







目录
1.1 web简介:
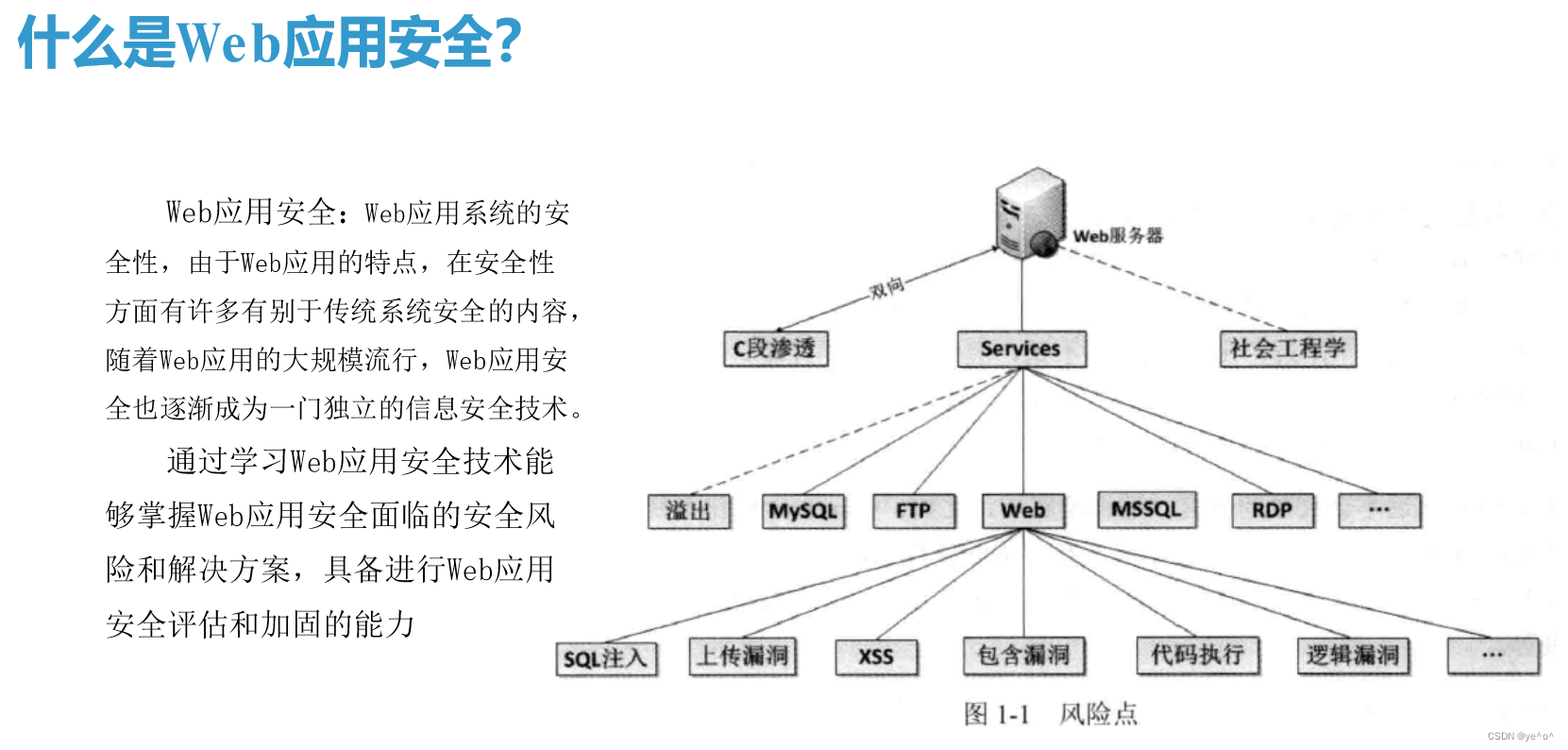
Web是万维网(World Wide Web, WWW)的简称,它利用HTTP (HyperText Transfer Protocol,超文本传输协议)来建立用户与服务器之间的标准交互方式。常用的Web应用都是基于网页形式开展的,即用户输入域名,利用HTTP协议发起访问请求。服务器接收到用户请求后,根据HTTP协议向用户返回响应页面。在这个过程中,HTTP协议规定了在当前请求中需要的参数,从而实现标准化的传输效果,如图1-1所示。

提供各种类型服务的Web网站非常多,网站是由多个页面组成,用户可通过浏览不同网来开展不同的业务。HTML (Hyper Text Markup Language,超文本标记语言)规定了Web应用的页面格式。使用HTML的好处在于规定了页面的基本格式后,用户端只要利用可以解析HTML格式的浏览器即可实现访问。如图1-2所示。
Web网站从早期只有浏览功能,逐渐发展到能支持用户进行自定义查询、支持用户登录并互动、在线交易等复杂业务。在这个过程中,需要添加额外的组件来实现上述功能。因此,目前的Web站点都会附带数据库及其他服务,从而实现对当前站点及用户信息的存储及复杂功能的支持。

下面来分析一个常见的Web应用:访问一个网站并做一次信息查询。这个过程中涉及的服务及功能流程如图1-3所示。
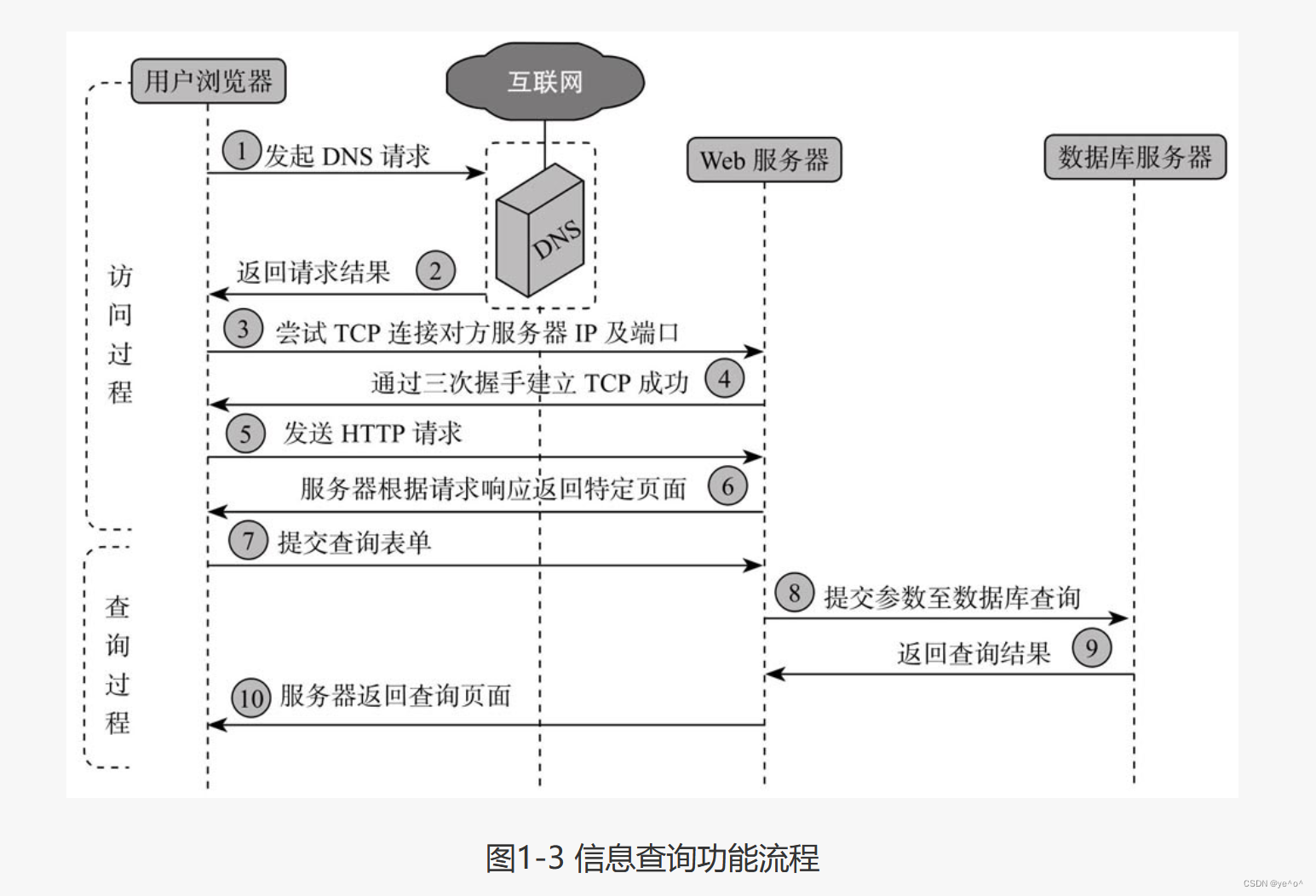
图中所示的流程与真实的大型网站应用流程并不完全一致,只用于说明基本原理。因为大型网
站要同时为数以千万的用户请求提供服务,仅通过一台服务器根本无法支持海量的用户访问请求,所以会利用负载均衡、CDN、云技术、分布式数据库等技术来应对大量用户的并发访问。值得说明的是,以上所有环节均可能存在安全隐患,其中一项服务产生问题都可能影响用户的正常使用或者危害Web服务器的安全。
1.1.1 web应用安全


由于网站后台具有更高的操作权限,往往是黑客攻击的重要目标。
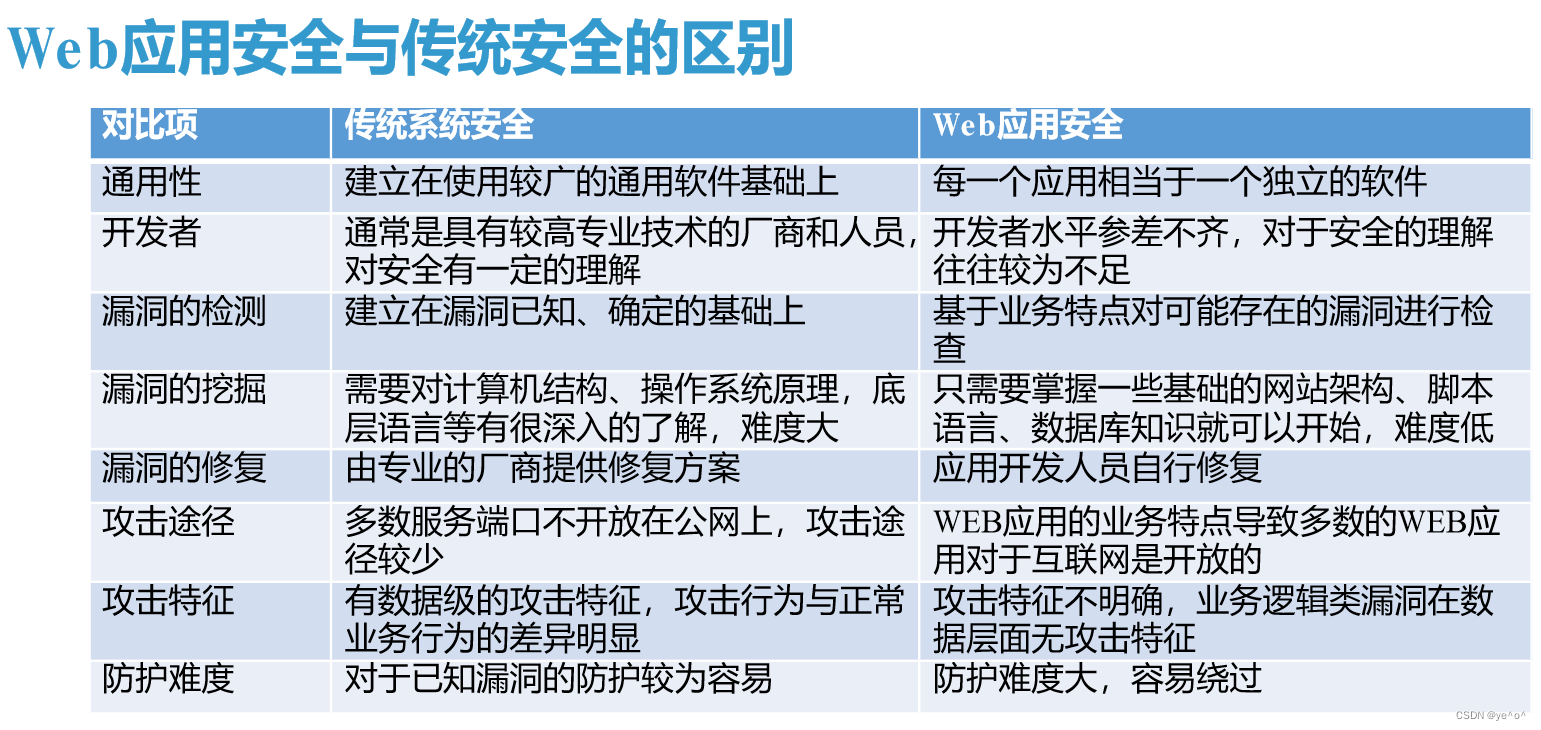
web应用安全与传统系统安全的区别
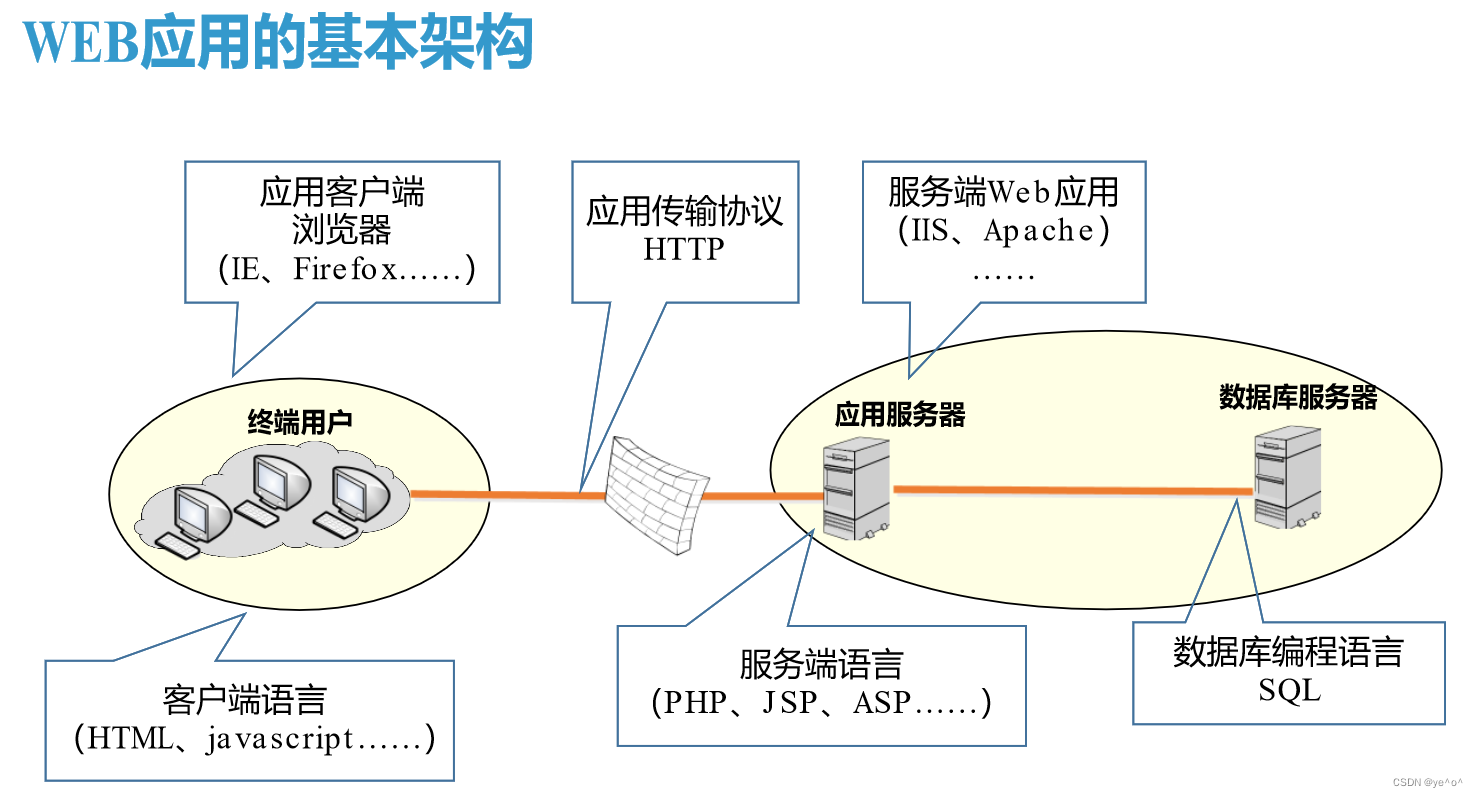
web应用基本架构

