







项目介绍
本数据集共有大约1200万条数据,数据为淘宝APP2014年11月18日至2014年12月18日的用户行为数据,共6列字段,列字段分别是:
1.user_id:用户身份,脱敏
2.item_id:商品ID,脱敏
3.behavior_type:用户行为类型 (包含点击、收藏、加购物车、支四种行为,分别用数字1、2、3、4表示)
4.user_geohash: 地理位置
5.item_category:品类ID (商品所属的品类)。
6.time:用户行为发生的时间
提出问题
1.不同时间维度下用户活跃度如何变化?
2.用户的留存情况如何(复购率及漏斗流失情况)?
3.用户价值情况?
理解数据
# 导入相关的工具
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #显示中文
plt.rcParams['axes.unicode_minus'] = False #允许显示负数
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
数据预处理
# 读取相应的数据
data=pd.read_csv('/home/mw/input/taobao6982/tianchi_mobile_recommend_train_user.csv')# 取数据的前5行数据
data.head()
运行结果:
user_id item_id behavior_type user_geohash item_category time
0 98047837 232431562 1 NaN 4245 2014-12-06 02
1 97726136 383583590 1 NaN 5894 2014-12-09 20
2 98607707 64749712 1 NaN 2883 2014-12-18 11
3 98662432 320593836 1 96nn52n 6562 2014-12-06 10
4 98145908 290208520 1 NaN 13926 2014-12-16 21
# 查看详细的信息
data.info()运行结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12256906 entries, 0 to 12256905
Data columns (total 6 columns):
user_id int64
item_id int64
behavior_type int64
user_geohash object
item_category int64
time object
dtypes: int64(4), object(2)
memory usage: 561.1+ MB
# 查看重复值
data.duplicated().sum()运行结果:
4092866
# 删除重复值
data.drop_duplicates(inplace=True)# 查看缺失值
data.isnull().sum()运行结果:
user_id 0
item_id 0
behavior_type 0
user_geohash 4308015
item_category 0
time 0
dtype: int64
存在缺失值的是user_geohash,有4308015条,不能删除缺失值,因为地理信息在数据集收集过程中做过加密转换,因此对数据集不做处理。
# 由于缺失值为地理信息,对用户行为分析无影响,不做处理。axis=1列操作,axis=0行操作。
data.drop('user_geohash',axis=1,inplace=True)
data.head()运行结果:
user_id item_id behavior_type item_category time
0 98047837 232431562 1 4245 2014-12-06 02
1 97726136 383583590 1 5894 2014-12-09 20
2 98607707 64749712 1 2883 2014-12-18 11
3 98662432 320593836 1 6562 2014-12-06 10
4 98145908 290208520 1 13926 2014-12-16 21
# 重置索引
data = data.reset_index(drop=True)用户行为发生的时间有日期和小时构成,需要将该列进行拆分,以便进行后续的分析操作。
# 数据类型转换
data['time'] = pd.to_datetime(data['time'])
# 将time列拆分为data列和hour列,用做不同时间维度的分析
data['date'] = data['time'].dt.date
data['date'] = pd.to_datetime(data['date'])
data['hour'] = data['time'].dt.hour
data.head()运行结果:
user_id item_id behavior_type item_category time date hour
0 98047837 232431562 1 4245 2014-12-06 02:00:00 2014-12-06 2
1 97726136 383583590 1 5894 2014-12-09 20:00:00 2014-12-09 20
2 98607707 64749712 1 2883 2014-12-18 11:00:00 2014-12-18 11
3 98662432 320593836 1 6562 2014-12-06 10:00:00 2014-12-06 10
4 98145908 290208520 1 13926 2014-12-16 21:00:00 2014-12-16 21
