






概述
NFS 英文即 Network File System,网络文件系统,是由 SUN 公司研制的 UNIX 表示层协议( presentation layer protocol ),它最大的功能就是可以通过网络,让不同的机器、不同的操作系统可以共享彼此的文件,能使使用者访问网络上别处的文件就像在使用自己的计算机一样。
NFS 作为最常用的网络文件系统能够提供简单易用、功能强大的存储解决方案。得益于其简单、成熟、易使用等特性,几乎在 Linux 每一发行版本中都是标准组件。NFS 比较适合串行应用程序(串行读写文件)模式,而当系统和数据集数量增多时或并行读写文件,NFS 可能就不是最佳的解决方案了。本文主要介绍 NFS 存储在 HPC 场景应用可能存在的性能、一致性、负载均衡性等问题,帮助大家去理解为什么分布式并行存储系统更加适合大型 HPC 环境。
HPC 超算环境 NFS 可能存在的问题
存储 IO 负载不均衡
NFS 是 C/S (客户端(Client)/服务器(Server))架构的协议,由一个 NFS 客户端程序和 NFS 服务器程序组成。所以要求计算集群中每个计算节点都要挂载一个 NFS 服务器,而且挂载关系也是固定;在计算服务器开机的时候执行挂载动作,关机的时候再断开连接。
通常 HPC 超算集群中计算节点和存储节点的数量一般会是 6:1 或更高的比例,因此多台计算节点会挂载到同一台 NFS 存储服务器上。为获得最好性能,计算服务器与 NFS 服务器之间的对应关系要尽量保持均衡,见下图:
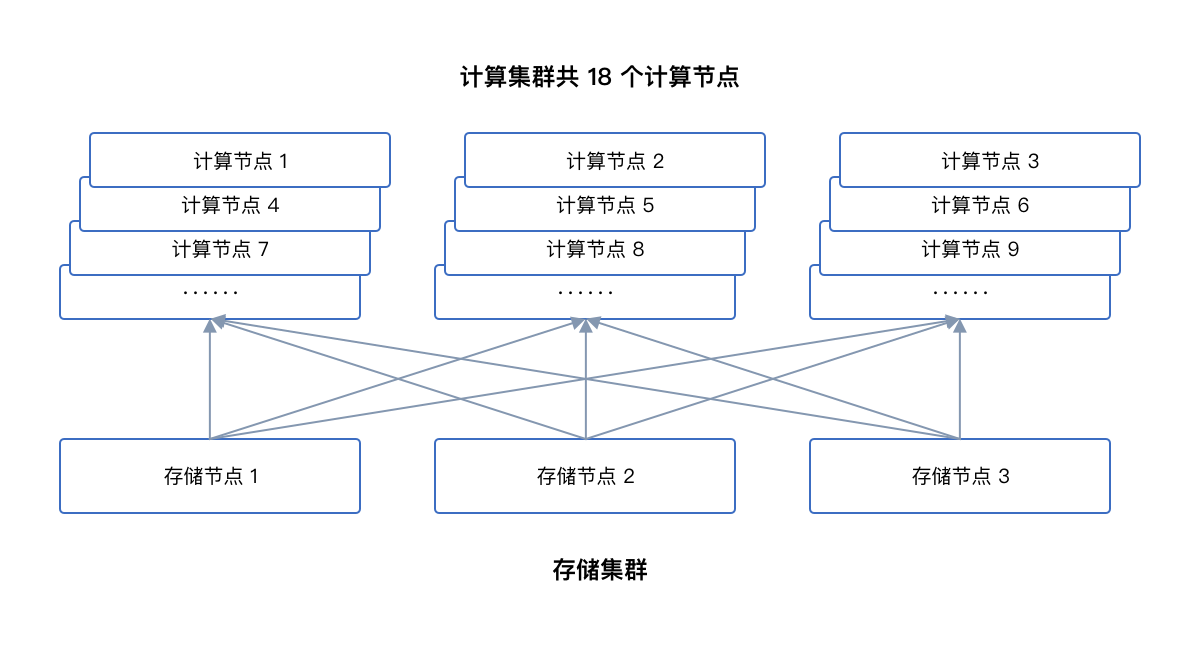
如图所示,一个由 18 台计算节点,3 台 NFS 存储服务节点(以下简称:存储节点)组成的 HPC 集群环境。通过 DNS 域名挂载功能通常能使每台存储节点比较均匀地被 6 台计算节点挂载。假设一个计算任务占用 6 台计算节点,这 6 台计算服务器是由作业调度软件随机分配的。最坏的情况下,这 6 台计算节点挂载的都是同一台存储节点。那么 6 台计算节点上的 MPI 集合 IO 操作都会压到这 1 台存储节点,即:NFS 存储服务器上。而另外 2 台存储节点则处于空闲状态,这就造成了2/3 的存储资源的浪费。
即便出现这类极端不均衡情形的概率不大,但中等不均衡状况出现的概率还是相当大的。比如,同样还是这个占用 6台计算节点的计算任务,其中有 4 台计算节点挂载到存储节点 1,另外 2 台计算节点分别挂载到了存储节点 2 和存储节点 3,即存储节点的负载比例是 4:1:1。然而 MPI-IO 中的集合 IO 结束时会有一个进程间同步,因此,聚合 IO 操作的速度取决于最慢进程的速度,即取决于负载最重的 NFS 服务器存储节点 1 的速度。
由于 NFS 的这种挂载机制,即:一旦挂载成功,客户端中途不会自动改变所挂载的 NFS 服务器,很容易出现存储 IO 负载不均衡的情况。而分布式并行文件系统(例如:YRCloudFile)的数据 IO 方式是不同的,首先私有客户端通过与存储集群的 MDS (元数据服务)通讯,并获得数据所在位置,之后客户端可以直接访问任意的 OSS(存储数据服务)节点,因此不存在类似的负载不均问题。
数据中转延迟高
NFS 客户端读写一个文件的时候只能向已挂载的 NFS 服务器发起请求,而文件数据被打散分布在多个 NFS 服务器上,所以 NFS 服务器上会有一个中转操作,见下图:

如上图所示,计算节点 1 需要向 NFS 存储节点 1 写入 3 个连续数据块 D0~D2,而数据块 D0~D2 分别放置在 NFS 存储节点 1-3上。因此,NFS 存储节点 1 需要在缓冲区暂存数据 D0~D2,将 D0 写入自己的本地硬盘,通过网络将 D1 和 D2 分别发送给 NFS 存储节点 2 和 3 。等 D0~D2 都正确地写入硬盘,存储服务器节点 1 才会向计算节点 1 返回写成功的信号。
如果将计算服务器与 NFS 存储节点(存储服务器)之间的数据流量称为外部流量,而将 NFS 存储节点之间的数据流量(数据中转所产生的流量)称为内部流量。显然上图中的外部流量为 9(9个数据块),内部流量为 6。由此可以推算出,当 NFS 存储节点的数量为 M 的时候,外部流量与内部流量的比例是 M:M-1。在存储节点数据较大( M 较大)时,例如:10 个存储节点,此时有效流量(外部流量)所占总流量的比例大约等于 50%,相当于将网络带宽上限降低于一半,严重影响文件系统性能。一个解决办法是单独配置网络设备(交换机、网卡)专为走内部流量使用,然而这样做无疑增加了成本。而且即使这样也仍然无法解决 IO 路径长的问题:文件数据从 NFS 客户端走到 NFS 服务器上的硬盘上,几乎都要走一个中转过程,必然导致延时变长。
我们来看一组对比,看看分布式并行存储(如:YRCloudFile )的 IO 路径,见下图,安装在计算节点上的 YRCloudFile 私有客户端先从元数据服务器( MDS )获得文件分布图( layout ),然后就知道了每一个数据块都存放在哪个 OSS 服务器的哪个位置, YRCloudFile 客户端直接从相应的 IO 服务器上读取数据块,没有中转,节省内部流量而且消除了中转延时。

