







254: 翻煎饼
题目描述
麦兜最喜欢的食物是煎饼,每次在街上看到煎饼摊的时候都会在那里停留几分钟。最吸引麦兜还是煎饼师傅那一手熟练的翻煎饼的技术,一堆煎饼在那里,师傅只需要用铲子翻几下,就让煎饼整齐的叠在了一起。 这天,为了庆祝麦兜被保送上研究生,他从煎饼师傅那里买回来一些煎饼请客。但是麦兜买回的煎饼大小不一,麦兜太想吃煎饼了,他想吃这些煎饼中最大的那个。麦兜还知道同学们也很喜欢煎饼,为了表示他的诚意,他想让同学们先吃,麦兜最后吃,因此,麦兜想把煎饼按照从小到大的顺序叠放在一起,大的在最下面。这样麦兜就可以在最后拿到最大的那一块煎饼了。 现在请你帮助麦兜用煎饼师傅翻煎饼的方法把麦兜买的煎饼从小到大的叠在一起。煎饼师傅的方法是用铲子插入两块煎饼之间,然后将铲子上的煎饼翻一转,这样铲子上第一个煎饼就被翻到了顶上,而原来顶上的煎饼则被翻到了刚才插入铲子的地方。麦兜希望这样翻煎饼的次数最少。
输入
输入包括两行,第一行是一个整数n(1<=n<=1000),表示煎饼的个数,接下来的一行有n个不相同的整数,整数间用空格隔开,每个整数表示煎饼的大小(直径),左边表示顶部,右边表示底部。
输出
输出为一行,翻煎饼的最少次数
样例输入
5 5 4 2 3 1
样例输出
4
#include<bits/stdc++.h>
using namespace std;
int n,sum=0,a[1000];
int main()
{
cin>>n;
for(int i=0;i<n;i++) cin>>a[i];
while(n>1)
{
int maxn=0;
for(int i=0;i<n;i++)
if(a[i]>=a[maxn]) maxn=i;
if(maxn==0)
{
sum+=1;
reverse(a,a+n);
}
else if(maxn!=n-1)
{
sum+=2;
reverse(a,a+maxn+1);
reverse(a,a+n);
}
n--;
}
cout<<sum<<endl;
}348: 花生采摘
题目描述
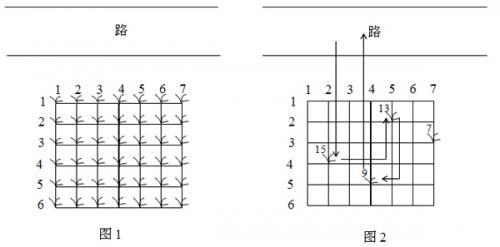
鲁宾逊先生有一只宠物猴,名叫多多。这天,他们两个正沿着乡间小路散步,突然发现路边的告示牌上贴着一张小小的纸条:“欢迎免费品尝我种的花生!——熊字”。 鲁宾逊先生和多多都很开心,因为花生正是他们的最爱。在告示牌背后,路边真的有一块花生田,花生植株整齐地排列成矩形网格(如图1)。
有经验的多多一眼就能看出,每棵花生植株下的花生有多少。为了训练多多的算术,鲁宾逊先生说:“你先找出花生最多的植株,去采摘它的花生;然后再找出剩下的植株里花生最多的,去采摘它的花生;依此类推,不过你一定要在我限定的时间内回到路边。” 我们假定多多在每个单位时间内,可以做下列四件事情中的一件:
1) 从路边跳到最靠近路边(即第一行)的某棵花生植株;
2) 从一棵植株跳到前后左右与之相邻的另一棵植株;
3) 采摘一棵植株下的花生;
4) 从最靠近路边(即第一行)的某棵花生植株跳回路边。
现在给定一块花生田的大小和花生的分布,请问在限定时间内,多多最多可以采到多少个花生?注意可能只有部分植株下面长有花生,假设这些植株下的花生个数各不相同。
例如在图2所示的花生田里,只有位于(2, 5), (3, 7), (4, 2), (5, 4)的植株下长有花生,个数分别为13, 7, 15, 9。沿着图示的路线,多多在21个单位时间内,最多可以采到37个花生。
输入
输入的第一行包括三个整数,M, N和K,用空格隔开;表示花生田的大小为M * N(1 <= M, N <= 20),多多采花生的限定时间为K(0 <= K <= 1000)个单位时间。接下来的M行,每行包括N个非负整数,也用空格隔开;第i + 1行的第j个整数Pij(0 <= Pij <= 500)表示花生田里植株(i, j)下花生的数目,0表示该植株下没有花生。
输出
输出包括一行,这一行只包含一个整数,即在限定时间内,多多最多可以采到花生的个数。
样例输入
6 7 21 0 0 0 0 0 0 0 0 0 0 0 13 0 0 0 0 0 0 0 0 7 0 15 0 0 0 0 0 0 0 0 9 0 0 0 0 0 0 0 0 0 0
样例输出
37
#include <bits/stdc++.h>
using namespace std;
int m,n,k,MaxNum=0,a[25][25];
void Func(int x,int y,int TimeLimit)
{
int Max=-0x3f3f3f3f,X_max,Y_max,NeedTime;
for(int i=1;i<=m;i++)
for(int j=1;j<=n;j++)
if(a[i][j]>Max)
{
Max=a[i][j];
X_max=i;
Y_max=j;
}
if(y==0) NeedTime=abs(X_max-x)+1;
else NeedTime=abs(X_max-x)+abs(Y_max-y)+1;
if((NeedTime+X_max)>TimeLimit||a[X_max][Y_max]==0) return;
else
{
MaxNum+=a[X_max][Y_max];
a[X_max][Y_max]=0;
Func(X_max,Y_max,TimeLimit-NeedTime);
}
}
int main()
{
cin>>m>>n>>k;
for(int i=1;i<=m;i++)
for(int j=1;j<=n;j++) cin>>a[i][j];
Func(0,0,k);
cout<<MaxNum<<endl;
return 0;
}480: Locker doors
题目描述
There are n lockers in a hallway numbered sequentially from 1 to n. Initially, all the locker doors are closed. You make n passes by the lockers, each time starting with locker #1. On the ith pass, i = 1, 2, ..., n, you toggle the door of every ith locker: if the door is closed, you open it, if it is open, you close it. For example, after the first pass every door is open; on the second pass you only toggle the even-numbered lockers (#2, #4, ...) so that after the second pass the even doors are closed and the odd ones are opened; the third time through you close the door of locker #3 (opened from the first pass), open the door of locker #6 (closed from the second pass), and so on. After the last pass, which locker doors are open and which are closed? How many of them are open? Your task is write a program to output How many doors are open after the last pass? Assumptions all doors are closed at first.
