数据挖掘–统计学模块 02 数据的描述性统计 python代码合集
import pandas as pd
import numpy as np
import scipy.stats
df = pd.DataFrame(np.random.randint(0,40,40).reshape(20,2),columns=list("ab"))
print(df,"\n-----------------------")
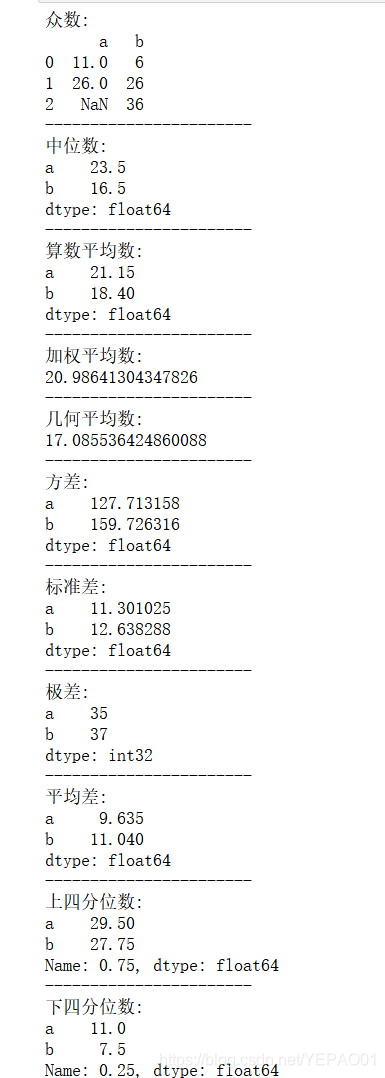
print("众数:\n{}".format(df.mode()),"\n-----------------------")
print("中位数:\n{}".format(df.median()),"\n-----------------------")
print("算数平均数:\n{}".format(df.mean()),"\n-----------------------")
print("加权平均数:\n{}".format((df["a"]*df["b"]).sum() / df["b"].sum()),"\n-----------------------")
print("几何平均数:\n{}".format(scipy.stats.gmean(df["a"])),"\n-----------------------")
print("方差:\n{}".format(df.var()),"\n-----------------------")
print("标准差:\n{}".format(df.std()),"\n-----------------------")
print("极差:\n{}".format(df.max() - df.min()),"\n-----------------------")
print("平均差:\n{}".format(df.mad()),"\n-----------------------")
print("上四分位数:\n{}".format(df.quantile(q=0.75)),"\n-----------------------")
print("下四分位数:\n{}".format(df.quantile(q=0.25)),"\n-----------------------")
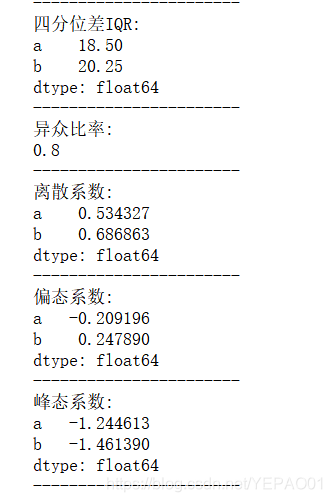
print("四分位差IQR:\n{}".format(df.quantile(q=0.75) - df.quantile(q=0.25)),"\n-----------------------")
print("异众比率:\n{}".format((df["a"].count() - df["a"].value_counts()[df["a"].mode()].sum())/ df["a"].count()),"\n-----------------------")
print("离散系数:\n{}".format(df.std() / df.mean()),"\n-----------------------")
print("偏态系数:\n{}".format(df.skew()),"\n-----------------------")
print("峰态系数:\n{}".format(df.kurt()),"\n-----------------------")























 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