# 查看详细的信息
data.info()运行结果:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 8164040 entries, 0 to 8164039
Data columns (total 7 columns):
user_id int64
item_id int64
behavior_type int64
item_category int64
time datetime64[ns]
date datetime64[ns]
hour int64
dtypes: datetime64[ns](2), int64(5)
memory usage: 436.0 MB
# 将item_id和item_category转换成str数据类型
data.item_id = data.item_id.astype(str)
data.item_category = data.item_category.astype(str)
# 查看转换后的数据类型
data['item_id'].dtype
运行结果:
dtype('0')
# 删除time这一列
data.drop(labels='time',axis=1,inplace=True)
# 查看数据统计信息
data.describe(include = ['object'])运行结果:
item_id item_category
count 8164040 8164040
unique 2876947 8916
top 112921337 1863
freq 953 264030
通过观察数据集的四分位数、总数、平均值、方差等,发现数据集并无异常值存在。
数据分析
构建模型 用户行为分析
时间维度的活跃度
# 取数据的前5行数据
data.head()运行结果:
user_id item_id behavior_type item_category date hour
0 98047837 232431562 1 4245 2014-12-06 2
1 97726136 383583590 1 5894 2014-12-09 20
2 98607707 64749712 1 2883 2014-12-18 11
3 98662432 320593836 1 6562 2014-12-06 10
4 98145908 290208520 1 13926 2014-12-16 21
PV(访问量):Page View,具体是指页面浏览量或者点击量,页面被刷新一个就计算一次。
UV(独立访客):Unique Visitor,访问网站的每一个IP为一个访客。
每天活跃度的变化
计算出日访问量,日独立访客量和人均访问量,封装成一个新的df
# 日访问量 pv (page views)
pv_daily_s = data.groupby(by='date')['user_id'].count()
pv_daily_s.head()运行结果:
date
2014-11-18 235493
2014-11-19 233144
2014-11-20 226523
2014-11-21 213894
2014-11-22 232994
Name: user_id, dtype: int64
# 日独立访客量 uv (unique visitors) 去重操作
uv_daily_s = data.groupby(by='date')['user_id'].nunique()
uv_daily_s.head()运行结果:
date
2014-11-18 6343
2014-11-19 6420
2014-11-20 6333
2014-11-21 6276
2014-11-22 6187
Name: user_id, dtype: int64
# 人均访问量 (日访问量/日独立访客量),也叫访问深度
uv_pv_s = pv_daily_s / uv_daily_s
uv_pv_s.head()date
2014-11-18 37.126439
2014-11-19 36.315265
2014-11-20 35.768672
2014-11-21 34.081262
2014-11-22 37.658639
Name: user_id, dtype: float64
# 形成新的数据表
df = pd.concat((pv_daily_s,uv_daily_s,uv_pv_s),axis=1)
df.columns = ['pv','uv','pv/uv']
df.head()运行结果:
pv uv pv/uv
date
2014-11-18 235493 6343 37.126439
2014-11-19 233144 6420 36.315265
2014-11-20 226523 6333 35.768672
2014-11-21 213894 6276 34.081262
2014-11-22 232994 6187 37.658639
数据可视化
# 绘制 pv 日访问量 折线图
plt.plot(df.index,df.pv)
plt.title('日访问量')
plt.xticks(rotation=30)
plt.show()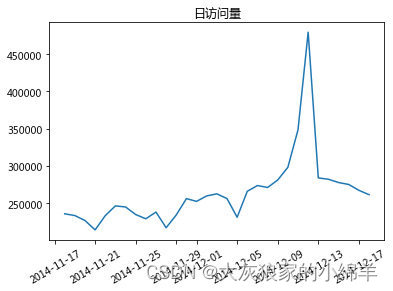
# 绘制 uv 日独立访客量 折线图
plt.plot(df.index,df.uv)
plt.title('日独立访客量')
plt.xticks(rotation=30)
plt.show()

结论:通过图形观察,发现在双12期间,pv和uv访问量达到峰值,并且可以发现,uv和pv两个访问量数值差距比较大。
UV 日独立访客量,在一阶段升高,但是PV 日访问量 降低,说明网站的弹出率升高了,需要对网站或者直接来了就走的那些人进行观察分析,分析是什么原因导致弹出:
1、用户没有看到想看的东西就走了。也就是说关键词和着陆页的相关性较低。