1.1.2 WEB安全核心问题
日益丰富的各类Web网站被Web用户使用,而且Web也不仅仅是利用浏览器访问站点。因此,在了解Web各类漏洞之前,我们先了解一下常见的Web应用表现形式。
1) Web应用不一定为用户可见页面,比如各类API接口,其原理是一个Web页面,并对用户请求的内容进行处理。
2) Web应用不一定要依托浏览器才能使用,例如,爬虫脚本的数据获取部分,只要能构造HTTP Request包即可开展对Web应用数据的获取。
3)并不一定需要标准的Web中间件,直接利用编程语言编写对应处理规则也可实现对用户请求的处理,但处理的过程就是中间件本来该执行的工作。
再思考一下Web应用的环境:
Web应用需要一台服务器提供基础资源,可运行操作系统,并配合中间件来为用户提供服务。如果站点功能较为复杂,那么还需要用数据库提供基础的数据存储支持,用文件服务器进行备份,用SAN系统提供高性能的文件存储等。在这个过程中,任何一个环节出现问题,都可能导致Web安全问题出现。
可以把Web应用环境类比为一个球队。球队中有负责打比赛的队员,有指导教练、领队、队医、后勤人员,它们共同为球队的运转服务,任何一个环节或岗位出现问题,都会影响球队的成绩。类似地,在Web系统中,无论有多少硬件设备、提供支持的组件有哪些,只要它们为Web提供支持,那么都要纳入防护体系。从安全角度考虑,Web应用中的中间件、数据库、操作系统等均会影响Web系统的安全,因此关注点并不能仅放在网页层面。
最后从交互角度来思考:
HTTP协议作为Web应用的基础协议,其特点就是用户请求-服务器响应。在这个过程中,服务器一直处于被动响应状态,无法主动获取用户的信息。再看一下HTML结构,服务器在完成用户响应后,当前的HTML页面会被发送到用户端的浏览器,这也就决定了客户端拥有HTML的全部结构及内容。基于这种交换环境,在客户端可篡改任何请求参数,服务器必须对请求内容进行响应。这也就决定了Web最核心的问题,用户端的所有行为均不可信。

最后总结一下Web存在安全隐患的核心问题:
1) Web应用类型复杂,防护经验无法复用。
2) Web应用包含的服务组件众多,任意一个组件出现问题都会影响整体的安全程度。
3)由于HTTP协议的特性,用户端的所有行为均不可信。
这些核心问题会贯穿在Web应用的每个漏洞中。
1.2 HTTP协议概述
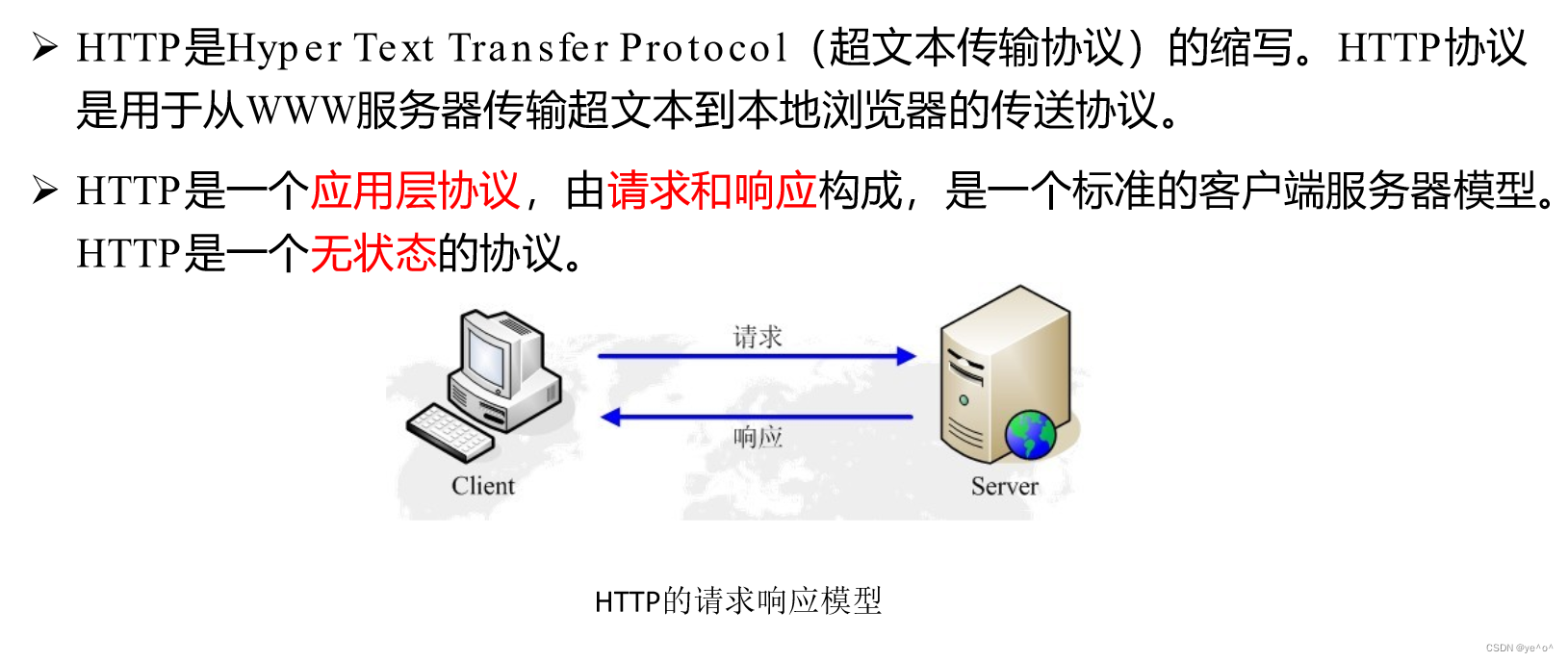
HTTP是一个应用层的面向对象的协议,由于其简捷、快速的特点,非常适合互联网应用。有了HTTP,用户利用浏览器即可访问不同的应用系统,避免了大量客户端的操作不便的情况。同时,这种由客户端发起请求、服务器根据用户请求进行处理的方式也非常适用于大规模的应用开展。
HTTP协议于1990年提出,经过多年的使用,不断完善和扩展,已逐渐成熟。在C/S模式为主的时代,HTTP支持的B/S (Browser/Server)模式能够从易用性、稳定性等方面满足用户个性化的需求。到目前为止,HTTP已成为互联网中应用最广泛的应用层协议。目前在WWW中使用的是HTTP 1.1版本,而且HTTP-NG (Next Generation of HTTP)的建议已经被提出。
HTTP协议的主要特点可概括如下:
1) HTTP协议足够简单,简单到可概括为“用户发起请求→服务器响应→新请求重新发起”,每次请求均为独立行为,这体现了HTTP的无状态特点。
2)HTTP协议支持B/S模式,只要有浏览器即可工作,用户使用简单、易于操作。从某种意义上说,APP也可以被视为某种特定内容的浏览器。
3) HTTP协议灵活性好,可用于数据传输、视频播放、交互等,因此适合快速迭代的互联网应用环境。

对于Web安全本身来说,HTTP是应用层的传输方式,目前大量的安全问题都是HTTP的应用带来的,但HTTP本身并没有太好的防护措施。好比一个门锁不安全,首要解决的是门锁的安全性,而对门锁依托的楼道(即HTTP协议)来说,并没有太多的直接防护措施。
HTTP协议非常严谨及复杂。以下将针对HTTP协议涉及安全问题的内容进行总结,这些内容可有效帮助读者理解后续各类安全漏洞的形成及利用方法等。
1.2.1 HTTP请求头的内容
HTTP请求由三部分组成,分别是请求行、消息报头、请求正文。下面重点介绍各部分的重要
参数。
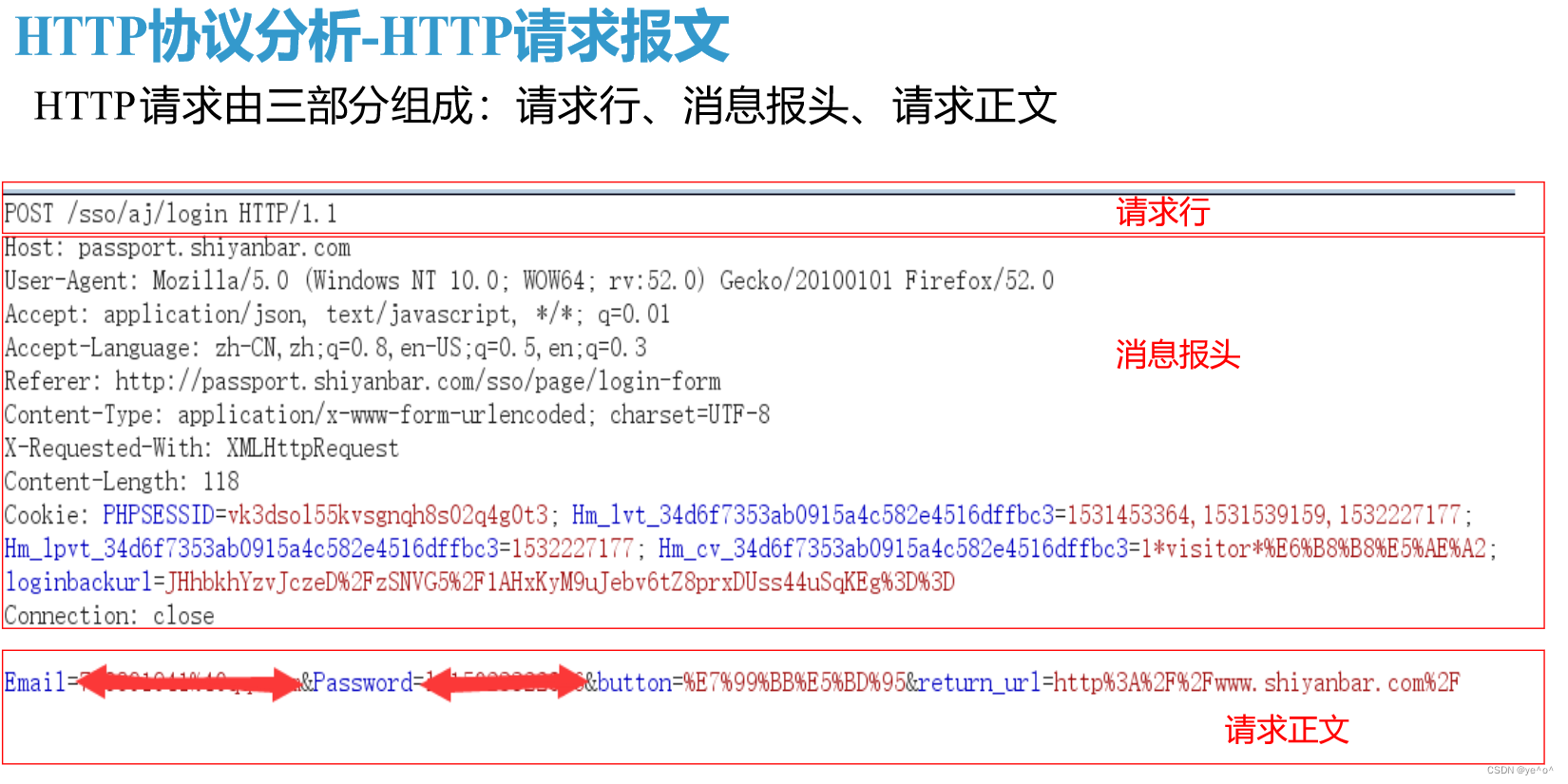
一般情况下,用户无法在正常访问时观察到HTTP包及其结构。但在Web安全中,HTTP包非常重要,其中的大量参数均会对安全产生至关重要的影响。部分浏览器(Chrome、Firefox等)具有相关的插件,可对HTTP包进行抓取及分析,但功能较为单一。这里推荐利用抓包技术进行分析,常见的抓包工具有Wireshark(抓取网卡通信的数据包)、Burpsuite(利用HTTP代理抓取数据包)、Fiddler (HTTP代理,效果类似Burpsuite)。我们利用Burpsuite抓取HTTP包,如图1-4所示。