输入
a positive numbers n, total doors. n<=100000
输出
a positive numbers ,the total of doors opened after the last pass.
样例输入
10
样例输出
3
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;cin>>n;
cout<<(int)sqrt(n)<<endl;
}536: The Josephus Problem
题目描述
The problem is named after Flavius Josephus, a Jewish historian who participated in and chronicled the Jewish revolt of 66-70C.E. against the Romans. Josephus, as a general, managed to hold the fortress of Jotapata for 47days, but after the fall of the city he took refuge with 40 diehards in a nearby cave. There the rebels voted to perish rather than surrender. Josephus proposed that each man in turn should dispatch his neighbor, the order to be determined by casting lots. Josephus contrived to draw the last lot, and as one of the two surviving men in the cave, he prevailed upon his intended victim to surrender to the Romans. Your task:computint the position of the survivor when there are initially n people.
输入
a Positive Integer n is initially people. n< = 50000
输出
the position of the survivor
样例输入
6
样例输出
5
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n,f=0;
cin>>n;
for(int i=1;i<=n;i++) f=(f+2)%i;
cout<<f+1<<endl;
}541: 排列的字典序问题
题目描述
n个元素{1,2,..., n }有n!个不同的排列。将这n!个排列按字典序排列,并编号为0,1,…,n!-1。每个排列的编号为其字典序值。例如,当n=3时,6 个不同排列的字典序值如下:
0 1 2 3 4 5
123 132 213 231 312 321
任务:给定n 以及n 个元素{1,2,..., n }的一个排列,计算出这个排列的字典序值,以及按字典序排列的下一个排列。
输入
第1 行是元素个数n(n < 15)。接下来的1 行是n个元素{1,2,..., n }的一个排列。
输出
第一行是字典序值,第2行是按字典序排列的下一个排列。
样例输入
8 2 6 4 5 8 1 7 3
样例输出
8227 2 6 4 5 8 3 1 7
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n,sum=0;
cin>>n;
int a[n],b[n]={0};
for(int i=0;i<n;i++) cin>>a[i];
for(int i=0;i<n;i++)
for(int j=i+1;j<n;j++)
if(a[i]>a[j]) b[i]++;
for(int i=0;i<n;i++)
{
int res=b[i];
for(int j=1;j<=n-1-i;j++) res*=j;
sum+=res;
}
cout<<sum<<endl;
int left,right;
for(int i=n-1;i>=0;i--)
if(a[i-1]<a[i])
{
left=i-1;
break;
}
for(int i=n-1;i>=0;i--)
if(a[i]>a[left])
{
right=i;
break;
}
swap(a[left],a[right]);
for(int i=left+1;i<n;i++)
for(int j=i+1;j<n;j++)
if(a[i]>a[j]) swap(a[i],a[j]);
for(int i=0;i<n;i++) cout<<a[i]<<" ";
cout<<endl;
return 0;
}
342: 变位词
题目描述
如果两个单词的组成字母完全相同,只是字母的排列顺序不一样,则它们就是变位词,两个单词相同也被认为是变位词。如tea 与eat , nic 与cin, ddc与dcd, abc与abc 等。你的任务就是判断它们是否是变位词。
输入
第一行一个N,表示下面有N行测试数据。每行测试数据包括两个单词,如tea eat ,它们之间用空格割开
输出
对于每个测试数据,如果它们是变位词,输出Yes,否则输出No.
样例输入
3 tea eat ddc cdd dee dde
样例输出
Yes Yes No
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
char a[100],b[100];
cin>>n;
for(int i=0;i<n;i++)
{
cin>>a>>b;
int la=strlen(a);
int lb=strlen(b);
int flag=0;
int c[26]={0},d[26]={0};
if(la!=lb) cout<<"No"<<endl;
else
{
for(int j=0;j<la;j++)
{
c[a[j]-'a']++;
d[b[j]-'a']++;
}
for(int k=0;k<26;k++)
if(c[k]!=d[k]) flag++;
if(flag>0) cout<<"No"<<endl;
else cout<<"Yes"<<endl;
}
}
return 0;
}
413: Quick Sort
题目描述
Quicksort is a well-known sorting algorithm developed by C. A. R.
Hoare that, on average, makes Θ(n log n) comparisons to sort n items. However, in the worst case, it makes Θ(n2) comparisons. Typically, quicksort is significantly faster in practice than other Θ(n log n) algorithms, because its inner loop can be efficiently implemented on most architectures, and in most real-world data it is possible to make design choices which minimize the possibility of requiring quadratic time.
Quicksort sorts by employing a divide and conquer strategy to divide a list into two sub-lists.
The steps are:
1. Pick an element, called a pivot, from the list.
2. Reorder the list so that all elements which are less than the pivot come before the pivot and so that all elements greater than the pivot come after it (equal values can go either way). After this partitioning, the pivot is in its final position. This is called the partition operation.
3. Recursively sort the sub-list of lesser elements and the sub-list of greater elements. The base case of the recursion are lists of size zero or one, which are always sorted. The algorithm always terminates because it puts at least one element in its final place on each iteration (the loop invariant).
Quicksort in action on a list of random numbers. The horizontal lines are pivot values. Write a program to sort ascending int number by QuickSort ,n less than 50000.