2、还是用户没有看到想看的东西。这个时候检查一下你的关键词是不是设置成广泛匹配了。
3、着陆页体验太差,用户可能在你的网站上看到了想要的东西。但是浏览选择很不顺畅。
4、还是着陆页的问题。是你的网页打开速度太慢。
# 绘制 人均访问量 (日访问量/日独立访客量) 折线图
plt.plot(df.index,df['pv/uv'])
plt.title('人均访问量')
plt.xticks(rotation=30)
plt.show()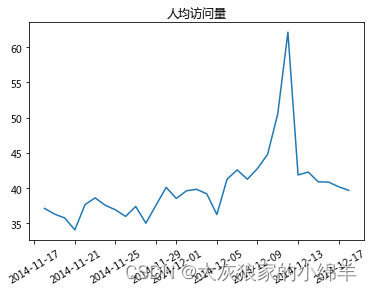
结论:
在12月5日之前,活跃度在一定水平上波动。12月5日后,活跃度开始明显上升,并在双十二当天达到峰值。可能原因:
12月5日之后双十二预热活动开始,用户活跃度上升。双十二当天活跃度的变化,选择双十二当天的数据,分析其活跃时间段:
双12当天每小时的访问量
双12当天每小时的访客量
双12当天每小时的人均访问量
形成一个新的df
# 取出双12当天的数据
data_1212 = data.loc[data['date']=='2014-12-12']
# 查看双12当天每小时的访问量
pv_hour_s = data_1212.groupby(by='hour')['user_id'].count()
# 查看双12当天每小时的访客量
uv_hour_s = data_1212.groupby(by='hour')['user_id'].nunique()
# 查看双12当天每小时的人均访问量
pv_uv_s = pv_hour_s / uv_hour_s
# 形成新的数据表
df = pd.concat((pv_hour_s,uv_hour_s,pv_uv_s),axis=1)
df.columns = ['pv_hour','uv_hour','pv/uv']
df.head()运行结果:
pv_hour uv_hour pv/uv
hour
0 25075 1569 15.981517
1 11388 811 14.041924
2 5956 411 14.491484
3 3177 255 12.458824
4 2567 211 12.165877
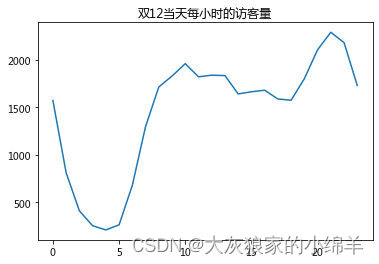
# 绘制 pv 双12当天每小时的访问量 折线图
plt.plot(df.index,df.pv_hour)
plt.title('双12当天每小时的访问量')
plt.show()
# 绘制 uv 双12当天每小时的访客量 折线图
plt.plot(df.index,df.uv_hour)
plt.title('双12当天每小时的访客量')
plt.show()
# 绘制 pv/uv 双12当天每小时的人均访问量 折线图
plt.plot(df.index,df['pv/uv'])
plt.title('双12当天每小时的人均访问量')
plt.show()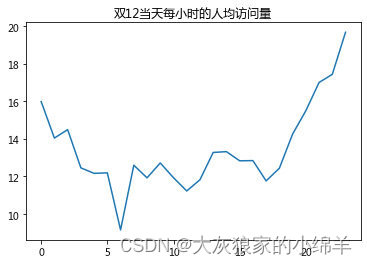
结论:双十二当天0点和18点之后淘宝用户活跃度较高,6点跌至最低点。
建议:商家可以在18点后设置优惠券或采取其他促销手段,吸引更多人消费,提高购买率。
结论:pv和uv在凌晨0-5点期间波动情况相同,都呈现下降趋势,访问量都比较小,同时在晚上18:00左右,pv波动情况比较剧烈,相比来看uv不太明显,所以,18:00以后是淘宝用户访问app的活跃时间。
用户行为活跃度变化
查看每天不同行为的各自的总量
提示:源数据中的一行数据表示一个用户的某一行为的数据
注意:aggfunc的count和size的区别
data.head()运行结果:
user_id item_id behavior_type item_category date hour
0 98047837 232431562 1 4245 2014-12-06 2
1 97726136 383583590 1 5894 2014-12-09 20
2 98607707 64749712 1 2883 2014-12-18 11
3 98662432 320593836 1 6562 2014-12-06 10
4 98145908 290208520 1 13926 2014-12-16 21
# 对数据按日期和行为类型进行分组,然后计算每个日期和行为类型组合的出现次数,并将结果放入透视表pv_df中。有助于在数据分析中了解不同日期和行为类型的关联关系和分布情况。
pv_df = data.pivot_table(index='date',columns='behavior_type',aggfunc='size',fill_value=0)
pv_df.head()运行结果:
behavior_type 1 2 3 4
date
2014-11-18 215480 6797 9800 3416
2014-11-19 213108 7079 9607 3350
2014-11-20 206740 7063 9552 3168
2014-11-21 196121 6722 8328 2723
2014-11-22 213292 7001 9493 3208
plt.plot(pv_df.index,pv_df[1],label='点击')
plt.plot(pv_df.index,pv_df[2],label='收藏')
plt.plot(pv_df.index,pv_df[3],label='加购物车')
plt.plot(pv_df.index,pv_df[4],label='支付')
plt.title('不同时期用户行为数据')
plt.xticks(rotation=30)
plt.legend()
plt.show()

结论:
点击、收藏、加购物车、支付这四种行为均在双12当天达到顶峰
只观察支付和收藏,发现双12当天支付量大于收藏量