文件锁和一致性问题
在大规模并发数据访问的场景,NFS 最严重的问题还是文件锁和一致性问题。首先我们来讨论一下文件锁的问题:
NFS 协议是为串行访问设计的,即每个客户端访问不同的文件,不支持多个客户端同时访问同一个文件。具体表现为,文件描述符(Open函数返回的文件句柄)不能共享,即:如果 N 个客户端想同时读写同一个文件,那么 N 个客户端都必须调用一次 open 函数以便得到文件描述符。这个 N 客户端虽然打开同一个文件,但客户端之间并不相互协调,相互不知道对方的动作,可能导致写冲突。
如下图,假设 NFS 客户端 C1 和 C2 同时写文件 f1.txt,C1 写的范围是[0-1023]字节,而 C2 写的范围是[512-1515]字节。按照 NFS 协议,C1 和 C2 之间是不相互协调的,那么就可能导致 C1 和 C2 同时写文件区间[512-1023],文件中最终数据不可预知。
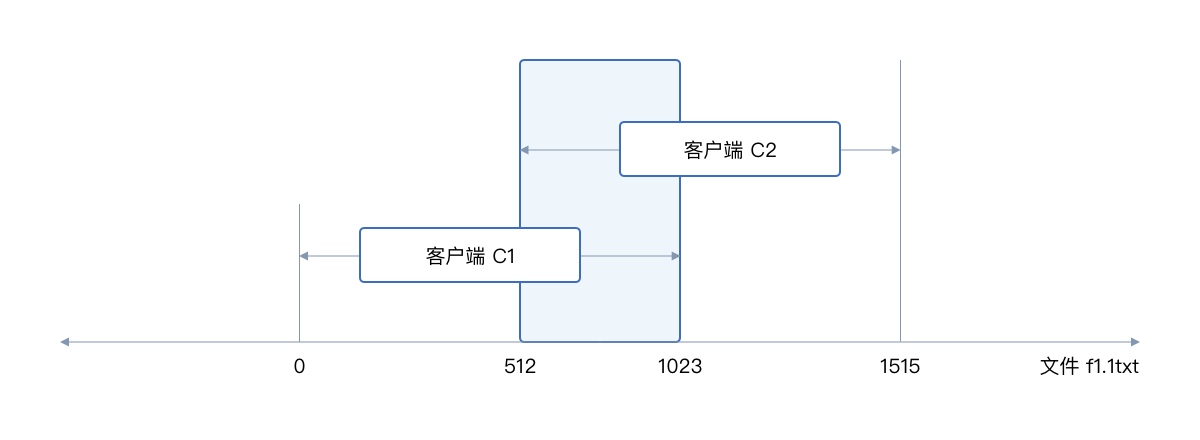
而为了避免数据冲突,需要使用文件锁函数 fcntl。在 C1 准备写文件的[0-1023] 字节时,先调用 fcntl 函数锁住这个文件区间,以便客户端 C1 独占操作。客户端 C2 写文件区间 [512-1023] 写数据时,文件系统发现区间[512-1023]被客户端 C1 锁住了,于是让客户端 C2 等待。只有当客户端 C1 写操作完成之后 C2 才能开始写。
fcntl 保证并行 IO 操作的正确性,代价是降低了性能。按照 MPI-IO 分析文章中的经验推断,集合 IO 涉及的 MPI 进程越多,锁竞争越激烈,性能下降越严重。
接下来再看看数据一致性的问题:
因为 NFS 设计时就没有考虑多个进程同时读写同一个文件的情况,所以 NFS 客户端就可以采用激进的缓存机制:不但缓存文件数据还缓存文件属性信息。文件属性包含:读、写、执行权限、*atime/*mtime/*ctime等。
这样一来,多个 MPI 进程聚合 IO 时就有文件同步的问题:如果开启了数据缓存机制,进程 A 通过 NFS 客户端 C1 写入文件区间[0-511],操作返回时,文件数据可能已经写到 NFS 服务器的硬盘上了,也可能还停留在 C1 客户端的缓存里。假设紧接着的 MPI 聚合 IO 操作要求进程 B 通过 NFS 客户端 2 读取文件区间[0-511],这时就会出现 3 种情况:
-
情况一:NFS 客户端1已经将文件区间[0-511]写入 NFS 服务器,且 NFS 客户端 1 也没有缓存区间[0-511]的数据。此时进程 B 通过客户端 2 读文件区间[0-511]的请求使得客户端 2 向 NFS 服务器请求文件数据,从而进程 B 能得到正确数据。
-
情况二:NFS 客户端 1 还没有将文件区间[0-511]写入 NFS 服务器,仍然保存在缓存中。此时 NFS 客户端 2 无论如何也读不到最新的数据,从而进程 B 能得到错误的旧数据。
-
情况三:NFS客户端 1 已经将文件区间[0-511]写入 NFS 服务器,而 NFS 客户端 2 本地缓存了文件属性和文件区间[0-511]的数据。进程 B 向客户端 2 请求读文件区间[0-511]时,客户端 2 就会对比文件数据缓存的更新时间和文件属性缓存中记录的文件最后修改时间( mtime 等)。因为客户端 1 不能主动向客户端 2 推送文件已经更新消息,而客户端 2 缓存的刷新又有一定的时间间隔,所以客户端 2 就可能得出错误的结论:缓存中的文件数据就是最新的,不用从 NFS 服务器重新读取。最终导致进程 B 读到错误的旧数据。
通过上面的分析,要保证 IO 结果正确的必要条件是:一个进程的操作结果能被其它进程立即看到,即:将写操作涉及的文件数据立即刷入 NFS 服务器,同时文件属性信息在进程间要保持同步,就能避免上述那些错误情况的发生。
要保证文件属性同步需要用 noac 选项关掉文件属性缓存,使得 NFS 客户端每次查看文件属性的时候都要向 NFS 服务器抓取。然而,关掉了缓存,就使得向 NFS 服务器写入、请求文件属性的次数大大增加,造成存储系统性能的下降。
性能对比:YRCloudFile 私有客户端 VS NFS 客户端
我们可以通过对 YRCloudFile 分布式文件存储系统实际环境的测试,来直观对比 NFS 和私有客户端在 IO 方面性能表现的差别。
硬件环境 
软件环境

