







3 栈和队列
在各类数据结构中,栈(Stack)和队列(Queue)是除线性表以外,另外两种应用非常广泛且极为重要的线性结构。它们与线性表不同之处在于:栈和队列都可被看成是两种操作受限的特殊线性表,其特殊性体现在它们的插入和删除操作都是控制在线性表的一端或两端进行。
3.1 栈
栈是一种特殊的线性表,栈中的数据元素以及数据元素间的逻辑关系和线性表相同,两者之间的差别在于:线性表的插入和删除操作可以在表的任意位置进行,而栈的插入和删除操作只允许在表 尾端进行。其中,栈中允许进行插入和删除 操作的一端称为栈顶(top),另一端称为栈底(bottom)。通常,我们将栈的插入操作称为入栈(push),而将删除操作称为出栈(pop)。
从栈的概念可知,每次最先入栈的数据元素总是被放在栈的底部,成为栈底元素;而每次最先出栈的总是放在栈顶位置的数据元素,称为栈顶元素。因此,栈是一种先进后出(First In Last out,FILO)或后进先出(Last In First Out,LIFO)的线性表。
3.1.1 栈的抽象数据类型描述
栈抽象数据类型用Java接口描述如下:
package adt;
public interface IStack {
/**
* 将一个已经存在的栈置为空栈
*/
public void clear();
/**
* 判断一个栈是否为空
*/
public boolean isEmpty();
/**
* 返回栈中数据元素的个数
*/
public int length();
/**
* 读取栈顶元素并返回其值,若栈为空,则返回null
*/
public Object peek();
/**
* 将数据元素x压入栈顶
*/
public void push(Object x) throws Exception;
/**
* 删除并返回栈顶元素,若栈为空,则返回null
*/
public Object pop();
}
3.1.2 顺序栈及其基本操作实现
与顺序表一样,顺序栈也是用数组来实现的。假设数组名为stackElem。由于入栈和出栈操作只能在栈顶进行,所有需要再加一个变量top来知识栈顶元素的位置。top有两种定义方式,一种是将其设置为指向栈顶元素存储位置的下一个存储单元的位置,则空栈时,top=0;另一种是将top设置为指向栈顶元素的存储位置,则空栈时,top=-1.这儿采用第一种方式。
1 入栈操作
入栈操作的基本要求是将数据元素x插入顺序栈中,使其成为新的栈顶元素。思路如下:
1)判断顺序栈是否为满,若为满,则抛出异常结束操作。
2)将新的数据元素x存入top所指向的存储单元,使其成为新的栈顶元素。
3)栈顶指针top加1。
完成2)和3)所对应的Java语句:stackElem[top++] = x;
实现:
public void push(Object x) throws Exception {
if (top == stackElem.length) {
throw new Exception("栈已满");
} else {
stackElem[top++] = x;// 先将新的数据元素x压入栈顶,再将top加1
}
}2. 出栈操作
出栈操作的基本要求是将栈顶元素从栈中移去,并返回被移去的栈顶元素的值。思路:
1)判断顺序栈是否为空,若为空,则返回null。
2)先将top减1,使得栈顶指针指向栈顶元素。
3)返回top所指示的栈顶元素的值。
完成2)和3)所对应的java语句为:return stackElem[--top];
实现:
public Object pop() {
if (isEmpty()) {
return null;
} else {
return stackElem[--top];
}
}
全部实现:
package stack;
import adt.IStack;
public class SqStack implements IStack {
private Object[] stackElem;
private int top;
public SqStack(int maxSize) {
top = 0;
stackElem = new Object[maxSize];
}
@Override
public void clear() {
top = 0;
}
@Override
public boolean isEmpty() {
return top == 0;
}
@Override
public int length() {
return top;
}
@Override
public Object peek() {
if (!isEmpty()) {// 栈非空
return stackElem[top - 1];// 返回栈顶元素
} else {
return null;
}
}
@Override
public void push(Object x) throws Exception {
if (top == stackElem.length) {
throw new Exception("栈已满");
} else {
stackElem[top++] = x;// 先将新的数据元素x压入栈顶,再将top加1
}
}
@Override