支付量大于收藏量是说明很多用户购买了目标之外的商品,可能是受到促销的影响冲动消费,又或者是为了凑单等。
用户留存率
漏斗转化情况
查看不同行为的总量,封装到 df 中
单一环节转化率(%) - 各环节转换率作为新的列存在
计算 点击→收藏、收藏→加购,加购→支付的转化率
整体转化率(%) - 作为新的一列存在
计算 点击→收藏、加购和支付的整体转化率
每一环节流失率(%)
100 - 单一环节转化率
# 不同行为数量统计
s = data['behavior_type'].value_counts()
s运行结果:
1 7479078
3 333371
2 240919
4 110672
Name: behavior_type, dtype: int64
# 查看不同行为的访问量,封装到df中
s = data['behavior_type'].value_counts()
s.index = ['点击','加购物车','收藏','支付']
df = pd.DataFrame([s.index,s])
df运行结果:
0 1 2 3
0 点击 加购物车 收藏 支付
1 7479078 333371 240919 110672
# 查看不同行为的访问量,封装到df中
s = data['behavior_type'].value_counts()
s.index = ['点击','加购物车','收藏','支付']
df = pd.DataFrame([s.index,s]).T
df.columns = ['用户行为','访问量']
df运行结果:
用户行为 访问量
0 点击 7479078
1 加购物车 333371
2 收藏 240919
3 支付 110672
指标计算
# 计算点击到收藏、收藏到加购、加购到支付的转化率
temp1 = df['访问量'][1:].values
temp2 = df['访问量'][0:-1].values
p = temp1 / temp2 *100
p = list(p)
# 在列表 p 的索引位置 0 处插入一个新元素 100
p.insert(0,100)
p运行结果:
[100, 4.457380976639099, 72.26753376868413, 45.937431252827714]
# 数组格式
temp1运行结果:
array([333371, 240919, 110672], dtype=object)
temp2运行结果:
array([7479078, 333371, 240919], dtype=object)
# 每环节之间的转化率
df['单一环节转化率(%)'] = p
df运行结果:
用户行为 访问量 单一环节转化率(%)
0 点击 7479078 100.000000
1 加购物车 333371 4.457381
2 收藏 240919 72.267534
3 支付 110672 45.937431
# 计算整体转化率
df['整体转化率(%)'] = df['访问量'] / df.iloc[0,1] * 100
df运行结果:
用户行为 访问量 单一环节转化率(%) 整体转化率(%)
0 点击 7479078 100.000000 100
1 加购物车 333371 4.457381 4.45738
2 收藏 240919 72.267534 3.22124
3 支付 110672 45.937431 1.47975
# 计算每一环节流失率(%)
df['每一环节流失率(%)'] = 100 - df['单一环节转化率(%)']
df
运行结果:
用户行为 访问量 单一环节转化率(%) 整体转化率(%) 每一环节流失率(%)
0 点击 7479078 100.000000 100 0.000000
1 加购物车 333371 4.457381 4.45738 95.542619
2 收藏 240919 72.267534 3.22124 27.732466
3 支付 110672 45.937431 1.47975 54.062569
# 整体转化率的漏斗转化图
from pyecharts.charts import Funnel
from pyecharts import options as opts
funnel = Funnel().add(
series_name = '整体转化率(%)',
data_pair = [ list(z) for z in zip(df['用户行为'],df['整体转化率(%)']) ],
is_selected = True,
label_opts = opts.LabelOpts(position ='inside')
)
funnel.set_series_opts(tooltip_opts = opts.TooltipOpts(formatter = '{a}<br/>{b}:{c}%'))
funnel.set_global_opts( title_opts = opts.TitleOpts(title = '整体转化率(%)') )
funnel.render_notebook()
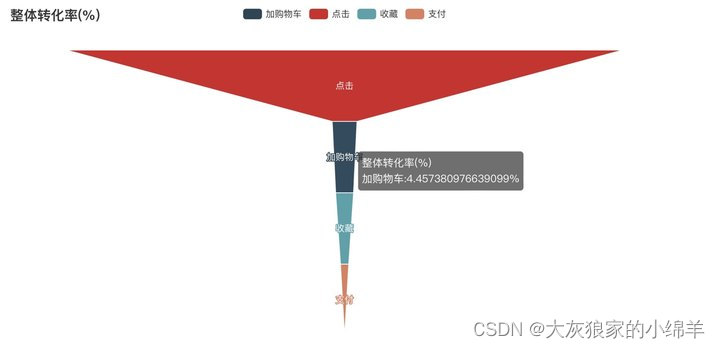
结论:用户的流失主要发生在点击→收藏环节
可能原因及建议
原因:用户被投放的广告吸引,进入后发现与预期严重不合,造成流失。
建议:优化广告。
原因:客户通过检索或推荐到列表页面但没找到合适的产品,造成流失。
建议:更新搜索引擎和相关算法,尽可能精准推送相关内容。
原因:如果商品的评价过低,造成流失。
建议:商家要做进一步调查,分析用户对商品评价低的原因,进一步改进,提升用户的购物体验,最终可以口碑营销。
收藏→加购物车环节流失
此类用户有较强的购买需求。可以对用户进行精准推送促销信息,刺激用户完成购买。加购物车→支付环节流失
原因:生成订单页面步骤过多。
建议:
(1)优化购物流程,尽可能支持多种支付方式,如银行卡、微信支付、支付宝支付、花呗等。
