from datasets import load_dataset
dataset = load_dataset("imdb")print(dataset["train"][0])
加载基础模型与Tokenizer
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name ="bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)# 原始参数量统计
total_params =sum(p.numel()for p in model.parameters())print(f"原始模型参数总量:{total_params:,}")
from peft import PeftModel
base_model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)# 加载基础模型
model = PeftModel.from_pretrained(base_model,"lora_imdb_output")# 注入LoRA
model = model.merge_and_unload()# 合并权重加速
inputs = tokenizer("This movie was fantastic!", return_tensors="pt")# 预测示例
outputs = model(**inputs)
pred = outputs.logits.argmax().item()print("正面"if pred ==1else"负面")# 输出:正面







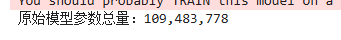


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









