







多级索引创建和获取
关键就是是否存在一个可构建二维(多维)的index
1. 使用MultiIndex基于元组创建
创建一个Series数组,以元组作为index
import pandas as pd
index = [('California', 2000), ('California', 2010),
('New York', 2000), ('New York', 2010), ('Texas', 2000), ('Texas', 2010)]
populations = [33871648, 37253956, 18976457, 19378102, 20851820, 25145561]
pop = pd.Series(populations, index=index)
print(pop)结果如图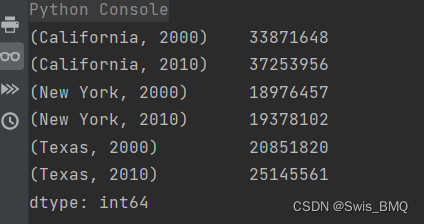
我们希望通过元组构建二级索引,使用pd.MultiIndex.from_tuples(index)
index1 = pd.MultiIndex.from_tuples(index) # 基于元组创建
pop1 = pop.reindex(index1)
print(pop1)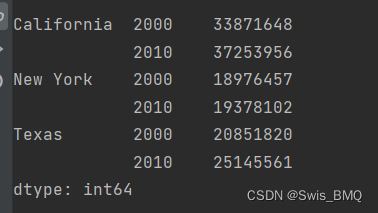
是不是瞬间舒服很多,下面根据索引取值
print(pop1.loc['California']) # 查询第一层索引
print("-------------------")
print(pop1.loc[:, 2010]) # 第二层索引
print(pop1.loc['California', 2010]) # 取一个元素
2. 通过二维索引数组创建
import numpy as np
import pandas as pd
index = [['a', 'a', 'b', 'b'], [1, 2, 1, 2]]
df = pd.DataFrame(np.random.rand(4, 2), index=index, columns=['data1', 'data2'])
print(df)
或者使用pd.MultiIndex.from_arrays(二维数组)
index = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]])
取值,df[]从列开始,df.loc从索引(index)开始,.iloc基于索引位置开始的
print(df['data1']) # 取'data1'列
print(df['data1']['a']) # 取'data1'列索引'a'
print(df['data1'][:, 1]) # 取'data1'列索引1
print(df['data1']['a', 1]) # 取'data1'列索引'a'索引1结果
a 1 0.174784
2 0.972091
b 1 0.565805
2 0.020060
Name: data1, dtype: float64
1 0.174784
2 0.972091
Name: data1, dtype: float64
a 0.174784
b 0.565805
Name: data1, dtype: float64
0.174783518383268
获取索引为2的数据,使用切片索引
idx = pd.IndexSlice
print(df.loc[idx[:, 2] , :])结果
data1 data2
a 2 0.865335 0.489147
b 2 0.350173 0.5748753. 笛卡尔积创建
pd.MultiIndex.from_product()
import numpy as np
import pandas as pd
index = pd.MultiIndex.from_product([[2013, 2014], [1, 2]], names=['year', 'visit']) # 给索引起名字
columns = pd.MultiIndex.from_product([['Bob', 'Guido', 'Sue'], ['HR', 'Temp']])
# 模拟数据
data = np.round(np.random.randn(4, 6), 1)
data[:, ::2] *= 10
data += 37
# 创建一个包含多级列索引的DataFrame
health_data = pd.DataFrame(data, index=index, columns=columns)
print(health_data)
运行结果
Bob Guido Sue
HR Temp HR Temp HR Temp
year visit
2013 1 51.0 38.2 35.0 37.2 42.0 36.7
2 38.0 37.4 59.0 35.4 44.0 36.1
2014 1 40.0 36.7 41.0 36.7 42.0 37.2
2 47.0 35.7 31.0 37.4 38.0 37.3“隔空取物”
idx = pd.IndexSlice
print(health_data.loc[:, idx[:, 'HR']]) # 列索引"HR"
print(health_data.loc[idx[:, 1], :]) # 索引1
print(health_data.loc[idx[:, 1], idx[:, 'HR']]) # 列索引"HR",索引1运行结果
Bob Guido Sue
HR HR HR
year visit
2013 1 26.0 39.0 37.0
2 47.0 42.0 52.0
2014 1 48.0 33.0 29.0
2 47.0 42.0 40.0
-----------------------------------------------
Bob Guido Sue
HR Temp HR Temp HR Temp
year visit
2013 1 26.0 39.1 39.0 38.5 37.0 35.4
2014 1 48.0 36.2 33.0 38.3 29.0 35.8
-----------------------------------------------
Bob Guido Sue
HR HR HR
year visit
2013 1 26.0 39.0 37.0
2014 1 48.0 33.0 29.0
4. stack() 和 unstack()
个人理解:
stack():列索引只有一级
unstack():行索引只有一级
运行上述代码 print(health_data.stack())
Bob Guido Sue
year visit
2013 1 HR 48.0 27.0 54.0
Temp 38.3 36.1 38.1
2 HR 40.0 44.0 47.0
Temp 37.5 37.8 35.6
2014 1 HR 46.0 36.0 48.0
Temp 37.4 38.7 37.2
2 HR 34.0 35.0 44.0
Temp 36.9 36.3 35.7














 1065
1065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