public Object pop() {
if (isEmpty()) {
return null;
} else {
return stackElem[--top];
}
}
}
3.1.3 链栈机器基本操作实现
链栈的存储结构可以使用不带头结点的单链表来实现。由于在栈中,不存在在单链表中的任意位置进行插入和删除的情况,所以,在链栈中不需要设置头结点,直接将栈顶元素放在单链表的首部成为首节点。
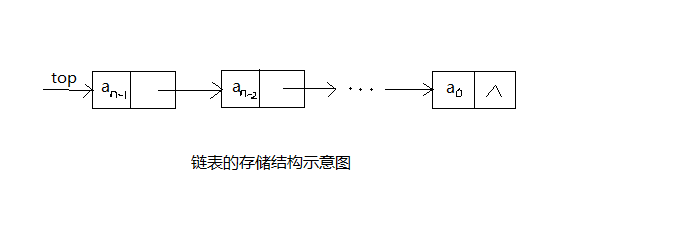
1.入栈操作
入栈操作的基本要求是将数据域为x的新节点插入到链栈的栈顶,使其成为新的栈顶元素。思路:
1)构造数据域值为x的新节点
2)将新节点直接链接到栈链的头部(栈顶),并使其成为新的首节点(栈顶节点)。
public void push(Object x) throws Exception {
Node p = new Node(x);// 构造一个新节点
p.next = top;
top = p;// 新节点称为当前栈顶元素
}
2. 出栈操作
出栈操作的基本要求是将首节点(栈顶结点)从栈链栈链中移去,并返回该节点的数值域的值。思路:
1)判断栈链是否为空,若为空,则结束操作并返回null,否则,转2)
2)确定被删除节点为栈顶节点
3)修改相关指针域的值,是栈顶节点从栈链中移去,并返回被删的栈顶节点的数据域的值。
public Object pop() {
if (isEmpty()) {
return null;
} else {
Node p = top;// p指向被删除节点(栈顶节点)
top = top.next;// 修改指针链,使栈顶元素从栈链中移去
return p.data;// 返回栈顶节点的数据域的值
}
}3.2 队列
队列是另一种特殊的线性表,它的特殊性体现在队列只允许在表尾插入数据元素,在表头删除数据元素,所以队列也是一种操作受限的的线性表,它具有先进先出(First In First Out,FIFO)或后进后出(Last In Last out,LILO)的特性。
允许进行插入的一端称为是队尾(rear),允许进行删除的一端称为是队首(front)。
3.2.1 队列的抽象数据类型描述
package adt;
public interface IQueue {
/**
* 将一个已经存在的队列置为空队列
*/
public void clear();
/**
* 判断一个队列是否为空
*/
public boolean isEmpty();
/**
* 返回队列中数据元素的个数
*/
public int length();
/**
* 读取队首元素并返回其值
*/
public Object peek();
/**
* 将数据元素x插入到队列中使其成为新的队尾元素
*/
public void offer(Object x) throws Exception;
/**
* 删除队首元素并返回其值,若队列为空,则返回null
*/
public Object poll();
}
3.2.2 顺序队列及其基本操作的实现
与顺序栈类似,在顺序队列的存储结构中,需要分配一块地址连续的存储区域来依次存放队列中从队首到队尾的所有元素。这样也可以使用一维数组来表示。由于队列的入队操作只能在当前队列的队尾进行,而出队操作只能在当前队列的队首进行,所以需加上变量front和rear来分别知识队首和队尾元素在数组中的位置,其初始值都为0,。在非空栈中,front指向队首元素,rear指向对队尾元素的下一个存储位置。
初始化队列时,令front=rear=0;入队时,直接将新的数据元素存入rear所指的存储单元中,然后将rear值加1;出队时,直接取出front所指的存储单元中数据元素的值,然后将front值加1。

从上图可以看出,若此时需要将数据元素H入队,H应存放于rear=6的位置处,顺序队列则因为数组下标越界而引起“溢出”,但此时顺序队列的首部还空出了两个数据元素的存储空间。这种溢出现象称为”假溢出“。
为了解决”假溢出“的现象,最好的办法是将顺序队列所使用的存储空间看成是一个逻辑上首尾相连的循环队列。当rear或front到达maxSize-1后,再加1就自动到0。这种转换可以利用Java语言中对整型数据求模(或取余)运算来实现,即令rear=(rear+1)%maxSize。显然,当rear=maxSize-1后,rear加1后,rear的值就为0。
将上述队列变为循环队列后,解决了”假溢出“的问题,如果在向上述队列中继续对其进行入队操作(将H、I进行入队操作),此时循环队列为满,front=rear=2。这时产生了一个新的问题:无论是队空还是队满的状态,front都和rear相等。
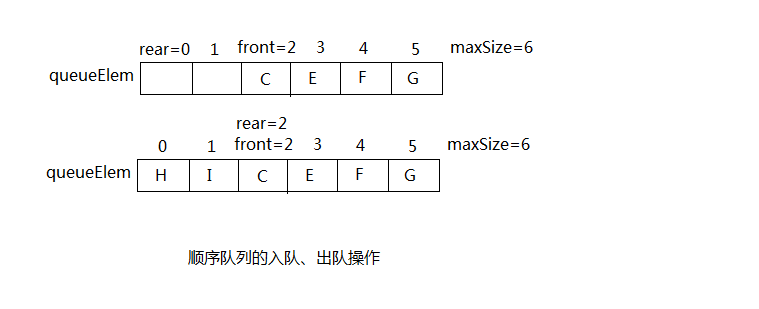
解决办法:
1)少用一个存储单元
当顺序呢存储的空间容量为maxSize时,最多只允许存放maxSize-1个数据元素。此时,队空的判断条件为:front==rear,而队满的判断条件为:front==(rear+1)%maxSize。
2)设置一个标记变量