从图中可以看到,HTTP包中有多组数据,且数量较多。根据HTTP包结构,对其进行简单分类,以便快速理解各组数据的具体意义。如图1-5所示。

1.请求行
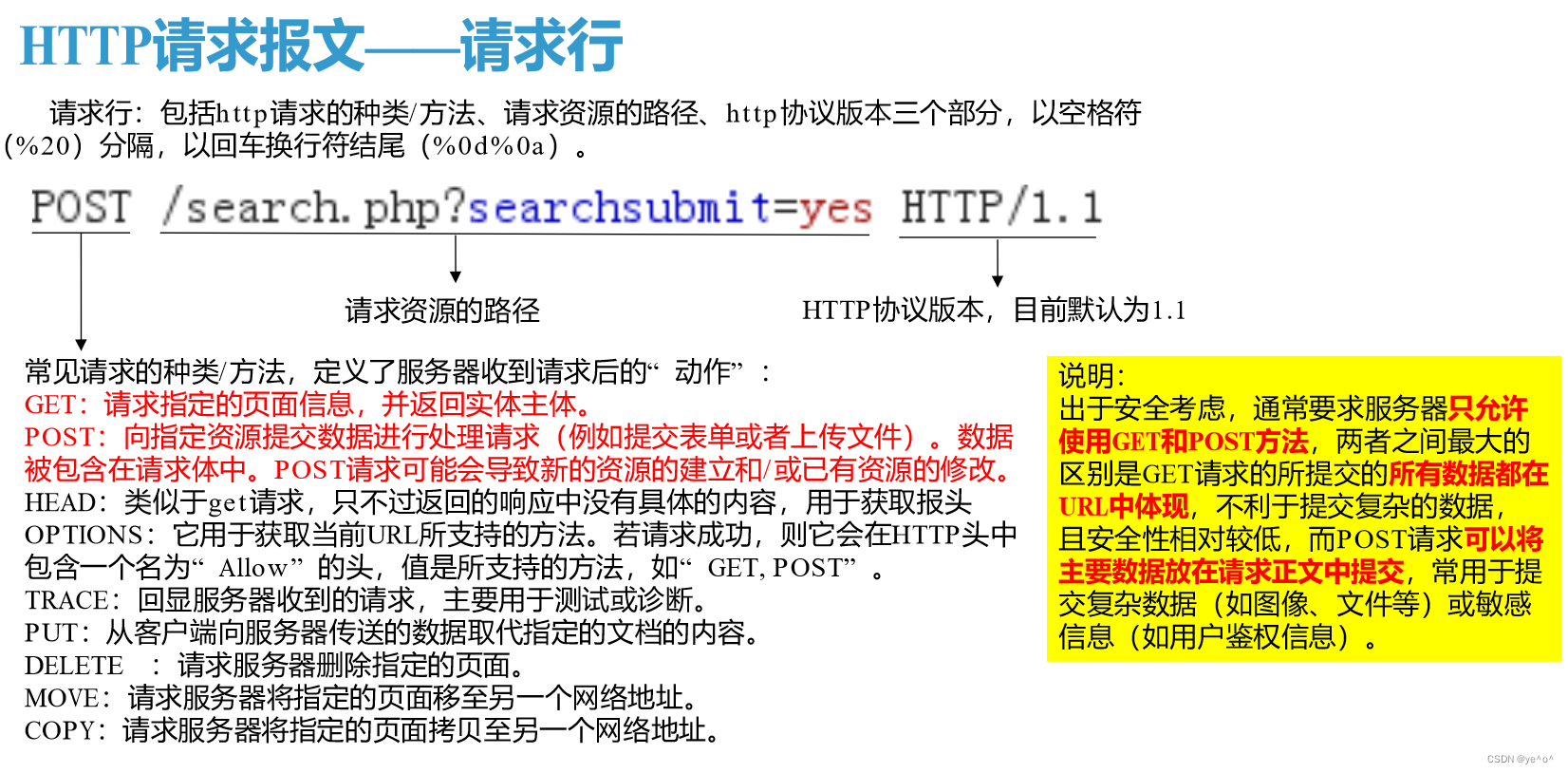
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,标准的请求行格式为:
Method Request-URI HTTP一Version CRLF
Method:表示请求方法;
Request-URI:是一个统一资源标识符;
HTTP-Version:表示请求的HTTP协议版本;
CRLF:表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。例如,请求行的内容为:
POST /member. php? mod=logging&action=login&loginsubmit=yes&loginhash=LS2S5&inaax=1 HTTP/1.1这段请求行内容说明了当前数据包的基本请求方法及路径。其中:
- 请求方法是POST。
- 请求路径为member.php。
- HTTP版本为HTTP 1.1。
URL中的mod=logging & action=login & loginsubmit=yes & loginhash=LS2S5 &inajax=1为当前站点页面的控制参数,格式与get方式发送参数相同。
请求方法
请求方法用来告知Web服务器本次请求的主要目的。HTTP协议中定义了多种请求方法(所有方法全为大写),各个方法的解释如下:
GET请求获取Request-URI所标识的资源。
POST在Request-URI所标识的资源后附加新的数据。
HEAD请求获取由Request-URI所标识的资源的响应消息报头。
PUT请求服务器存储一个资源,并用Request-URI作为其标识。
DELETE请求服务器删除Request-URI所标识的资源。
TRACE请求服务器回送收到的请求信息,主要用于测试或诊断。
CONNECT保留,将来使用。
OPTIONS请求查询服务器的性能,或者查询与资源相关的选项和需求。在实际应用中,考虑到安全因素,主要使用GET和POST两种方式开展请求。例如,早期ASP系统中存在大量IIS PUT漏洞,导致攻击者可直接利用PUT工具上传木马以获得Webshell。因此,从安全及业务开展统一的角度,其余方式目前基本都不再使用。
GET和POST在使用中的主要区别为:
GET方法通过在浏览器的地址栏中输入网址访问网页时,浏览器采用GET方法向服务器获取资源,对应的请求行示例为:GET/form.html HTTP/1.1 (CRLF)。
POST方法要求被请求服务器接收附在请求后面的数据,常用于提交表单。可参考图1-5中的HTTP body (请求正文)。GET和POST方法的最大区别就是提交参数在HTTP请求包的位置不同。也就是说,使用GET方式时Request body部分为空,POST方式则可利用URL及Request body发送请求。但在实际应用中,两者的安全性基本一致,都可能因链路劫持而出现参数泄漏的情况。链路劫持是由HTTP协议本身的特点所决定的,与请求方法没有任何关系。
目前,有一些系统依然支持HEAD万法。HEAD方法与GET使用方法几乎是一样的,利用HEAD方法的好处在于不必传输整个资源内容,就可以得到Request-URI所标识的资源的信息。
该方法常用于测试链接的有效性,看链接是否可以访问,以及最近是否更新。当然,随着互联网带宽的提升及网站应用的日趋复杂,目前HEAD方法已不在重要业务场景下使用,这里的介绍仅供了解。
2.请求消息报头
请求消息报头用来向服务器端传递客户端自身的信息以及用户的附加信息。这些信息可帮助服务器端更好地识别用户的请求,以提供对应的响应内容。仍以图1-5中的请求报头为例,其内容如下:
Host: www.a. com
Proxy-Connection: keep-aliveContent—Length: 224
Cache-Control : max-age=0Origin: HTTP://www.ghtt.netUpgrade-Insecure-Requests: 1
Content-Type: application/x一www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTMlike Gecko) Chrome/61.0.3163.100 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml ;
q=0.9,image/webp,image/
apng,*/*; q=0.8
Referer: HTTP:/ /www.ghtt.net/member. php? mod=logging&action=loginkreferer=Accept一Encoding: gzip,deflate
Accept一Language: zh-CN, zh; q=0.8
Cookie:UM_distinctid=15claa7d069784-0df76df5ea1636-5393662-384000-15c1aa7d06a5d6;
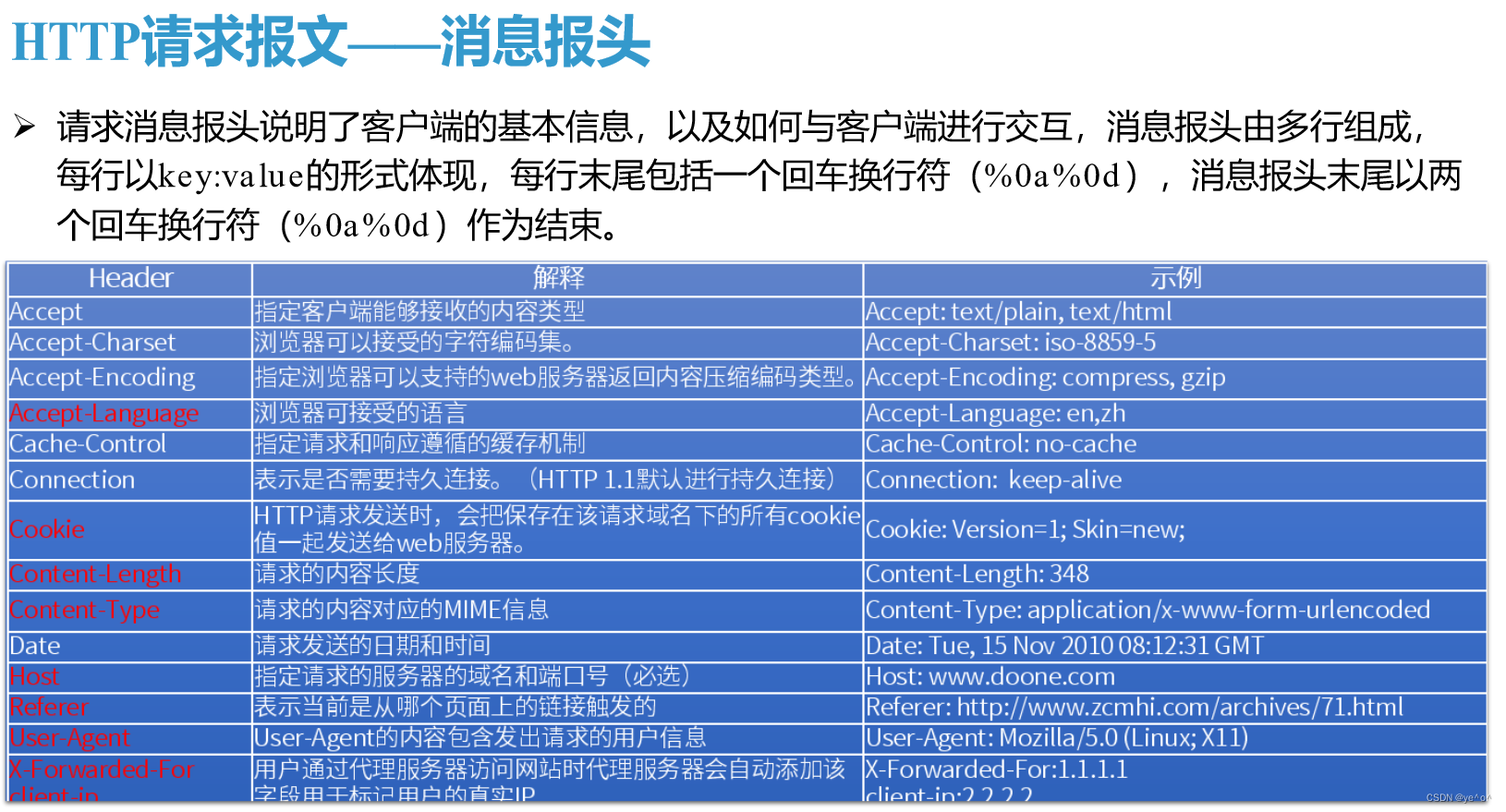
请求报头中涉及安全的内容主要有以下几项:
Host(必须存在):Host主要用于指定被请求资源的Internet主机和端口号,即标识请求目标。其来源为当前访问的URL。缺省端口号为80,若指定了端口号(以8000为例)进行防卫,则变成Host:www.a.com:8000。
Content-Length :标识当前请求包中的内容长度。
Origin :用来标识本次请求的发起源,只适用于POST方式。
Referer:用来标识当前请求的发起页面。
Accept:Accept用于指定客户端接收哪些类型的信息。上例中表明允许后续类型在客户端实现。
Accept-Encoding:告知服务器端当前客户端可接受的内容编码。
Accept-Language:告知服务器端支持的语言类型。
User-Agent:User-Agent通常简称为UA,其中包含当前用户的操作系统、浏览器的基本信息,用于告知Web服务器当前访问者的情况。此报头域不是必需存在的。但如果客户端不使用User-Agent请求报头域,那么服务器端就无法得知客户端的基本信息。目前UA也经常被Web服务器用于统计当前用户状态及行为。
3.请求正文内容
请求正文中包含HTTP传输的信息。当请求方法为GET时,请求正文为空,所有内容通过在URL后面添加参数进行传输。只有请求方法为POST时,HTTP请求正文中才有信息,通常为Web系统自定义的参数,用于实现与服务端的交互。其中的参数是由Web系统自行定义的。在Web系统开发时一般会根据参数用途指定特定的名称,如username.code等。但这样也会让攻击者清楚地知道参数的具体用法。推荐在此部分中,参数命名应模糊,使得参数名称无法通过表面意思被理解,从而增加攻击者的分析难度。
1.2.2 HTTP协议响应头的内容
服务器端接收到用户的请求包后,会根据其中的请求内容进行处理,并返回HTTP响应消息。HTTP响应包与请求包的结构类似,也是由三个部分组成,分别是响应行、响应消息报头、响应正文。如图1-6所示。
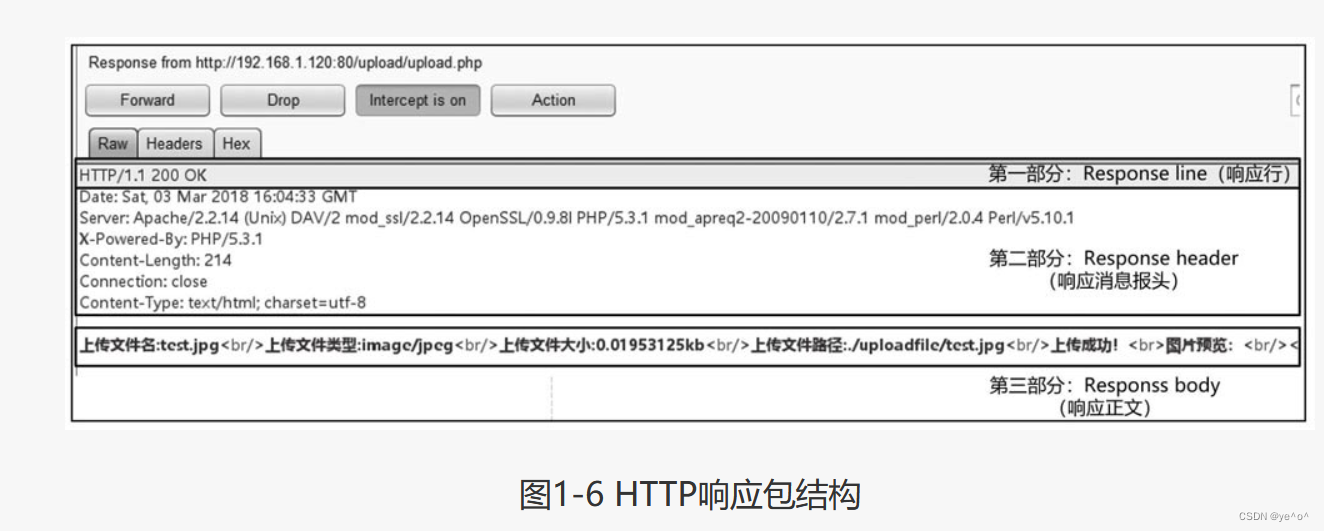

1.响应行
响应行的基本格式为:
HTTP-Version Status-Code Reason-Phrase CRLF- HTTP-Version:表示服务器HTTP协议的版本;
- Status-Code:表示服务器发回的响应状态代码;
- Reason-Phrase:表示状态代码的文本描述。上例中的“HTTP/1.1 200 OK”说明服务器HTTP版本为1.1,已接收到用户请求并返回状态码“200,OK”,表示当前请求正常。
服务器状态码
1XX表示提示信息,说明请求已被成功接收,继续处理。
2XX表示成功,说明请求已被成功接收、理解、接受。
3XX表示重定向,要完成请求必须进行更进─步处理。
4XX表示客户端错误,请求有语法错误或请求无法实现。
5XX表示服务器端错误,服务器处理请求时出错。
之后两位会利用不同的数字来代表当前服务的状态。以下是常见状态代码及状态描述:
200:OK,客户端请求成功。
301:Permanently Moved,页面重定向。
203:Temporarily Moved,页面临时重定向。
400:Bad Request,客户端请求有语法错误,不能被服务器所理解。
401:Unauthorized,请求未经授权,这个状态代码必须和WWW-Authenticate报头域起使用。
403:Forbidden,服务器收到请求,但是拒绝提供服务。
404:Not Found,请求资源不存在,或者请求无法实现
500:Internal Server Error,服务器发生不可预期的错误。
503:Server Unavailable,服务器当前不能处理客户端的请求,一段时间后可能恢复正常。2.消息响应报头
响应消息报头允许服务器传递不能放在响应行中的附加响应信息,以及关于服务器的信息和对Request-URI所标识的资源进行下一步访问的信息。

常用的响应消息报头有以下内容:
Server Server:响应报头域包含服务器用来处理请求的软件信息。参考图1-6,其中定义了Server:Apache,用来告知用户端提供本次响应的服务器端采用的中间件是Apache。可以看到,在响应包中Server信息与请求包中User-Agent信息的作用非常类似,都是将自身的版本告知对方。
X-Powered-By:用来标识实现当前Web站点所采用的语言及版本号。
Set-cookie:根据响应包生成Cookie,并提供给客户端。
oContent-Length:与请求包中的用法相同,用以标识当前响应包中的内容长度。3.响应正文内容
相对于请求包中的正文内容,响应包中的内容会携带当前页面的源码。客户端浏览器可根据响应包中的源码显示出完整的页面。从安全角度来说,对于响应包中的正文内容,直接观看浏览器会直观、方便得多。因此,在Web安全研究时,无需关注这部分内容。
1.2.3 URL的基本格式
前面介绍过,HTTP是一个基于请求与响应模式、无状态应用层协议,常基于TCP的连接方式。HTTP 1.1版本给出一种持续连接的机制,绝大多数的Web开发都是构建在HTTP协议之上的Web应用系统。
HTTP中URL的标准格式如下:
scheme : //host[:port][abs_path]? [query-string1]&[query-string2]以常见的URL为例,其格式如下:

在URL中,各项的意义如下:
scheme:指定低层使用的协议,如HTTP/HTTPS。目前浏览器默认以HTTP开头。
host:HTTP服务器的IP地址或者域名,如www.XXXXXX.com/ 119.188.50.116。
port#:HTTP默认端口为80, HTTPS默认端口为443。如果当前请求为协议的默认端口,则可省略端口号;如果不是默认端口,则需注明端口,端口与域名之间用:(冒号)隔开。如上例利用的端口为8080,不是HTTP默认端口,因此必须标明。
path:访问资源的路径。在服务器中以www开头的路径,通常表示访问文件的地点。
query-string: 发送给HTTP服务器的数据。此时,应用GET方式传输才有效。多个数据可用&进行分割,实现多组数据同时传输。作为用户请求服务器内容的主要凭证,服务器会根据用户的URL请求判断相应方式,因此需重点了解上述内容,熟悉URL每个部分的作用,为理解后续内容打下基础。
1.3 HTTPS协议的安全性分析
HTTP协议在传输内容时并没有采取任何加密措施,这样可利用网络抓包方法来直接获HTTP包的内容。通过对包内容分析可得到用户的访问行为,汇总后便能知道当前用户的网络动向及规律,目前上网行为管理设备或者各类Web应用行为分析软件就是利用此原理实现的。更有甚者,由于参数未加密,攻击者便可在网络层直接获得当前用户的传参信息,并利用爆破等手段获得用户的敏感内容。例如,下面就是一个利用Wireshark抓包得到目标站点的参数的例子。
首先,利用目标站点的登录功能登录,参考图1-7。
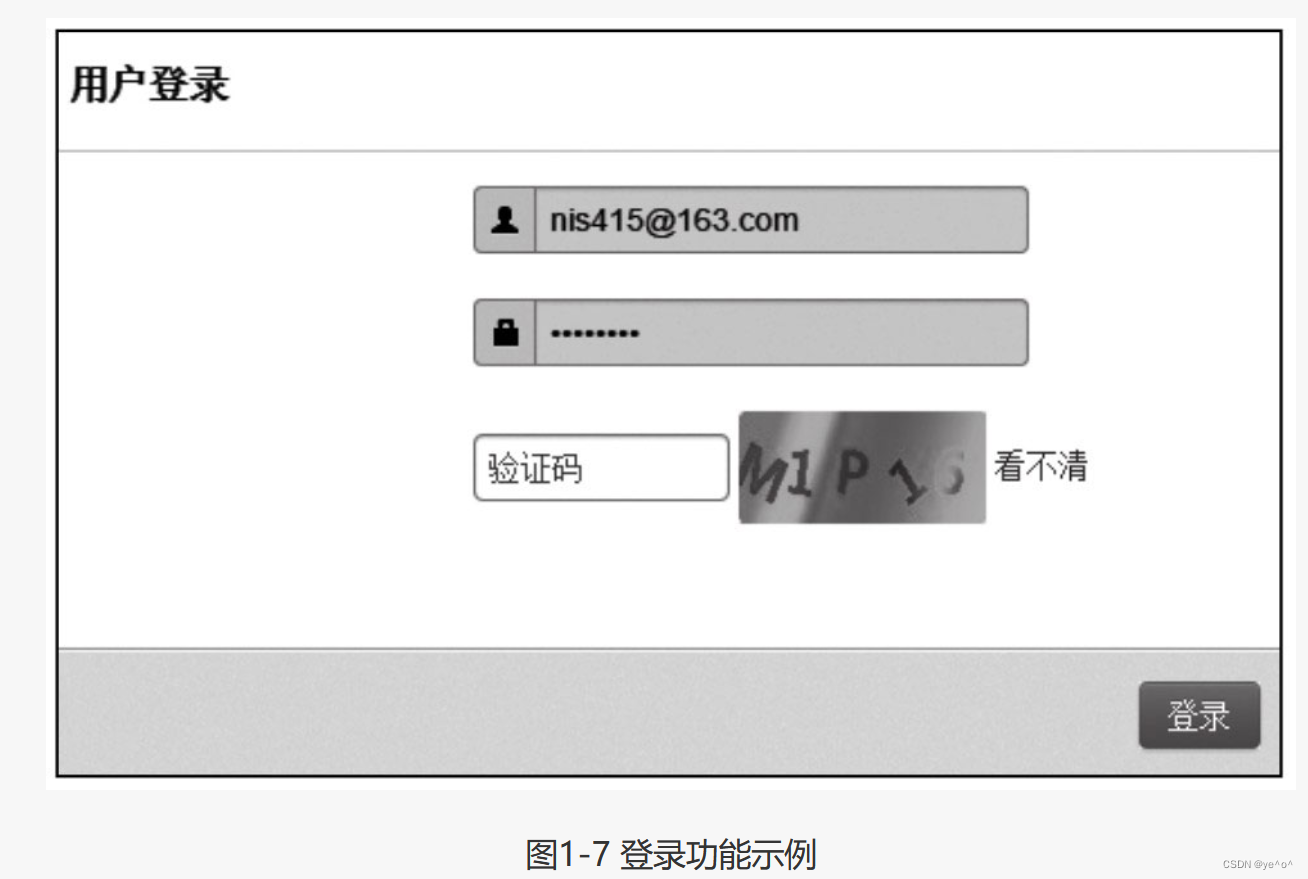
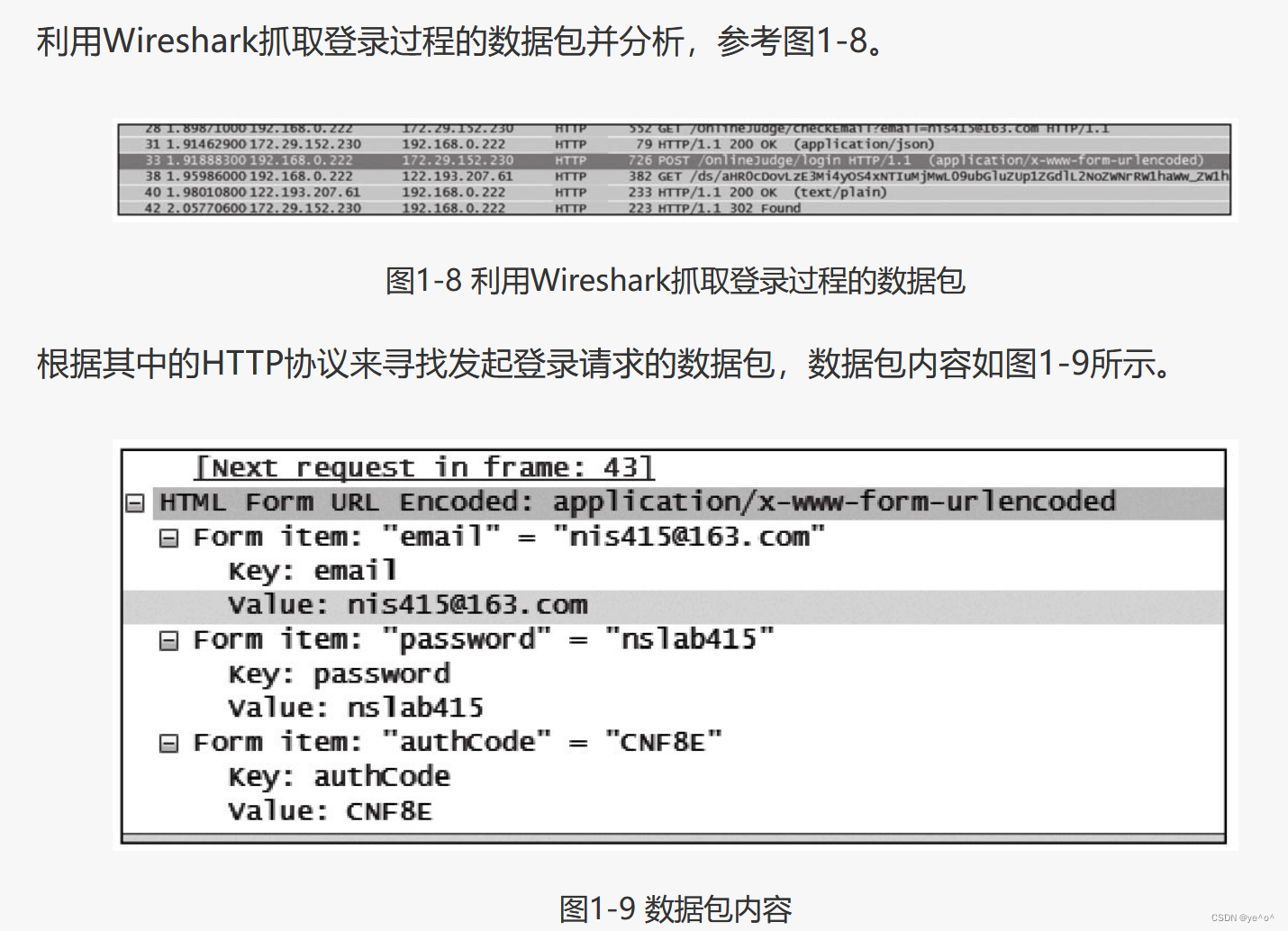
这里可以清晰地看到用户当前的行为,包括用户的登录情况、用户名和密码、访问地址等,这是由于在传输中未进行加密而导致的。因此,HTTPS协议在HTTP协议基础上,利用SSL技术进行数据包的传输。这样就可以避免传输内容在链路中被劫持,从而保障用户传输中的数据不被窃听。
1.3.1 HTTPS协议的基本概念
从严格意义上来说,HTTPS并不是一个独立的协议,而是工作在SSL协议上的HTTP协议。SSL (Secure Sockets Layer,安全套接层)是一种为网络通信提供安全及数据完整性的安全协议。其后续规范协议TLS (Transport Layer Security)对原有SSL协议进行了扩展。目前,HTTP协议都是利用TLS实现传输加密过程。通俗地说,HTTPS协议就是HTTP依托SSL协议来达到数据安全传输的效果。这也是有效保障用户数据安全的措施,使用HTTPS访问站点的效果如图1-10所示。
了解了HTTPS协议特点后,会发现在HTTPS传输过程中有两个核心的问题将直接影响用户的数据安全:
1)如何建立安全的传输通道。
2)如何确认双方的身份。
先分析建立安全的传输通道问题。说起安全传输就要提及对应的加密算法,而对于加密算法,其密钥的安全性至关重要。在传统的加密场景中,可利用离线的方式进行密钥传输,与各类U盾(又称USBkey)设备保障安全。但是在Web应用环境下,用户通常是第一次访问站点。因此,如何安全有效地将密钥传到用户手里,是建立安全传输通道的基础。
目前,主流的加密方式有对称加密与非对称加密两种形式。对称加密很好理解,即服务器端和客户端使用相同的密钥来对信息进行加密与解密,且处理速度非常快。非对称加密则利用公私钥模式实现,客户端具有公钥,用来对数据进行加密,并且公钥可以公开传输,服务器端具有私钥,用于对用户的数据解密。
根据加密方式的特点,在建立安全通道时可利用非对称加密方式实现。当用户利用HTTPS协议访问Web站点时,Web站点会向用户发送其加密算法的公钥。
用户根据公钥对数据进行加密,从而实现建立安全通道的基础需求。但这个过程中又会产生一个新的问题,可能有人仿冒目标站点,并向用户发送仿冒站点的公钥,且成功实施欺骗。因此,如何确认双方的身份,就成为传输通道建立之后要解决的问题。
要解决这个问题,最有效的手段是验证站点发送的公钥是否真实,这需要第三方权威机构进行判定。这个第三方权威机构就是CA (Certificate Authority)认证中心。利用CA认证中心的权威性,可以杜绝公钥造假行为,这样也成功解决了Web传输过程中双方身份的确认问题。
1.3.2 HTTPS认证流程
了解HTTPS的基本概念后,接下来我们梳理一下HTTPS认证流程。HTTPS协议根据其认证次数可分为单向认证和双向认证。其中单向认证适用范围较广,配置也简单。
1.HTTPS单项认证流程
HTTPS的单向认证主要有以下流程:
1)客户端向服务器发起请求,其中包含各种SSL参数,并从服务器端拿到证书。
2)客户端将从服务器端获得的证书提交至CA,CA验证该证书的合法性并告知客户端,客户端根据CA验证结果来确认目标站点的真实性。
3)从服务器端的证书中取出公钥,利用公钥对客户端产生的密钥加密(对称密钥),并利用公钥将加密后的密钥发送到服务器端。
4)服务器端用其私钥解密出数据,即得到客户端发送来的对称密钥,之后均利用这个对称密钥对传输文件进行加密/解密。 单向认证的特点在于只有客户端对服务器端进行了身份验证,而服务器只是对提交过来的加密密钥进行识别并处理,而不对客户端的合法性进行验证。这就造成了遭受SSL剥离攻击的隐患。
SSL剥离攻击是针对HTTPS单向认证环境的攻击手段。例如,SSL Strip工具的原理就是劫持用户的请求,并模拟用户来与目标站点建立HTTPS连接。成功连接后利用已建立连接的对称密钥解密服务器发送过来的HTTPS,将其中的HTTP再发送给客户端。SSL剥离攻击的流程如图1-11所示。这也是由于单向认证中服务器并不对客户端的有效性进行检查而造成的。

