







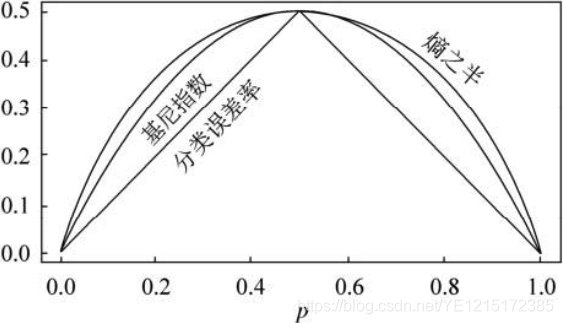
1、分类误差率
在二分类中,对于任意一个叶子节点,假设其中一个类别A占比(概率)为p,则另外一个类别B的占比(概率)就是1-p。那么,我们可以直观地将分类误差作为损失,即:
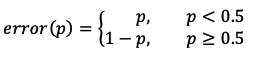
上式表示:当一个叶子类目中的类别A占比较多时(p>0.5),进入该叶子结点的样本就会被判别为类别A,那么剩下的占比为1-p的(类别B)样本则会被分类错误,随之产生的分类误差率就是1-p;反之,当叶子结点中类别A样本较少(p<=0.5)时,该叶子结点就表示类别B,所有进入该节点的类别A样本将会被分类错误,随之产生的分类误差率就是p.
2、基尼系数
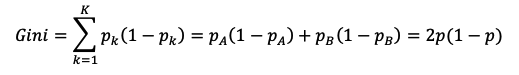
根据上式,当p=0.5时,基尼系数达到最大值0.5(集合最混乱),当p=0时,基尼系数的值最小为0(集合最纯净),基尼系数和p值的关系如上图所示。基尼系数表示一个集合中任意两个样本类别不一致的概率。对于叶子结点,我们希望结点中的样本类别尽可能地一致,因此我们也可以将基尼系数当做叶子结点的损失。
3、熵之半
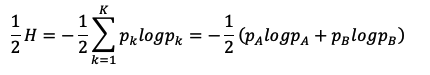
上面的公式即为二分之一熵,当p=0.5时,熵之半的值为-1/2*log1/2,即0.5;当p=1时,熵之半的值为0,熵之半和p值的关系如上图所示。熵和基尼系数其实是正相关的(https://blog.csdn.net/YE1215172385/article/details/79470926),都可以用来表示一个集合的混乱程度,值越大越混乱。因此,熵之半和基尼系数相似,也可以当作叶子结点的损失。

















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









