






又是新的一周,最近上海的疫情似乎又开始严重起来了,小编所在的小区也被封了,身边很多包括同事、朋友所在的小区也都被封了。希望这个疫情可以尽快过去吧,生活能够重新回到正轨。今天我们来聊一下Pandas当中的数据集中带有多重索引的数据分析实战
通常我们接触比较多的是单层索引(左图),而多级索引也就意味着数据集当中的行索引有多个层级(右图),具体的如下图所示
AUTUMN


导入数据
我们先导入数据与pandas模块,源数据获取,公众号后台回复【多重索引】就能拿到
import pandas as pd
## 导入数据集
df = pd.read_csv('dataset.csv')
df.head()output

该数据集描述的是英国部分城市在2019年7月1日至7月4日期间的全天天气状况,我们先来看一下当前的数据集的行索引有哪些?代码如下
df.index.namesoutput
FrozenList(['City', 'Date'])数据集当中City、Date,这里的City我们可以当作是第一层级索引,而Date则是第二层级索引。
我们也可以通过调用sort_index()方法来按照数据集的行索引来进行排序,代码如下
df_1 = df.sort_index()
df_1output

要是我们想将这个多层索引去除掉,就调用reset_index()方法,代码如下
df.reset_index()下面我们就开始针对多层索引来对数据集进行一些分析的实战吧
第一层级的数据筛选
在pandas当中数据筛选的方法,一般我们是调用loc以及iloc方法,同样地,在多层级索引的数据集当中数据的筛选也是调用该两种方法,例如筛选出伦敦白天的天气状况如何,代码如下
df_1.loc['London' , 'Day']output

要是我们想针对所有的行,就可以这么来做
df_1.loc[:, 'Day']output

同理针对所有的列,就可以这么来做
df_1.loc['London' , :]output

多层级索引的数据筛选
要是我们想看伦敦2019年7月1日白天的天气状况,就可以这么来做
df.loc['London', 'Day'].loc['2019-07-01']output
Weather Shower
Wind SW 16 mph
Max Temperature 28
Name: 2019-07-01, dtype: object这里我们进行了两次数据筛选的操作,先是df.loc['London', 'Day'],然后再此的基础之上再进行loc['2019-07-01']操作,当然还有更加方便的步骤,代码如下
df.loc[('London', '2019-07-01'), 'Day']output
Weather Shower
Wind SW 16 mph
Max Temperature 28
Name: 2019-07-01, dtype: object除此之外我们要是想看一下伦敦2019年7月1日和7月2日两天白天的天气情况,就可以这么来做
df.loc[
('London' , ['2019-07-01','2019-07-02'] ) ,
'Day'
]output

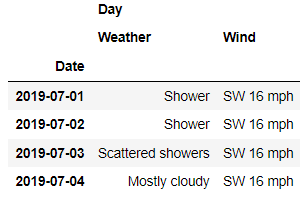
在此基础之上,我们想要看天气和风速这两列,我们也可以单独摘出来,代码如下
df.loc[
'London' ,
('Day', ['Weather', 'Wind'])
]output
按照范围来筛选数据
对于第一层级的索引而言,我们同样还是调用loc方法来实现
df.loc[
'Cambridge':'Oxford',
'Day'
]output

但是对于第二层级的索引,要是用同样的方式来用就会报错,
df.loc[
('London', '2019-07-01': '2019-07-03'),
'Day'
]output
SyntaxError: invalid syntax (<ipython-input-22-176180497f92>, line 3)正确的写法代码如下
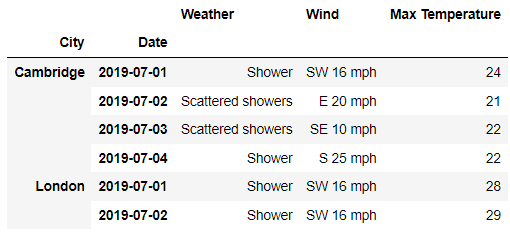
df.loc[
('London','2019-07-01'):('London','2019-07-03'),
'Day'
]output
筛选出所有全部的内容
对于单层索引而言,我们通过:来筛选出所有的内容,但是在多层级的索引上面则并不适用,
# 出现语法错误
df.loc[
('London', :),
'Day'
]
# 出现语法错误
df.loc[
(: , '2019-07-04'),
'Day'
]正确的做法如下所示
# 筛选出伦敦下面所有天数的白天天气情况
df.loc[
('London', slice(None)),
'Day'
]output

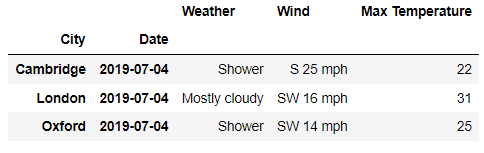
# 筛选出2019年7月4日下所有城市的白天天气情况
df.loc[
(slice(None) , '2019-07-04'),
'Day'
]output
当然这里还有更加简便的方法,我们通过调用pandas当中IndexSlice函数来实现,代码如下
from pandas import IndexSlice as idx
df.loc[
idx[: , '2019-07-04'],
'Day'
]output

又或者是
rows = idx[: , '2019-07-01']
cols = idx['Day' , ['Max Temperature','Weather']]
df.loc[rows, cols]output
xs()方法的调用
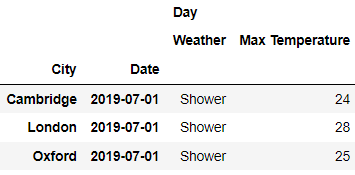
对于多层级索引的数据集而言,调用xs()方法能够更加方便地进行数据的筛选,例如我们想要筛选出日期是2019年7月4日的所有数据,代码如下
df.xs('2019-07-04', level='Date')output
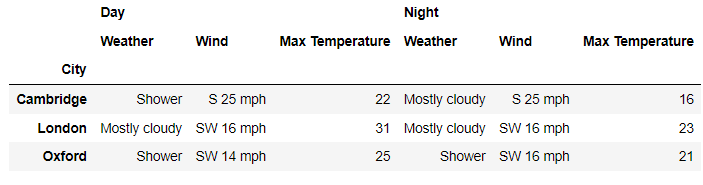
我们需要在level参数上指定是哪个标签,例如我们想要筛选出伦敦2019年7月4日全天的天气情况,代码如下
df.xs(('London', '2019-07-04'), level=['City','Date'])output

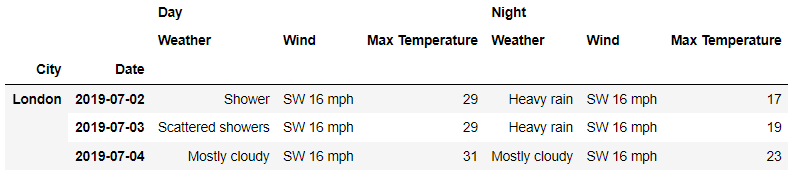
最后xs方法可以和上面提到的IndexSlice函数联用,针对多层级的数据集来进行数据的筛选,例如我们想要筛选出2019年7月2日至7月4日,伦敦全天的天气状况,代码如下
rows= (
idx['2019-07-02':'2019-07-04'],
'London'
)
df.xs(
rows ,
level = ['Date','City']
)output
觉得还不错就给我一个小小的鼓励吧!














 6013
6013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