需要注意的是,直接利用各类抓包工具也可实现在本地抓取HTTPS包。以Burpsuite为例,将Burpsuite的证书导入浏览器并取得信任后,可以代理HTTPS双向认证的连接并开展安全测试。因此,HTTPS重点是解决传输过程中链路被劫持的风险,针对Web系统的安全防护效果有限。
目前,SSL剥离攻击常用于WiFi劫持、ISP层面的流量劫持等环境,如果在日常站点访问中,经常访问的站点突然由HTTPS协议变成了HTTP协议,那么就需格外小心。这类劫持行为对用户的数据会产生较大的危害,同时也会危害到网站的利益。因为用户权益一旦受到损失,用户会降低对网站的信任度,导致网站最终受到损失。因此,在大型站点的高价值业务或者两个站点互联互通时均会利用HTTPS双向验证技术来解决上述安全隐患。
2.HTTPS双向认证流程
相对于单向认证整体流程,HTTPS双向认证主要是在客户与服务器端的认证部分发生了改变。HTTPS双向认证流程如下所示:
- 1)客户端向服务器发起请求,其中包含各种SSL参数,并从服务器端拿到证书。
- 2)客户端将从服务器端获得的证书提交至CA,CA验证该证书的合法性并告知客户端,客户端根据CA验证结果来确认目标站点的真实性。在这里新增了两个步骤:
-
服务器端要求客户端发送证书并验证,并接受用户的公钥。
-
双方利用对方公钥加密来协商可支持的传输类型及密码方案。
-
- 3)客户端从服务器端的证书中取出公钥,利用公钥对客户端产生的密钥加密(对称密钥),并利用公钥将加密后的密钥发送到服务器端。
- 4)服务器端用私钥解密出数据,即得到客户端发送来的对称密钥,之后所有内容均利用这个对称密钥对传输文件进行加密/解密。
HTTPS双向认证主要是增加了服务器对客户端的合法性校验,这样可有效避免SSL剥离攻击。需要注意的是,由于客户端没有针对特定网站的密钥生成机制,因此在双向认证时站点会要求客户端安装特定的插件,用来实现密钥的生成。这个过程会给用户带来额外的操作及影响,因此双向认证并不适用于全部的场景。
1.3.3 HTTPS协议特点总结
● HTTPS并没有改变HTTP协议本身的特性,只是在传输过程中利用SSL/TLS技术进行加密,保障传输过程中的安全。
● HTTPS技术可有效保障用户信息不被泄露,避免上网行为设备、代理类设备对用户当前行为的获取,并且可有效避免来自运营商层面的TCP劫持
● HTTPS主要防护传输过程中的安全,如果在用户端利用Burpsuite,则依然可以通过代理技术实现对Web访问的劫持,因此并不会有效提升服务器的安全性。
HTTPS重点解决的是传输过程中的安全问题,可用来保障客户端的传输数据安全,并不会直接提升Web站点的安全性。Web安全的问题仍要从功能角度出发,找到问题根源,方可有效解决。
1.4 Web应用页面中的编码与加密
字符是各种文字和符号的总称,其中包括各个国家文字、标点符号、图形符号、数字等。世界上存在大量不同的语言,每种语言所使用的文字或格式均不相同。在Web系统中,必须考虑使用某种编码方式来表现语言所对应的文字和格式。目前,常见的语言都有对应的字符编码,字符编码就是约定某个字在计算机中的编号。但不同的编码中,同一个字对应的编号完全不同,因此容易形成“乱码”的效果。
1.4.1 针对字符的编码
字符编码有很多种类型,常用的是用8bit实现针对某一个字符的标识,如ASCII编码。但由于8bit只能提供256个编码定义(28),可用于编码的值太少,因此无法表示汉字。针对汉字,利用双字节(两个8bit,可支持65536个汉字)实现编码,常见的就是GBK及GBK18030等字符集。
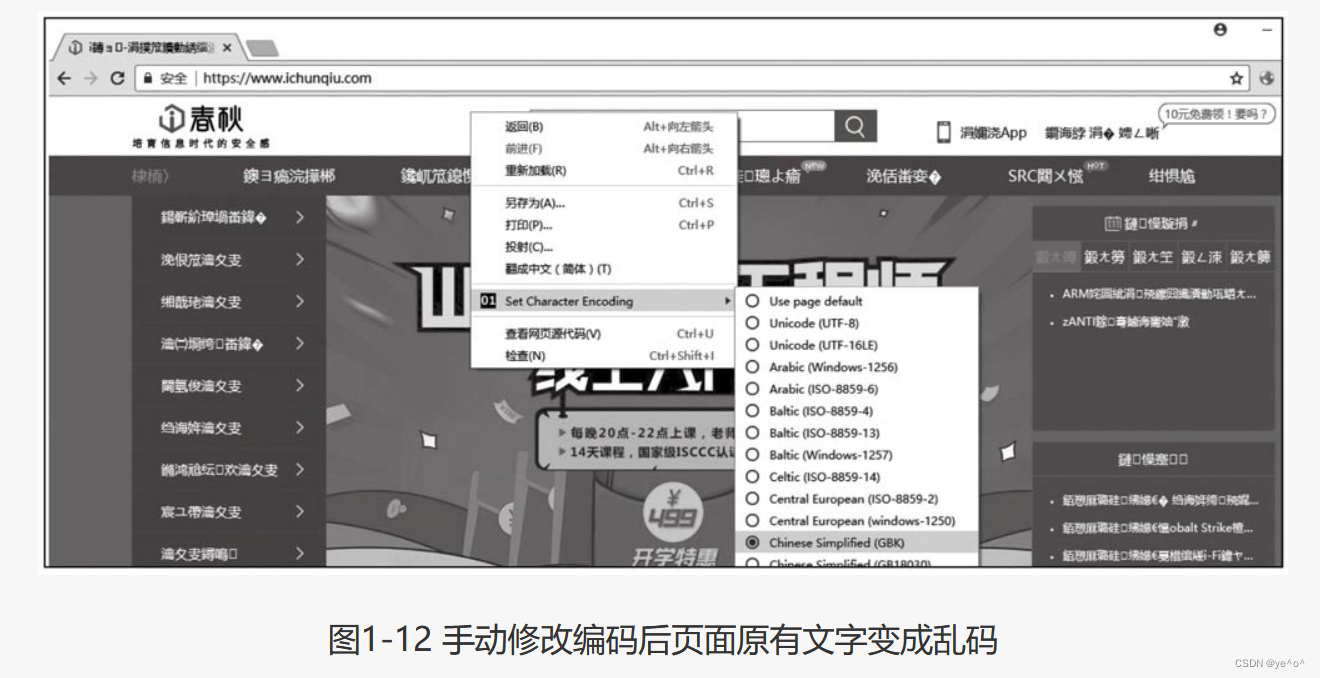
可利用Chrome浏览器观察各种编码的效果。但Chrome浏览器在其编号为55的版本后移除了网站设置编码的功能,因此需添加插件,插件为Set Character Encoding。利用该插件可手动指定编码格式,如图1-12所示。由于默认编码为UTF-8,因此这里改成GBK之后发现页面为乱码。
最基本的编码是ASCll (American Standard Code for Information Interchange,美国信息互换标准代码),它是基于拉丁字母的一套编码系统,主要用于显示现代英语和常用符号,是现今最通用的单字节编码系统。它的编码标准为ISO-8859-1。通俗来说,ASCII适用于针对英文字母加上标点符号的场景。
由于英语是字母文字,其常用单词均可以利用26个字母拼接实现,因此ASCII编码可满足英语环境。但在面对形意文字时,使用ASCII编码会有非常大的问题。中文是典型的形意文字,常用的文字数量达到3500个以上,仅仅利用8bit提供的256个编码数量远远无法满足编码需求。
利用DBCS (Double Byte Charecter Set,双字节字符集)可很好地解决编码不足的问题。常用的双字节字符集包括GB2312、GBK和GB18030等中文编码,使两字节长的汉字字符和一字节长的英文字符并存。以下是服务器的响应包示例,如图1-13所示。其中,利用content-type中的charset标识网页的编码格式。

由于不同国家和地区采用的编码不一致,因此无法正常显示所有字符的情况时有发生,也就出现了乱码的情况。Unicode编码主要解决多种语言环境下的统一集合,它为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。用来给Unicode字符集编码的标准有很多种,比如UTF-8、UTF-7、UTF-16、UnicodeLittle、UnicodeBig等。
在国内,早期的站点大多使用GBK的编码方式实现中文显示,但目前主流站点都基于UTF-8进行中文显示。这主要是因为UTF-8支持多种语言环境,因此在多语言环境下使用UTF-8编码可大大减少客户端乱码的可能性。但需注意的是,UTF-8是三字节编码,GBK是双字节编码。因此在对大量内容编码时,UTF-8编码所需的存储空间会多于GBK。鉴于目前存储空间及网络带宽充足(甚至过剩),因此在实际使用中二者没有明显的区别。
1.4.2 传输过程的编码
再回到前文所说的URL格式。在HTML中,利用"/","?","&"等符号实现针对特定字符的内容定义,如规定访问路径、参数名称及间隔等。如果正常提交的参数里出现这类字符,势必会对
正常URL解析造成影响。因此传输过程中的编码的目的就是解决这个问题。常见的编码如下。
1.URL编码
RFC3986文档规定,URL中只允许包含英文字母(a~z、A~z)、数字(0~9)、4个特殊
字符(-、_、.、~)以及所有保留字符。在实际Web应用中,所使用的字符不只在这个范围内,如用户输入参数中还带有单引号、百分号、中文等。因此,需要对URL中的非允许字符进行编码。
URL编码主体采用的是ASCII编码表,编码方式是用%(百分号)加上两位字符代表一个字节。例如,单引号在ASCII中的十六进制编码为27,在URL编码中就是%27。对于中文字符,会先确认当前页面所用的编码格式。如果当前页面使用UTF-8编码,则会先将中文字符转换成UTF-8编码,然后在每个字符的每一组编码前添加%,这样就完成URL编码。下面是一个实例。
· URL编码前
HTTP://172.29.152.23/loginPage.jsp?name=测试&passwd=ww121%$
. URL编码后
HTTP://172.29.152.23/loginPage.jsp?name=%E6%B5%8B%E8%AF%95&passwd=ww121%25$假设当前页面为UTF-8编码。可以看到,URL编码里针对参数"ww121%$"中的"%"进行了编码,编码结果为"%25"。针对中文字符“测试”,URL编码为"%E6%B5%8B%E8%AF%95"。再查询“测试”字符的UTF-8编码,其十六进制编码就是"E6 B5 8B E8 AF 95",如图1-14所示。

以上过程很好地演示了URL编码针对中文字符的编码方式。更好地了解URL编码方式会对后续
攻防技术的学习有非常大的帮助。
2.Base64编码
Base64是网络上常见的用于传输8bit字节代码的编码方式之一,其原理是将3个8bit字节(3*8=24)转化为4个6bit的字节(4*6=24)。因此,Base64编码的特点是编码后的字节数是4的倍数,如果不足4bit则用等号((=)等进行填充。下面给出两个例子:
●编码前: base64编码
编码后:YmFzZTY057yW56CB (十六位)
●编码前: base64编码1测试
编码后: YmFzZTY057yW56CBMea1i+ivlQ==
Base64编码非常好识别,它含有大小写字母及+、-、=等符号,各种在线解码工具均可对Base64编码进行解码。利用Burpsuite的Decoder模块也可实现此类功能。如图1-15所示。
Base64编码可用于在HTTP环境下传递较长的标识信息,最早用于邮件的传输。目前,在HTTP Basic认证中依然利用Base64对用户密码编码后进行传输。在早期的Web木马中,也会利用Base64对木马文件进行重复编码达到源码混滑的效果。
3.HTML字符实体
HTML字符实体(Character Entity)是用来表示HTML中危险字符的方案,也是解决跨站脚本(XSS)攻击的有效手段。以常见的跨站脚本代码为例: <script> alert(/xss/)</script>。当这段代码由客户端提交到Web页面后,由于语句中含有<script>标签,会导致HTML页面将其当作Javascript代码进行执行。因此,在HTML内容中不能使用小于号(<)和大于号(>),因为浏览器会误认为它们是标签。
在日常应用中,如果需要正确地显示危险字符,可以使用HTML字符实体进行实现。HTML字符实体的特点是以&开头,并以分号结尾。例如,"<"的编码是"<"。在上述语句中,当用户提交的参数为<script>alert(/xss/)</script>时,经过HTML字符实体处理后,可得到"<script> alert(/xss/)< /script>"。这样就解决了危险字符的显示问题。
类似的编码类型还有很多,并且根据适用场景有所不同。编码的初衷是解决不同类型组件传递信息的一致性。但随着攻防技术的发展,编码也会根据其自身特点产生各类安全隐患。例如,之前常见的GBK编码,在SQL注入、XSS环境下都存在宽字节的安全隐患。详细原理将在后面详细介绍。
1.4.3 Web系统中的加密措施
标准的加密方法是对用户提交的参数(如密码、特定内容等)进行加密后再传输,避免参数在传输过程中被劫持,导致用户数据丢失。当数据传输到Web服务器,将参数解密后处理。这个过程中存在两种情况。
1.不需要服务器知道明文的内容
这种情况常见于用户的隐私信息,如用户密码。Web系统在存储用户密码时不会直接存储密
码明文,而是预先设定加密算法,将用户的隐私信息加密后存储在数据库中。这样可在系统运维过程中避免管理人员直接观察并获取用户的密码信息。这种情况下,经常利用MD5/SHA-1实现加
密。
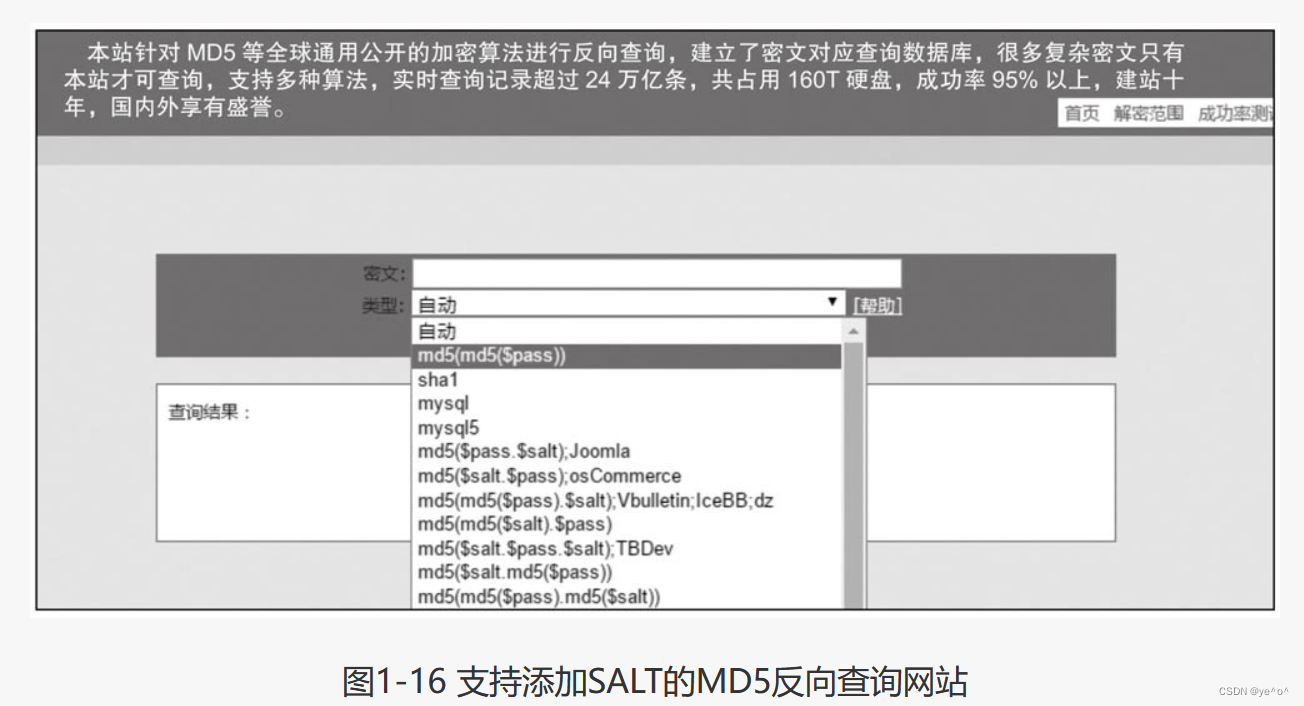
严格来说,MD5/SHA-1是一种信息摘要算法,可将任意长度的明文内容转换成长度固定的密文,并且针对信息摘要的过程不可逆,但针对相同内容每次执行算法得到的密文完全相同。Web系统存储的内容就是经过MD5/SHA-1转换后的密文。因此用户在客户端利用MD5/SHA-1将转换后的密文传输到Web系统,Web系统再将用户密文与数据库中的密文进行比对即可。当然直接使用MD5/SHA-1并不安全,毕竟有大量彩虹表(存储明文与密文的表)存在,可间接实现密码破解的效果。因此,Web系统常用SALT方式提升破解难度,但过于简单的SALT也会存在一定安全隐患,如图1-16所示。
除此之外,MD5\SHA-1还存在碰撞问题,结果是不同明文利用MD5或SHA-1计算之后得到的密文完全相同,这个问题带来的影响远比彩虹表的威胁更大。考虑到安全情况,推荐使用SHA-256/512来提升安全性。但从性能角度考虑,MD5或SHA-1的处理速度明显优于SHA-256/512。因此在实际业务中需综合业务系统安全需求及实际情况选择使用。
2.需要知道服务器的内容
除用户的个人隐私信息之外,客户端发起的请求中还包含大量需要服务器处理的内容,如订单信息、留言等。由于HTTP协议在传输过程中并不会对其中的内容加密,就会导致在传输过程中内容被抓包。
因此,在传输过程中,加密的最大意义还是避免内容泄漏。利用HTTPS协议可有效解决这些问题。国内大量云厂商也支持采用这种方式进行安全的连接。例如,腾讯云提供了SSL证书功能,如图1-17所示。网站可根据自身需求选择对应的服务器。

