




 该文介绍了使用Pytorch框架进行图像分类的步骤,包括数据预处理(如随机裁剪、翻转、归一化),模型构建,训练集和测试集的加载,以及训练过程中的损失计算、精度评估和模型保存。训练过程中采用了ImageFolder数据集,使用了数据加载器(DataLoader)并调整了学习率。
该文介绍了使用Pytorch框架进行图像分类的步骤,包括数据预处理(如随机裁剪、翻转、归一化),模型构建,训练集和测试集的加载,以及训练过程中的损失计算、精度评估和模型保存。训练过程中采用了ImageFolder数据集,使用了数据加载器(DataLoader)并调整了学习率。
使用的数据集合
直接使用Pytorch 的数据集合: fruit30_split

目录结构:
模型部分
导入工具包
import warnings
import time
import os
from tqdm import tqdm
import pandas as pd
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torchvision import models
import torch.optim as optim
from torch.optim import lr_scheduler
%matplotlib inline
# 忽略烦人的红色提示
warnings.filterwarnings("ignore")
# 获取计算硬件
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
图像预处理
from torchvision import transforms
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [
0.229, 0.224, 0.225])
])
# 测试集图像预处理-RCTN:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
载入数据集
# 数据集文件夹路径
dataset_dir = 'fruit30_split'
from torchvision import datasets
train_path = os.path.join(dataset_dir, 'train')
test_path = os.path.join(dataset_dir, 'val')
print('训练集路径', train_path)
print('测试集路径', test_path)
# 载入训练集
train_dataset = datasets.ImageFolder(train_path, train_transform)
# 载入测试集
test_dataset = datasets.ImageFolder(test_path, test_transform)
print('训练集图像数量', len(train_dataset))
print('类别个数', len(train_dataset.classes))
print('各类别名称', train_dataset.classes)
print('测试集图像数量', len(test_dataset))
print('类别个数', len(test_dataset.classes))
print('各类别名称', test_dataset.classes)
映射
# 各类别名称
class_names = train_dataset.classes
n_class = len(class_names)
# 映射关系:类别 到 索引号
train_dataset.class_to_idx
# 映射关系:索引号 到 类别
idx_to_labels = {y:x for x,y in train_dataset.class_to_idx.items()}
idx_to_labels定义数据加载Dataloader
from torch.utils.data import DataLoader
BATCH_SIZE = 32
# 训练集的数据加载器
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
# 测试集的数据加载器
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)
训练配置
model = model.to(device)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 训练轮次 Epoch
EPOCHS = 100
# 学习率降低策略
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)训练日志
# 训练日志-训练集
df_train_log = pd.DataFrame()
log_train = {}
log_train['epoch'] = 0
log_train['batch'] = 0
images, labels = next(iter(train_loader))
log_train.update(train_one_batch(images, labels))
df_train_log = df_train_log.append(log_train, ignore_index=True)
# 训练日志-测试集
df_test_log = pd.DataFrame()
log_test = {}
log_test['epoch'] = 0
log_test.update(evaluate_testset())
df_test_log = df_test_log.append(log_test, ignore_index=True)
训练
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
epoch = 0
batch_idx = 0
best_test_accuracy = 0
def train_one_batch(images, labels):
'''