(2)考虑目前到淘宝的购物流程已经很难再简化,需要商家进一步调查,了解用户放弃支付的原因,方便做出调整。
用户留存率
留存率计算
分析次日留存率、3日留存率、7日留存率、14日留存率、30日留存率,通过留存率分析平台的用户粘性。
由于此处未能获得新用户的标识,故而此处将基期新用户数目替代为基期用户数目
from datetime import datetime
from datetime import timedelta
data_retain=pd.DataFrame(columns=['日期','基期用户数','次日留存率','3日留存率','7日留存率','14日留存率','30日留存率'])
date_max=pd.Series(data['date'].unique()).max()
# print(date_max)
# print(date_max+timedelta(days=1))
for date in pd.Series(data['date'].unique()).sort_values():
data_retain_base=set(data[data['date']==date]['user_id'].unique())
data_base_cnt=len(data_retain_base)
data_retain_2day=len(set(data[data['date']==date+timedelta(days=1)]['user_id'].unique()) & data_retain_base)/data_base_cnt if date+timedelta(days=1)<= date_max else 0
# print(data_retain_2day)
data_retain_3day=len(set(data[data['date']==date+timedelta(days=2)]['user_id'].unique()) & data_retain_base)/data_base_cnt if date+timedelta(days=2)<= date_max else 0
data_retain_7day=len(set(data[data['date']==date+timedelta(days=6)]['user_id'].unique()) & data_retain_base)/data_base_cnt if date+timedelta(days=6)<= date_max else 0
data_retain_14day=len(set(data[data['date']==date+timedelta(days=13)]['user_id'].unique()) & data_retain_base)/data_base_cnt if date+timedelta(days=13)<= date_max else 0
data_retain_30day=len(set(data[data['date']==date+timedelta(days=29)]['user_id'].unique()) & data_retain_base)/data_base_cnt if date+timedelta(days=29)<= date_max else 0
data_retain_item={'日期':[date],'基期用户数':[data_base_cnt],'次日留存率':[round(data_retain_2day,2)],'3日留存率':[round(data_retain_3day,2)],'7日留存率':[round(data_retain_7day,2)],'14日留存率':[round(data_retain_14day,2)],'30日留存率':[round(data_retain_30day,2)]}
# print(pd.DataFrame(data_retain_item))
data_retain_item=pd.DataFrame(data_retain_item)
data_retain=pd.concat([data_retain,data_retain_item],axis=0,join='inner')
data_retain.index=range(0,data_retain.shape[0])
data_retain
运行结果:
日期 基期用户数 次日留存率 3日留存率 7日留存率 14日留存率 30日留存率
0 2014-11-18 6343 0.81 0.79 0.78 0.75 0.75
1 2014-11-19 6420 0.80 0.78 0.76 0.75 0.74
2 2014-11-20 6333 0.79 0.76 0.76 0.76 0.00
3 2014-11-21 6276 0.78 0.78 0.75 0.76 0.00
4 2014-11-22 6187 0.80 0.79 0.74 0.73 0.00
5 2014-11-23 6373 0.80 0.77 0.75 0.74 0.00
6 2014-11-24 6513 0.79 0.78 0.75 0.73 0.00
7 2014-11-25 6351 0.80 0.77 0.77 0.76 0.00
8 2014-11-26 6357 0.79 0.76 0.77 0.75 0.00
9 2014-11-27 6359 0.77 0.76 0.77 0.76 0.00
10 2014-11-28 6189 0.78 0.78 0.76 0.77 0.00
11 2014-11-29 6224 0.79 0.78 0.75 0.85 0.00
12 2014-11-30 6379 0.79 0.79 0.75 0.76 0.00
13 2014-12-01 6544 0.80 0.79 0.75 0.75 0.00
