









-
数据库的三范式?
第一范式:每列的原子性:每列都是不可再分的最小数据单元;
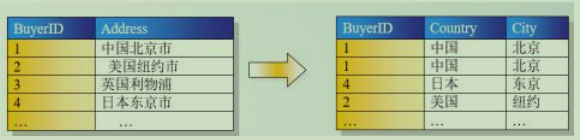
第二范式:每个表只描述一件事情
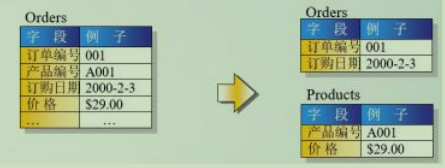
第三范式:不存在对非主键列的传递依赖

-
索引
索引的优点:
1.创建唯一性索引,保证数据表中每一行数据的唯一性。
2.大大加快数据的检索速度,这也是创建索引的最主要的原因。
3.减少磁盘IO(向字典一样可以直接定位)索引的分类:
1.普通索引和唯一性索引
普通索引:Create Index mycolumn_index on mytable (myclumn)
唯一性索引:保证在索引列中的全部数据是唯一性的
CREATE unique INDEX mycolumn_index ON mytable (myclumn)2.单个索引和复合索引
单个索引:对单个字段建立索引
复合索引:又叫组合索引,在索引建立语句中同时包含多个字段名,最多16个字段,CREATE INDEX name_index ON userInfo(firstname,lastname)3.顺序索引,散列索引,位图索引
-
数据库事务特性?
1.原子性:事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执行, 要么都不执行。2.一致性:当事务完成时,数据必须处于一致状态。
3.隔离性:对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不 应以任何方式依赖于或影响其他事务。
4.永久性:事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性。
-
四种隔离级别?
Serializable(串行化):可避免脏读、不可重复读、幻读的发生。
Repeatable read(可重复读):可避免脏读、不可重复读的发生。
Read committed(读已提交):可避免脏读发生。
Read uncommitted(读未提交):最低级别,任何情况都无法保证。 -
分页语句?
oracle:
select * from (select * from (select s.*,rownum rn from student s ) where rn<=5) where rn>0
mysql:
select * from table_name where 1= 1 limit start,end -
数据库优化的思路?
一、SQL语句优化
1.尽量避免在where子句中使用!=或<>操作符,否则引擎将放弃索引而进行全表扫描。2.尽量避免在where子句中对字段进行null值判断,否则引擎将放弃索引而进行全表扫描。
如: select id from t where num is null
可以在 num 上设置默认值 0,确保表中 num 列没有 null 值,然后这样查询:
select id from t where num=03.使用exists代替in是一个好的选择。
4.用where子句代替HAVING是一个好的选择。因为HAVING只会在检索出所有记录之后才对结果集进行过滤。
二、索引
数据索引是有序的
在有序的情况下,通过索引查询一个数据是无需遍历索引记录的
极端情况下,数据索引的查询效率为二分法查询效率,趋近于log2(N)三、索引添加适当存储器过程,触发器,事务等
四、读写分离(主从数据库)
五、数据库结构优化
1.范式优化:比如消除冗余(节省空间)
2.反范式优化:适当增加冗余(减少join)
3.拆分表:
分区将数据在物理上分隔开,不同分区的数据可以制定保存在处于不同磁盘上的数据文件 里。这样,当对这个表进行查询时,只需要在表分区中进行扫描,而不必进行全表扫描,明 显缩短了查询时间,另外处于不同磁盘的分区也将对这个表的数据传输分散在不同的磁盘I/O,一个精心设置的分区可以将数据传输对磁盘 I/O 竞争均匀地分散开。对数据量大的时 时表可采取此方法。可按月自动建表分区。4.拆分分垂直拆分和水平拆分
案例:
简单购物系统暂设涉及如下表:
1.产品表(数据量 10w,稳定)
2.订单表(数据量 200w,且有增长趋势)
3.用户表 (数据量 100w,且有增长趋势)
以 mysql 为例讲述下水平拆分和垂直拆分,mysql 能容忍的数量级在百万静态数据可以到千 万
垂直拆分:
解决问题:表与表之间的 io 竞争
不解决问题:单表中数据量增长出现的压力
方案: 把产品表和用户表放到一个 server 上
订单表单独放到一个 server 上
水平拆分:
解决问题:单表中数据量增长出现的压力
不解决问题:表与表之间的 io 争夺
方案: 用户表通过性别拆分为男用户表和女用户表
订单表通过已完成和完成中拆分为已完成订单和未完成订单
产品表 未完成订单放一个 server 上
已完成订单表盒男用户表放一个 server 上
女用户表放一个 server 上 -
分区和分表的区别?
mysql分表是真正的分表,都对应三个文件,一个.MYD 数据文件,.MYI 索引文件,.frm 表结构文件。
分区后还是一张大表,存放数据的区块变多了。 -
Redis?
本质是键值数据库,吸收部分关系数据库的优点。从而使它的位置处于关系数据库和键值数 据库之间。Redis 不仅能保 存 Strings 类型的数据,还能保存 Lists 类型(有序)和 Sets 类型(无序)的数据,而且还能完成排序 (SORT) 等高级功能,在实现 INCR,SETNX 等 功能的时候,保证了其操作的原子性,除此以外, 还支持主从复制等功能。















02-21
 536
536
536
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