需要注意的是,HTTPS并不是完全免费的服务,受制于成本问题,多数大型站点仍然会采用HTTP进行业务开展。那么,要在HTTP下保障传输安全,可利用对称加密措施进行实现,如AES方式等。需要注意的是,由于Web站点始终在用户浏览器上,那么相对应的加密算法也处于公开状态,因此,针对这种情况,更多的应该是考虑加密算法的单次持续时间及重复程度。当然,也可利用JS混淆技术来提升加密算法的安全性。但最有效的手段是优化整体业务流程,从根本上降低需要加密传参的业务数量。
1.5 HTML语言基础



HTML常见标签
- 格式标签
- <h1>to<h6>定义HTML标签
- <br>定义换行
- 链接标签
- <a>定义超链接
- 文本标签
- <input>定义文本域
- 多媒体标签
- <imag>定义图像




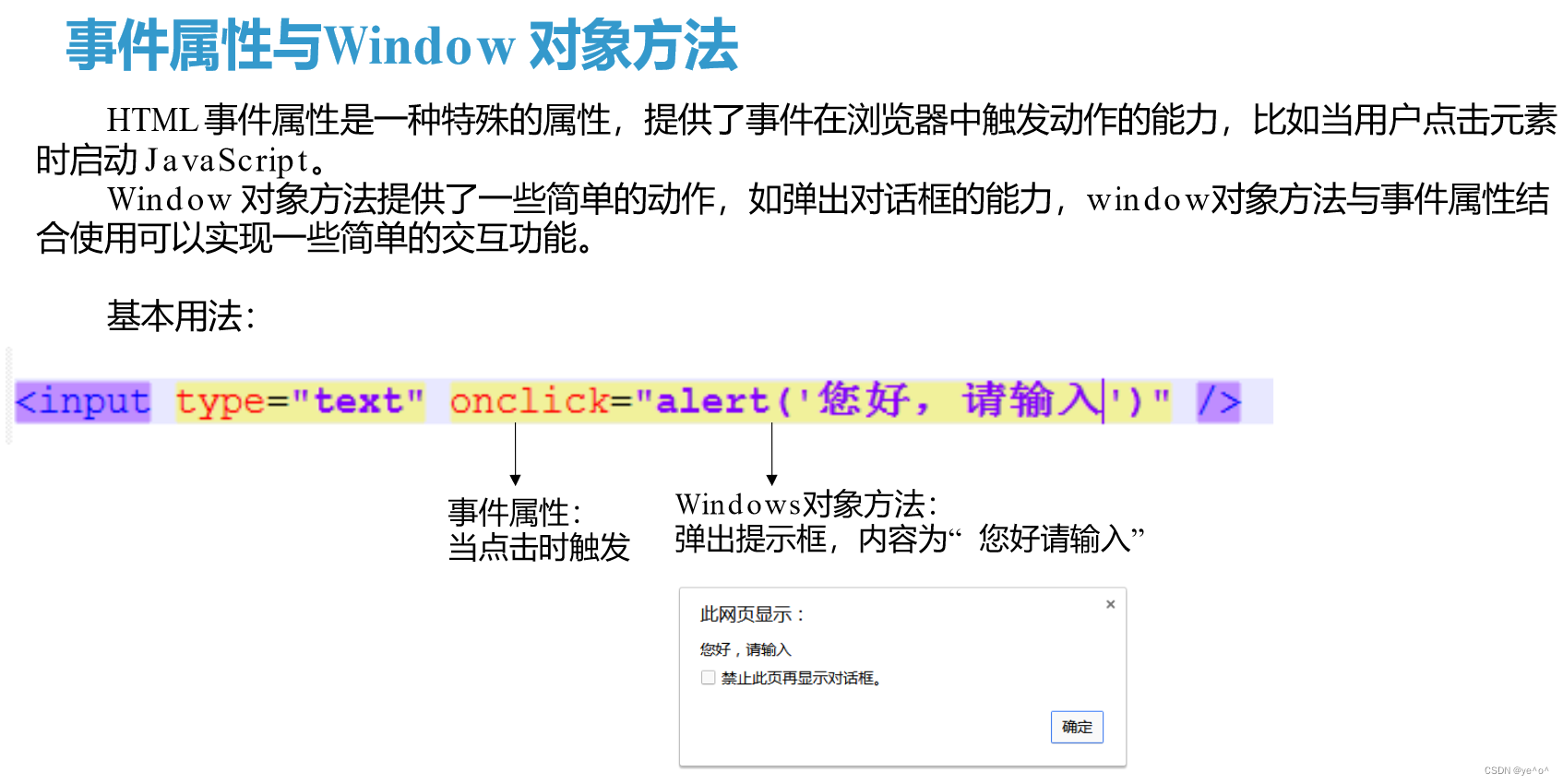

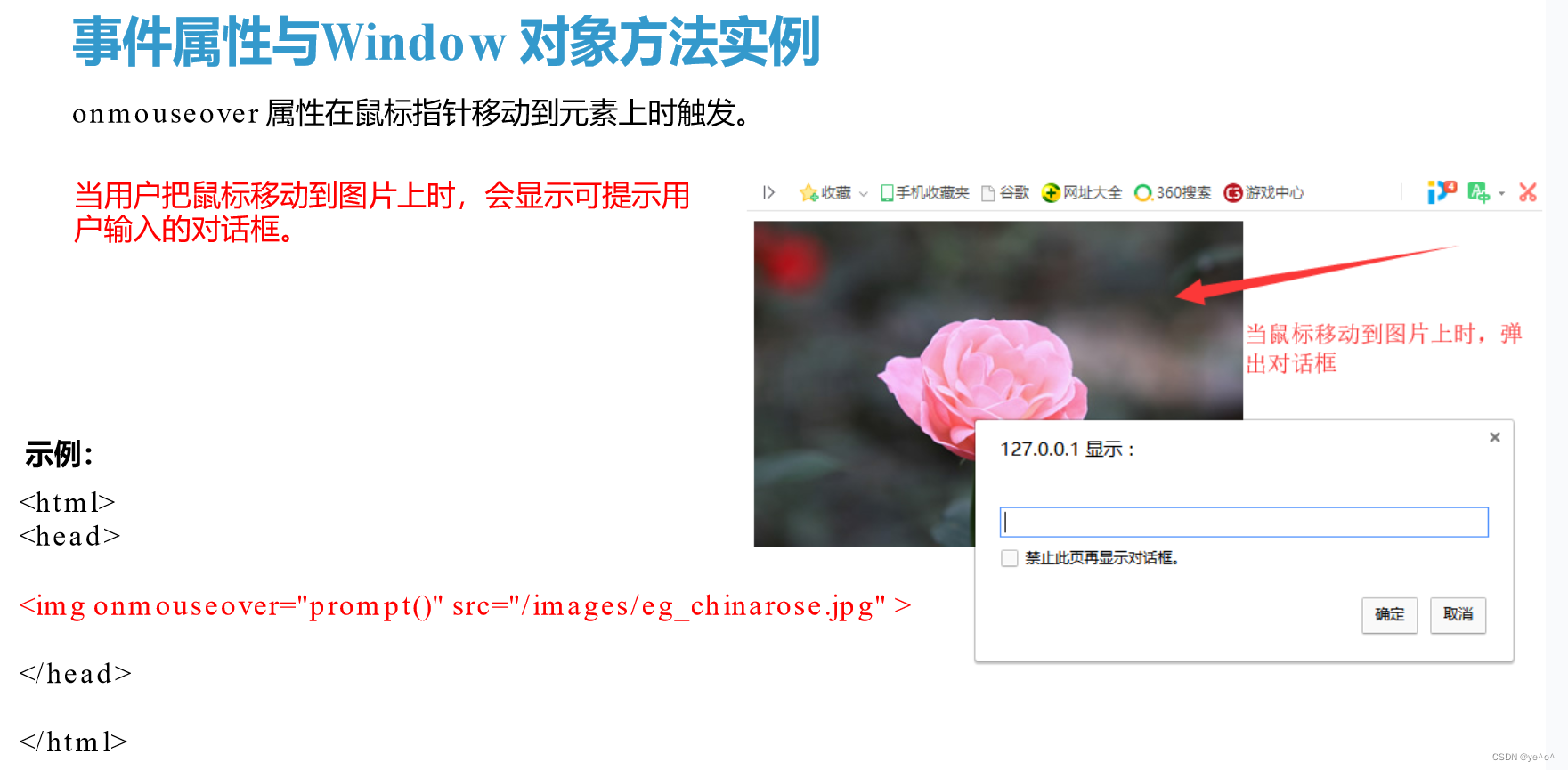
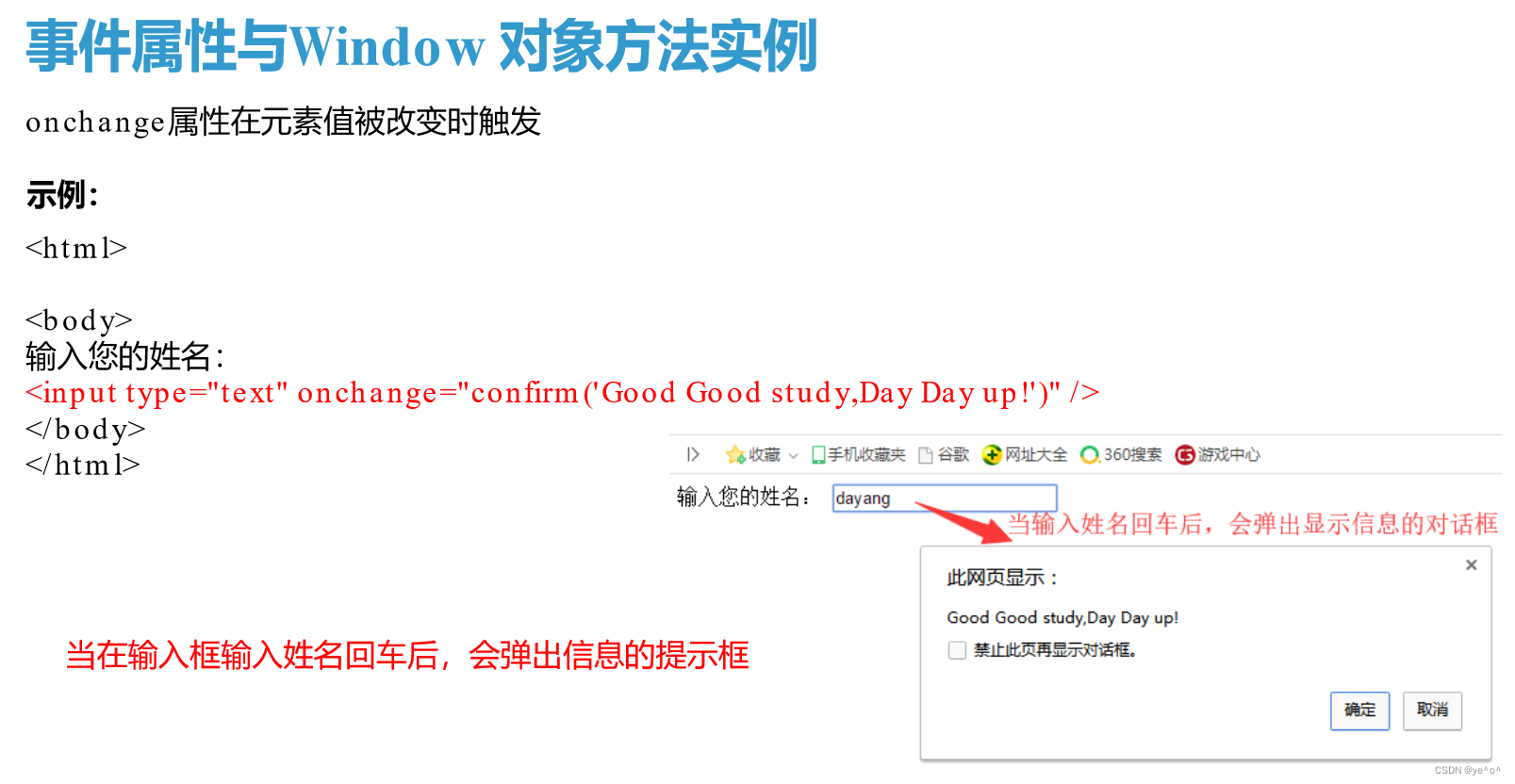
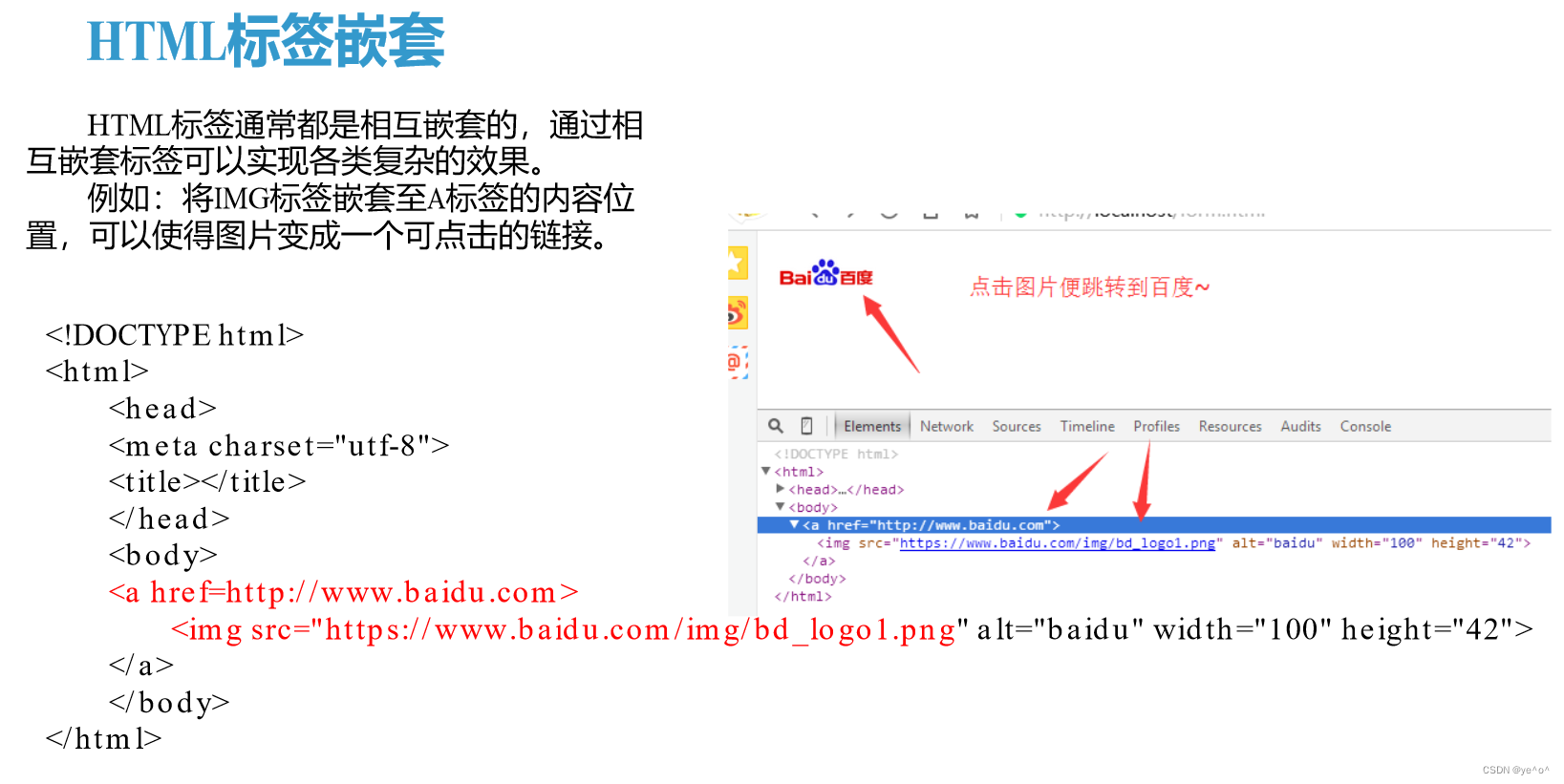
1.6动静态页面
1.6.1 动态页面