输入
two lows, the first low is numbers , less and equal than 50000. the second low is a set integer numbers
输出
a set integer numbers of sort ascending
样例输入
10 4 2 1 5 7 6 9 8 0 3
样例输出
0 1 2 3 4 5 6 7 8 9
#include<bits/stdc++.h>
using namespace std;
void quicksort(int left,int right,int *arr)
{
if(left>=right) return;
int i,j,t;
i=left;
j=right;
t=arr[left];
while(i<j)
{
while(i<j&&arr[j]>=t) j--;
arr[i]=arr[j];
while(i<j&&arr[i]<=t) i++;
arr[j]=arr[i];
}
arr[i]=t;
quicksort(left,i,arr);
quicksort(i+1,right,arr);
}
int main()
{
int n;
cin>>n;
int a[n];
for(int i=0;i<n;i++) cin>>a[i];
quicksort(0,n-1,a);
for(int i=0;i<n;i++) cout<<a[i]<<' ';
cout<<endl;
return 0;
}446: 合并排序
题目描述
这是一个很简单的排序题目. 为了锻炼大家对不同算法的了解,请大家用归并排序法对此题进行解答. 对一组整数数列A[1],A[2],A[3]......A[N]进行排序,按照从小到大的顺序输出.
输入
本题只有一组测试数据,在输入的第一行输入N(表示整数数列的大小)(N < 1000) 接下来N行输入N个整数,每一行一个整数.
输出
对已经排好序的数从小到大依次输出,每两个数之间用两个空格隔开,且每输出10个数换行.
样例输入
12 45 545 48 47 44 45 4857 58 57 485 1255 42
样例输出
42 44 45 45 47 48 57 58 485 545 1255 4857
#include<bits/stdc++.h>
using namespace std;
void merge(int *a,int left,int mid,int right,int *temp)
{
int i=left;
int j=mid+1;
int t=0;
while(i<=mid&&j<=right)
{
if(a[i]<=a[j]) temp[t++]=a[i++];
else temp[t++]=a[j++];
}
while(i<=mid) temp[t++]=a[i++];
while(j<=right) temp[t++]=a[j++];
for(i=0;i<t;i++) a[left+i]=temp[i];
}
void merge_sort(int *temp,int *a,int left,int right)
{
if(left<right)
{
int mid=left+(right-left)/2;
merge_sort(temp,a,left,mid);
merge_sort(temp,a,mid+1,right);
merge(a,left,mid,right,temp);
}
}
int main()
{
int n;
cin>>n;
int a[n];
for(int i=0;i<n;i++) cin>>a[i];
int temp[1000]={0};
merge_sort(temp,a,0,n-1);
for(int i=0;i<n;i++)
{
if((i+1)%10==0||i==n-1) cout<<a[i]<<endl;
else cout<<a[i]<<" ";//两个空格
}
return 0;
}493: PostOffice
题目描述
在一个按照东西和南北方向划分成规整街区的城市里,n个居民点散乱地分布在不同的街区中。用x 坐标表示东西向,用y坐标表示南北向。各居民点的位置可以由坐标(x,y)表示。 街区中任意2 点(x1,y1)和(x2,y2)之间的距离可以用数值|x1-x2|+|y1-y2|度量。 居民们希望在城市中选择建立邮局的最佳位置,使n个居民点到邮局的距离总和最小。 任务:给定n 个居民点的位置,编程计算n 个居民点到邮局的距离总和的最小值。
输入
第1 行是居民点数n,1 < = n < =10000。接下来n 行是居民点的位置,每行2 个整数x 和y,-10000 < =x,y < =10000。
输出
n 个居民点到邮局的距离总和的最小值。
样例输入
5 1 2 2 2 1 3 3 -2 3 3
样例输出
10
#include<bits/stdc++.h>
using namespace std;
int main()
{
int x[10000],y[10000];
int n,sum=0;
cin>>n;
for(int i=0;i<n;i++) cin>>x[i]>>y[i];
sort(x,x+n);
sort(y,y+n);
int X=x[n/2],Y=y[n/2];
for(int i=0;i<n;i++) sum+=abs(x[i]-X)+abs(y[i]-Y);
cout<<sum<<endl;
return 0;
}
794: 最近对问题
题目描述
设p1=(x1, y1), p2=(x2, y2), …, pn=(xn, yn)是平面上n个点构成的集合S,设计算法找出集合S中距离最近的点对。
输入
多组测试数据,第一行为测试数据组数n(0<n≤100),每组测试数据由两个部分构成,第一部分为一个点的个数m(0<m≤1000),紧接着是m行,每行为一个点的坐标x和y,用空格隔开,(0<x,y≤100000)
输出
每组测试数据输出一行,为该组数据最近点的距离,保留4为小数。
样例输入
2 2 0 0 0 1 3 0 0 1 1 1 0
样例输出
1.0000 1.0000
#include<bits/stdc++.h>
#define INF 0x3f3f3f3f
using namespace std;
double Distance(double x1,double y1,double x2,double y2)
{
double dis=sqrt((x1-x2)*(x1-x2)+(y1-y2)*(y1-y2));
return dis;
}
int main()
{
int n,m;
double x1[1001],y1[1001];
cin>>n;
while(n--)
{
cin>>m;
for(int i=0;i<m;i++) cin>>x1[i]>>y1[i];
double min=INF;
double t;
for(int i=0;i<m;i++)
for(int j=i+1;j<m;j++)
{
t=Distance(x1[i],y1[i],x1[j],y1[j]);
if(t<min) min=t;
}
cout<<fixed<<setprecision(4)<<min<<endl;
}
return 0;
}492: 荷兰国旗问题(The Dutch flag problem)
题目描述
The Dutch flag problem is to rearrange an array of characters R, W,and B (red, white, and blue are the colors of the Dutch national flag) so that all the R’s come first, the W’s come next, and the B’s come last. Design a linear and stable algorithm for this problem.
输入
two lines, the first line is total of numbers characters R,W and B ,and the numbers less than 500005 the second line is random characters R,W and B
输出
a line, all the R’s come first, the W’s come next, and the B’s come last.