运行一个 batch 的训练,返回当前 batch 的训练日志
'''
# 获得一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
loss = criterion(outputs, labels) # 计算当前 batch 中,每个样本的平均交叉熵损失函数值
# 优化更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 获取当前 batch 的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
log_train = {}
log_train['epoch'] = epoch
log_train['batch'] = batch_idx
# 计算分类评估指标
log_train['train_loss'] = loss
log_train['train_accuracy'] = accuracy_score(labels, preds)
# log_train['train_precision'] = precision_score(labels, preds, average='macro')
# log_train['train_recall'] = recall_score(labels, preds, average='macro')
# log_train['train_f1-score'] = f1_score(labels, preds, average='macro')
return log_train
def evaluate_testset():
'''
在整个测试集上评估,返回分类评估指标日志
'''
loss_list = []
labels_list = []
preds_list = []
with torch.no_grad():
for images, labels in test_loader: # 生成一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
# 获取整个测试集的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
# 由 logit,计算当前 batch 中,每个样本的平均交叉熵损失函数值
loss = criterion(outputs, labels)
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
loss_list.append(loss)
labels_list.extend(labels)
preds_list.extend(preds)
log_test = {}
log_test['epoch'] = epoch
# 计算分类评估指标
log_test['test_loss'] = np.mean(loss)
log_test['test_accuracy'] = accuracy_score(labels_list, preds_list)
log_test['test_precision'] = precision_score(
labels_list, preds_list, average='macro')
log_test['test_recall'] = recall_score(
labels_list, preds_list, average='macro')
log_test['test_f1-score'] = f1_score(labels_list,
preds_list, average='macro')
return log_test
import wandb
wandb.init(project='fruit30', name=time.strftime('%m%d%H%M%S'))
for epoch in range(1,EPOCHS+1):
print(f'EPOCH: {epoch}/{EPOCHS}')
model.train()
for images, labels in tqdm(train_loader):
batch_idx += 1
log_train = train_one_batch(images,labels)
df_train_log=df_train_log.append(log_train, ignore_index=True)
wandb.log(log_train)
lr_scheduler.step()
model.eval()
log_test = evaluate_testset()
df_test_log = df_test_log.append(log_test, ignore_index = True)
wandb.log(log_test)
if log_test['test_accuracy'] > best_test_accuracy:
old_best_path = 'best-{:.3f}.pth'.format(best_test_accuracy)
if os.path.exists(old_best_path):
os.remove(old_best_path)
new_best_path = 'best-{:.3f}.pth'.format(log_test['test_accuracy'])
torch.save(model, new_best_path)
print('保存新的最佳模型','best-{:.3f}.pth'.format(best_test_accuracy))
best_test_accuracy = log_test['test_accuracy']
df_train_log.to_csv('训练日志-训练集.csv', index=False)
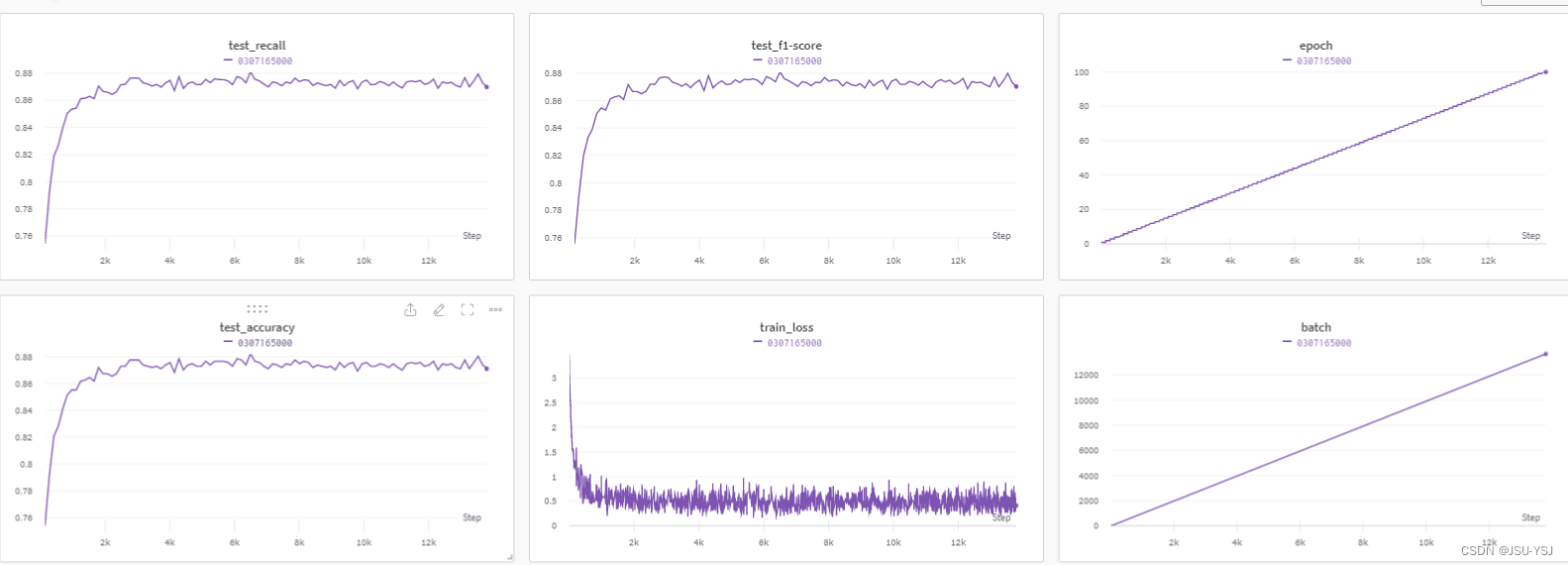
df_test_log.to_csv('训练日志-测试集.csv', index=False)训练结果





















 4764
4764




 到【灌水乐园】发言
到【灌水乐园】发言