14 2014-12-02 6550 0.81 0.79 0.76 0.77 0.00
15 2014-12-03 6585 0.80 0.76 0.76 0.75 0.00
16 2014-12-04 6531 0.78 0.77 0.77 0.76 0.00
17 2014-12-05 6367 0.79 0.77 0.79 0.75 0.00
18 2014-12-06 6440 0.79 0.78 0.86 0.00 0.00
19 2014-12-07 6422 0.79 0.78 0.77 0.00 0.00
20 2014-12-08 6564 0.80 0.79 0.76 0.00 0.00
21 2014-12-09 6566 0.80 0.81 0.78 0.00 0.00
22 2014-12-10 6652 0.82 0.87 0.77 0.00 0.00
23 2014-12-11 6894 0.89 0.78 0.76 0.00 0.00
24 2014-12-12 7720 0.78 0.75 0.73 0.00 0.00
25 2014-12-13 6776 0.79 0.80 0.00 0.00 0.00
26 2014-12-14 6668 0.81 0.78 0.00 0.00 0.00
27 2014-12-15 6787 0.80 0.78 0.00 0.00 0.00
28 2014-12-16 6729 0.80 0.78 0.00 0.00 0.00
29 2014-12-17 6643 0.79 0.00 0.00 0.00 0.00
30 2014-12-18 6582 0.00 0.00 0.00 0.00 0.00
留存率因为天数不足无法计算的直接填0,在计算平均留存率时不考虑这些数据
留存率可视化
fig,ax = plt.subplots(figsize=(16,8))
ax.plot(data_retain['日期'],data_retain['次日留存率'],label='次日留存率')
ax.plot(data_retain['日期'],data_retain['3日留存率'],label='3日留存率')
ax.plot(data_retain['日期'],data_retain['7日留存率'],label='7日留存率')
ax.plot(data_retain['日期'],data_retain['14日留存率'],label='14日留存率')
ax.plot(data_retain['日期'],data_retain['30日留存率'],label='30日留存率')
ax.set_xlabel('日期', size=15)
ax.set_ylabel('留存率', size=15)
ax.set_title('留存率随日期变动', size=20)
ax.legend()
plt.show()

平均留存率
#计算平均留存率
print('平均次日留存率: '+str(round(data_retain[data_retain['次日留存率']!=0]['次日留存率'].mean(),4)))
print('平均3日留存率: '+str(round(data_retain[data_retain['3日留存率']!=0]['3日留存率'].mean(),4)))
print('平均7日留存率: '+str(round(data_retain[data_retain['7日留存率']!=0]['7日留存率'].mean(),4)))
print('平均14日留存率: '+str(round(data_retain[data_retain['14日留存率']!=0]['14日留存率'].mean(),4)))
print('平均30日留存率: '+str(round(data_retain[data_retain['30日留存率']!=0]['30日留存率'].mean(),4)))运行结果:
平均次日留存率: 0.7977
平均3日留存率: 0.7817
平均7日留存率: 0.7648
平均14日留存率: 0.7583
平均30日留存率: 0.745
结论:
从留存率折线图来看,各期限的用户留存率随日期推移变化不大,从平均留存率来看,随期限增加,虽然留存率有所下降,但下降平缓,总体留存率较为稳定。分析与建议:
用户留存率随日期推移变化不大,说明当前阶段平台对用户的粘性未发生显著变化;留存率随期限增加下降平缓说明平台对用户粘性较高,平台保留用户的能力较强。但通过平均次日留存率仅79%,说明短期留存率仍有较大的提升空间,可以通过有奖签到等方式提高短期留存率,长期留存率较为稳定,可以通过增加推送或者发放优惠券等方式,进一步提升长期中用户对平台的粘性。
复购情况分析
用户购买次数直方图
计算复购率 = 购买次数大于1的用户数量 / 有购买行为的用户总数
# 用户购买次数直方图
buy_df = data.loc[data['behavior_type'] == 4]
user_buy_s = buy_df.groupby(by='user_id')['behavior_type'].count()
plt.hist(user_buy_s,bins=50)
plt.show()
user_buy_s运行结果:

user_id
4913 6
6118 1
7528 6
7591 21
12645 8
54056 2
63348 1
79824 13
88930 23
100539 18
104155 4
109103 17
113251 5
113960 36
120873 3
134658 2
151617 28
156608 9
157097 15
189833 22
190327 7
191366 2
213655 15
217996 2
227293 8
230711 13
239485 8
247543 22
250843 27
263670 1
..