样例输入
10 WRRWRWBBRW
样例输出
RRRRWWWWBB
#include <bits/stdc++.h>
using namespace std;
int main()
{
int n,b[5]={0};
cin>>n;
char a[n];
for(int i=0;i<n;i++)
{
cin>>a[i];
if(a[i]=='R') b[0]++;
else if(a[i]=='W') b[1]++;
else b[2]++;
}
for(int i=0;i<b[0];i++) cout<<'R';
for(int i=0;i<b[1];i++) cout<<'W';
for(int i=0;i<b[2];i++) cout<<'B';
cout<<endl;
}
642:俄式乘法
题目描述
俄式乘法,又被称为俄国农夫法,它是对两个正整数相乘的非主流算法。假设m和n是两个正整数,我们要计算它们的积。它的主要原理如下: if n is 偶数 n m=n/2 2m else n * m=(n-1)/2 + m 该算法只包括折半,加倍,相加等几个简单操作,因此实现速度非常快。具体计算如下图所示:

输入
两个正整数 n,m。
输出
n和m的乘积。 输出整个求和表达式,运算符与数字之间用一个空格隔开。
样例输入
50 65
样例输出
130 + 1040 + 2080 = 3250
#include <bits/stdc++.h>
using namespace std;
int main()
{
int m,n,sum=0;
cin>>m>>n;
while(m!=0)
{
if(m%2==0)
{
m=m/2;
n=2*n;
}
else
{
if(m!=1)
{
cout<<n<<" + ";//注意空格
sum+=n;
}
else cout<<n<<" = "<<sum+n<<endl;
m=(m-1)/2;
n=n*2;
}
}
}
76:数字模式的识别
题目描述
数字的模式是指在一堆给定数字中出现次数最多的数值,如5,5,5,3,3,2,6,4,它的模式就是5。现在你的任务,就是从数字中找到它的模式.
输入
第一行为整数N.从第二行开始为N个整数。对于输入的每个数,有( |input_number| <= 2000000 ).
输出
输出这些数字的模式,如果模式个数不为1,选择它们之中较小的。
样例输入
10 1 2 3 4 5 6 7 8 9 9
样例输出
9
#include <bits/stdc++.h>
using namespace std;
int main()
{
int n,maxi=0,b[2000000];
cin>>n;
int a[n];
for(int i=0;i<n;i++)
{
cin>>a[i];
b[a[i]]++;
}
for(int i=0;i<2000000;i++)
maxi=max(maxi,b[i]);
for(int i=0;i<2000000;i++)
if(b[i]==maxi) cout<<i<<endl;
}
195: Buyer(采购员)
题目描述
哆啦A梦班级举办个party,当然吃的东西必不可少,哆啦A梦负责采购任务,他得到了一份清单,上面注明不同食品的受欢迎程度,哆啦A梦需要用一定的价钱尽可能达到的更大的受欢迎程度!例如,瓜子的受欢迎程度为20,瓜子的价钱是50元,那么如果哆啦A梦选择买瓜子,将花费50元,但受欢迎程度增加了20。为了避免食品单调性,每种食品只能买一份,不能重复购买。 现在哆啦A梦需要知道如何采购才能达到最大的受欢迎程度,你能帮助他吗?
输入
输入数据为多组,每组输入的第一行有两个正整数M和N(M<100&&N<1000),分别为哆啦A梦可以支配的钱数和清单上的可选择的物品种类。 接下来的N行每行有两个正整数,分别为每种物品的价钱和它的受欢迎程度(编号为1到N)。
输出
如果存在物品购买,那么输出的第一行为能够达到的最大的受欢迎程度。第二行为需要购买的物品的编号(如果有多种可能,输出字典序靠前的那种),空格分隔每个数字;如没有物品可以购买,输出只有一行,为数字0。
样例输入
10 4 100 5 5 5 5 5 10 10
样例输出
10 2 3
#include<bits/stdc++.h>
using namespace std;
int main()
{
int m,n;
while(cin>>m>>n)
{
int w[1000]={0},v[1000]={0},f[100][100]={0},c[101]={0},k=0;
for(int i=1;i<=n;i++) cin>>w[i]>>v[i];
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
if(j>=w[i]) f[i][j]=max(f[i-1][j],v[i]+f[i-1][j-w[i]]);
else f[i][j]=f[i-1][j];
for(int i=n,j=m;i>=1&&j>=1;i--)
if(f[i][j]>f[i-1][j])
{
c[++k]=i;
j=j-w[i];
}
cout<<f[n][m]<<endl;
for(int i=k;i>0;i--) cout<<c[i]<<((i==1)?"\n":" ");
}
}572: Boyer-Moore-Horspool algorithm(BM算法)
题目描述
题目内容来自: https://en.wikipedia.org/w/index.php?title=Boyer%E2%80%93Moore_string-search_algorithm&oldid=280422137
The Boyer–Moore string search algorithm is a particularly efficient string searching algorithm. It was developed by Bob Boyer and J Strother Moore in 1977. The algorithm preprocesses the target string (key) that is being searched for, but not the string being searched (unlike some algorithms which preprocess the string to be searched, and can then amortize the expense of the preprocessing by searching repeatedly). The execution time of the Boyer-Moore algorithm can actually be sub-linear: it doesn't need to actually check every character of the string to be searched but rather skips over some of them. Generally the algorithm gets faster as the key being searched for becomes longer. Its efficiency derives from the fact that, with each unsuccessful attempt to find a match between the search string and the text it's searching in, it uses the information gained from that attempt to rule out as many positions of the text as possible where the string could not match.
How the algorithm works

What people frequently find surprising about the Boyer-Moore algorithm when they first encounter it is that its verifications – its attempts to check whether a match exists at a particular position – work backwards. If it starts a search at the beginning of a text for the word "ANPANMAN", for instance, it checks the eighth position of the text to see if it contains an "N". If it finds the "N", it moves to the seventh position to see if that contains the last "A" of the word, and so on until it checks the first position of the text for a "A". Why Boyer-Moore takes this backward approach is clearer when we consider what happens if the verification fails – for instance, if instead of an "N" in the eighth position, we find an "X". The "X" doesn't appear anywhere in "ANPANMAN", and this means there is no match for the search string at the very start of the text – or at the next seven positions following it, since those would all fall across the "X" as well. After checking just one character, we're able to skip ahead and start looking for a match starting at the ninth position of the text, just after the "X". This explains why the best-case performance of the algorithm, for a text of length N and a fixed pattern of length M, is N/M: in the best case, only one in M characters needs to be checked. This also explains the somewhat counter-intuitive result that the longer the pattern we are looking for, the faster the algorithm will be usually able to find it. The algorithm precomputes two tables to process the information it obtains in each failed verification: one table calculates how many positions ahead to start the next search based on the identity of the character that caused the match attempt to fail; the other makes a similar calculation based on how many characters were matched successfully before the match attempt failed. (Because these two tables return results indicating how far ahead in the text to "jump", they are sometimes called "jump tables", which should not be confused with the more common meaning of jump tables in computer science.)
the first table
The first table is easy to calculate: Start at the last character of the sought string and move towards the first character. Each time you move left, if the character you are on is not in the table already, add it; its Shift value is its distance from the rightmost character. All other characters receive a count equal to the length of the search string.
