







目录
第1关:查找购买个数超过20,重量小于50的商品,按照商品id升序排序
第2关:查询向follow表中user_id = 1 的用户,推荐其关注的人喜欢的音乐
第3关:查询向follow表中user_id用户,推荐其关注的人喜欢的音乐
第5关:查询各工程号最大的按零件号合计供应量以及该零件号,并先按工程号升序,再按零件号升序排序。
如果对你有帮助的话,不妨点赞收藏评论一下吧,爱你么么哒😘❤️❤️❤️
第1关:查找购买个数超过20,重量小于50的商品,按照商品id升序排序
描述 如下有一张商品表(goods),字段依次为:商品id、商品名、商品质量

还有一张交易表(trans),字段依次为:交易id、商品id、这个商品购买个数

查找购买个数超过20,重量小于50的商品,按照商品id升序排序,如:

USE mygoods;
########## Begin ##########
select goods.id,sum(count) as total
from goods,trans
where goods.weight<50 and goods.id=trans.id
group by goods.id
having total>20
order by goods.id;
########## End ##########
第2关:查询向follow表中user_id = 1 的用户,推荐其关注的人喜欢的音乐
任务描述
假设音乐数据库里面现在有几张如下简化的数据表: 关注follow表,第一列是关注人的id,第二列是被关注人的id,这2列的id组成主键

这张表的第一行代表着用户id为1的关注着id为2的用户
这张表的第二行代表着用户id为1的关注着id为4的用户
这张表的第三行代表着用户id为2的关注着id为3的用户
个人的喜欢的音乐music_likes表,第一列是用户id,第二列是喜欢的音乐id,这2列的id组成主键

这张表的第一行代表着用户id为1的喜欢music_id为17的音乐 ....
这张表的第五行代表着用户id为4的喜欢music_id为17的音乐
音乐music表,第一列是音乐id,第二列是音乐name,id是主键

请你编写一个MYSQL,查询向user_id = 1 的用户,推荐其关注的人喜欢的音乐。不要推荐该用户已经喜欢的音乐,并且按music的music_name升序排列。你返回的结果中不应当包含重复项 上面的查询结果如下:

USE mymusic;
########## Begin ##########
select distinct m1.music_name
from follow f1
right join music_likes ml1 on f1.follower_id=ml1.user_id
right join music m1 on m1.id=ml1.music_id
where f1.user_id=1 and music_name not in (
select m2.music_name
from music_likes ml2
right join music m2 on ml2.music_id=m2.id
where ml2.user_id=1
)
order by m1.music_name;
########## End ##########第3关:查询向follow表中user_id用户,推荐其关注的人喜欢的音乐
任务描述
假设音乐数据库里面现在有几张如下简化的数据表: 关注follow表,第一列是关注人的id,第二列是被关注人的id,这2列的id组成主键

这张表的第一行代表着用户id为1的关注着id为2的用户
这张表的第二行代表着用户id为1的关注着id为4的用户
这张表的第三行代表着用户id为2的关注着id为3的用户
个人的喜欢的音乐music_likes表,第一列是用户id,第二列是喜欢的音乐id,这2列的id组成主键

这张表的第一行代表着用户id为1的喜欢music_id为17的音乐 ....
这张表的第五行代表着用户id为4的喜欢music_id为17的音乐
音乐music表,第一列是音乐id,第二列是音乐name,id是主键

请你编写一个MYSQL,查询向follow表中user_id用户,推荐其关注的人喜欢的音乐。不要推荐该用户已经喜欢的音乐,并且先按follow的user_id升序排列,再按music的music_name升序排列。你返回的结果中不应当包含重复项
上面的查询结果如下:
user_id music_name
1 kong
1 MOM
2 Sold Out
USE mymusic;
########## Begin ##########
SELECT DISTINCT follow.user_id,music_name
FROM follow ,music_likes,music
WHERE follow.follower_id=music_likes.user_id
AND music.id=music_likes.music_id and follow.user_id
AND music_id NOT IN(
SELECT music_id
FROM music_likes m
WHERE m.user_id=follow.user_id
)
ORDER BY user_id,music_name;
########## End ##########第4关:查询用户日活数及支付金额
现有3张业务表,详见如下:

需要输出结果如下,没有支付的日期不需要显示,请写出对应的MYSQL
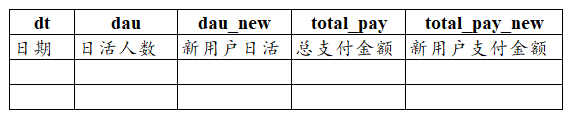
USE myusers;
########## Begin ##########
SELECT A.dt,
COUNT(DISTINCT A.user_id) AS dau,
SUM(B.is_new) AS dau_new,
SUM(C.pay_money) AS total_pay,
SUM(IF(B.is_new=1,C.pay_money,NULL)) AS total_pay_new
FROM(
SELECT DISTINCT user_id,dt
FROM login_record)A
LEFT JOIN new_user AS B ON A.user_id=B.user_id
LEFT JOIN user_pay AS C ON C.user_id=A.user_id AND C.dt=A.dt
GROUP BY A.dt
HAVING SUM(C.pay_money) IS NOT NULL
########## End ##########第5关:查询各工程号最大的按零件号合计供应量以及该零件号,并先按工程号升序,再按零件号升序排序。
任务描述
查询各工程号最大的按零件号合计供应量以及该零件号,并先按工程号升序,再按零件号升序排序。
相关知识
供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。 SPJ表如下图:
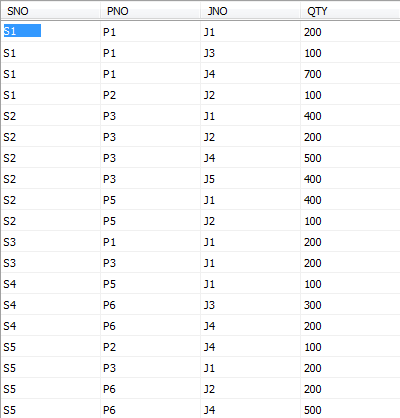
现已构建SPJ表,结构信息如下:
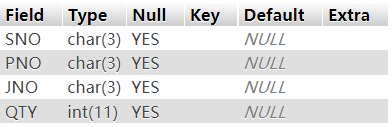
开始你的任务吧,祝你成功!
USE mydata;
#请在此处添加实现代码
########## Begin ##########
create view calculate(JNO,PNO,maxsum) as
select JNO,PNO,sum(QTY)
from SPJ
group by JNO,PNO
order by JNO,PNO;
select JNO,PNO,maxsum
from calculate as x
where x.maxsum>=all(
select maxsum
from calculate as y
where x.JNO=y.JNO
);
########## End ##########















 3406
3406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