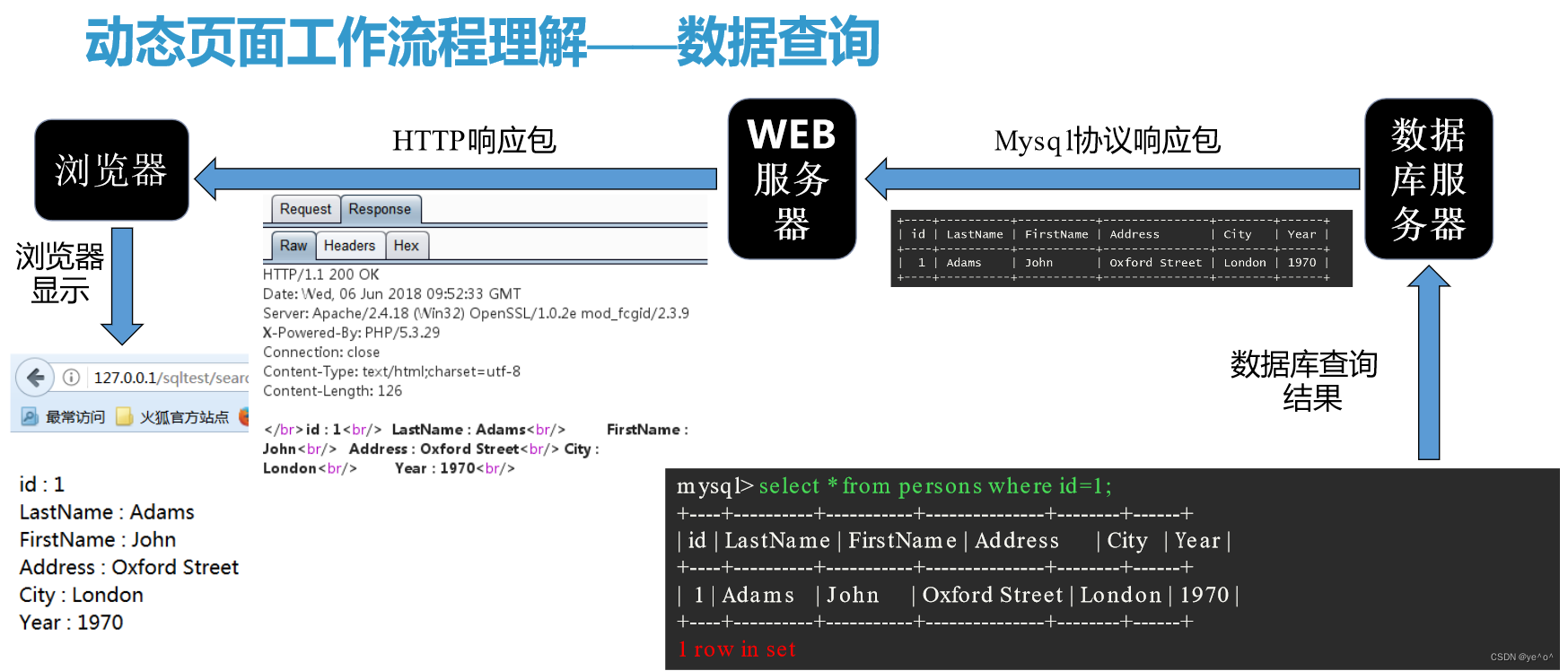
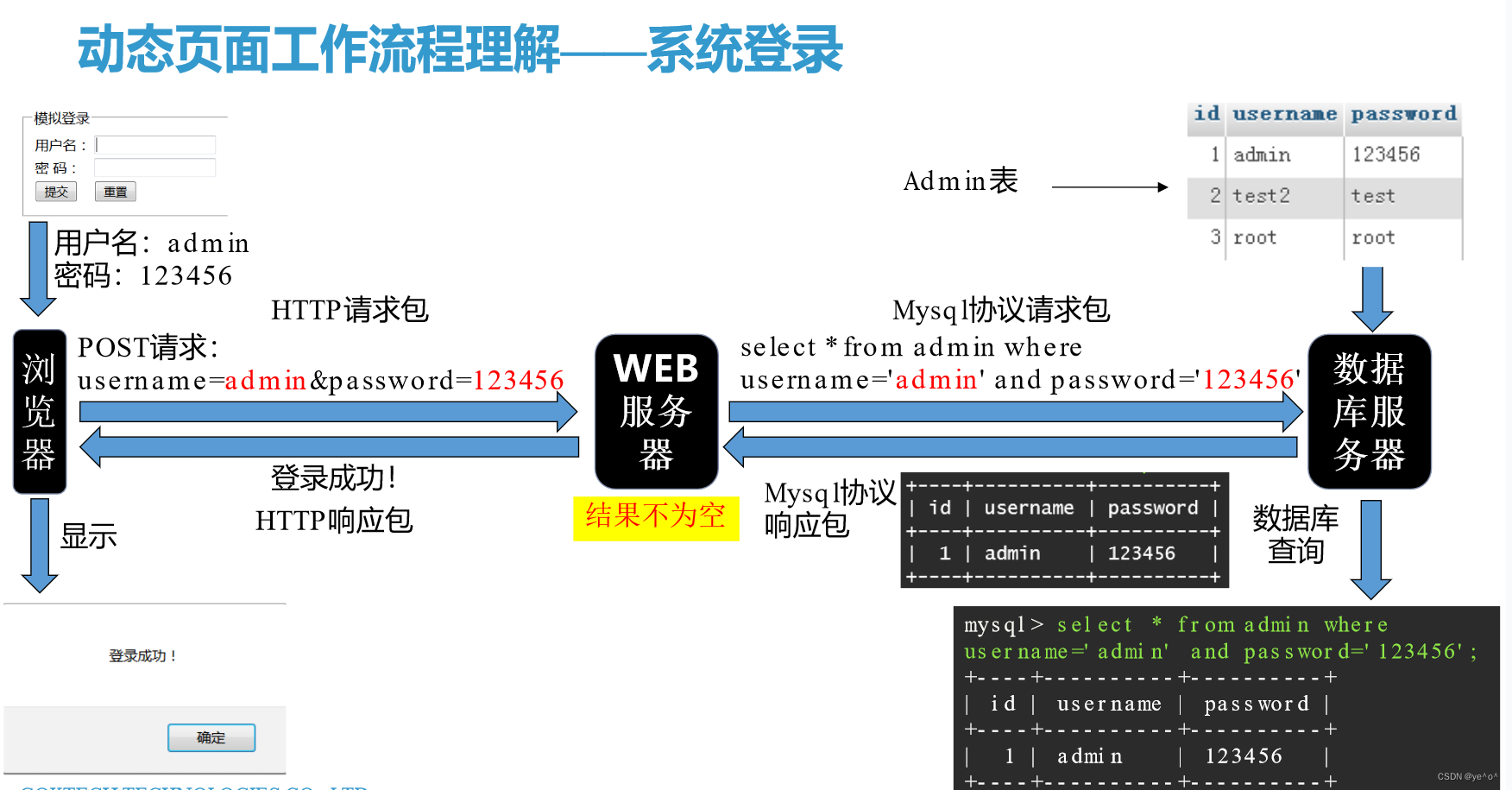
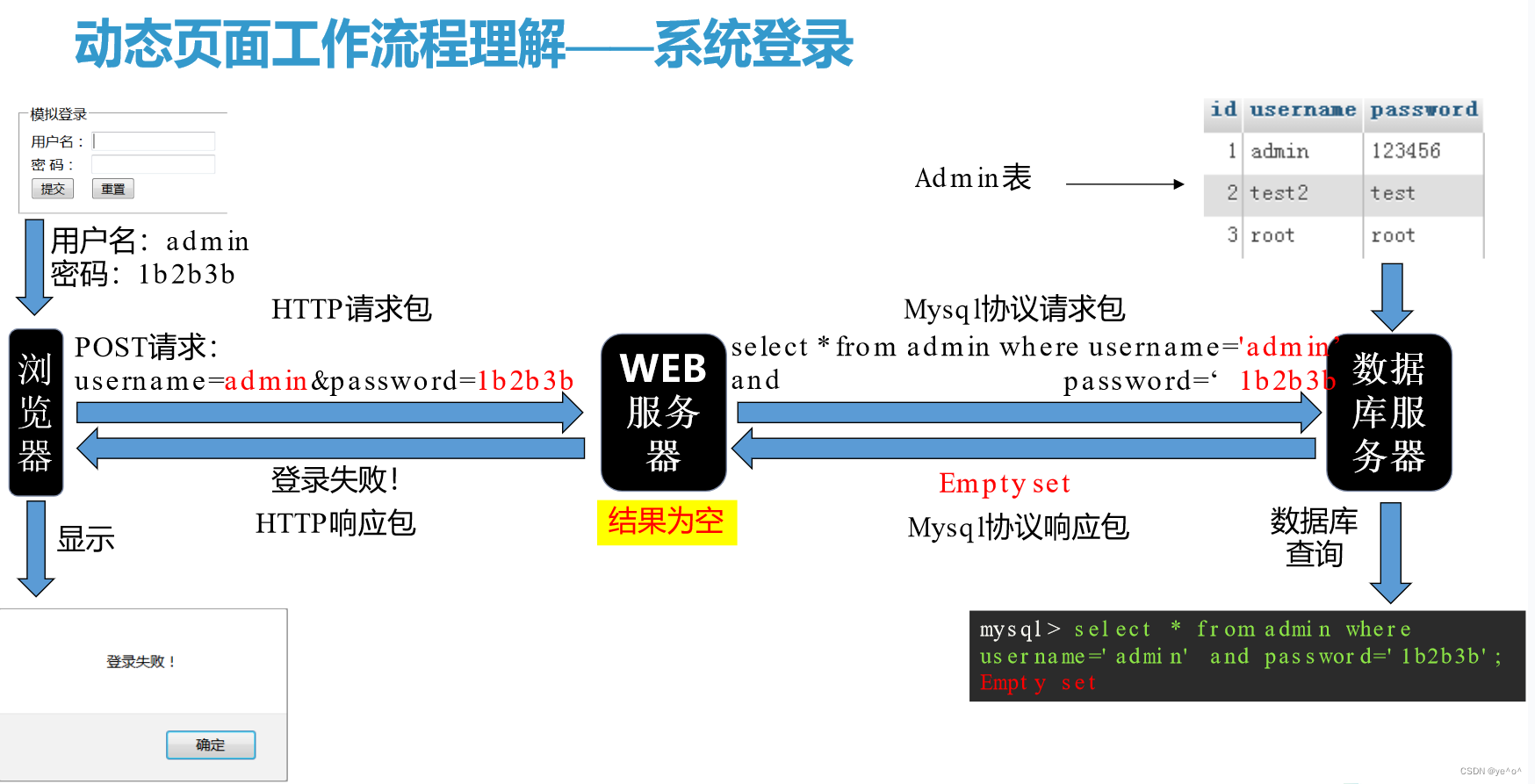
1.6.2 静态页面与动态页面
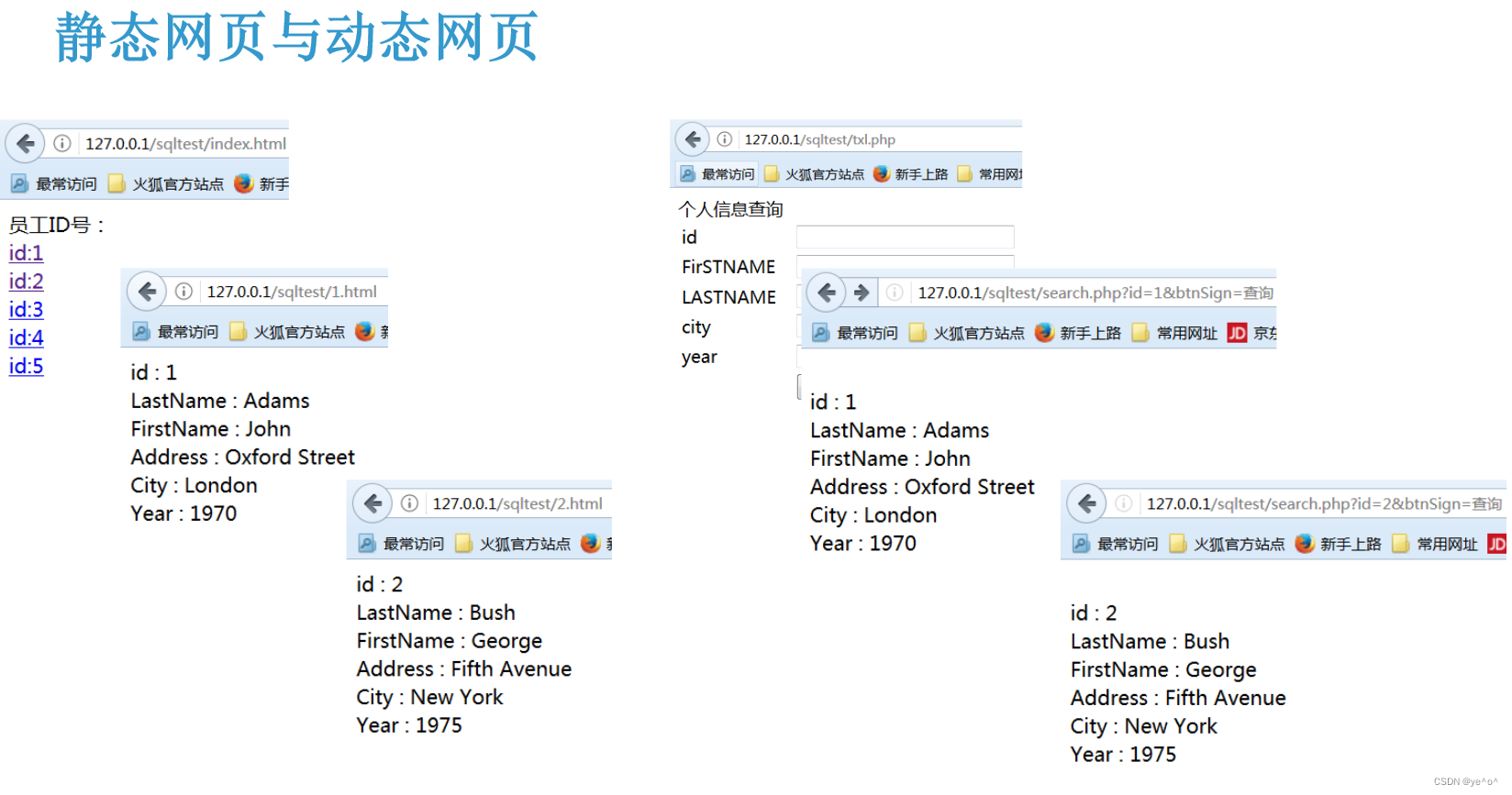