Example: For the string ANPANMAN, the first table would be as shown (for clarity, entries are shown in the order they would be added to the table):(The N which is supposed to be zero is based on the 2nd N from the right because we only calculate from letters m-1)

The amount of shift calculated by the first table is sometimes called the "bad character shift"[1].
the second table

The second table is slightly more difficult to calculate: for each value of i less than the length of the search string, we must first calculate the pattern consisting of the last i characters of the search string, preceded by a mis-match for the character before it; then we initially line it up with the search pattern and determine the least number of characters the partial pattern must be shifted left before the two patterns match. For instance, for the search string ANPANMAN, the table would be as follows: (N signifies any character that is not N)

The amount of shift calculated by the second table is sometimes called the "good suffix shift"[2] or "(strong) good suffix rule". The original published Boyer-Moor algorithm [1] uses a simpler, weaker, version of the good suffix rule in which each entry in the above table did not require a mis-match for the left-most character. This is sometimes called the "weak good suffix rule" and is not sufficient for proving that Boyer-Moore runs in linear worst-case time.
Performance of the Boyer-Moore string search algorithm
The worst-case to find all occurrences in a text needs approximately 3*N comparisons, hence the complexity is O(n), regardless whether the text contains a match or not. The proof is due to Richard Cole, see R. COLE,Tight bounds on the complexity of the Boyer-Moore algorithm,Proceedings of the 2nd Annual ACM-SIAM Symposium on Discrete Algorithms, (1991) for details. This proof took some years to determine. In the year the algorithm was devised, 1977, the maximum number of comparisons was shown to be no more than 6*N; in 1980 it was shown to be no more than 4*N, until Cole's result in 1991.
References
- Hume and Sunday (1991) [Fast String Searching] SOFTWARE—PRACTICE AND EXPERIENCE, VOL. 21(11), 1221–1248 (NOVEMBER 1991)
- ^ R. S. Boyer (1977). "A fast string searching algorithm". Comm. ACM. 20: 762–772. doi:10.1145/359842.359859.
输入
two lines and only characters “ACGT” in the string. the first line is string (< = 102000) the second line is text(< = 700000)
输出
position of the string in text else -1
样例输入
GGCCTCATATCTCTCT CCCATTGGCCTCATATCTCTCTCCCTCCCTCCCCTGCCCAGGCTGCTTGGCATGG
样例输出
6
#include<bits/stdc++.h>
using namespace std;
int Horspool(string str,string text)
{
int table[26];
int str_len=str.length(),text_len=text.length();
for(int i=0;i<str_len-1;i++) table[str[i]-'A']=str_len-1-i;
int i=str_len-1;
while(i<text_len)
{
int k=0;
while(k<str_len&&str[str_len-1-k]==text[i-k]) k++;
if(k==str_len) return i-str_len+1;
else i+=table[text[i]-'A'];
}
return -1;
}
int main()
{
string str,text;
cin>>str>>text;
cout<<Horspool(str,text)<<endl;
}697: Edit Distance(编辑距离)
题目描述
设A 和B 是2 个字符串。要用最少的字符操作将字符串A 转换为字符串B。这里所说的字符操作包括
(1)删除一个字符;
(2)插入一个字符;
(3)将一个字符改为另一个字符。
将字符串A变换为字符串B 所用的最少字符操作数称为字符串A到B 的编辑距离,记为d(A,B)。
试设计一个有效算法,对任给的2 个字符串A和B,计算出它们的编辑距离d(A,B)。
输入
第一行是字符串A,文件的第二行是字符串B。字符串长度不大于2000。
输出
输出距离d(A,B)
样例输入
fxpimu xwr
样例输出
5
#include<bits/stdc++.h>
using namespace std;
int s[2001][2001];
int main(){
char a[2001],b[2001];
cin>>a>>b;
int len1=strlen(a);
int len2=strlen(b);
for(int i=0;i<=len1;i++) s[i][0]=i;
for(int i=0;i<=len2;i++) s[0][i]=i;
for(int i=1;i<=len1;i++)
for(int j=1;j<=len2;j++)
{
if(a[i-1]==b[j-1]) s[i][j]=s[i-1][j-1];
else s[i][j]=min(s[i-1][j-1],min(s[i-1][j],s[i][j-1]))+1;
}
cout<<s[len1][len2]<<endl;
}1132: Coin-collecting by robot(机器人收集硬币)
题目描述
Several coins are placed in cells of an n×m board. A robot, located in the upper left cell of the board, needs to collect as many of the coins as possible and bring them to the bottom right cell. On each step, the robot can move either one cell to the right or one cell down from its current location.
输入
The fist line is n,m, which 1< = n,m <= 1000. Then, have n row and m col, which has a coin in cell, the cell number is 1, otherwise is 0.
输出
The max number Coin-collecting by robot.
样例输入
5 6 0 0 0 0 1 0 0 1 0 1 0 0 0 0 0 1 0 1 0 0 1 0 0 1 1 0 0 0 1 0
样例输出
5
#include<bits/stdc++.h>
using namespace std;
int arr[1005][1005]={0};
int main()
{
int n,m;
cin>>n>>m;
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
{
cin>>arr[i][j];
arr[i][j]=max(arr[i-1][j],arr[i][j-1])+arr[i][j];
}
cout<<arr[n][m]<<endl;
}1139: Coin-row problem(硬币排问题)
题目描述
There is a row of n coins whose values are some positive integers c₁, c₂,...,cn, not necessarily distinct. The goal is to pick up the maximum amount of money subject to the constraint that no two coins adjacent in the initial row can be picked up.
