







1、DBMS
DatabaseManagementSystem 数据库管理系统,俗称数据库软件,用于管理数据库;常用的有:
- MySQL(MariaDB):Oracle公司产品, 08年被Sun公司收购了,09年Sun公司被Oracle收购了,MySQL开源产品,市占率排名第一;MariaDB是类似于MySQL的一种DBMS;
- Oracle:Oracle公司产品,闭源产品,性能最强价格最贵, 市占率排名第;
-
SQLServer: 微软公司产品,闭源产品,市占率第三 ;
-
DB2: IBM公司产品,闭源产品;
-
SQLite:轻量级数据库 ;
2、SQL
2.1 基础语法
Structured Query Language,结构化查询语言, 通过此语言让程序员和数据库软件进行交流 ;
| 作用 | 语法 |
| 查询所有数据库 | show databases; |
| 创建数据库 | create databases 数据库名 charset=字符集; |
| 查询数据库信息: | show create database 数据库名字; |
| 删除数据库 | drop database 数据库名字; |
| 使用/切换数据库 | use 数据库名字; |
需要先建库、使用库,之后才能建立表;即表<数据库
| 作用 | 语法 |
| 创建表 | create table 表名(字段1名字 类型,字段2名字 类型。。。);(可选:更改字符集:charset=utf8/gbk) |
| 查询所有表 | show tables; |
| 查询表信息 | show create table 表名; |
| 查询表字段信息 | desc 表名; |
| 删除表 | drop table 表名; |
| 重命表名 | rename table 原表名 to 新表名; |
| 给表的后面插入字段 | alter table 表名 add 新字段 属性; |
| 给表的前面插入字段 | alter table 表名 add 新字段 属性 first; |
| 给表的特定字段后面添加字段 | alter table 表名 add 新字段 属性 after 特定字段名; |
| 删除表字段 | alter table 表名 drop 字段名; |
| 修改表字段 | alter table 表名 change 原名 新名 新类型; |
数据<表<数据库;
| 全表格式插入数据 | insert into 表名 values (数据1,数据2); |
| 指定字段格式插入数据 | insert into 表名 (字段名)values (数据); |
| 批量全表格式插入数据 | insert into 表名 values(数据1,数据2),(数据3,数据4)..; |
| 批量指定字段插入数据 | insert into 表名(字段名1,字段名2) values(数据1),(数据2),...; |
| 查询数据 | select 字段名/多组字段名/*:全字段 from 表名; |
| 有条件查询数据 | select 字段名 from 表名 where 条件(字段); |
| 修改数据 | update 表名 set 字段=新数据 where 条件; |
| 删除数据 | delete from 表名 where |
2.2 条件查询语句
主键约束
约束:创建表时给表字段添加的限制条件;
主键:表示数据唯一性的字段(不重复且不能为空);
例如,给字段类型后面添加primary key: 该字段的数据唯一且不为空;
给int型字段后面添加primary key auto_increment:可以给字段符空值,数据会从1开始;继续给null,数值会从1自增;可以自由赋值,数据的自增会从数值的历史最大值开始;
比较运算符: > < >= <= = !=和<>
用法和java相似,不同的地方主要是取反符有两种写法;
与或非 and or not
-
and: 查询多个条件同时满足时使用
-
or : 查询多个条件满足一个条件时使用
-
not: 取反
between x and y 两者之间 包含x和y
包含之外的数用取反: not between x and y ;
in(x,y,z)
当查询某个字段的值为多个的时候使用 ;
去重 distinct
在要选择去重的字段前面加入属性distinct,可以把不同属性的字段选出来;
如: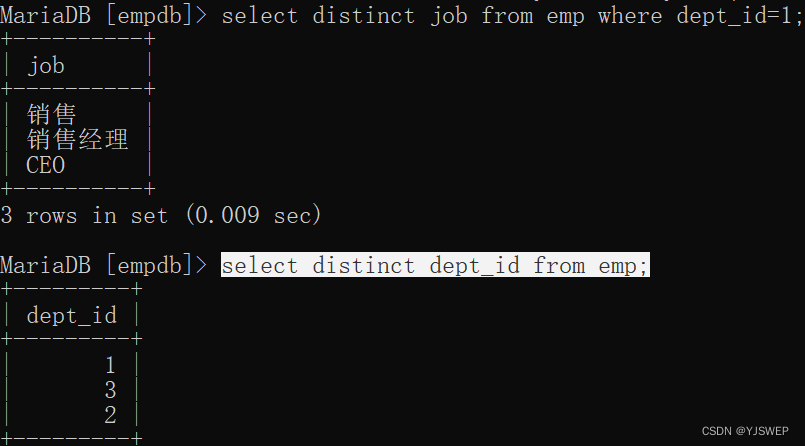
模糊查询:like
-
_: 代表1个未知字符
-
%: 代表0或多个未知字符
-
举例:
-
以x开头 x%
-
以x结尾 %x
