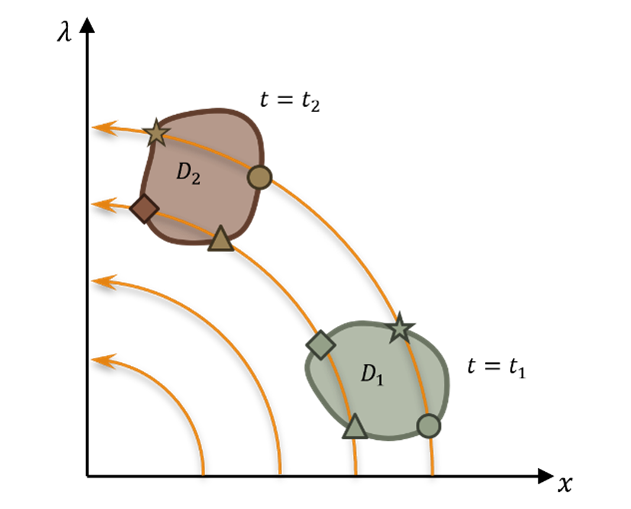
这一变量在状态和协态变量演化的过程中保持不变。如图2所示,假设 时刻的各状态构成的区域为
,
时刻的各状态构成的区域为
,则在沿着系统轨迹进行演化时,均有
。该守恒性条件在最优和非最优情况下都成立,可以为算法设计提供额外的约束条件,从而增强算法迭代的稳定性。
PMP与HJB方程的内在统一性
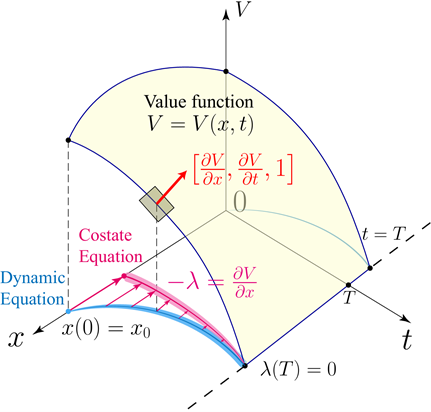
研究发现,PMP中的协态变量与HJB方程中的价值函数
对状态变量
的导数的相反数相等,即:
通过示意图,可以更清楚地看到动力学方程、协态方程和价值函数的关系:蓝线为动力学方程,系统状态从演化至
,在每个时刻$t$,都存在一个对应的协态变量
,该变量的定义即为状态变量导数
的Legendre变换,且演化规律服从正则方程。价值函数
作为
的多元函数,其表面上任意一点的法线方向即为:
协态变量与价值函数导数的关系表明,法线方向在沿
轴方向的投影等于协态变量
的相反数。值得注意的是,该性质不仅存在于最优策略和最优轨迹上,同时对于任意策略和由其产生的轨迹上也成立。
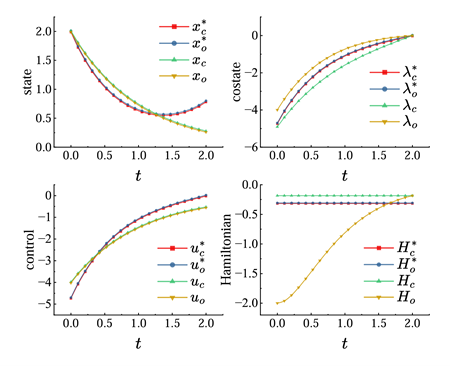
仿真数值验证
以线性二次调节器(LQR)问题为例,比较了最优闭环、最优开环、非最优闭环和非最优开环四种控制策略下的状态、协态、控制量和哈密顿量的变化曲线。实验结果表明,在最优情况下,无论开环还是闭环控制,协态变量和哈密顿量都保持不变。而非最优情况下,协态变量和哈密顿量表现出不同的动态特性,验证了理论模型的正确性。
总结
综上所述,研究分析了强化学习和最优控制领域中两个关键的最优性条件——庞特里亚金最大值原理(PMP)和哈密顿-雅可比-贝尔曼(HJB)方程之间的联系。通过将最优控制问题视为非完整拉格朗日系统,将协态变量重新定义为状态导数的Legendre变换,并在最优和非最优、开环和闭环控制等多种情况下,证明了价值函数与协态变量之间的内在等价性。这一发现不仅揭示了最优控制问题中的守恒性质,还为算法设计提供了全新的视角。通过在数值实验中验证理论结果,该研究为开发更高效的强化学习算法奠定了坚实的理论基础,有望在自动驾驶、机器人控制等多个领域发挥重要作用。
参考文献
[1] Zhang X, Lyu Y, Li S E, et al. Understanding Connection between PMP and HJB equations from the Perspective of Hamilton Dynamics[J]. IEEE Transactions on Artificial Intelligence, 2025: 1-11.
[2] Lyu Y, Zhang X, Li S E, et al. Conformal Symplectic Optimization for Stable Reinforcement Learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024: 1-15.
[3] Zhan G, Jiang Y, Duan J, et al. Continuous-Time Policy Optimization[C]//2023 American Control Conference (ACC). 2023: 3382-3388.
[4] Li S E. Reinforcement learning for sequential decision and optimal control[M]. Singapore: Springer Verlag, 2023.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