输入
Two lines, the first line is n (0< n <=10000), and the second line is value of coin(0< value <= 2^32).
输出
the maximum amount of money.
样例输入
6 5 1 2 10 6 2
样例输出
17
#include<bits/stdc++.h>
using namespace std;
int arr[10005]={0};
int main()
{
int n;cin>>n;
for(int i=1;i<=n;i++) cin>>arr[i];
for(int i=2;i<=n;i++) arr[i]=max(arr[i-1],arr[i-2]+arr[i]);
cout<<arr[n]<<endl;
}411: 售货员的难题
题目描述
某乡有n个村庄(1< n < 20),有一个售货员,他要到各个村庄去售货,各村庄之间的路程s(0 < s < 1000)是已知的,且A村到B村与B村到A村的路大多不同。为了提高效率,他从商店出发到每个村庄一次,然后返回商店所在的村,假设商店所在的村庄为 1,他不知道选择什么样的路线才能使所走的路程最短。请你帮他选择一条最短的路。
输入
村庄数n和各村之间的路程(均是整数)。
输出
最短的路程
样例输入
3 {村庄数}
0 2 1 {村庄1到各村的路程}
1 0 2 {村庄2到各村的路程}
2 1 0 {村庄3到各村的路程}
样例输出
3
#include<bits/stdc++.h>
using namespace std;
int n,MIN=0x7FFFFFFF,a[20][20];
bool b[20];
void search(int x,int y,int z)
{
if(y==n&&z+a[x][1]<MIN)
{
MIN=z+a[x][1];
return;
}
for(int i=2;i<=n;i++)
if(!b[i]&&z+a[x][i]<MIN)
{
b[i]=true;
search(i,y+1,z+a[x][i]);
b[i]=false;
}
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++) cin>>a[i][j];
b[1]=true;
search(1,1,0);
cout<<MIN<<endl;
}594: Maximum Tape Utilization Ratio(最大磁带利用率)
题目描述
设有n 个程序{1,2,…, n }要存放在长度为L的磁带上。程序i存放在磁带上的长度是li ,1 < = i < = n。 程序存储问题要求确定这n 个程序在磁带上的一个存储方案,使得能够在磁带上存储尽可能多的程序。在保证存储最多程序的前提下还要求磁带的利用率达到最大。 对于给定的n个程序存放在磁带上的长度,编程计算磁带上最多可以存储的程序数和占用磁带的长度。
输入
第一行是2 个正整数,分别表示文件个数n <=600和磁带的长度L<=6000。接下来的1 行中,有n个正整数,表示程序存放在磁带上的长度。
输出
第1 行输出最多可以存储的程序数和占用磁带的长度;第2行输出存放在磁带上的每个程序的长度。
样例输入
9 50 2 3 13 8 80 20 21 22 23
样例输出
5 49 2 3 13 8 23
#include<bits/stdc++.h>
using namespace std;
struct node{
int count;
int sumVa;
vector<long long int>army;
};
int main()
{
int n,Length;
cin>>n>>Length;
int len[605];
for(int i=1;i<=n;i++) cin>>len[i];
node dp[6005];
for(int i=n;i>0;i--)
{
int s=len[i];
for(int j=Length;j>=0;j--)
if(j>=s)
{
if(dp[j].count<dp[j-s].count+1
||dp[j].count==dp[j-s].count+1
&&dp[j].sumVa<=dp[j-s].sumVa+s)
{
dp[j].count=dp[j-s].count+1;
dp[j].sumVa=dp[j-s].sumVa+s;
dp[j].army=dp[j-s].army;
dp[j].army.push_back(s);
}
}
}
cout<<dp[Length].count<<" "<<dp[Length].sumVa<<endl;
for(int i=dp[Length].army.size()-1;i>=0;i--)
{
if(i!=dp[Length].army.size()-1)cout<<" ";
cout<<dp[Length].army[i];
}
cout<<endl;
}696: Soldiers(士兵)
题目描述
在一个划分成网格的操场上,n个士兵散乱地站在网格点上。网格点由整数坐标(x,y)表示。士兵们可以沿网格边上、下、左、右移动一步,但在同一时刻任一网格点上只能有一名士兵。按照军官的命令,士兵们要整齐地列成一个水平队列,即排列成(x,y),(x+1,y),…,(x+n-1,y)。如何选择x 和y的值才能使士兵们以最少的总移动步数排成一列。计算使所有士兵排成一行需要的最少移动步数。
输入
第1 行是士兵数n,1< =n< =10000。接下来n 行是士兵的位置,每行2个整数x和y,-10000< =x,y< =10000。
输出
第1 行中的数是士兵排成一行需要的最少移动步数。
样例输入
5 1 2 2 2 1 3 3 -2 3 3
样例输出
8
#include<bits/stdc++.h>
using namespace std;
int main(){
int n,x[10001],y[10001];
cin>>n;
for(int i=0;i<n;i++) cin>>x[i]>>y[i];
sort(x,x+n);
sort(y,y+n);
for(int i=0;i<n;i++) x[i]-=i;
sort(x,x+n);
int midy=y[n/2];
int midx=x[n/2];
int sum=0;
for(int i=0;i<n;i++) sum+=abs(x[i]-midx)+abs(y[i]-midy);
cout<<sum<<endl;
}698: Independent Task Scheduling(独立任务调度)
题目描述
用2 台处理机A 和B 处理n 个作业。设第i 个作业交给机器A 处理时需要时间ai ,若由机器B 来处理,则需要时间bi 。由于各作业的特点和机器的性能关系,很可能对于某些i,有ai >=bi,而对于某些j,j≠i,有aj < bj 。既不能将一个作业分开由2 台机器处理,也没有一台机器能同时处理2 个作业。设计一个动态规划算法,使得这2 台机器处理完这n个作业的时间最短(从任何一台机器开工到最后一台机器停工的总时间)。
研究一个实例:
(a1,a2,a3,a4,a5,a6)=(2,5,7,10,5,2);
(b1,b2,b3,b4,b5,b6)=(3,8,4,11,3,4)。
对于给定的2 台处理机A 和B处理n 个作业,找出一个最优调度方案,使2台机器处理完这n 个作业的时间最短。
输入
的第1行是1个正整数n<=200, 表示要处理n个作业。 接下来的2行中,每行有n 个正整数,分别表示处理机A 和B 处理第i 个作业需要的处理时间。
输出
最短处理时间
样例输入
6 2 5 7 10 5 2 3 8 4 11 3 4
样例输出
15
#include<bits/stdc++.h>
using namespace std;
#define INF 0x3f3f3f3f
int a[201],b[201];
int f[201][10000];
int sum=0;
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i];
sum+=a[i];
}
for(int i=1;i<=n;i++) cin>>b[i];