142060721 4
142061900 3
142064691 9
142073213 2
142081324 14
142095821 10
142120051 47
142126535 11
142128942 14
142128951 26
142138619 4
142144275 7
142151675 13
142168798 13
142181816 8
142204924 2
142216376 9
142227202 39
142244794 15
142265405 34
142306250 10
142306361 7
142337230 4
142358910 2
142368840 11
142376113 1
142412247 11
142430177 5
142450275 39
142455899 8
Name: behavior_type, Length: 8886, dtype: int64
# 计算复购率 = 购买次数大于1的用户数量 / 有购买行为的用户总数
reBuy_rate = user_buy_s[user_buy_s > 1].count() / user_buy_s.count() * 100
reBuy_rate运行结果:
91.44722034661264
结论:
2014年11月18日至2014年12月18日这一个月用户复购率高达91.45%
用户价值分析(REF模型)
对已购用户进行价值划分
各类用户占比
# 将已购用户的数据单独取出
buy_df = data.loc[data['behavior_type'] == 4]
buy_df.head()运行结果:
user_id item_id behavior_type item_category date hour
143 101260672 73008997 4 4076 2014-11-25 13
146 116730636 85319721 4 10079 2014-12-17 11
152 104811265 61764614 4 675 2014-12-01 13
177 106230218 238910858 4 12090 2014-12-03 11
198 100684618 271840783 4 12220 2014-11-23 18
buy_df['date'].max()运行结果:
Timestamp('2014-12-18 00:00:00')
list(buy_df.groupby(by='user_id')['date'])[3]运行结果:
(7591, 625981 2014-12-06
626385 2014-11-25
626392 2014-12-02
626532 2014-12-04
1605162 2014-12-10
1605542 2014-12-12
2979569 2014-12-12
4473350 2014-12-04
4473479 2014-12-03
5438459 2014-12-10
5438669 2014-12-12
5752184 2014-12-12
5752429 2014-12-13
6839354 2014-12-13
6839637 2014-12-10
7140622 2014-12-11
7140676 2014-12-10
7140785 2014-12-06
7770509 2014-12-11
7770801 2014-12-04
7770812 2014-12-11
Name: date, dtype: datetime64[ns])
# 计算R:R表示客户最近一次交易时间的间隔
#/np.timedelta64(1,'D') 去出days
now_date = buy_df['date'].max()
R = buy_df.groupby(by='user_id')['date'].apply(lambda x:now_date - x.max()) / np.timedelta64(1,'D')
R.head()运行结果:
user_id
4913 2.0
6118 1.0
7528 5.0
7591 5.0
12645 4.0
Name: date, dtype: float64
# 计算F:每个用户消费频率
F = buy_df.groupby(by='user_id')['date'].count()
F.head()
运行结果:
user_id
4913 6
6118 1
7528 6
7591 21
12645 8
Name: date, dtype: int64
pd.DataFrame(data=[R,F],index=['R','F'])运行结果:
user_id 4913 6118 7528 7591 12645 54056 63348 79824 88930 100539 ... 142306250 142306361 142337230 142358910 142368840 142376113 142412247 142430177 142450275 142455899
R 2.0 1.0 5.0 5.0 4.0 11.0 7.0 2.0 1.0 2.0 ... 5.0 0.0 5.0 4.0 2.0 10.0 3.0 0.0 5.0 14.0
F 6.0 1.0 6.0 21.0 8.0 2.0 1.0 13.0 23.0 18.0 ... 10.0 7.0 4.0 2.0 11.0 1.0 11.0 5.0 39.0 8.0
2 rows × 8886 columns
# 交易金额缺失,只考虑最后交易日期和交易频率两个维度
rfm = pd.DataFrame(data=[R,F],index=['R','F']).T
rfm.head()运行结果:
R F
user_id
4913 2.0 6.0
6118 1.0 1.0
7528 5.0 6.0
7591 5.0 21.0
12645 4.0 8.0
# 将各维度分成两个程度
recent_avg = rfm['R'].mean()
freq_avg = rfm['F'].mean()
# R 是越小越好,则 R 小于均值返回1,否则返回0
def rec_value(x):
if x < recent_avg: # R avg
return '1'
else:
return '0'
# F 是越大越好,则 R 大于均值返回1,否则返回0
def freq_value(x):
if x > freq_avg:
return '1'
else:
return '0'
rfm['R_value'] = rfm['R'].apply(rec_value)
rfm['F_value'] = rfm['F'].apply(freq_value)
# 将T和F拼接到一起
rfm['rfm'] = rfm['R_value'].str.cat(rfm['F_value'])
rfm['rfm'].head()运行结果:
user_id
4913 10
6118 10
7528 10