设置一个标识变了flag,初始值为0,每当入队操作成功后就置flag=1;每当出队操作成功后就置flag=0,则此时队空的判断条件为:front==rear&&flag==0,而队满的判断条件为:front==rear&&flag=1。
这里采用第一种办法。采用第一种办法时,当rear > front时,队列的长度为rear-front。当rear<front时,队列长度为两段:一段为queueElem.length-front,另一段为0+rear,加在一起,队列长度为rear- front+queueElem.length。所有通用的队列长度计算公式为:(rear- front+queueElem.length)%queueElem.length
实现:
package queue;
public class CircleSqQueue {
private Object[] queueElem;// 队列的存储空间
private int front;// 队首的引用,若队列不为空,指向队首元素
private int rear;// 队尾的引用,若队列不为空,指向队尾元素的下一个存储位置
public CircleSqQueue(int maxSize) {
front = rear = 0;// 队首、队尾初始化为0
queueElem = new Object[maxSize];// 为队列分配maxSize个存储单元
}
public void clear() {
front = rear = 0;
}
public boolean isEmpty() {
return front == rear;
}
public int length() {
return (rear - front + queueElem.length) % queueElem.length;
}
public Object peek() {
if (!isEmpty()) {
return queueElem[front];
} else {
return null;
}
}
public void offer(Object x) throws Exception {
if (!isEmpty()) {
queueElem[rear] = x;// x存入rear所指的数组存储位置,使其成为新的队尾元素
rear = (rear + 1) % queueElem.length;// 修改队尾指针
} else {
throw new Exception("队列已满");
}
}
public Object poll() {
if (!isEmpty()) {
Object t = queueElem[front];// 记录队首元素
front = (front + 1) % queueElem.length;// 修改队首指针
return t;
} else {
return null;
}
}
}
3.2.3 链队列及其基本操作的实现
队列的链式存储结构也用不带头结点的单链表来实现。为了便于实现入队和出队操作,需要引进两个指针front和rear来分别指向队首元素和队尾元素的节点。
package queue;
import stack.Node;
import adt.IQueue;
public class LinkQueue implements IQueue {
private Node front;// 队首指针
private Node rear;// 队尾指针
public LinkQueue() {
front = rear = null;
}
@Override
public void clear() {
front = rear = null;
}
@Override
public boolean isEmpty() {
return front == null;
}
@Override
public int length() {
Node p = front;
int length = 0;
while (p != null) {
p = p.next;
length++;
}
return length;
}
@Override
public Object peek() {
if (front == null) {
return null;
} else {
return front.data;
}
}
@Override
public void offer(Object x) throws Exception {
Node p = new Node(x);
if (front == null) {// 队列胃口弄
front = rear = p;
} else {// 队列非空
rear.next = p;
rear = p;// 改变队尾位置
}
}
@Override
public Object poll() {
if (front == null) {// 队列为空
return null;
} else {// 队列非空
Node p = front;// 将p指向队首节点
front = front.next;// 队首节点出列
if (p == rear) {// 被删除的节点时队尾节点时
rear = null;
}
return p.data;// 返回队首节点的数据域
}
}
}
3.2.4 优先级队列