for(int i=1;i<=n;i++)
for(int j=0; j <= sum; j++)
{
if(a[i]<=j) f[i][j]=min(f[i-1][j-a[i]],f[i-1][j]+b[i]);
else f[i][j]=f[i-1][j]+b[i];
}
int min_time=INF;
for(int i=1; i <= sum; i++)
{
int t=max(i,f[n][i]);
min_time=min(min_time,t);
}
cout<<min_time<<endl;
}699: Arbitrage(套汇)
题目描述
套汇是指利用货币汇兑率的差异将一个单位的某种货币转换为大于一个单位的同种货币。例如,假定1 美元可以买0.7 英镑,1 英镑可以买9.5 法郎,且1 法郎可以买到0.16美元。通过货币兑换,一个商人可以从1 美元开始买入,得到0.7×9.5×0.16=1.064美元,从而获得6.4%的利润。 给定n 种货币c1 ,c2 ,... ,cn的有关兑换率,试设计一个有效算法,用以确定是否存在套汇的可能性。
输入
含多个测试数据项。每个测试数据项的第一行中只有1 个整数n (1< =n< =30),表示货币总数。其后n行给出n种货币的名称。接下来的一行中 有1 个整数m,表示有m种不同的货币兑换率。其后m行给出m种不同的货币兑换率,每行有3 个数据项ci , rij 和cj ,表示货币ci 和cj的兑换率为 rij。文件最后以数字0 结束。
输出
对每个测试数据项j,如果存在套汇的可能性则输出“Case j Yes”, 否则输出“Case j No”。
样例输入
3 USDollar BritishPound FrenchFranc 3 USDollar 0.5 BritishPound BritishPound 10.0 FrenchFranc FrenchFranc 0.21 USDollar 3 USDollar BritishPound FrenchFranc 6 USDollar 0.5 BritishPound USDollar 4.9 FrenchFranc BritishPound 10.0 FrenchFranc BritishPound 1.99 USDollar FrenchFranc 0.09 BritishPound FrenchFranc 0.19 USDollar 0
样例输出
Case 1 Yes Case 2 No
#include<bits/stdc++.h>
using namespace std;
double e[100][100];
int main()
{
int n,m,cnt=0;
while(cin>>n,n)
{
memset(e,1,sizeof e);
string s,t;
map<string,int>mp;
for(int i=0;i<n;i++)
{
cin>>s;
mp[s]=i;
}
cin>>m;
for(int i=0;i<m;i++)
{
double x;
cin>>s>>x>>t;
e[mp[s]][mp[t]]=x;
}
for(int k=0;k<n;k++)
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
e[i][j]=max(e[i][j],e[i][k]*e[k][j]);
bool flag=false;
for(int i=0;i<n;i++)
if(e[i][i]>1)
{
flag=true;
break;
}
printf("Case %d %s\n",++cnt,(flag?"Yes":"No"));
}
return 0;
}574: Renting Boats(租用船只)
题目描述
长江游艇俱乐部在长江上设置了n 个游艇出租站1,2,…,n。游客可在这些游艇出租站租用游艇,并在下游的任何一个游艇出租站归还游艇。游艇出租站i 到游艇出租站j 之间的租金为r(i,j),1< =i< j < =n。试设计一个算法,计算出从游艇出租站1 到游艇出租站n 所需的最少租金。
输入
第1 行中有1 个正整数n(n<=200),表示有n个游艇出租站。接下来的n-1 行是r(i,j),1< =i< j < =n。
输出
从游艇出租站1 到游艇出租站n所需的最少租金
样例输入
3 5 15 7
样例输出
12
#include<iostream>
using namespace std;
int main()
{
int n;cin>>n;
int a[201][201]={0};
for(int i=1;i<n;i++)
for(int j=i;j<n;j++)
{
cin>>a[i][j];
int s=a[1][i-1]+a[i][j];
if(a[1][j]>s) a[1][j]=s;
}
cout<<a[1][n-1]<<endl;
}266: 车行的进货问题
题目描述
小白是一家自行车行的董事长兼CEO兼技师兼……车行的主要业务是销售各种自行车配件或者根据客户需求组装自行车,因此在进货的时候他需要根据不同配件的销售情况来决定各种配件的进货量。同时,因为资金有限,小白还需要考虑如何使用有限的资金创造更大的利润。因为自行车配件种类繁多,人工计算相当的麻烦,于是小白决定找人帮他写个程序来解决车行的进货问题。 每次进货前,小白都会列出可用于进货的总资金V(0<=V<=100,000)、当前自行车配件的期望利润率R(0<=R<=2)以及一个配件需求清单。配件需求清单包括所需要的配件种类N(0<=N<=100)以及每种配件的进货价格vi(0<=vi<=200,000)和需求量ci(0<=ci<=1000)。进货时的总进货价格不能超过可用于进货的总资金以避免财政赤字;同时也必须保证每种零件的进货量不超过这种零件的需求量,以避免货物积压。现在我们的任务是帮助小白计算出此次进货能达到的最大期望利润。
输入
题目有多组输入,以EOF结束。每组输入的第一行包含一个整数V和一个浮点数R;每组输入的第二行包含一个整数N,接下来的N行每一行包含两个整数vi和ci。
输出
每组输出包含一个浮点数(保留两位小数),表示此次进货所能达到的最大期望利润。
样例输入
1000 0.333 5 1100 2 1001 2 100 3 500 1 120 3 1000 0.5 3 100 3 500 1 200 1
样例输出
319.68 500.00
#include<bits/stdc++.h>
using namespace std;
int dp[100010],w[100010];
int main()
{
int V;
float R;
while(cin>>V>>R)
{
int cnt=0;
int n;
cin>>n;
for(int i=0;i<n;i++)
{
int v,num;
cin>>v>>num;
if(v>V) continue;
int k=1;
while(num-k>0)
{
w[cnt++]=k*v;
num-=k;
k*=2;
}
w[cnt++]=v*num;
}
for(int i=0;i<cnt;i++)
for(int j=V;j>=w[i];j--)
dp[j]=max(dp[j],dp[j-w[i]]+w[i]);
printf("%.2f\n",dp[V]*R);
}
}577: Shortest path counting(最短路径计数)
题目描述
A chess rook can move horizontally or vertically to any square in the same row or in the same column of a chessboard. Find the number of shortest paths by which a rook can move from one corner of a chessboard to the diagonally opposite corner。
输入
a interger number n is row and column of chessboard. 0 < n <=16
输出
the number of shortest paths.