1.7 PHP语法基础




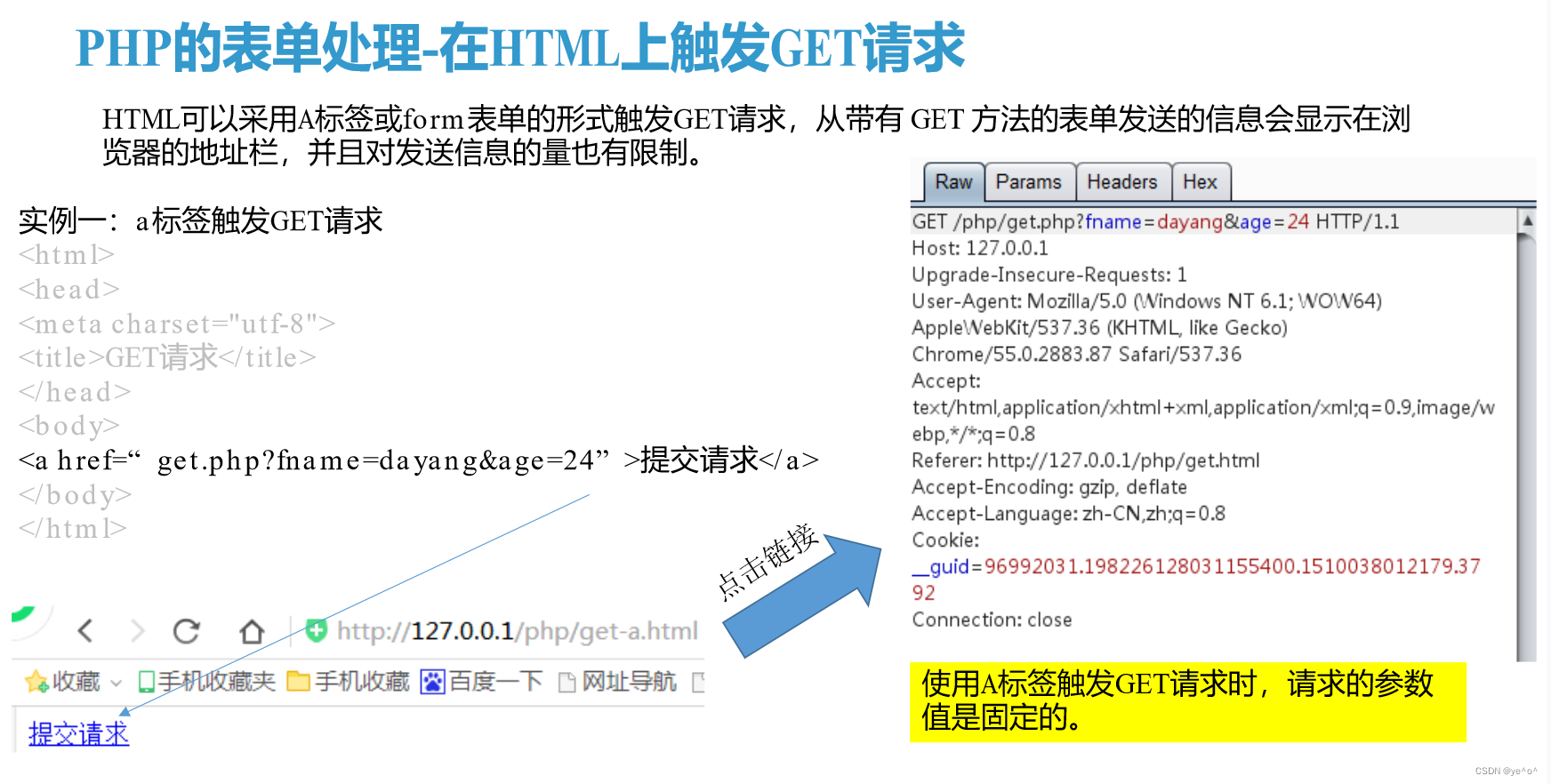
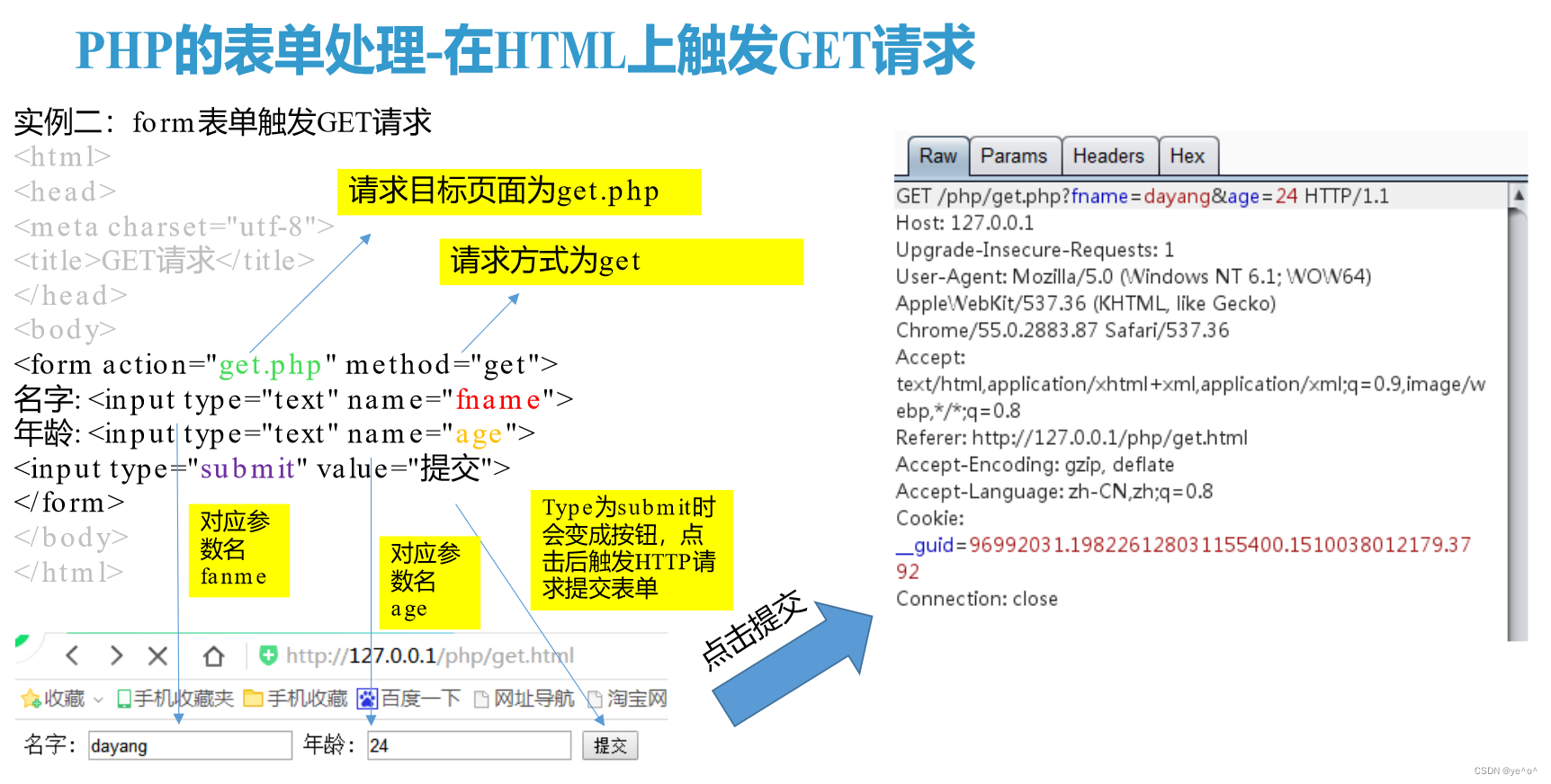
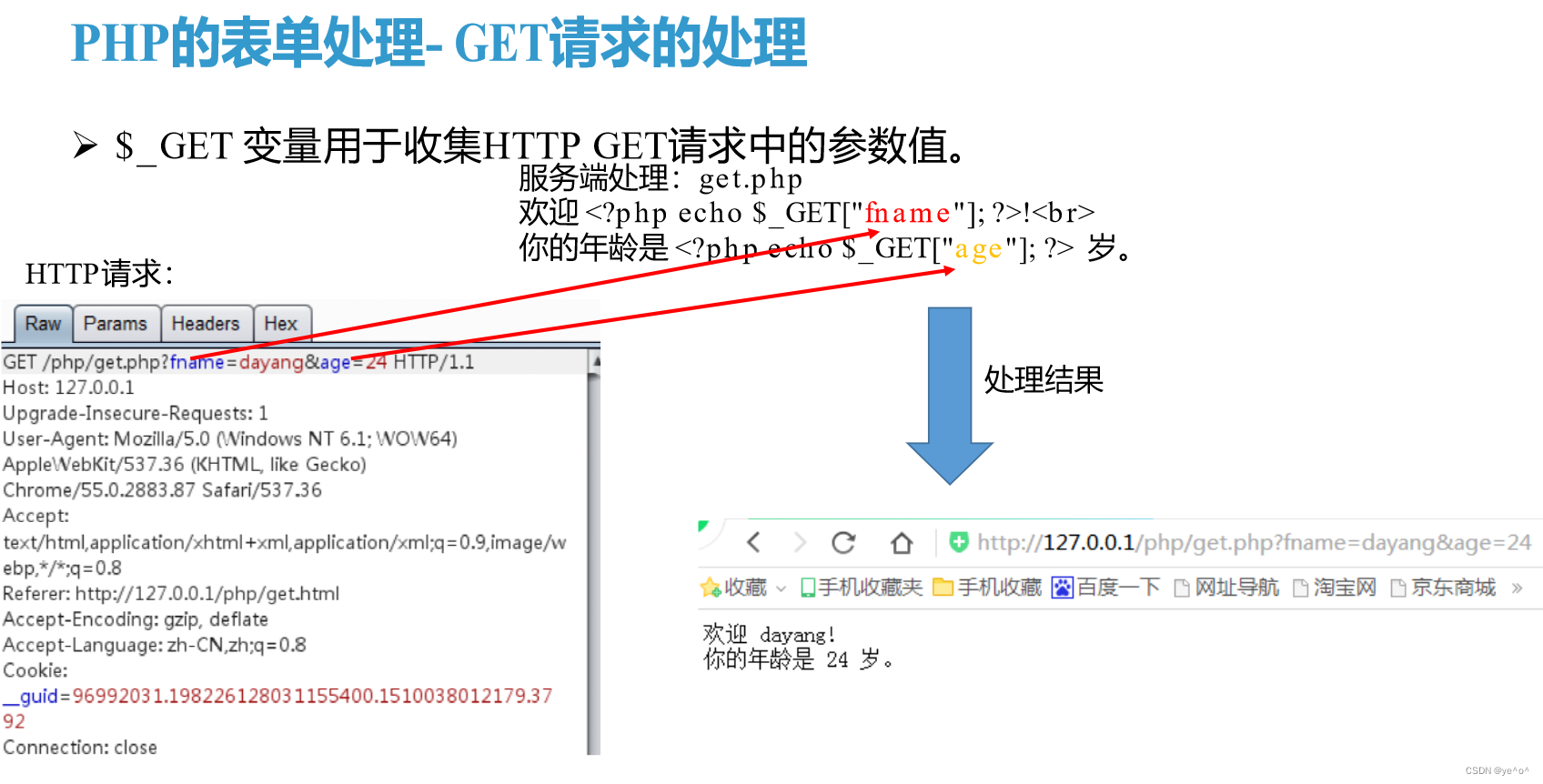
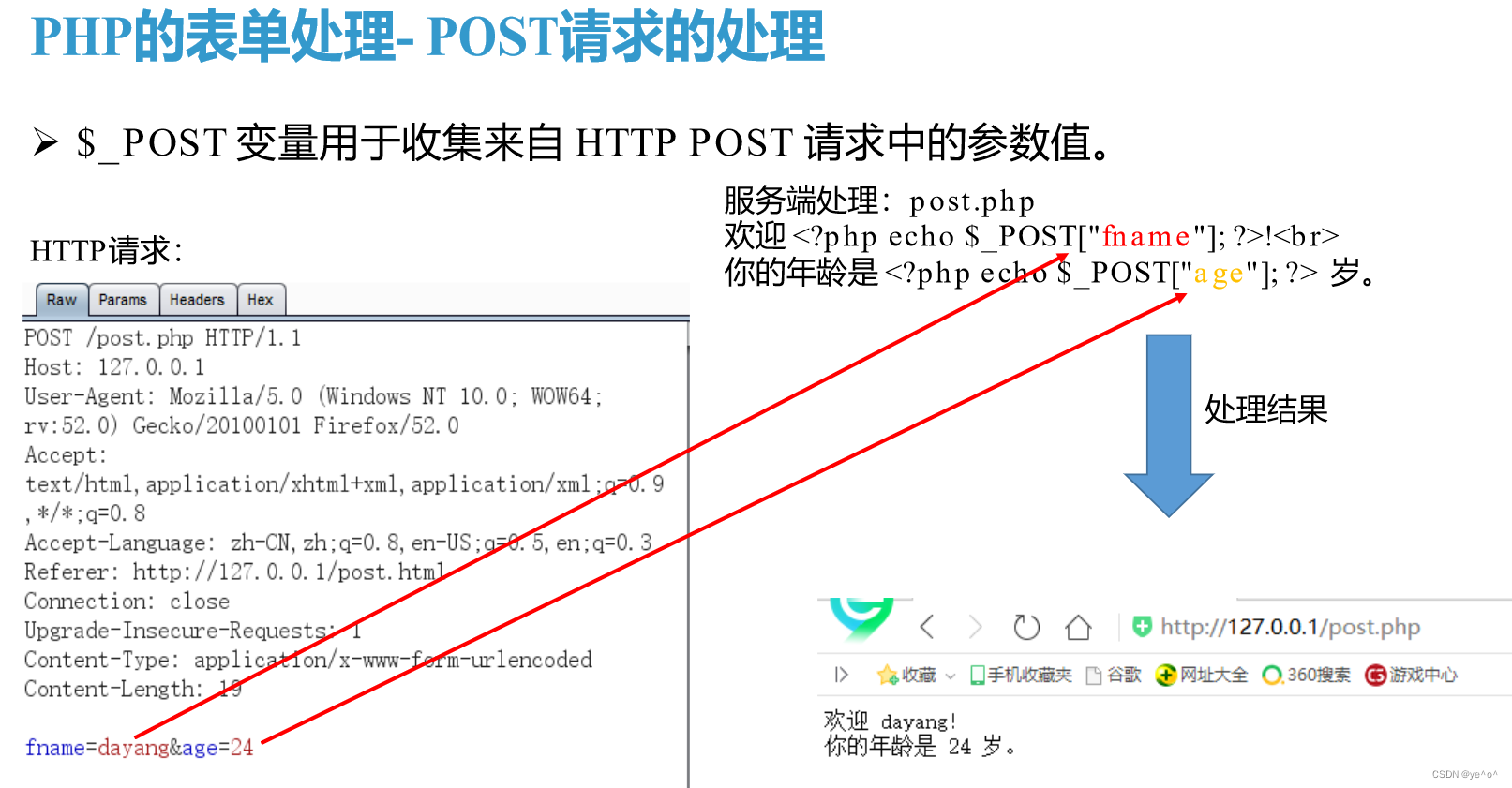
1.7.1 PHP的表单处理
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