-
以x开头y结尾 x%y
-
包含x %x%
-
第二个字符是x _x%
-
第三个是x倒数第二个是y __x%y_
-
排序 order by
order by + 字段名+升序排序asc(默认) / 降序排序desc;
分页查看 limit x,y
x: 忽略掉的数据数量;
y: 显示的数据数量;
修改字段名
select 要修改的字段名 新字段名 from 表名;
聚合函数
可以对查询的多条数据进行统计计算;
求平均值: avg(字段名); 求最大值:max(字段名); 求最小值: min(字段名); 求和:sum(字段名);
可以在一行语句中组合使用这些聚合函数;
注意: where后面只能跟普通字段条件,不能跟聚合函数;
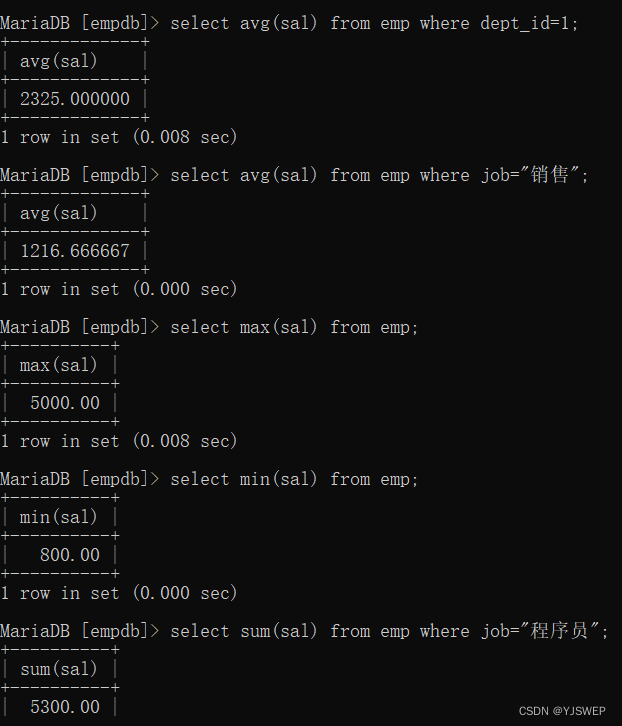
添加聚合函数的条件:having + 聚合函数的条件
与group by 结合使用,放在它的后面;

统计数据数量:count()
由于数据为Null的无法统计数量,推荐用法: select count(*) from 表名;
分组查询 groupe by
根据特定字段进行分组查询,一般要将分组的字段也查出来以便查看:
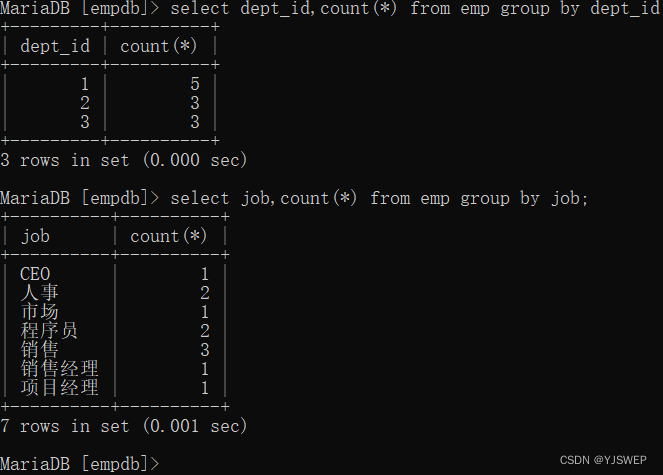
数值计算
查询每个员工的姓名,工资和年终奖(5个月的工资):select name,sal,5*sal price 年终奖 from emp;
可以在要查询的值里直接进行计算;
子查询(嵌套查询)
可以在把查询的数值当做相应字段的值:select avg(sal) from emp where dept_id=3;
select sal,name from emp where sal>(select avg(sal) from emp where dept_id=3);
嵌套可以迭代,实现多重条件的查询;
2.2 关联关系
有三种关系:一对一;多对一;多对多;
针对三种关系我们如何建立联系:
一对一: 在两张表的任意一张表中添加建立关系的字段指向另外一张表的主键;
一对多: 在多的表中添加建立关系的字段指向另外一张表的主键 ;
多对多: 新建一张关系表,表中至少有两个字段用于建立关系, 指向另外两张表的主键 ;
关联查询:同时从多张表查询数据的方式;分为三种:
等值连接:
查询的都是两个表的"交集数据"(存在关系的数据);
格式: select 字段信息 from A,B where A.xxx=B.xxx(关联关系) and 其它条件;
内连接:
等值连接和内连接的作用一样,查询的都是两个表的"交集数据"(存在关系的数据);
格式: select 字段信息 from A join B on A.x=B.x where 其它条件
外连接:
外连接查询到的是一张表的全部和另外一张表的交集数据
格式: select 字段信息 from A left/right join B on A.x=B.x where 其它条件 ;
left:表示查询左边表格的全部全部数据,rigth则指右边;
关联查询总结:
需要查询多张表格的数据;如果查询的是两张表格的交集数据,使用等值连接或者内连接(推荐);如果查询的是一张表的全部数据和另一张表的交集数据,则使用外连接;
3. JDBC
3.1 概述:
java DataBase Connectivity: java数据库链接, 它是SUN公司提供的一套专门用于java和各种数据库软件进行连接的API,确定了各种数据库的唯一方法名(从数据库厂商的角度来说,则是根据接口写各自的驱动), 提高了开发效率和降低了学习成本;
3.2 使用步骤
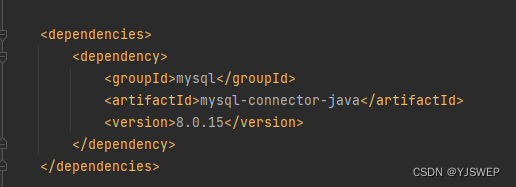
1: 创建Maven工程,在pom.xml文件里配置连接mysql数据库的依赖;
2:建立新类,按四步执行SQL语句:
1.获取数据库的连接对象~2.创建执行SQL语句的对象~3.执行SQL语句~4.最后记得关闭连接对象;
public class Demo1 {
public static void main(String[] args) throws SQLException {
//1.获取数据库连接对象
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/empdb?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"root","root"
);
System.out.println("连接对象:"+conn);
// 2.创建执行SQL语句的对象