样例输入
4
样例输出
20
#include<bits/stdc++.h>
using namespace std;
int main()
{
int n;
cin>>n;
int f[n+1][n+1];
for(int i=2;i<=n;i++)
{
f[1][i]=1;
f[i][1]=1;
}
for(int i=2;i<=n;i++)
for(int j=2;j<=n;j++)
f[i][j]=f[i-1][j]+f[i][j-1];
cout<<f[n][n]<<endl;
}649: NBA Finals(NBA总决赛)
题目描述
Consider two teams, Lakers and Celtics, playing a series of NBA Finals until one of the teams wins n games. Assume that the probability of Lakers winning a game is the same for each game and equal to p and the probability of Lakers losing a game is q = 1-p. Hence, there are no ties.Please find the probability of Lakers winning the NBA Finals if the probability of it winning a game is p.
输入
first line input the n-games (7<=n<=165)of NBA Finals second line input the probability of Lakers winning a game p (0< p < 1)
输出
the probability of Lakers winning the NBA Finals
样例输入
7 0.4
样例输出
0.289792
#include<bits/stdc++.h>
using namespace std;
int n;
double dp[201][201]={0};
int main()
{
double p;
cin>>n>>p;
for(int i=1;i<=n;i++)
{
dp[i][0]=0;
dp[0][i]=1;
}
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
dp[i][j]=dp[i-1][j]*p+dp[i][j-1]*(1-p);
cout<<dp[n-3][n-3]<<endl;
}680: Jack Straws(Jack Straws游戏)
题目描述
In the game of Jack Straws, a number of plastic or wooden "straws" are dumped on the table and players try to remove them one-by-one without disturbing the other straws. Here, we are only concerned with if various pairs of straws are connected by a path of touching straws. You will be given a list of the endpoints for some straws (as if they were dumped on a large piece of graph paper) and then will be asked if various pairs of straws are connected. Note that touching is connecting, but also two straws can be connected indirectly via other connected straws.
输入
A problem consists of multiple lines of input. The first line will be an integer n (1 < n < 13) giving the number of straws on the table. Each of the next n lines contain 4 positive integers, x1 , y1 , x2 and y2 , giving the coordinates, (x1 ; y1 ); (x2 ; y2 ) of the endpoints of a single straw. All coordinates will be less than 100. (Note that the straws will be of varying lengths.) The first straw entered will be known as straw #1, the second as straw #2, and so on. The remaining lines of input (except for the final line) will each contain two positive integers, a and b, both between 1 and n, inclusive. You are to determine if straw a can be connected to straw b. When a = 0 = b, the input is terminated. There will be no illegal input and there are no zero-length straws.
输出
You should generate a line of output for each line containing a pair a and b, except the final line where a = 0 = b. The line should say simply "CONNECTED", if straw a is connected to straw b, or "NOT CONNECTED", if straw a is not connected to straw b. For our purposes, a straw is considered connected to itself.
样例输入
7 1 6 3 3 4 6 4 9 4 5 6 7 1 4 3 5 3 5 5 5 5 2 6 3 5 4 7 2 1 4 1 6 3 3 6 7 2 3 1 3 0 0
样例输出
CONNECTED NOT CONNECTED CONNECTED CONNECTED NOT CONNECTED CONNECTED
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll i,j,k,m,n;
struct straw
{
ll a,b,x,y;
}a[100];
bool check(ll x,ll y)
{
ll Ax1=a[x].a,Ay1=a[x].b,Ax2=a[x].x,Ay2=a[x].y,Bx1=a[y].a,By1=a[y].b,Bx2=a[y].x,By2=a[y].y;
if(max(Ax1,Ax2)<min(Bx1,Bx2) || max(Ay1,Ay2)<min(By1,By2) ||
max(Bx1,Bx2)<min(Ax1,Ax2) || max(Bx1,Bx2)<min(Ax1,Ax2)
) return false;
if(( ((Ax1-Ax2)*(Ay1-By1) - (Ax1-Bx1)*(Ay1-Ay2)) * ((Ax1-Ax2)*(Ay1-By2) - (Ax1-Bx2)*(Ay1-Ay2)) <=0) &&
( ((Bx1-Bx2)*(By1-Ay1) - (Bx1-Ax1)*(By1-By2)) * ((Bx1-Bx2)*(By1-Ay2) - (Bx1-Ax2)*(By1-By2)) <=0)
) return true;
else return false;
}
ll pre[1000];
ll find(ll num)
{
while(num!=pre[num]) num=pre[num];
return num;
}
int main()
{
while(cin>>n)
{
for(i=1;i<=n;i++)
{
cin>>a[i].a>>a[i].b>>a[i].x>>a[i].y;
pre[i]=i;
}
ll x,y;
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(check(i,j))
{
x=find(i);
y=find(j);
if(x!=y) pre[x]=y;
}
while(true)
{
cin>>m>>k;
if(m==0 && k==0) break;
x=find(m);
y=find(k);
if(x==y) cout<<"CONNECTED\n";
else cout<<"NOT CONNECTED\n";
}
}
}















 1457
1457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











