









 本文详细描述了如何定期将生产环境的Oracle数据库恢复到测试环境服务器,包括创建备份目录、获取备份文件、调整db_name、恢复控制文件和数据文件,以及处理可能遇到的问题,如数据库升级和验证恢复效果。
本文详细描述了如何定期将生产环境的Oracle数据库恢复到测试环境服务器,包括创建备份目录、获取备份文件、调整db_name、恢复控制文件和数据文件,以及处理可能遇到的问题,如数据库升级和验证恢复效果。
一 目的
定期将生产环境oracle数据库恢复到一台测试环境数据库服务器上,以验证备份是否有效,是否能正常恢复。
二 环境
这里以恢复orcl1库为例,计划在orcl这个实例上进行恢复测试。

三 实验步骤
3.1 在目标端创建和源端一样的备份目录
① 查看下源端备份脚本,确定备份目录。
这里是/backup/日期
示例:
202404080100
② 在目标端创建全备目录
su - oracle
mkdir -p /backup/202404080100
3.2 获取源端备份文件
如果备份文件上传到了ftp服务器上的话,则这样获取:
cd /backup/
vi downloadbak.sh
添加如下内容:
cd /backup/202404080100
ftp -ivn <<!
open ftp服务器ip
user 账号/密码
bin
cd 备份路径
mget *
bye
!
#开始下载备份
nohup sh downloadbak.sh > downloadbak.log 2>&1 &
tail -f downloadbak.log
检查日志和备份文件数量,大小,确保都下载成功了。
下载完毕后,最后一行会输出如下:
221 Goodbye. You uploaded 0 bytes and downloaded 20345794.00 KB.
3.3 确保目标端db_name和源端保持一致
如果不一致,后面恢复完控制文件,将数据库启动到mount状态时会报错:
ORA-01103: 控制文件中的数据库名 ''ORCL1'' 不是 ''ORCL''。
修改示例:
示例:
create pfile='/home/oracle/temp.ora' from spfile;
vi /home/oracle/temp.ora
将*.db_name='orcl'改为*.db_name='orcl1'
shutdown immediate;
startup nomount pfile='/home/oracle/temp.ora';
create spfile from pfile='/home/oracle/temp.ora';
show parameter db_name; #检查确认
3.4 在目标端恢复数据
3.4.1 恢复控制文件
3.4.1.1 将目标端数据库启动至nomount状态
SQL> shutdown immediate;
SQL> startup nomount;
3.4.1.2 查询源端dbid
SQL> select dbid from v$database;
DBID
----------
1368003574
3.4.1.3 在目标端恢复控制文件
#指定dbid为3.4.2查询到的源端dbid
RMAN> set dbid 1368003574;
executing command: SET DBID
#恢复控制文件
RMAN>restore controlfile from '/backup/202404080100/orcl_ctl0_20240408_ORCL1_5756_1';
/*
从哪个备份文件恢复控制文件,这个值需要先从主库进行查询下,每次值都不一样的:
list backup of controlfile;
*/
3.4.2将数据库启动到mount状态
RMAN> alter database mount;
3.4.3 恢复数据库
--在恢复前,先删除下测试环境恢复库的数据文件和redo log文件。
删除数据文件一是为了释放空间,二是不删除的话,到时恢复完后分不清是以前的数据文件,还是新的数据文件。
删除redo log文件是为了避免后面恢复完后,启动数据库报错。
#删数据文件
cd /data/app/oracle/oradata/orcl
rm -rf data_D-*
#删redo
rm -rf redo*.log
#加载备份目录,删除过期备份。
catalog start with '/backup/202404080100';
report schema;
crosscheck backup;
delete expired backup;
#将输出放日志里,方便看错误,也方便看restore用了多长时间。
cd ~/baidd/
rman target / log restore.log append
run {
allocate channel t1 type disk;
allocate channel t2 type disk;
allocate channel t3 type disk;
allocate channel t4 type disk;
allocate channel t5 type disk;
allocate channel t6 type disk;
allocate channel t7 type disk;
allocate channel t8 type disk;
allocate channel t9 type disk;
allocate channel t10 type disk;
set newname for database to '/data/app/oracle/oradata/orcl/%U';
restore database;
switch datafile all;
switch tempfile all;
}
restore用时较长,等restore成功后,再recover。
#可以这样查看restore进度:
tail -f restore.log
执行sql查看进度
select sid,
serial#,
context,
sofar,
totalwork,
round(sofar / totalwork * 100, 2) "%_complete"
from v$session_longops
where opname like 'RMAN%'
and opname not like '%aggregate%'
and totalwork != 0
and sofar<>totalwork;
示例:

rman restore完毕后,就查看不到输出结果了。
#检查restore.log是否有报错:
less restore.log
exit
rman target /
recover database;
假如恢复库的时候报类似这样的错:
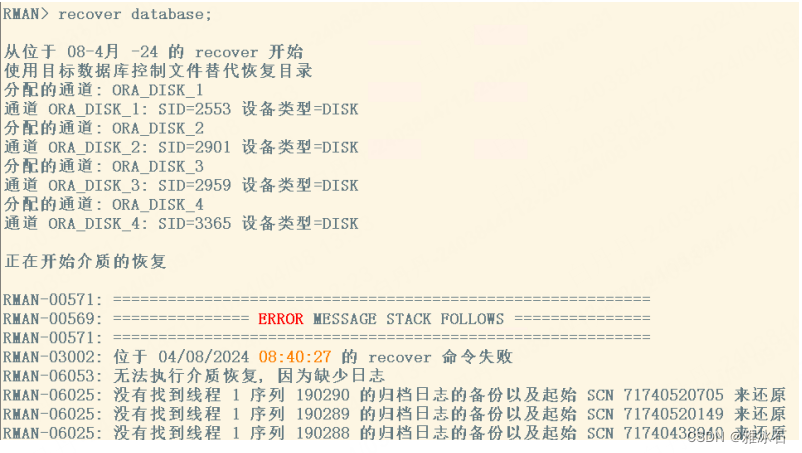
则在目标端查看下归档日志备份,找到最新的一个归档日志的next_scn:
list backup of archivelog all;
recover database until scn=找到的SCN值
如果是RAC,需要指定thread的话,可以这样:
recover database until sequence 197315 thread 2;
3.4.4 启动数据库
3.4.4.1 检查源端redo log所在路径在目标环境是否存在
存在的话,可跳过这一步,执行‘3.4.4.2 启动数据库’。
不存在的话,将redo log指定到一个已存在(有该目录)的路径下,再启动数据库,否则启动数据库会报错:
ORA-00349: 无法获得 '/oracle/app/oracle/oradata/orcl/redo01.log' 的块大小
ORA-27041: 无法打开文件
Linux-x86_64 Error: 2: No such file or directory
Additional information: 9
假如启动库报了上面这个错,然后指定redo log到新位置了,再启动库,还会报这个错:
RMAN> alter database open resetlogs;
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: 位于 04/05/2024 10:58:27 的 sql statement 命令失败
ORA-00392: 日志 1 (用于线程 1) 正被清除, 不允许操作
ORA-00312: 联机日志 1 线程 1: '/data/app/oracle/oradata/orcl/redo01.log'
这就需要重新恢复了,需要确保在启动数据库之前,就rename redo log到一个存在目录的路径。
具体操作示例:
select member from v$logfile;
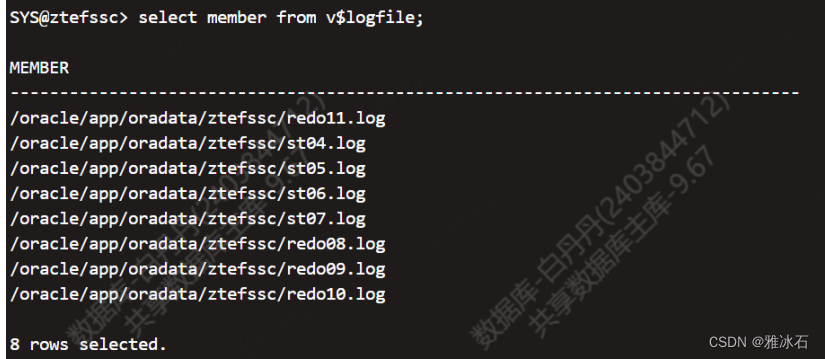
目标端没有这个目录:
/oracle/app/oradata/ztefssc
select 'alter database rename file '||''''||member||''''||' to '||chr(39)||replace(member,'旧路径','新路径')||''';'
from v$logfile;
示例:
select 'alter database rename file '||''''||member||''''||' to '||chr(39)||replace(member,'/oracle/app/oradata/ztefssc','/data/app/oracle/oradata/orcl')||''';' from v$logfile;
执行输出来的sql,重命名下redo log。
……
#检查确认
select member from v$logfile;
3.4.4.2 启动数据库
alter database open resetlogs;
启动完数据库后,会自动生成redo log。
#检查redo log是否生成。
cd /data/app/oracle/oradata/orcl
ls -l | grep redo
3.4.5 升级和更新数据字典
假如是从11g往12c恢复或者oracle小版本往大版本恢复,则需要升级和更新一下数据字典:
$ORACLE_HOME/bin/dbupgrade
如果是同版本实例,则不用做这一步。
#启动下目标端数据库
执行完$ORACLE_HOME/bin/dbupgrade后,发现数据库自动关闭了,将其起来:
startup;
3.5 验证
select username from dba_users;
查看下新用户有没有恢复过来。















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