Statement s = conn.createStatement();
// 3.执行SQL语句
s.execute("create table jdbct1(id int)"); //如果有一个表存在的话会报错
// 4.关闭资源
conn.close();
System.out.println("执行完成");
}
}执行SQL语句的方法有几种:
execute("SQL"): 可以执行任意SQL语句,但推荐只执行与数据库和表相关的SQL语句;
int i = statement.executeUpdate("SQL"):执行数据 增/删/改 相关的语句,返回值代表生效的行数;
ResultSet rs = statement.executeQuery("SQL"):执行数据查询,返回查询的结果装到ResultSet对象中;可以通过以下方式得到ResultSet对象的数据:
public class Demo03 {
public static void main(String[] args) throws SQLException {
Connection conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/empdb?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false",
"root","root"
);
Statement s = conn.createStatement();
ResultSet res = s.executeQuery("select name,sal,dept_id from emp");
// 取出数据
while(res.next()){
// 通过字段名字获取游标指向的数据
// String name = res.getString("name");
// int salary = res.getInt("sal");
// 通过数字游标获取数据
String name = res.getString(1);
int salary = res.getInt(2);
System.out.println(name+":"+salary);
}
conn.close();3.3 DBCP
DataBaseConnectionPool数据库连接池:将连接重用,避免频繁的开关连接,,提高了效率;
使用流程:
1.先导入好DBCP的依赖:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>2.创建连接池,并从连接池里获取连接对象,可以封装建立好的连接池为一个单独的类,提供获取连接对象的公共方法;
private static DruidDataSource dds;
static {
//创建连接池对象
dds = new DruidDataSource();
//设置数据库信息
dds.setUrl("jdbc:mysql://localhost:3306/empdb?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false");
dds.setUsername("root");
dds.setPassword("root");
//设置初识链接数量
dds.setInitialSize(3);
dds.setMaxActive(5);
}
public static Connection getConn() throws SQLException {
Connection conn = dds.getConnection();
System.out.println("连接对象:"+conn);
return conn;
}3.按JDBC提供的接口方法执行SQL语句:
//隐藏连接对象关闭语句
try (Connection conn = DBUtils.getConn()){
Statement s = conn.createStatement();
ResultSet re = s.executeQuery("select name from emp");
while(re.next()){
String name = re.getString(1);
System.out.println(name);
}
} catch (SQLException throwables) {
throwables.printStackTrace();
}
}














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