7591 11
12645 10
Name: rfm, dtype: object
# 根据R和F的拼接判定用户等级
def rfm_value(x):
if x == '10': # 购买间隔短,但是购买频率低
return '重要发展客户'
elif x == '01': # 购买间隔长,但是购买频率高
return '重要保持客户'
elif x == '00':
return '重要挽留客户'
else:
return '重要价值客户' # 11
rfm['user_type'] = rfm['rfm'].apply(rfm_value)
rfm.head()运行结果:
R F R_value F_value rfm user_type
user_id
4913 2.0 6.0 1 0 10 重要发展客户
6118 1.0 1.0 1 0 10 重要发展客户
7528 5.0 6.0 1 0 10 重要发展客户
7591 5.0 21.0 1 1 11 重要价值客户
12645 4.0 8.0 1 0 10 重要发展客户
# 各类用户占比
user_type_count_s = rfm['user_type'].value_counts()
user_type_count_s / user_type_count_s.sum() * 100运行结果:
重要挽留客户 34.233626
重要发展客户 33.400855
重要价值客户 27.143822
重要保持客户 5.221697
Name: user_type, dtype: float64
结论(案例):
1.重要换留客户:占比最大,该用户消费时间间较远,并目消费频次低。需要主动联系客户,调查清禁哪里出现了问题,可以通过短信,邮件,APP推送等唤醒客户,尽可能减少流失。
2.重要发展客户:消费频次低,可以适当给点折扣或捆绑销售来增加用户的购买频率,尽可能提高留存率。
3.重要价值客户:为重点用户,但用户比较少。可以针对性地给这类客户提供 VIP服务
4.重要保持客户:消费时间间隔较远,但是消费频次高。该类用户可能一次性购买很多东西。对于这类客户,需要主动联系,关注他们的购物习性做精准化营销,及时满足这类用户的需求。
R、F值百分位分布情况
为后续R、F打分提供指导依据。
rfm.describe()运行结果:
R F
count 8886.000000 8886.000000
mean 5.811839 12.454648
std 6.678478 17.734442
min 0.000000 1.000000
25% 1.000000 4.000000
50% 4.000000 8.000000
75% 7.000000 16.000000
max 30.000000 770.000000
计算R、F得分,并得出R、F值的高低
#对R、F打分:
def r_score(x):
if x<=2:
return 5
if x>=3 and x<=5:
return 4
if x>=6 and x<=8:
return 3
if x>=9 and x<=17:
return 2
if x>=18:
return 1
def f_score(x):
if x==1:
return 1
if x==2:
return 2
if x==3:
return 3
if x==4:
return 4
if x>=5:
return 5
rfm["R_SCORE"]=rfm["R"].map(r_score)
rfm["F_SCORE"]=rfm["F"].map(f_score)rfm["R>R_MEAN"]=rfm["R_SCORE"]>rfm["R_SCORE"].mean()
rfm["F>F_MEAN"]=rfm["F_SCORE"]>rfm["F_SCORE"].mean()
rfm.head()运行结果:
R F R_value F_value rfm user_type R_SCORE F_SCORE R>R_MEAN F>F_MEAN
user_id
4913 2.0 6.0 1 0 10 重要发展客户 5 5 True True
6118 1.0 1.0 1 0 10 重要发展客户 5 1 True False
7528 5.0 6.0 1 0 10 重要发展客户 4 5 True True
7591 5.0 21.0 1 1 11 重要价值客户 4 5 True True
12645 4.0 8.0 1 0 10 重要发展客户 4 5 True True
计算各类客户数量、占比并可视化
rfm["user_type"].value_counts()运行结果:
重要挽留客户 3042
重要发展客户 2968
重要价值客户 2412
重要保持客户 464
Name: user_type, dtype: int64
rfm["user_type"].value_counts(True)运行结果:
重要挽留客户 0.342336
重要发展客户 0.334009
重要价值客户 0.271438
重要保持客户 0.052217
Name: user_type, dtype: float64
#不同价值客户占比图
fig,ax = plt.subplots(figsize=(12,6))
label=rfm["user_type"].value_counts(True).index.tolist()
num=np.array(round(rfm["user_type"].value_counts(True),4).tolist())
# print(num)
# print(label)
plt.pie(num,
labels=rfm["user_type"].value_counts(True).index.tolist(),
autopct='%.2f%%',
textprops={'fontsize': 14})
plt.title("不同价值客户占比", size=20)
plt.show()
结论及建议
结论:
根据RFM用户价值分析对用户进行分类,其中重要发展用户和重要挽留用户各占约30%,重要价值用户占约20%,重要保持用户占约5%。
分析与建议:应针对不同价值的用户采取不同的运营策略。总的来说,应当提升重要价值用户占比,减少重要挽留用户占比。
重要价值用户:主要提升该部分用户的满意度,服务升级,发放专属特别优惠,推送推广时也应当注意频率和方式,提升用户体验。
重要发展用户:最近消费时间间隔小,但消费频率不高,需要提高其消费频率,可在每次购买商品收货后提供限时代金券、限时优惠券等,提升下一步的消费欲望。
重要保持用户:交易频繁但最近无交易,可以向该类用户增加活动优惠、相关商品的推送频率等,唤回该部分用户。
重要挽留用户:最近消费时间间隔大,且消费频率低,这类用户即将流失,发放调查问卷调查用户体验找出问题原因,想办法挽留客户,若是价格原因则推送优惠券,若是推送不准确则改进推送机制。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