网络拓扑图
 如上图所示,共 3 台存储节点,其中存储网络使用单口 25Gbps 网络相连,管理网络使用单口千兆网络相连。4 台客户端服务器,每台使用单口 25Gbps 网络与存储服务器连接。
如上图所示,共 3 台存储节点,其中存储网络使用单口 25Gbps 网络相连,管理网络使用单口千兆网络相连。4 台客户端服务器,每台使用单口 25Gbps 网络与存储服务器连接。
测试性能对比如下
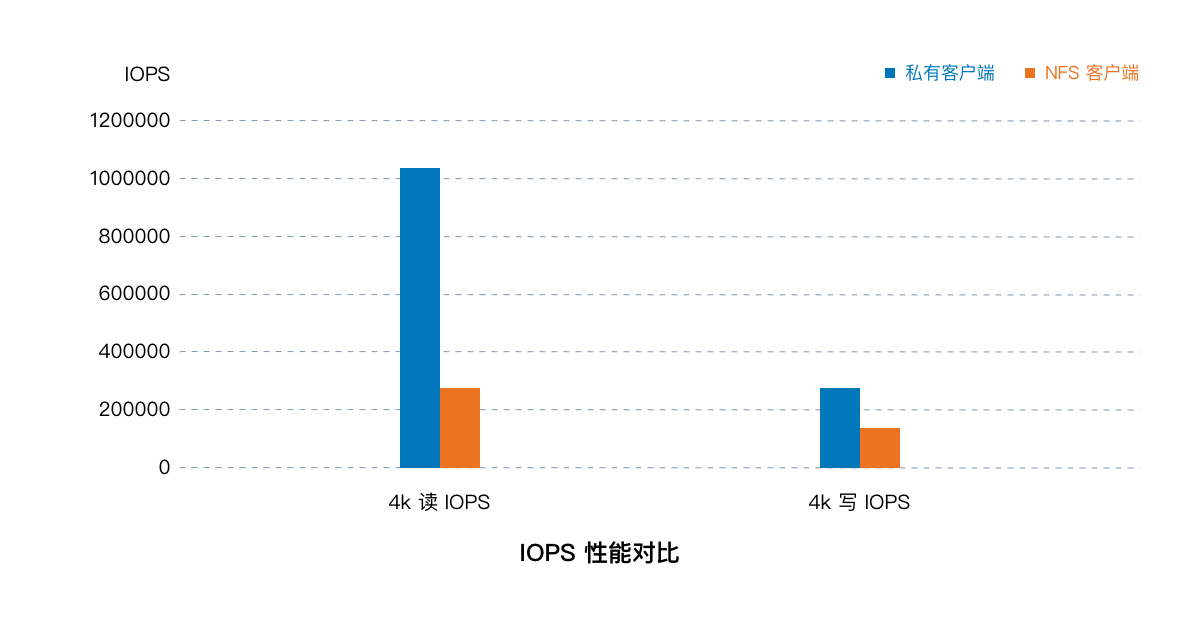
4K IOPS 性能测试
512K 带宽性能测试

从上面测试结果能够清晰的看出,私有客户端的性能明显高于通用的 NFS 客户端。
结论:YRCloudFile VS NFS
NFS 并不是一个高性能的协议,并不擅长处理大规模并发的数据访问。综上所示,在 HPC 等高并发场景中存在负载不均衡、数据中转 IO 路径长,以及为了保证一致性、避免数据写入冲突,而关闭了缓存和使用文件锁 fcntl 等所带来的诸多性能问题。HPC 环境会根据计算需求构建不同规模的分布式计算集群,并通过计算作业调度系统将计算任务被分布到各个计算节点。由于超算集群的数据量很大,要解决计算节点所带来的 IO 流量瓶颈问题,往往需要使用分布式架构的文件存储系统。
焱融科技分布式并行文件系统 YRCloudFile 区别于 NFS 存储客户端系统,可以直接访问所有存储节点以进行数据传输,而不必通过协议服务器。YRCloudFile 将文件数据切分并放置到多个存储设备中(各个被切分的数据如何放置,由并行文件系统通过算法来控制,可以基于元数据服务或类似一致性哈希的方式实现),系统使用全局名称空间来进行数据访问。通过 YRCloudFile 的客户端可以同时使用多个 IO 路径将数据读/写到多个存储设备。能够提为大规模、高并发的 HPC 计算群集提供卓越的存储性能。同时,配合预读策略可以有效的减少存储和应用程序的 I/O 等待时间,进一步提升存储的 I/O 性能。

*atime(access time,最后1次访问时间 );*mtime(modification time,最后修改时间)*ctime(change time,元数据的最后改变时间)















 3071
3071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