优先级队列是一种带有优先级的队列,它是一种比栈和队列更为专用的数据结构。与普通队列一样,优先级队列有一个队首和一个队尾,并且也是可以从队首删除数据元素,但不同的是优先级队列中数据元素按关键字的值有序排列。由于在很多情况下,需要访问具有最小关键字值的数据元素(例如要寻找最便宜的方法或最短的路径去做某件事),因此,约定关键字最小的数据元素(或者在某些实现中是关键字最大的数据元素)具有最高的优先级,并且总是排在队首。在优先级队列中数据元素的插入也不仅仅限制在队尾进行,而是顺序插入到队列的合适位置,以确保队列的优先级顺序。
优先队列中节点的data类的描述:
package queue;
/**
* 优先队列中节点的data类的描述
*
* @author Oner.wv
*
*/
public class PriorityQData {
public Object elem;// 节点的数据元素值
public int priority;// 节点的优先级
public PriorityQData(Object elem, int priority) {
this.elem = elem;
this.priority = priority;
}
}
实现IQueue接口的类的描述:
package queue;
import stack.Node;
import adt.IQueue;
public class PriorityQueue implements IQueue {
private Node front;// 队首的引用
private Node rear;// 队尾的引用
// 优先队列的构造函数
public PriorityQueue() {
front = rear = null;
}
@Override
public void clear() {
front = rear = null;
}
@Override
public boolean isEmpty() {
return front == null;
}
@Override
public int length() {
Node p = front;
int length = 0;
while (p != null) {
p = p.next;
length++;
}
return length;
}
@Override
public Object peek() {
if (isEmpty()) {
return null;
} else {
return front.data;
}
}
@Override
// 入队
public void offer(Object x) throws Exception {
PriorityQData pn = (PriorityQData) x;// 将x类型转成PriorityQData类
Node s = new Node(pn);// 生成一个data为pn的新节点
if (front == null) {
front = rear = s;// 修改队列的首位节点
} else {
Node p = front, q = front;
while (p != null
&& pn.priority >= ((PriorityQData) p.data).priority) {
q = p;
p = p.next;
}
if (p == null) {// p为空,表示遍历到了队列尾部,说明pn的优先数最大,即优先级最底
rear.next = s;// 将新节点加入到队尾
rear = s;// 修改队尾指针
} else if (p == front) {// pn的优先数最小,即pn的优先级最高
s.next = front;// 将新节点加入到队首
front = s;// 修改队首指针
} else {// 新节点添加到队列中部
s.next = q.next;
q.next = s;
}
}
}
@Override
// 出队
public Object poll() {
if (isEmpty()) {
return null;
} else {
Node p = front;
front = front.next;
if (p == rear) {
rear = null;
}
return p.data;
}
}
}
3.3 栈和队列的比较
1. 栈与队列的相同点
1)都是线性结构,即数据元素之间具有”一对一“的逻辑关系
2)插入操作都是限制在表尾进行
3)都可在顺序 存储结构和链式存储结构上实现
4)在时间代价上,插入与删除操作都需时间常数;在空间代价上,情况也相同。
2. 栈与队列的不同点
1)删除数据元素操作的位置不同。栈的删除操作控制在表尾进行,而队列的删除操作控制在表头进行。
2)两者的应用场合不相同。具有后进先出(或先进后出)特性的应用需求,可使用栈式结构进行管理。而具有先进先出(或后进后出)特性的应用需求,则要使用队列结构进行管理。
3)顺序结构栈可实现多栈空间共享,而顺序队列则不同。
3.4 练习
练习1 编写一个函数,要求借助一个栈把一个数组中的数据元素逆置。















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









