









1、检测与安装
首先,验证命令
mpstat

如果出现命令不识别的情况,则需要根据不同的系统进行安装
#Debian
apt-get install sysstat
#Ubuntu
apt-get install sysstat
#Alpine
apk add sysstat
#Arch Linux
pacman -S sysstat
#Kali Linux
apt-get install sysstat
#CentOS
yum install sysstat
#Fedora
dnf install sysstat
#OS X
brew install sysstat
#Raspbian
apt-get install sysstat
#Docker
docker run cmd.cat/mpstat mpstat
安装网络监控工具:ifstat
网络监控工具ifstat和iftop使用yum无法安装成功,需要使用源代码方式安装。注意:使用源代码方式安装需要有C编译环境gcc。
1、安装ifstat
wget http://distfiles.macports.org/ifstat/ifstat-1.1.tar.gz
tar xzvf ifstat-1.1.tar.gz
cd ifstat-1.1
./configure
make && make install
2、安装iftop
yum install -y flex byacc libpcap ncurses-devel libpcap-devel
wget http://www.ex-parrot.com/pdw/iftop/download/iftop-1.0pre4.tar.gz
tar zxvf iftop-1.0pre4.tar.gz
cd iftop-1.0pre4
./configure
make && make install
2、top 整机状态查询命令 详解
- 整机:top
- CPU:vmstat
- 内存:free
- 硬盘:df
- 磁盘IO:iostat
- 网络IO:ifstat
top命令运行图

第一行:基本信息
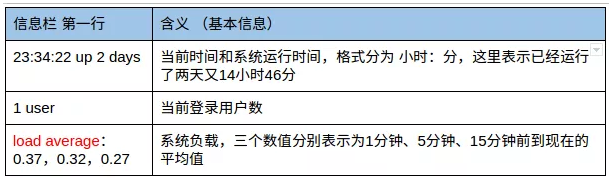
第二行:任务信息

第三行:CPU使用情况

第四行:物理内存使用情况
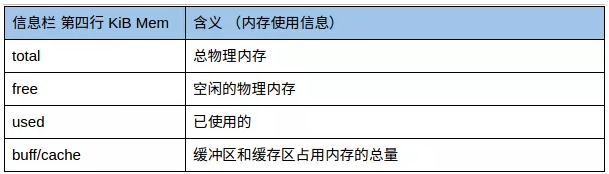
buff/cache:
buffers 和 cache 都是内存中存放的数据,不同的是,buffers 存放的是准备写入磁盘的数据,而 cache 存放的是从磁盘中读取的数据
在Linux系统中,有一个守护进程(daemon)会定期把buffers中的数据写入的磁盘,也可以使用 sync 命令手动把buffers中的数据写入磁盘。使用buffers可以把分散的 I/O 操作集中起来,减少了磁盘寻道的时间和磁盘碎片。
cache是Linux把读取频率高的数据,放到内存中,减少I/O。Linux中cache没有固定大小,根据使用情况自动增加或删除。
第五行:交换区使用情况
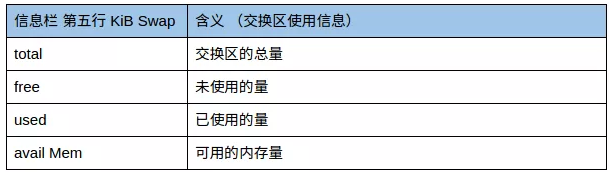
Swap(内存交换区):
是硬盘上的一块空间。在内存不足的情况下,操作系统把内存中不用的数据存到硬盘的交换区,腾出内存来让别的程序运行。因此,开启swap会一定程度的引起 I/O 性能下降(阿里服务器默认不开)。
第六行:进程详细信息

3、生产环境服务器变慢,诊断思路和性能评估
下面我们就来模拟一次死锁、死循环的故障排查。
介绍一下使用到的top参数:

线上的出现需要使用top排查的情况一般是死循环或者死锁,下面通过代码来模拟两种情况:
我们首先需要创建一个spring boot 项目,然后在控制器中写入调用方法:
package demo.controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.concurrent.TimeUnit;
@RestController
@RequestMapping("demo")
public class TopController {
private Object lock1 = new Object();
private Object lock2 = new Object();
@RequestMapping("test")
public String test() {
return "success";
}
// 死循环
@RequestMapping("loop")
public String loop() {
System.out.println("start");
while (true) {}
}
// 死锁
@RequestMapping("deadlock")
public String deadlock() {
new Thread(() -> {
synchronized (lock1) {
try{
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {}
synchronized (lock2) {
System.out.println("thread1 over");
}
}
}).start();
new Thread(() -> {
synchronized (lock2) {
try{
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {}
synchronized (lock1) {
System.out.println("thread2 over");
}
}
}).start();
return "success";
}
}
启动项目:
#启动
nohup java -jar deadLock-1.0-SNAPSHOT.jar &
#结束进程(项目)
kill -9 3538(PID)
通过浏览器唤醒这个死循环:
http://192.168.56.10:8080/demo/loop

这时候我们来使用 top 命令看一下CPU 和 内存的使用情况:
#查看所有进程
top
#查看指定进程
top -p 10579

可以看到,PID为10579进程的CPU的使用率已经飙升到90%多,这肯定是不正常的。
我们也可以使用 jps -l 查看Java 进程号:
jps -l

再通过 ps -mp 10579 -o THREAD,tid,time 查看里面的线程情况
定位到具体线程或代码
ps -mp 10579 -o THREAD,tid,time

参数说明:
ps -mp 进程 -o THREAD,tid,time
-m 显示所有的线程
-p 指定进程id
-o 该参数后是用户自定义格式
由于线程号是应该使用16进制来查询,所以我们需要把TID的转成16进制:
将需要的线程ID转换为16进制格式(英文小写格式)
printf "%x" 10622
得到:297e

命令:jstack 进程ID(也就是PID) | grep tid(16进程线程ID小写英文) -A60
-A 显示为多少行,-A60 就是显示前60行
jstack 10579 | grep 297e -A60

看这条:
at demo.controller.TopController.loop(TopController.java:24)
第24行的锅:

结案!!
4、总结
其实命令顺序 是这样的:
1、top 先看一下cpu 内存 情况
top
2、jps -l 看一下 Java进程
jps -l
3、根据 进程 PID 查一下是进程里的哪个线程搞得鬼
ps -mp 10579(PID) -o THREAD,tid,time
4、查到搞鬼的线程TID 后 转成16进制 ,得到 :297e
printf "%x" 10622(TID)
5、根据 进程TID 和 16进制的 TID 查询 问题所在
jstack 10579 | grep 297e -A60

















 1835
1835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











